Kernel untuk Jupyter Notebook pada kluster Apache Spark di Azure HDInsight
Kluster HDInsight Spark menyediakan kernel yang dapat Anda gunakan dengan Jupyter Notebook di Apache Spark untuk menguji aplikasi Anda. Kernel adalah program yang menjalankan dan menafsirkan kode Anda. Tiga kernel adalah:
- PySpark - untuk aplikasi yang ditulis dalam Python2. (Hanya berlaku untuk kluster versi Spark 2.4)
- PySpark3 - untuk aplikasi yang ditulis dalam Python3.
- Spark - untuk aplikasi yang ditulis dalam Scala.
Dalam artikel ini, Anda mempelajari cara menggunakan kernel ini dan manfaat menggunakannya.
Prasyarat
Kluster Apache Spark di Microsoft Azure HDInsight. Untuk petunjuk selengkapnya, lihat Membuat kluster Apache Spark di Microsoft Azure HDInsight.
Membuat Jupyter Notebook di Spark HDInsight
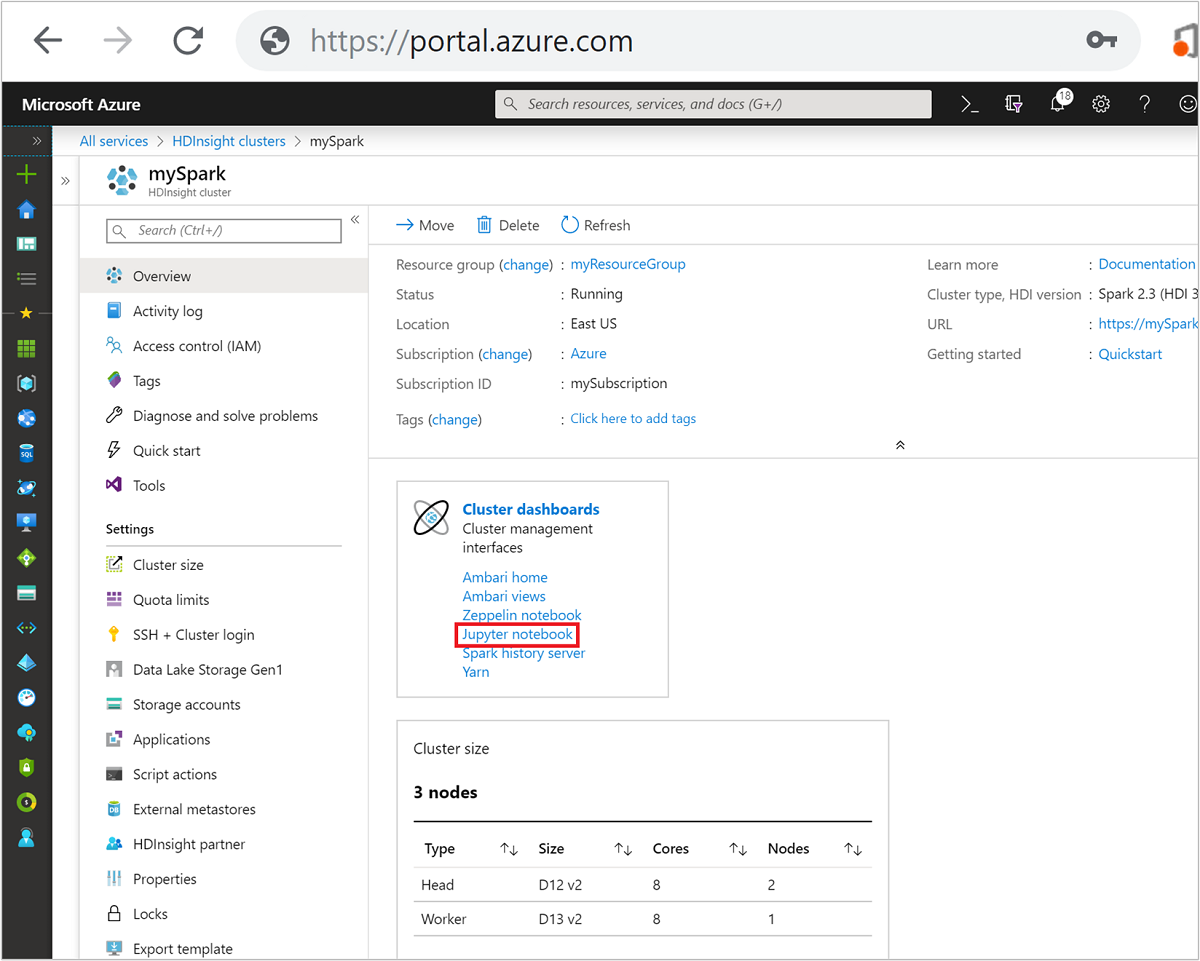
Dari portal Microsoft Azure, pilih kluster Spark Anda. Lihat Mencantumkan dan memperlihatkan kluster untuk instruksi. Tampilan Gambaran Umum terbuka.
