Menyiapkan AutoML untuk melatih model prakiraan rangkaian waktu dengan Python (SDKv1)
BERLAKU UNTUK: SDK Python azureml v1
SDK Python azureml v1
Dalam artikel ini, Anda mempelajari cara menyiapkan pelatihan AutoML untuk model perkiraan rangkaian waktu dengan ML otomatis Azure Machine Learning di Azure Machine Learning Python SDK.
Untuk melakukannya, Anda perlu:
- Menyiapkan data untuk pemodelan rangkaian waktu.
- Mengonfigurasi parameter rangkaian waktu tertentu dalam objek
AutoMLConfig. - Menjalankan prediksi dengan data rangkaian waktu.
Untuk pengalaman minim kode, lihat Tutorial: Memperkirakan permintaan dengan pembelajaran mesin otomatis untuk contoh perkiraan rangkaian waktu menggunakan ML otomatis di studio Azure Machine Learning.
Tidak seperti metode rangkaian waktu klasik, dalam ML otomatis, nilai rangkaian waktu sebelumnya "dipivot" untuk menjadi dimensi tambahan bagi regresor bersama dengan prediktor lain. Pendekatan ini menggabungkan beberapa variabel kontekstual dan hubungannya satu sama lain selama pelatihan. Karena beberapa faktor dapat mempengaruhi perkiraan, metode ini selaras dengan skenario perkiraan di dunia nyata. Misalnya, ketika memperkirakan penjualan, interaksi tren di masa lampau, nilai tukar, dan harga semuanya bersama-sama mendorong hasil penjualan.
Prasyarat
Untuk artikel ini Anda memerlukan,
Ruang kerja Azure Machine Learning. Untuk membuat ruang kerja, lihat Membuat sumber daya ruang kerja.
Dengan mengikuti artikel ini, Anda diasumsikan memiliki pemahaman akan penyiapan percobaan pembelajaran mesin otomatis. Ikuti petunjuk untuk melihat pola desain percobaan pembelajaran mesin otomatis utama.
Penting
Perintah Python dalam artikel ini memerlukan versi paket
azureml-train-automlterbaru.- Pasang paket
azureml-train-automlterbaru ke lingkungan lokal Anda. - Untuk detail tentang paket
azureml-train-automlterbaru, lihat catatan rilis.
- Pasang paket
Data pelatihan dan validasi
Perbedaan paling penting antara jenis tugas regresi prakiraan dan jenis tugas regresi dalam ML otomatis mencakup fitur dalam data pelatihan Anda yang mewakili rangkaian waktu yang valid. Rangkaian waktu reguler memiliki frekuensi yang terdefinisi dengan baik dan konsisten, serta memiliki nilai di setiap titik sampel dalam rentang waktu berkelanjutan.
Penting
Saat melatih model untuk memperkirakan nilai masa depan, pastikan semua fitur yang digunakan dalam pelatihan dapat digunakan saat menjalankan prediksi untuk cakrawala yang Anda maksudkan. Misalnya, saat membuat perkiraan permintaan, menyertakan fitur untuk harga saham saat ini dapat secara besar-besaran meningkatkan akurasi pelatihan. Namun, jika Anda berniat untuk memperkirakan dengan cakrawala yang panjang, Anda mungkin tidak dapat memprediksi nilai saham di masa depan secara akurat sesuai dengan poin rangkaian waktu di masa depan, dan akurasi model dapat menurun.
Anda dapat menentukan data pelatihan dan kumpulan data validasi terpisah secara langsung di objek AutoMLConfig. Pelajari AutoMLConfig lebih lanjut.
Untuk prakiraan rangkaian waktu, hanya Rolling Origin Cross Validation (ROCV) yang digunakan untuk validasi secara default. ROCV membagi rangkaian menjadi data pelatihan dan validasi menggunakan titik waktu asal. Menggeser asal-usul tepat waktu menghasilkan lipatan validasi silang. Strategi ini mempertahankan integritas data rangkaian waktu dan menghilangkan risiko kebocoran data.
