Gunakan Notebook Apache Zeppelin dengan Apache Spark pada Azure HDInsight
Klaster HDInsight Spark mencakup notebook Apache Zeppelin. Gunakan notebook untuk menjalankan pekerjaan Apache Spark. Dalam artikel ini, Anda mempelajari cara menggunakan notebook Zeppelin pada klaster HDInsight.
Prasyarat
- Klaster Apache Spark pada HDInsight. Untuk petunjuk selengkapnya, lihat Membuat kluster Apache Spark di Microsoft Azure HDInsight.
- Skema URI untuk penyimpanan utama kluster Anda. Skema yang digunakan adalah
wasb://untuk Azure Blob Storage,abfs://untuk Azure Data Lake Storage Gen2 atauadl://untuk Azure Data Lake Storage Gen1. Jika transfer aman diaktifkan untuk Blob Storage, URI akan menjadiwasbs://. Untuk informasi selengkapnya, lihat Memerlukan transfer aman di Azure Storage.
Meluncurkan notebook Apache Zeppelin
Dari Ikhtisar klaster Spark, pilih Notebook Zeppelin dari Dasbor klaster. Masukkan kredensial admin untuk klaster.
Catatan
Anda juga dapat meraih Zeppelin Notebook untuk klaster Anda dengan membuka URL berikut di browser Anda. Ganti CLUSTERNAME dengan nama kluster Anda:
https://CLUSTERNAME.azurehdinsight.net/zeppelinBuat notebook baru. Dari panel header, arahkan ke Notebook>Buat catatan baru.
Masukkan nama untuk notebook, lalu pilih Buat Catatan.
Pastikan header notebook menampilkan status tersambung. Hal ini ditandai dengan titik hijau di sudut kanan atas.
Muat data sampel ke dalam tabel sementara. Saat Anda membuat klaster Spark di HDInsight, file data sampel,
hvac.csv, disalin ke akun penyimpanan terkait di bawah\HdiSamples\SensorSampleData\hvac.Di paragraf kosong yang dibuat secara default di notebook baru, tempelkan cuplikan berikut ini.
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Tekan SHIFT + ENTER atau pilih tombol Putar untuk paragraf guna menjalankan cuplikan. Status di sudut kanan paragraf harus berlangsung dari SIAP, DITUNDA, BERJALAN hingga SELESAI. Output muncul di bagian bawah paragraf yang sama. Cuplikan layar terlihat seperti gambar berikut:
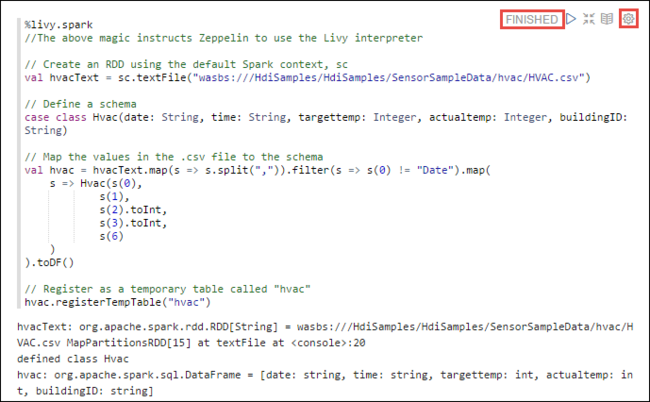
Anda juga dapat memberikan judul untuk setiap paragraf. Dari sudut kanan paragraf, pilih ikon Pengaturan (sprocket), lalu pilih Tampilkan judul
Catatan
%spark2 interpreter tidak didukung di notebook Zeppelin di semua versi HDInsight, dan %sh interpreter tidak akan didukung mulai dari HDInsight 4.0 dan seterusnya.
Anda sekarang dapat menjalankan pernyataan Spark SQL pada tabel
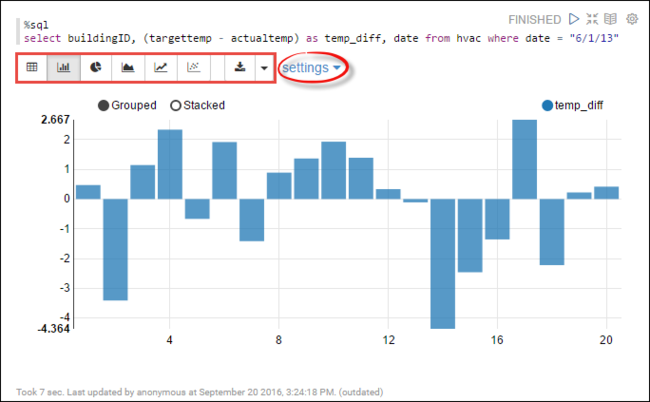
hvac. Tempelkan kueri berikut ini dalam paragraf baru. Kueri mengambil ID bangunan. Juga perbedaan antara suhu target dan yang sebenarnya untuk setiap bangunan pada tanggal tertentu. Tekan SHIFT + ENTER.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"Pernyataan %sql pada awalnya memberi tahu notebook untuk menggunakan interpreter Livy Scala.