Dari tampilan Gambaran Umum, dalam kotak, Dasbor kluster pilih Notebook Jupyter. Jika diminta, masukkan kredensial admin untuk klaster.
Catatan
Anda juga dapat mencapai kluster Jupyter Notebook on Spark dengan membuka URL berikut di browser Anda. Ganti CLUSTERNAME dengan nama kluster Anda:
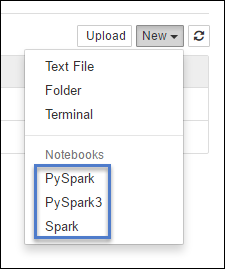
https://CLUSTERNAME.azurehdinsight.net/jupyterPilih Baru, lalu pilih Pyspark, PySpark3, atau Spark untuk membuat buku catatan. Gunakan kernel Spark untuk aplikasi Scala, kernel PySpark untuk aplikasi Python2, dan kernel PySpark3 untuk aplikasi Python3.
Catatan
Untuk Spark 3.1, hanya PySpark3, atau Spark yang akan tersedia.
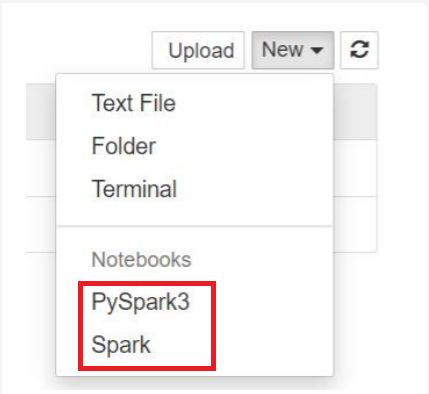
- Buku catatan terbuka dengan kernel yang Anda pilih.
Manfaat menggunakan kernel
Berikut adalah beberapa manfaat menggunakan kernel baru dengan Jupyter Notebook pada kluster Spark HDInsight.
Konteks yang telah ditetapkan. Dengan kernel PySpark, PySpark3, atau Spark, Anda tidak perlu mengatur konteks Spark atau Apache Hive secara eksplisit sebelum mulai bekerja dengan aplikasi Anda. Konteks ini tersedia secara default. Konteks ini adalah:
sc - untuk konteks Spark
sqlContext - untuk konteks Apache Hive
Jadi, Anda tidak perlu menjalankan pernyataan seperti berikut ini untuk mengatur konteks:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)Sebagai gantinya, Anda dapat langsung menggunakan konteks yang telah disiapkan di aplikasi Anda.
Cell magics. Kernel PySpark menyediakan beberapa "keajaiban" yang telah ditentukan sebelumnya, yang merupakan perintah khusus yang dapat Anda panggil dengan
%%(misalnya,%%MAGIC<args>). Perintah magic harus menjadi kata pertama dalam sel kode dan memungkinkan beberapa baris konten. Kata ajaib harus menjadi kata pertama dalam sel. Tambahkan apa pun sebelum magic, bahkan komentar, menyebabkan kesalahan. Untuk informasi lebih lanjut tentang magic, lihat di sini.Tabel berikut ini mencantumkan berbagai magic yang tersedia melalui kernel.