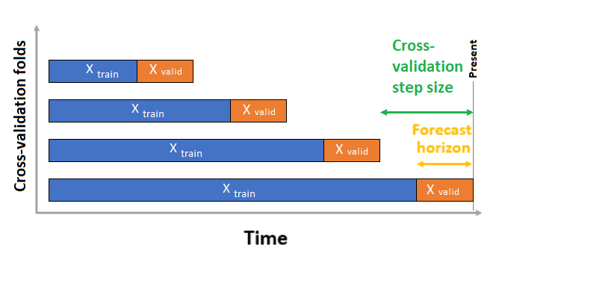
Teruskan data pelatihan dan validasi Anda sebagai satu himpunan data ke parameter training_data. Atur jumlah lipatan validasi silang dengan parameter n_cross_validations dan atur jumlah periode antara dua lipatan validasi silang berturut-turut dengan cv_step_size. Anda juga dapat membiarkan atau kedua parameter kosong dan AutoML mengaturnya secara otomatis.
BERLAKU UNTUK:SDK Python azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Anda juga dapat membawa data validasi Anda sendiri, pelajari lebih lanjut dalam Mengonfigurasi pemisahan data dan validasi silang di AutoML.
Pelajari lebih lanjut cara AutoML menerapkan validasi silang untuk mencegah model over-fitting.
Mengonfigurasi eksperimen
Objek AutoMLConfig menentukan pengaturan dan data yang diperlukan untuk tugas pembelajaran mesin otomatis. Konfigurasi untuk model perkiraan mirip dengan pengaturan model regresi standar, tetapi model, opsi konfigurasi, dan langkah-langkah fiturisasi tertentu ada khusus untuk data rangkaian waktu.
Model yang didukung
Pembelajaran mesin otomatis secara otomatis mencoba berbagai model dan algoritma sebagai bagian dari proses pembuatan dan penyetelan model. Sebagai pengguna, Anda tidak perlu menentukan algoritma. Untuk percobaan perkiraan, baik rangkaian waktu asli maupun model pembelajaran mendalam adalah bagian dari sistem rekomendasi.
Tip
Model regresi tradisional juga diuji sebagai bagian dari sistem rekomendasi untuk percobaan perkiraan. Lihat daftar lengkap model yang didukung dalam dokumentasi referensi SDK.
Pengaturan konfigurasi
Mirip dengan masalah regresi, Anda menentukan parameter pelatihan standar seperti jenis tugas, jumlah iterasi, data pelatihan, dan jumlah validasi silang. Tugas prakiraan memerlukan parameter time_column_name dan forecast_horizon untuk mengonfigurasi eksperimen Anda. Jika data menyertakan beberapa rangkaian waktu, seperti data penjualan untuk beberapa toko atau data energi di berbagai negara, ML otomatis secara otomatis mendeteksi ini dan mengatur parameter time_series_id_column_names (pratinjau) untuk Anda. Anda juga dapat menyertakan parameter tambahan untuk mengonfigurasi eksekusi Anda dengan lebih baik, lihat bagian konfigurasi opsional untuk detail lebih lanjut tentang apa yang dapat disertakan.
Penting
Identifikasi rangkaian waktu otomatis saat ini dalam pratinjau umum. Versi pratinjau ini disediakan tanpa perjanjian tingkat layanan. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
| Nama Parameter | Deskripsi |
|---|---|
time_column_name |
Digunakan untuk menentukan kolom datetime dalam data input yang digunakan untuk membangun rangkaian waktu dan menyimpulkan frekuensinya. |
forecast_horizon |
Menentukan berapa banyak periode ke depan yang ingin Anda perkirakan. Cakrawala berada dalam satuan frekuensi rangkaian waktu. Satuan didasarkan pada interval waktu data pelatihan Anda, misalnya, bulanan, mingguan yang harus diprediksi oleh peramal. |
Kode berikut,
ForecastingParametersMenggunakan kelas untuk menentukan parameter prakiraan untuk pelatihan eksperimen Anda- Mengatur
time_column_nameke bidangday_datetimedalam himpunan data. - Mengatur
forecast_horizonhingga 50 untuk memprediksi seluruh set pengujian.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Kemudian forecasting_parameters diteruskan ke objek AutoMLConfig standar Anda bersama dengan jenis tugas forecasting, metrik utama, kriteria keluar, dan data pelatihan.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
Jumlah data yang diperlukan untuk berhasil melatih model perkiraan dengan ML otomatis dipengaruhi oleh forecast_horizon, n_cross_validations, dan target_lags atau nilai target_rolling_window_size yang ditentukan saat Anda mengonfigurasi AutoMLConfig.
Rumus berikut menghitung jumlah data historis yang akan diperlukan untuk membangun fitur rangkaian waktu.
Data historis minimum yang diperlukan: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Dinaikkan Error exception untuk seri apa pun dalam himpunan data yang tidak memenuhi jumlah data historis yang diperlukan untuk pengaturan yang relevan yang ditentukan.