Pilih ikon Bagan Bilah untuk mengubah tampilan. pengaturan muncul setelah Anda memilih Bagan Batang, memungkinkan Anda memilih Kunci, dan Nilai. Cuplikan layar berikut menampilkan output.
Anda juga dapat menjalankan pernyataan Spark SQL menggunakan variabel dalam kueri. Cuplikan berikutnya menampilkan cara menentukan variabel,
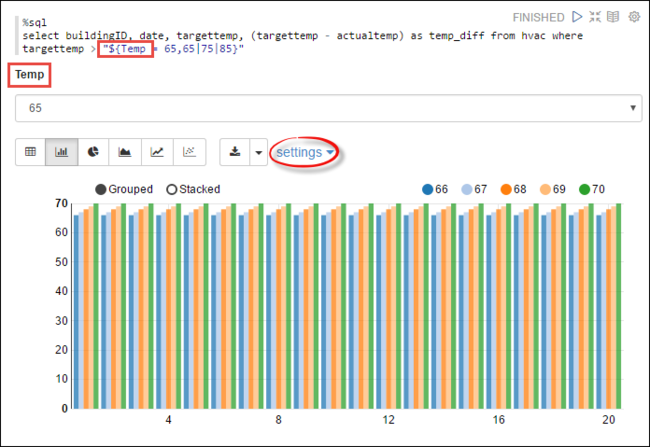
Temp, dalam kueri dengan nilai yang mungkin ingin Anda kueri. Saat Anda pertama kali menjalankan kueri, tarik turun secara otomatis diisi dengan nilai yang Anda tentukan untuk variabel.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Tempelkan cuplikan ini di paragraf baru dan tekan SHIFT + ENTER. Lalu pilih 65 dari daftar tarik turun Suhu.
Pilih ikon Bagan Bilah untuk mengubah tampilan. Kemudian pilih pengaturan dan buat perubahan berikut:
Grup: Tambahkan targettemp.
Nilai: 1. Hapus tanggal. 2. Tambahkan temp_diff. 3. Ubah agregator dari SUM ke AVG.
Cuplikan layar berikut menampilkan output.
Bagaimana cara menggunakan paket eksternal dengan notebook?
Notebook Zeppelin di klaster Apache Spark pada HDInsight dapat menggunakan paket eksternal dari kontribusi komunitas yang tidak termasuk dalam klaster. Cari repositori Maven untuk daftar lengkap paket yang tersedia. Anda juga bisa mendapatkan daftar paket yang tersedia dari sumber lain. Misalnya, daftar lengkap paket yang berkontribusi komunitas tersedia di Paket Spark.
Dalam artikel ini, Anda akan melihat cara menggunakan paket spark-csv dengan Jupyter Notebook.
Buka pengaturan interpreter. Dari sudut kanan atas, pilih nama pengguna yang masuk, lalu pilih Interpreter.
Gulirkan ke livy2, lalu pilih edit.
Arahkan ke kunci
livy.spark.jars.packages, dan atur nilainya dalam formatgroup:id:version. Jadi, jika Anda ingin menggunakan paket spark-csv, Anda harus mengatur nilai kunci kecom.databricks:spark-csv_2.10:1.4.0.
Pilih Simpan lalu OK untuk memulai ulang interpreter Livy.
Jika Anda ingin memahami cara mengetahui nilai kunci yang dimasukkan di atas, berikut caranya.
a. Cari paket di Repositori Maven. Untuk artikel ini, kami menggunakan spark-csv.
b. Dari repositori, kumpulkan nilai untuk GroupId, ArtifactId, dan Versi.
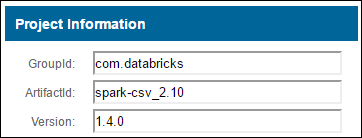
c. Gabungkan tiga nilai, yang dipisahkan oleh titik dua (:).
com.databricks:spark-csv_2.10:1.4.0
Di mana notebook Zeppelin disimpan?
Notebook Zeppelin disimpan ke headnode klaster. Jadi, jika Anda menghapus klaster, notebook juga akan dihapus. Jika Anda ingin melestarikan notebook Anda untuk digunakan nantinya pada klaster lain, Anda harus mengekspornya setelah Anda selesai menjalankan pekerjaan. Untuk mengekspor notebook, pilih ikon Ekspor seperti yang ditampilkan di gambar di bawah ini.
Tindakan ini menyimpan notebook sebagai file JSON di lokasi unduhan Anda.
Catatan
Dalam HDI 4.0, jalur direktori notebook zeppelin adalah,
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/Mis. /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Di mana seperti dalam HDI 5.0 dan di atas jalur ini berbeda
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/Mis. /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
Nama file yang disimpan berbeda dalam HDI 5.0. Ini disimpan sebagai
<notebook_name>_<sessionid>.zplnMis. testzeppelin_2JJK53XQA.zpln
Dalam HDI 4.0, nama file hanya note.json disimpan di bawah direktori session_id.
