Menyiapkan pelatihan AutoML tanpa kode untuk data tabular dengan antarmuka pengguna studio
Dalam artikel ini, Anda mempelajari cara menyiapkan pekerjaan pelatihan AutoML tanpa satu baris kode pun menggunakan ML otomatis Azure Machine Learning di studio Azure Machine Learning.
Pembelajaran mesin otomatis, AutoML, adalah proses di mana algoritma pembelajaran mesin terbaik untuk digunakan untuk data spesifik Anda dipilih untuk Anda. Proses ini memungkinkan Anda menghasilkan model pembelajaran mesin dengan cepat. Pelajari selengkapnya tentang cara Azure Machine Learning menerapkan pembelajaran mesin otomatis.
Untuk contoh akhir ke akhir, coba Tutorial: AutoML- latih model klasifikasi tanpa kode.
Untuk pengalaman berbasis kode Python, konfigurasikan eksperimen pembelajaran mesin otomatis Anda dengan Azure Machine Learning SDK.
Prasyarat
Langganan Azure. Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai. Coba versi gratis atau berbayar Azure Machine Learning sekarang.
Ruang kerja Azure Machine Learning. Lihat Membuat sumber daya ruang kerja.
Mulai
Masuk ke Studio Azure Machine Learning.
Pilih langganan dan ruang kerja Anda.
Navigasi ke panel kiri. Pilih ML Otomatis di bawah bagian Penulisan .

Jika ini pertama kalinya Anda melakukan eksperimen apa pun, Anda akan melihat daftar kosong dan tautan ke dokumentasi.
Jika tidak, Anda akan melihat daftar eksperimen ML otomatis terbaru Anda, termasuk yang dibuat dengan SDK.
Membuat dan menjalankan eksperimen
Pilih + Pekerjaan ML otomatis baru dan isi formulir.
Pilih aset data dari kontainer penyimpanan Anda atau buat aset data baru. Aset data dapat dibuat dari file lokal, url web, penyimpanan data, atau himpunan data terbuka Azure. Pelajari selengkapnya tentang pembuatan himpunan data.
Penting
Persyaratan untuk data pelatihan:
- Data harus dalam bentuk tabular.
- Nilai yang ingin Anda prediksi (kolom target) harus ada dalam data.
Untuk membuat himpunan data baru dari file di komputer lokal Anda, pilih +Buat himpunan data lalu pilih Dari file lokal.
Pilih Berikutnya untuk membuka formulir Datastore dan pemilihan file. , Anda memilih tempat untuk mengunggah himpunan data Anda; kontainer penyimpanan default yang secara otomatis dibuat dengan ruang kerja Anda, atau pilih kontainer penyimpanan yang ingin Anda gunakan untuk eksperimen.
- Jika data Anda berada di belakang jaringan virtual, Anda perlu mengaktifkan fungsi lewati validasi untuk memastikan bahwa ruang kerja dapat mengakses data Anda. Untuk informasi selengkapnya, lihat Menggunakan studio Azure Machine Learning di jaringan virtual Azure.
Pilih Telusuri untuk mengunggah file data untuk himpunan data Anda.
Tinjau formulir Pengaturan dan pratinjau untuk akurasi. Formulir diisi secara cerdas berdasarkan jenis file.
Bidang Deskripsi Format file Menentukan tata letak dan jenis data yang disimpan dalam sebuah file. Pemisah Satu atau beberapa karakter untuk menentukan batas antara, wilayah independen yang terpisah dalam teks biasa atau aliran data lainnya. Pengodean Mengidentifikasi bit ke tabel skema karakter apa yang akan digunakan untuk membaca himpunan data Anda. Header kolom Menunjukkan bagaimana header himpunan data, jika ada, akan diperlakukan. Lewati baris Menunjukkan berapa banyak, jika ada, baris yang dilewati dalam himpunan data. Pilih Selanjutnya.
Formulir Skema diisi secara cerdas berdasarkan pilihan dalam formulir Pengaturan dan pratinjau. Di sini konfigurasikan tipe data untuk setiap kolom, tinjau nama kolom, dan pilih kolom mana yang tidak disertakan untuk eksperimen Anda.
Pilih Selanjutnya.