Langkah-langkah featurisasi
Dalam setiap eksperimen pembelajaran mesin otomatis, penskalaan otomatis dan teknik normalisasi diterapkan ke data Anda secara default. Teknik-teknik ini adalah jenis featurisasi yang membantu algoritma tertentu yang sensitif terhadap fitur pada skala yang berbeda. Pelajari lebih lanjut langkah-langkah featurisasi default dalam Fiturisasi di AutoML
Namun, langkah-langkah berikut ini dilakukan hanya untuk jenis tugas forecasting:
- Deteksi frekuensi sampel rangkaian waktu (misalnya, per jam, harian, mingguan) dan buat rekaman baru untuk titik waktu absen untuk membuat rangkaian berkelanjutan.
- Memperhitungkan nilai yang hilang dalam target (melalui isi maju) dan kolom fitur (menggunakan nilai kolom median)
- Membuat fitur berdasarkan pengidentifikasi rangkaian waktu untuk mengaktifkan efek tetap di berbagai rangkaian
- Membuat fitur berbasis waktu untuk membantu mempelajari pola musiman
- Mengkodekan variabel kategoris ke jumlah numerik
- Deteksi rangkaian waktu nonstationary dan secara otomatis berbeda untuk mengurangi dampak akar unit.
Untuk melihat daftar lengkap kemungkinan fitur rekayasa yang dihasilkan dari data rangkaian waktu, lihat Kelas TimeIndexFeaturizer.
Catatan
Langkah-langkah fiturisasi pembelajaran mesin otomatis (normalisasi fitur, penanganan data yang hilang, mengonversi teks menjadi numerik, dll.) menjadi bagian dari model yang mendasari. Saat menggunakan model untuk prediksi, langkah-langkah fiturisasi yang sama dan diterapkan selama pelatihan akan diterapkan ke data input Anda secara otomatis.
Menyesuaikan fiturisasi
Anda juga memiliki opsi untuk menyesuaikan pengaturan fiturisasi guna memastikan bahwa data dan fitur yang digunakan untuk melatih model ML menghasilkan prediksi yang relevan.
Kustomisasi yang didukung untuk tugas forecasting meliputi:
| Penyesuaian | Definisi |
|---|---|
| Pembaruan tujuan kolom | Mengganti jenis fitur yang terdeteksi otomatis untuk kolom yang ditentukan. |
| Pembaruan parameter transformator | Memperbarui parameter untuk transformator yang ditentukan. Saat ini mendukung Imputer (fill_value dan median). |
| Membuat kolom | Menentukan kolom untuk dihilangkan agar tidak ditampilkan. |
Untuk menyesuaikan fiturisasi dengan SDK, tentukan "featurization": FeaturizationConfig di objek AutoMLConfig Anda. Pelajari lebih lanjut fiturisasi kustom.
Catatan
Fungsi hilangkan kolom dihentikan pada SDK versi 1.19. Hilangkan kolom dari himpunan data Anda sebagai bagian dari pembersihan data, sebelum menggunakannya dalam percobaan ML otomatis.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Jika Anda menggunakan studio Azure Machine Learning untuk percobaan, lihat cara menyesuaikan fiturisasi di studio.
Konfigurasi opsional
Konfigurasi opsional lainnya tersedia untuk tugas prakiraan, seperti mengaktifkan pembelajaran mendalam dan menentukan agregasi jendela bergulir target. Daftar lengkap lebih banyak parameter tersedia dalam dokumentasi referensi ForecastingParameters SDK.
Agregasi data frekuensi & target
Gunakan frekuensi, freqparameter , untuk membantu menghindari kegagalan yang disebabkan oleh data yang tidak teratur. Data tidak teratur mencakup data yang tidak mengikuti irama yang ditetapkan, seperti data per jam atau harian.
Untuk data yang sangat tidak teratur atau untuk berbagai kebutuhan bisnis, pengguna dapat secara opsional mengatur frekuensi perkiraan yang mereka inginkan, freq, dan menentukan target_aggregation_function untuk mengagregasi kolom target dari rangkaian waktu. Gunakan kedua pengaturan ini di objek Anda AutoMLConfig dapat membantu menghemat waktu pada persiapan data.