Mis. /2JMC9BZ8X/note.json
HDI Zeppelin selalu menyimpan notebook di jalur
/usr/hdp/<version>/zeppelin/notebook/di disk lokal hn0.Jika Anda ingin buku catatan tersedia bahkan setelah penghapusan kluster, Anda dapat mencoba menggunakan penyimpanan file azure (Menggunakan protokol SMB ) dan menautkannya ke jalur lokal. Untuk detail selengkapnya, lihat Memasang berbagi file Azure SMB di Linux
Setelah memasangnya, Anda dapat memodifikasi konfigurasi zeppelin zeppelin.notebook.dir ke jalur yang dipasang di Ambari UI.
- Fileshare SMB sebagai penyimpanan GitNotebookRepo tidak disarankan untuk zeppelin versi 0.10.1
Menggunakan Shiro untuk Mengonfigurasi Akses ke Interpreter Zeppelin di Klaster Enterprise Security Package (ESP)
Seperti disebutkan di atas, interpreter %sh tidak didukung mulai dari HDInsight 4.0 dan seterusnya. Selain itu, karena interpreter %sh memperkenalkan masalah keamanan potensial, seperti perintah shell penggunaan keytab akses, interpreter juga telah dihapus dari klaster ESP HDInsight 3.6. Artinya interpreter %sh tidak tersedia saat mengeklik Buat catatan baru atau di UI Interpreter secara default.
Pengguna domain istimewa dapat menggunakan file Shiro.ini untuk mengontrol akses ke UI Interpreter. Hanya pengguna ini yang dapat membuat interpreter %sh baru dan mengatur izin pada setiap interpreter %sh baru. Untuk mengontrol akses menggunakan file shiro.ini, gunakan langkah-langkah berikut:
Tentukan peran baru menggunakan nama grup domain yang sudah ada. Dalam contoh berikut,
adminGroupNameadalah sekelompok pengguna istimewa di AAD. Jangan menggunakan karakter khusus atau spasi putih dalam nama grup. Karakter setelah=memberikan izin untuk peran ini.*berarti grup memiliki izin penuh.[roles] adminGroupName = *Tambahkan peran baru untuk akses ke interpreter Zeppelin. Dalam contoh berikut, semua pengguna di
adminGroupNamediberi akses ke interpreter Zeppelin dan dapat membuat interpreter baru. Anda bisa menempatkan beberapa peran di antara tanda kurung diroles[], yang dipisahkan oleh koma. Kemudian, pengguna yang memiliki izin yang diperlukan, dapat mengakses interpreter Zeppelin.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Contoh shiro.ini untuk beberapa grup domain:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Manajemen sesi Livy
Paragraf kode pertama di notebook Zeppelin Anda membuat sesi Livy baru di klaster Anda. Sesi ini dibagikan melintasi semua notebook Zeppelin yang nantinya Anda buat. Jika sesi Livy dimatikan karena alasan apa pun, pekerjaan tidak akan berjalan dari notebook Zeppelin.
Jika demikian, Anda harus melakukan langkah-langkah berikut sebelum Anda bisa mulai menjalankan pekerjaan dari notebook Zeppelin.
Mulai ulang interpreter Livy dari notebook Zeppelin. Untuk melakukannya, buka pengaturan interpreter dengan memilih nama pengguna yang masuk dari sudut kanan atas, lalu pilih Interpreter.
Gulirkan ke livy2, lalu pilih mulai ulang.
Jalankan sel kode dari notebook Zeppelin yang ada. Kode ini membuat sesi Livy baru di kluster HDInsight.
Informasi Umum
Memvalidasi layanan
Untuk memvalidasi layanan dari Ambari, arahkan ke https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary di mana CLUSTERNAME adalah nama klaster Anda.
Untuk memvalidasi layanan dari baris perintah, SSH ke headnode. Alihkan pengguna ke zeppelin menggunakan perintah sudo su zeppelin. Perintah status:
| Perintah | Deskripsi |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Status layanan. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Versi layanan. |
ps -aux | grep zeppelin |
Identifikasi PID. |
Lokasi log
| Layanan | Jalur |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Log Server | /var/log/zeppelin |
Penerjemah Konfigurasi, Shiro, site.xml, log4j |
/usr/hdp/current/zeppelin-server/conf atau /etc/zeppelin/conf |
| Direktori PID | /var/run/zeppelin |
Mengaktifkan pengelogan debug
Arahkan ke
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summarydi mana CLUSTERNAME adalah nama klaster Anda.Arahkan ke CONFIGS>zeppelin-log4j-properties Tingkat Lanjut>log4j_properties_content.
Modifikasi
log4j.appender.dailyfile.Threshold = INFOkelog4j.appender.dailyfile.Threshold = DEBUG.Tambahkan
log4j.logger.org.apache.zeppelin.realm=DEBUG.Simpan perubahan dan mulai ulang layanan.