Magic Contoh Deskripsi bantuan %%helpMenghasilkan tabel semua magic yang tersedia dengan contoh dan deskripsi info %%infoKeluaran informasi sesi untuk titik akhir Livy saat ini konfigurasi %%configure -f{"executorMemory": "1000M","executorCores": 4}Mengonfigurasi parameter untuk membuat sesi. Bendera pasukan( -f) wajib jika sesi telah dibuat, yang memastikan bahwa sesi dijatuhkan dan dibuat kembali. Lihatlah Livy's POST / sesi Request Body untuk daftar parameter yang valid. Parameter harus diteruskan sebagai string JSON dan harus berada di baris berikutnya setelah magic, seperti yang ditunjukkan di kolom contoh.Sql %%sql -o <variable name>
SHOW TABLESMenjalankan kueri Apache Hive terhadap sqlContext. Jika -oparameter dilewatkan, hasil kueri tetap ada dalam konteks Python lokal %%sebagai dataframe Pandas.Lokal %%locala=1Semua kode di baris selanjutnya dijalankan secara lokal. Kode harus valid kode Python2 tidak peduli kernel mana yang Anda gunakan. Jadi, bahkan jika Anda memilih kernel PySpark3 atau Spark saat membuat buku catatan, jika Anda menggunakan %%localmagic dalam sel, sel itu hanya boleh memiliki kode Python2 yang valid.logs %%logsMengeluarkan log untuk sesi Livy saat ini. hapus %%delete -f -s <session number>Menghapus sesi tertentu dari titik akhir Livy saat ini. Anda tidak dapat menghapus sesi yang dimulai untuk kernel itu sendiri. Pembersihan %%cleanup -fMenghapus semua sesi untuk titik akhir Livy saat ini, termasuk sesi buku catatan ini. Bendera pasukan -f adalah wajib. Catatan
Selain magic yang ditambahkan oleh kernel PySpark, Anda juga dapat menggunakan magic IPython bawaan, termasuk
%%sh. Anda dapat menggunakan%%shmagic untuk menjalankan skrip dan blok kode pada headnode kluster.Visualisasi otomatis. Kernel Pyspark secara otomatis memvisualisasikan output kueri Apache Hive dan SQL. Anda dapat memilih antara beberapa tipe visualisasi yang berbeda termasuk Tabel, Pai, Garis, Area, Bilah.
Parameter yang didukung dengan %%sql magic
Magic %%sql mendukung berbagai parameter yang dapat Anda gunakan untuk mengontrol jenis output yang Anda terima saat menjalankan kueri. Tabel berikut ini mencantumkan output.
| Parameter | Contoh | Deskripsi |
|---|---|---|
| o- | -o <VARIABLE NAME> |
Gunakan parameter ini untuk bertahan pada hasil kueri, dalam konteks %%local Python, sebagai dataframe Pandas. Nama variabel dataframe merupakan nama variabel yang Anda tentukan. |
| -q | -q |
Gunakan parameter ini untuk menonaktifkan visualisasi untuk sel. Jika Anda tidak ingin secara memvisualisasi otomatis konten sel dan hanya ingin mengambilnya sebagai dataframe, maka gunakan -q -o <VARIABLE>. Jika Anda ingin menonaktifkan visualisasi tanpa menangkap hasilnya (misalnya, untuk menjalankan kueri SQL, seperti pernyataan CREATE TABLE), gunakan -q tanpa menentukan -o argumen. |
| -m | -m <METHOD> |
Di manaMETHOD baik mengambil atau mengambil sampel (defaultnya adalah mengambil). Jika metodenya adalah take, kernel memilih elemen dari bagian atas set data hasil yang ditentukan oleh MAXROWS (dijelaskan nanti di dalam tabel ini). Jika metode ini adalah mengambil sampel, kernel secara acak mengambil sampel elemen dari kumpulan data sesuai -r dengan parameter, dijelaskan berikutnya dalam tabel ini. |
| \r | -r <FRACTION> |
Di sini FRACTION adalah angka floating-point antara 0,0 dan 1,0. Jika metode sampel untuk kueri SQL adalah sample, maka kernel secara acak mencicipi pecahan yang ditentukan dari elemen hasil yang ditetapkan untuk Anda. Misalnya, jika Anda menjalankan kueri SQL dengan argumen -m sample -r 0.01, maka 1% dari baris hasil diambil sampelnya secara acak. |
| -n | -n <MAXROWS> |
MAXROWS adalah nilai bilangan bulat. Kernel membatasi jumlah baris output ke MAXROWS. Jika MAXROWS adalah angka negatif seperti -1, maka jumlah baris dalam kumpulan hasil tidak terbatas. |
Contoh:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
Pernyataan di atas melakukan tindakan berikut:
- Memilih semua rekaman dari hivesampletable.