Operasi agregasi yang didukung untuk nilai kolom target meliputi:
| Function | Deskripsi |
|---|---|
sum |
Jumlah nilai target |
mean |
Nilai tengah atau rata-rata nilai target |
min |
Nilai minimum target |
max |
Nilai maksimum target |
Mengaktifkan pembelajaran mendalam
Catatan
Dukungan DNN untuk perkiraan dalam Pembelajaran Mesin Otomatis sedang dipratinjau dan tidak didukung untuk proses lokal atau proses yang dimulai di Databricks.
Anda juga dapat menerapkan pembelajaran mendalam dengan jaringan neural mendalam, DNN, untuk meningkatkan skor model Anda. Pembelajaran mendalam ML otomatis memungkinkan untuk memperkirakan data rangkaian waktu univariat dan multivariat.
Model pembelajaran mendalam memiliki tiga kemampuan intrinsik:
- Model dapat belajar dari pemetaan arbitrer dari input ke output
- Model mendukung beberapa input dan output
- Model dapat secara otomatis mengekstrak pola dalam data input yang mencakup urutan panjang.
Untuk mengaktifkan pembelajaran mendalam, atur enable_dnn=True dalam objek AutoMLConfig.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Peringatan
Saat Anda mengaktifkan DNN untuk percobaan yang dibuat dengan SDK, penjelasan model terbaik dinonaktifkan.
Untuk mengaktifkan DNN untuk eksperimen AutoML yang dibuat di studio Azure Machine Learning, lihat Cara pengaturan jenis tugas di antarmuka pengguna studio.
Agregasi jendela bergulir target
Seringkali informasi terbaik untuk prakiraan adalah nilai terbaru dari target. Agregasi jendela bergulir target memungkinkan Anda menambahkan agregasi bergulir nilai data sebagai fitur. Membuat dan menggunakan fitur-fitur ini sebagai data kontekstual tambahan membantu akurasi model pelatihan.
Misalnya, Anda ingin memprediksi permintaan energi. Anda mungkin ingin menambahkan fitur jendela bergulir selama tiga hari untuk memperhitungkan perubahan termal di ruang berpemanas. Dalam contoh ini, buat jendela ini dengan mengatur target_rolling_window_size= 3 di konstruktor AutoMLConfig.
Tabel memperlihatkan rekayasa fitur yang dihasilkan yang terjadi saat agregasi jendela diterapkan. Kolom untuk minimum, maksimum, dan jumlah dihasilkan pada jendela geser tiga berdasarkan pengaturan yang ditentukan. Setiap baris memiliki fitur terhitung baru, dalam hal tanda waktu untuk 8 September 2017 04:00, nilai maksimum, minimum, dan jumlah dihitung menggunakan nilai permintaan untuk 8 September 2017 01:00 - 03:00. Jendela tiga ini bertukar untuk mengisi data pada baris yang tersisa.

Lihat contoh kode Python yang menerapkan fitur agregat jendela bergulir target.
Penanganan rangkaian singkat
ML otomatis menganggap rangkaian waktu sebagai seri pendek jika tidak ada cukup poin data untuk melakukan fase pelatihan dan validasi pengembangan model. Jumlah titik data bervariasi untuk setiap eksperimen, dan tergantung pada max_horizon, jumlah pemisahan validasi silang, dan panjang model lookback, yaitu maksimum riwayat yang diperlukan untuk membangun fitur rangkaian waktu.
ML otomatis menawarkan penanganan rangkaian singkat secara default dengan parameter short_series_handling_configuration dalam objek ForecastingParameters.
Untuk mengaktifkan penanganan rangkaian singkat, parameter freq juga harus ditentukan. Untuk menentukan frekuensi per jam, kita akan mengatur freq='H'. Lihat opsi string frekuensi dengan mengunjungi bagian objek DataOffset halaman Seri waktu panda. Untuk mengubah perilaku default, short_series_handling_configuration = 'auto', perbarui parameter short_series_handling_configuration di objek ForecastingParameter Anda.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
Tabel berikut merangkum pengaturan yang tersedia untuk short_series_handling_config.