Formulir Konfirmasi detail adalah ringkasan informasi yang sebelumnya diisi dalam formulir Info dasar dan Pengaturan serta pratinjau. Anda juga memiliki opsi untuk membuat profil data untuk himpunan data Anda menggunakan komputasi yang diaktifkan pembuatan profil.
Pilih Selanjutnya.
Pilih himpunan data yang paling baru dibuat setelah muncul. Anda juga dapat melihat pratinjau himpunan data dan statistik sampel.
Pada formulir Konfigurasi jalankan, pilih Buat baru dan masukkan Tutorial-automl-deploy untuk nama eksperimen.
Pilih kolom target; ini adalah kolom yang ingin Anda lakukan prediksi.
Pilih jenis komputasi untuk pekerjaan pembuatan profil dan pelatihan data. Anda dapat memilih kluster komputasi atau instans komputasi.
Pillih komputasi dari daftar tarik turun komputasi yang ada. Untuk membuat komputasi baru, ikuti instruksi di langkah 8.
Pilih Buat komputasi baru untuk mengonfigurasi konteks komputasi Anda untuk eksperimen ini.
Bidang Deskripsi Nama komputasi Masukkan nama unik yang mengidentifikasi konteks komputasi Anda. Prioritas komputer virtual Komputer virtual prioritas rendah lebih murah tetapi tidak menjamin simpul komputasi. Jenis komputer virtual Pilih CPU atau GPU untuk tipe komputer virtual. Ukuran komputer virtual Pilih jenis komputer virtual untuk komputasi Anda. Node Min/Maks Untuk memprofilkan data, Anda harus menentukan satu atau beberapa simpul. Masukkan jumlah maksimum simpul untuk komputasi Anda. Defaultnya adalah enam simpul untuk Azure Pembelajaran Mesin Compute. Pengaturan tingkat lanjut Setelan ini memungkinkan Anda mengonfigurasi akun pengguna dan jaringan maya yang ada untuk eksperimen Anda. Pilih Buat. Pembuatan komputasi baru dapat memakan waktu beberapa menit.
Pilih Selanjutnya.
Pada formulir Tipe tugas dan pengaturan, pilih tipe tugas: klasifikasi, regresi, atau perkiraan. Lihat tipe tugas yang didukung untuk informasi selengkapnya.
Untuk klasifikasi, Anda juga dapat mengaktifkan pembelajaran mendalam.
Untuk perkiraan Anda bisa,
Aktifkan pembelajaran mendalam.
Pilih kolom waktu: Kolom ini berisi data waktu yang akan digunakan.
Pilih cakrawala prakiraan: Menunjukkan berapa banyak unit waktu (menit/jam/hari/minggu/bulan/tahun) yang akan dapat diprediksi model ke masa depan. Semakin jauh ke masa depan model diperlukan untuk memprediksi, semakin kurang akurat modelnya. Pelajari selengkapnya tentang perkiraan dan cakrawala perkiraan.
(Opsional) Tampilan pengaturan konfigurasi tambahan: setelan tambahan yang dapat Anda gunakan untuk mengontrol pekerjaan pelatihan dengan lebih baik. Jika tidak, pengaturan default diterapkan berdasarkan pilihan eksperimen dan data.
Konfigurasi tambahan Deskripsi Metrik utama Metrik utama yang digunakan untuk mencetak model Anda. Pelajari selengkapnya tentang metrik model. Mengaktifkan tumpukan ansambel Pembelajaran ansambel meningkatkan hasil pembelajaran mesin dan performa prediktif dengan menggabungkan beberapa model dan bukan dengan menggunakan model tunggal. Pelajari selengkapnya tentang model ansambel. Model yang diblokir Pilih model yang ingin Anda kecualikan dari pekerjaan pelatihan.
Mengizinkan model hanya tersedia untuk eksperimen SDK.
Lihat algoritma yang didukung untuk setiap jenis tugas.Menjelaskan model terbaik Secara otomatis menunjukkan kemampuan penjelasan pada model terbaik yang dibuat oleh ML Otomatis. Label kelas positif Label yang akan digunakan ML Otomatis untuk menghitung metrik biner. (Opsional) Melihat pengaturan fiturisasi: jika Anda memilih untuk mengaktifkan fiturisasi Otomatis dalam formulir Pengaturan konfigurasi tambahan, teknik fiturisasi default diterapkan. Di pengaturan Tampilkan fiturisasi, Anda dapat mengubah default ini dan menyesuaikannya. Pelajari cara menyesuaikan featurisasi.