- Karena kita menggunakan -q, itu akan mematikan autovisualisasi.
- Karena kita menggunakan
-m sample -r 0.1 -n 500, itu secara acak sampel 10% dari baris hivesampletable dan membatasi ukuran hasil yang ditetapkan untuk 500 baris. - Akhirnya, karena kami
-o query2menggunakannya juga menyimpan output ke dalam dataframe yang disebut query2.
Pertimbangan saat menggunakan kernel baru
Kernel apa pun yang Anda gunakan, membiarkan buku catatan yang tereksekusi akan mengkonsumsi sumber daya kluster. Dengan kernel ini, karena konteksnya sudah ditetapkan, sekedar keluar dari buku catatan tidak akan membunuh konteks. Sehingga sumber daya kluster terus digunakan. Praktik yang baik adalah menggunakan opsi Tutup dan Hentikan dari menu File buku catatan saat Anda selesai menggunakan buku catatan. Penutupan akan membunuh konteks dan kemudian keluar dari buku catatan.
Di mana buku catatan disimpan?
Jika kluster Anda menggunakan Microsoft Azure Storage sebagai akun penyimpanan default, Jupyter Notebooks disimpan ke akun penyimpanan di bawah folder /HdiNotebooks. Buku catatan, file teks, dan folder yang Anda buat dari dalam Jupyter dapat diakses dari akun penyimpanan. Misalnya, jika Anda menggunakan Jupyter untuk membuat folder myfolder dan buku catatan myfolder/mynotebook.ipynb, Anda dapat mengakses buku catatan itu /HdiNotebooks/myfolder/mynotebook.ipynb di dalam akun penyimpanan. Sebaliknya juga benar, yaitu, jika Anda mengunggah buku catatan langsung ke akun penyimpanan Anda di, /HdiNotebooks/mynotebook1.ipynb buku catatan juga terlihat dari Jupyter. Buku catatan tetap berada di akun penyimpanan bahkan setelah kluster dihapus.
Catatan
Kluster HDInsight dengan Azure Data Lake Storage sebagai penyimpanan default tidak menyimpan buku catatan dalam penyimpanan terkait.
Cara notebook disimpan ke akun penyimpanan kompatibel dengan APACHE Hadoop HDFS. Jika Anda SSH ke dalam kluster, Anda dapat menggunakan perintah manajemen file:
| Perintah | Deskripsi |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Daftar semuanya di direktori root - semua yang ada di direktori ini terlihat oleh Jupyter dari halaman beranda |
hdfs dfs –copyToLocal /HdiNotebooks |
# Unduh konten folder Buku HdiNote |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Unggah contoh notebook.ipynb ke folder root sehingga terlihat dari Jupyter |
Apakah kluster menggunakan Azure Storage atau Azure Data Lake Storage sebagai akun penyimpanan default, buku catatan juga disimpan di headnode kluster di /var/lib/jupyter.
Browser yang didukung
Jupyter Notebook di kluster Spark HDInsight hanya didukung di Google Chrome.
Saran
Kernel baru berada dalam tahap berkembang dan akan matang dari waktu ke waktu. Jadi API bisa berubah saat kernel ini matang. Kami akan menghargai umpan balik apa pun yang Anda miliki selama menggunakan kernel baru ini. Umpan balik berguna dalam membentuk rilis akhir kernel ini. Anda dapat meninggalkan komentar/umpan balik Anda di bagian Umpan Balik di bagian bawah artikel ini.