| Pengaturan | Deskripsi |
|---|---|
auto |
Nilai default untuk penanganan seri pendek. - Jika semua rangkaian berdurasi singkat, lapisi data. - Jika tidak semua rangkaian berdurasi singkat. hilangkan rangkaian singkat. |
pad |
Jika short_series_handling_config = pad, ML otomatis akan menambahkan nilai acak ke setiap rangkaian singkat yang ditemukan. Berikut ini mencantumkan jenis kolom dan apa yang disertakan dengannya: - Kolom objek dengan NaN - Kolom numerik dengan 0 - Kolom Boolean/logika dengan False - Kolom target diisi dengan nilai acak dengan rata-rata nol dan simpang siur standar 1. |
drop |
Jika short_series_handling_config = drop, ML otomatis akan menghilangkan rangkaian singkat dan tidak akan digunakan untuk pelatihan atau prediksi. Prediksi untuk seri ini mengembalikan NaN. |
None |
Tidak ada rangkaian yang dilapisi atau dihilangkan |
Peringatan
Lapisan dapat memengaruhi akurasi model yang dihasilkan, karena kami memperkenalkan data buatan hanya untuk melewati pelatihan tanpa kegagalan. Jika banyak rangkaian singkat, Anda mungkin juga melihat beberapa pengaruh dalam hasil penjelasan
Deteksi dan penanganan rangkaian waktu nonstationary
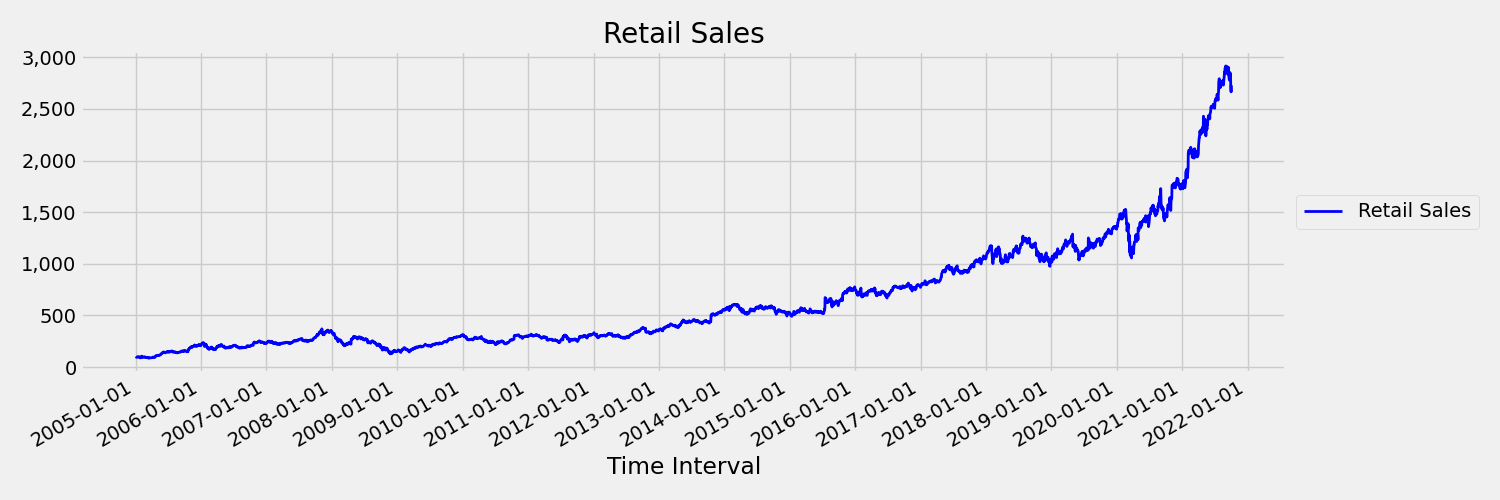
Rangkaian waktu yang momennya (rata-rata dan varian) berubah dari waktu ke waktu disebut non-stasioner. Misalnya, rangkaian waktu yang menunjukkan tren stochastic bersifat non-stasioner. Untuk memvisualisasikan ini, gambar di bawah ini memplot seri yang umumnya tren ke atas. Sekarang, komputasi dan bandingkan nilai rata-rata (rata-rata) untuk paruh pertama dan kedua seri. Apakah keduanya sama? Di sini, rata-rata seri di paruh pertama plot lebih kecil dari pada paruh kedua. Fakta bahwa rata-rata seri tergantung pada interval waktu yang dilihat, adalah contoh momen yang bervariasi waktu. Di sini, rata-rata seri adalah saat pertama.
Selanjutnya, mari kita periksa gambar, yang memplot seri asli dalam perbedaan pertama, $x_t = y_t - y_{t-1}$ di mana $x_t$ adalah perubahan penjualan ritel dan $y_t$ dan $y_{t-1}$ mewakili seri asli dan jeda pertamanya, masing-masing. Rata-rata seri ini kira-kira konstan terlepas dari kerangka waktu yang dilihat. Ini adalah contoh rangkaian waktu stasioner pesanan pertama. Alasan kami menambahkan istilah urutan pertama adalah karena saat pertama (rata-rata) tidak berubah dengan interval waktu, hal yang sama tidak dapat dikatakan tentang varians, yang merupakan momen kedua.