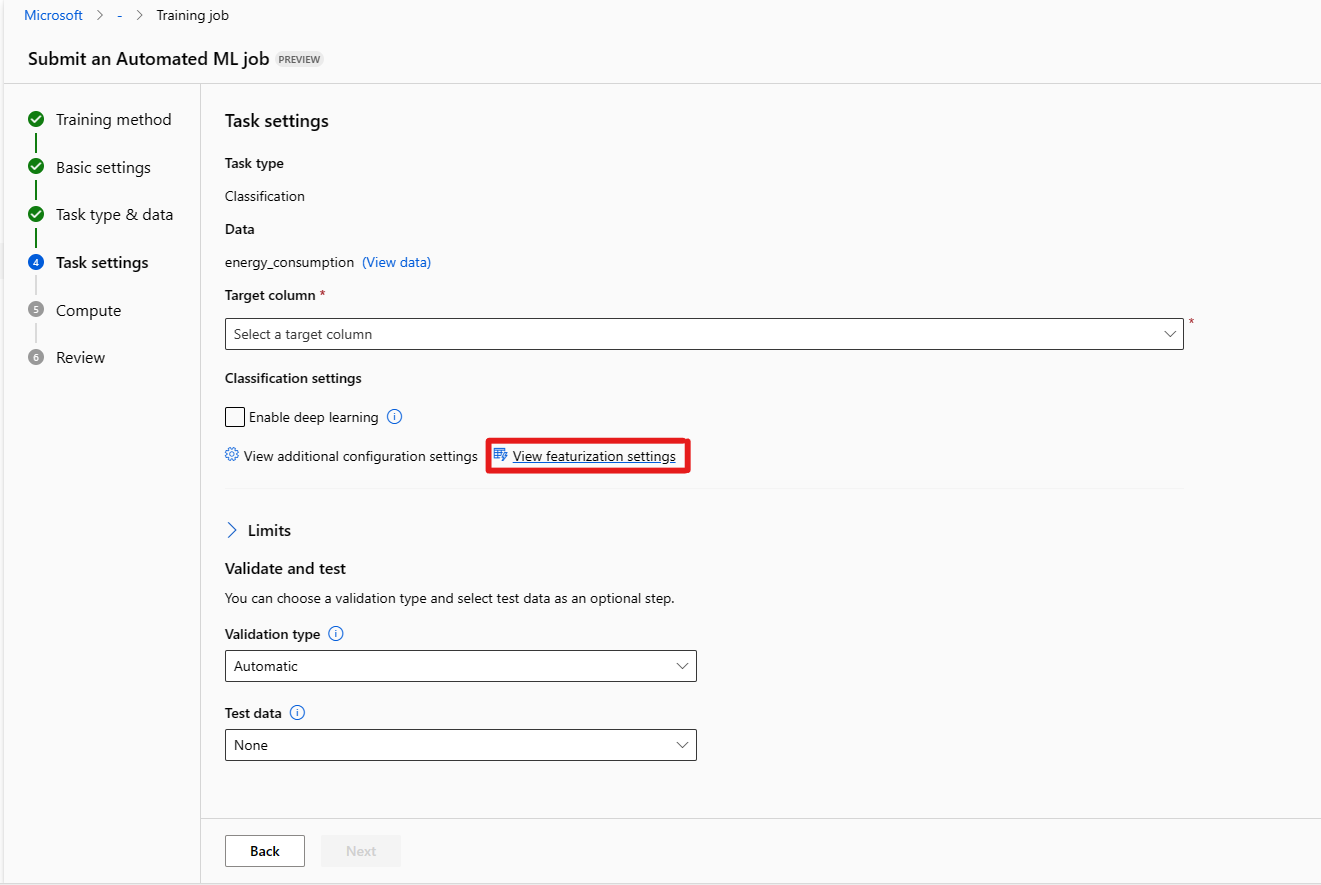
Formulir Batas [Opsional] memungkinkan Anda melakukan hal berikut.