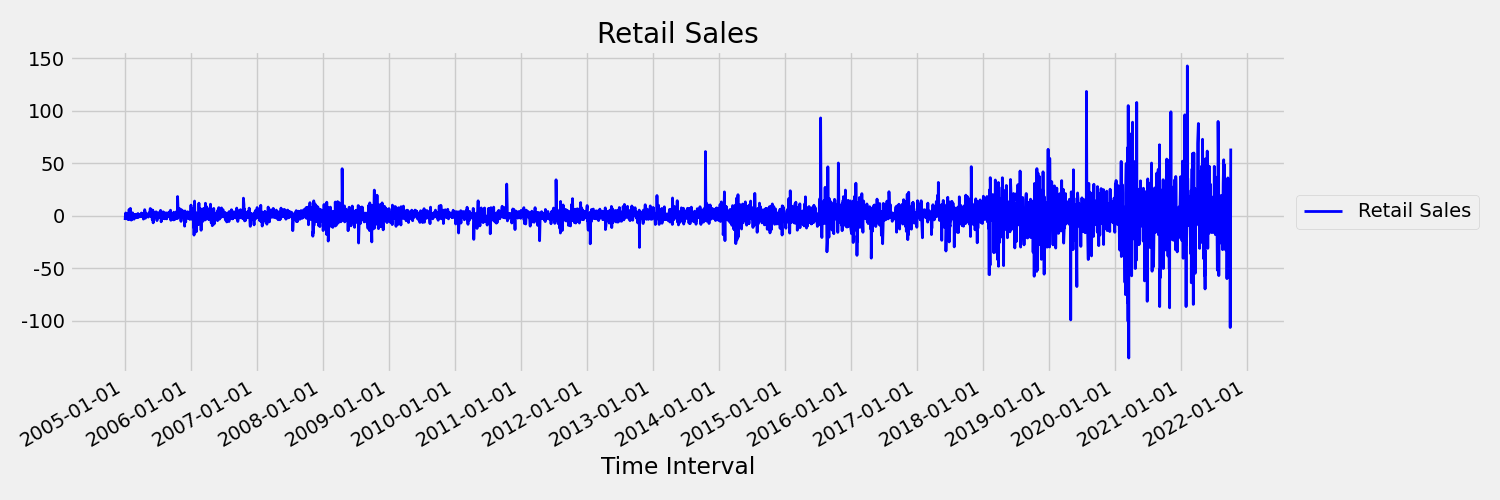
Model pembelajaran Mesin AutoML tidak dapat menangani tren stochastic secara inheren, atau masalah terkenal lainnya yang terkait dengan rangkaian waktu non-stasioner. Akibatnya, akurasi prakiraan sampel mereka "buruk" jika tren tersebut ada.
AutoML secara otomatis menganalisis himpunan data rangkaian waktu untuk memeriksa apakah itu stasioner atau tidak. Ketika rangkaian waktu non-stasioner terdeteksi, AutoML menerapkan transformasi yang berbeda secara otomatis untuk mengurangi pengaruh rangkaian waktu non-stasioner.
Menjalankan percobaan
Ketika objek AutoMLConfig Anda siap, Anda dapat mengirimkan percobaan. Setelah model selesai, ambil iterasi proses terbaik.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Membuat perkiraan dengan model terbaik
Gunakan perulangan model terbaik untuk prakiraan nilai untuk data yang tidak digunakan untuk melatih model.
Mengevaluasi akurasi model dengan prakiraan bergulir
Sebelum memasukkan model ke dalam produksi, Anda harus mengevaluasi akurasinya pada set pengujian yang diadakan dari data pelatihan. Prosedur praktik terbaik adalah apa yang disebut evaluasi bergulir, yang menggulung prakiraan terlatih maju dalam waktu selama set pengujian, rata-rata metrik kesalahan di beberapa jendela prediksi untuk mendapatkan perkiraan yang kuat secara statistik untuk beberapa set metrik yang dipilih. Idealnya, set pengujian untuk evaluasi relatif panjang terhadap cakrawala prakiraan model. Perkiraan kesalahan prakiraan mungkin berisik secara statistik dan, oleh karena itu, kurang dapat diandalkan.
Misalnya, Anda melatih model pada penjualan harian untuk memprediksi permintaan hingga dua minggu (14 hari) ke depan. Jika ada data historis yang memadai yang tersedia, Anda mungkin memesan beberapa bulan terakhir hingga bahkan satu tahun data untuk kumpulan pengujian. Evaluasi bergulir dimulai dengan menghasilkan prakiraan 14 hari ke depan untuk dua minggu pertama dari rangkaian pengujian. Kemudian, prakiraan dimajukan oleh beberapa hari ke dalam set pengujian dan Anda menghasilkan prakiraan 14 hari ke depan lainnya dari posisi baru. Proses berlanjut hingga Anda sampai di akhir set pengujian.
Untuk melakukan evaluasi bergulir, Anda memanggil rolling_forecast metode fitted_model, lalu menghitung metrik yang diinginkan pada hasilnya. Misalnya, asumsikan Anda memiliki fitur set pengujian dalam Pandas DataFrame yang disebut test_features_df dan pengujian menetapkan nilai aktual target dalam array numpy yang disebut test_target. Evaluasi bergulir menggunakan kesalahan kuadrat rata-rata diperlihatkan dalam sampel kode berikut:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
Dalam sampel ini, ukuran langkah untuk prakiraan bergulir diatur ke satu, yang berarti bahwa prakiraan maju satu periode, atau satu hari dalam contoh prediksi permintaan kami, pada setiap perulangan. Jumlah total prakiraan yang dikembalikan dengan rolling_forecast demikian tergantung pada panjang set pengujian dan ukuran langkah ini. Untuk detail dan contoh selengkapnya, lihat dokumentasi rolling_forecast() dan Prakiraan jauh dari buku catatan data pelatihan.
Prediksi ke masa depan
Fungsi forecast_quantiles() memungkinkan spesifikasi kapan prediksi harus dimulai, tidak seperti metode predict(), yang biasanya digunakan untuk tugas klasifikasi dan regresi. Metode forecast_quantiles() secara default menghasilkan perkiraan titik atau perkiraan rata-rata/median, yang tidak memiliki kerucut ketidakpastian di sekitarnya. Pelajari lebih lanjut di Prakiraan jauh dari buku catatan pelatihan data.
Dalam contoh berikut, Anda terlebih dahulu mengganti semua nilai dalam y_pred dengan NaN. Asal prakiraan berada di akhir data pelatihan dalam kasus ini. Namun, jika Anda hanya mengganti paruh kedua y_pred dengan NaN, fungsi akan meninggalkan nilai numerik di paruh pertama tanpa dimodifikasi, tetapi memperkirakan nilai NaN di paruh kedua. Fungsi ini menampilkan nilai yang diperkirakan dan fitur yang diratakan.
Anda juga dapat menggunakan parameter forecast_destination dalam fungsi forecast_quantiles() untuk memperkirakan nilai hingga tanggal yang ditentukan.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Sering kali pelanggan ingin memahami prediksi pada kuantil tertentu dari distribusi. Misalnya, ketika perkiraan digunakan untuk mengontrol inventaris seperti barang belanjaan atau mesin virtual untuk layanan cloud. Dalam kasus seperti itu, titik kontrol biasanya sesuatu seperti "kami ingin item berada dalam stok dan tidak kehabisan 99% dari waktu". Berikut ini menunjukkan cara menentukan kuantil mana yang ingin Anda lihat untuk prediksi Anda, seperti persentil ke-50 atau ke-95. Jika Anda tidak menentukan kuantil, seperti dalam contoh kode yang disebutkan di atas, maka hanya prediksi persentil ke-50 yang dihasilkan.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Anda dapat menghitung metrik model seperti, root mean kuadrat error (RMSE) atau mean absolute percentage error (MAPE) untuk membantu Anda memperkirakan performa model. Lihat bagian Evaluasi dari Buku catatan permintaan berbagi sepeda sebagai contoh.
Setelah akurasi model keseluruhan telah ditentukan, langkah yang paling realistis selanjutnya adalah menggunakan model untuk memperkirakan nilai masa depan yang tidak diketahui.
Berikan himpunan data dalam format yang sama dengan kumpulan pengujian test_dataset tetapi dengan datetimes yang akan datang, dan kumpulan prediksi yang dihasilkan adalah nilai yang diperkirakan untuk setiap langkah rangkaian waktu. Asumsikan catatan rangkaian terakhir dalam himpunan data adalah untuk 31/12/2018. Untuk memperkirakan permintaan untuk hari berikutnya (atau sebanyak periode yang perlu Anda perkirakan, <= forecast_horizon), buat catatan rangkaian waktu tunggal untuk setiap toko untuk 01/01/2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Ulangi langkah-langkah yang diperlukan untuk memuat data mendatang ini ke kerangka data lalu jalankan best_run.forecast_quantiles(test_dataset) untuk memprediksi nilai di masa mendatang.
Catatan
Prediksi dalam sampel tidak didukung untuk perkiraan dengan ML otomatis saat target_lags dan/atau target_rolling_window_size diaktifkan.
Prakiraan dalam skala besar
Ada skenario ketika model pembelajaran mesin tunggal tidak cukup dan beberapa model pembelajaran mesin diperlukan. Misalnya, memprediksi penjualan untuk setiap toko individu untuk merek, atau menyesuaikan pengalaman dengan pengguna individu. Membangun model untuk setiap instans dapat memberikan hasil yang lebih baik pada banyak masalah pembelajaran mesin.
Pengelompokan adalah konsep dalam prakiraan deret waktu yang memungkinkan deret waktu digabungkan untuk melatih model individu per grup. Pendekatan ini dapat sangat membantu jika Anda memiliki deret waktu yang memerlukan pemulusan, pengisian, atau entitas dalam grup yang dapat memperoleh manfaat dari riwayat atau tren dari entitas lain. Banyak model dan prakiraan deret waktu hierarkis adalah solusi yang didukung oleh pembelajaran mesin otomatis untuk skenario prakiraan skala besar ini.
Banyak model
Solusi banyak model Azure Machine Learning dengan pembelajaran mesin otomatis memungkinkan pengguna untuk melatih dan mengelola jutaan model secara paralel. Banyak model Akselerator solusi menggunakan alur Azure Pembelajaran Mesin untuk melatih model. Secara khusus, objek Alur dan ParalleRunStep digunakan dan memerlukan parameter konfigurasi khusus yang ditetapkan melalui ParallelRunConfig.
Diagram berikut menunjukkan alur kerja untuk solusi banyak model.

Kode berikut menunjukkan parameter kunci yang dibutuhkan pengguna untuk menyiapkan banyak model agar dapat berjalan. Lihat Banyak Model - Buku catatan ML Otomatis untuk contoh prakiraan banyak model
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Prakiraan deret waktu hierarkis
Di sebagian besar aplikasi, pelanggan harus memahami prakiraan mereka di tingkat makro dan mikro bisnis. Prakiraan dapat memprediksi penjualan produk di lokasi geografis yang berbeda, atau memahami permintaan tenaga kerja yang diharapkan untuk organisasi yang berbeda di perusahaan. Kemampuan untuk melatih model pembelajaran mesin untuk secara cerdas memprakirakan data hierarki sangatlah penting.
Rangkaian waktu hierarkis adalah struktur di mana masing-masing seri unik disusun menjadi hierarki berdasarkan dimensi seperti, geografi atau jenis produk. Contoh berikut menunjukkan data dengan atribut unik yang membentuk hierarki. Hierarki kami didefinisikan oleh: jenis produk seperti headphone atau tablet, kategori produk, yang membagi jenis produk menjadi aksesori dan perangkat, dan wilayah tempat produk dijual.

Untuk lebih memvisualisasikan ini, tingkat daun hierarki berisi semua deret waktu dengan kombinasi nilai atribut yang unik. Setiap tingkat yang lebih tinggi dalam hierarki menganggap satu dimensi lebih sedikit untuk menentukan deret waktu dan mengagregat setiap set node anak dari tingkat yang lebih rendah ke node induk.

Solusi deret waktu hierarkis dibangun di atas Solusi Banyak Model dan berbagi pengaturan konfigurasi serupa.
Kode berikut menunjukkan parameter kunci untuk mengatur peramalan deret waktu hierarkis Anda. Lihat Rangkaian waktu hierarkis- Buku catatan ML Otomatis, untuk contoh ujung ke ujung.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Contoh buku catatan
Lihat buku catatan contoh perkiraan untuk rincian contoh kode konfigurasi perkiraan tingkat lanjut termasuk:
- deteksi dan fiturisasi liburan
- validasi lintas rolling-origin
- jeda yang dapat dikonfigurasi
- fitur agregat jendela gulir
Langkah berikutnya
- Pelajari lebih lanjut Cara menyebarkan model AutoML ke titik akhir online.
- Pelajari Interpretabilitas: penjelasan model dalam pembelajaran mesin otomatis (pratinjau).
- Pelajari tentang cara AutoML membangun model prakiraan.