Opsi Deskripsi Uji coba maks Jumlah maksimum uji coba, masing-masing dengan kombinasi algoritma dan hiperparameter yang berbeda untuk dicoba selama pekerjaan AutoML. Harus bilangan bulat antara 1 dan 1000. Uji coba serentak maks Jumlah maksimum pekerjaan percobaan yang dapat dijalankan secara paralel. Harus bilangan bulat antara 1 dan 1000. Simpul maks Jumlah maksimum simpul yang dapat digunakan pekerjaan ini dari target komputasi yang dipilih. Ambang batas skor metrik Ketika nilai ambang batas ini akan tercapai untuk metrik iterasi, pekerjaan pelatihan akan berakhir. Perlu diingat bahwa model yang bermakna memiliki korelasi > 0, jika tidak, model tersebut sama baiknya dengan menebak ambang batas Metrik rata-rata harus berada di antara batas [0, 10]. Batas waktu eksperimen (menit) Waktu maksimum dalam menit seluruh eksperimen diizinkan untuk berjalan. Setelah batas ini tercapai, sistem akan membatalkan pekerjaan AutoML, termasuk semua uji cobanya (pekerjaan anak- anak). Batas waktu perulangan (menit) Waktu maksimum dalam menit setiap pekerjaan uji coba diizinkan untuk dijalankan. Setelah batas ini tercapai, sistem akan membatalkan percobaan. Aktifkan penghentian dini Pilih untuk mengakhiri pekerjaan jika skor tidak membaik dalam jangka pendek. Formulir Validasi dan uji [Opsional] memungkinkan Anda melakukan hal berikut.
a. Tentukan jenis validasi yang akan digunakan untuk pekerjaan pelatihan Anda. Jika Anda tidak menentukan parameter validation_data atau n_cross_validations secara eksplisit, ML otomatis menerapkan teknik default bergantung pada jumlah baris yang disediakan dalam himpunan data tunggal.training_data
| Ukuran data pelatihan | Teknik validasi |
|---|---|
| Lebih besar dari 20.000 baris | Pemisahan data pelatihan/validasi diterapkan. Defaultnya yaitu mengambil 10% dari himpunan data pelatihan awal sebagai set validasi. Pada saatnya, set validasi tersebut digunakan untuk perhitungan metrik. |
| Lebih kecil dari 20.000& baris | Pendekatan validasi silang diterapkan. Jumlah lipatan default tergantung pada jumlah baris. Jika himpunan data kurang dari 1.000 baris, 10 lipatan akan digunakan. Jika baris antara 1.000 dan 20.000, maka tiga lipatan digunakan. |
b. Sediakan himpunan data pengujian (pratinjau) untuk mengevaluasi model yang direkomendasikan yang dihasilkan ML otomatis untuk Anda di akhir eksperimen. Ketika Anda memberikan data uji, pekerjaan uji secara otomatis dipicu pada akhir eksperimen Anda. Pekerjaan pengujian ini hanya pekerjaan pada model terbaik yang direkomendasikan oleh ML otomatis. Pelajari cara mendapatkan hasil pekerjaan uji jarak jauh.
Penting
Menyediakan himpunan data pengujian untuk mengevaluasi model yang dihasilkan adalah fitur pratinjau. Kemampuan ini adalah fitur pratinjau eksperimental, dan dapat berubah sewaktu-waktu.
* Data pengujian dianggap terpisah dari pelatihan dan validasi, sehingga tidak bias hasil pekerjaan pengujian model yang direkomendasikan. Pelajari selengkapnya tentang bias selama validasi model.
* Anda dapat menyediakan himpunan data pengujian Anda sendiri atau memilih untuk menggunakan persentase himpunan data pelatihan Anda. Data uji harus dalam bentuk Azure Machine Learning TabularDataset.
* Skema himpunan data pengujian harus sesuai dengan himpunan data pelatihan. Kolom target bersifat opsional, tetapi jika tidak ada kolom target yang ditunjukkan tidak ada metrik pengujian yang akan dihitung.
* Himpunan data pengujian tidak boleh sama dengan himpunan data pelatihan atau himpunan data validasi.
* Pekerjaan prakiraan tidak mendukung pemisahan pelatihan/pengujian.
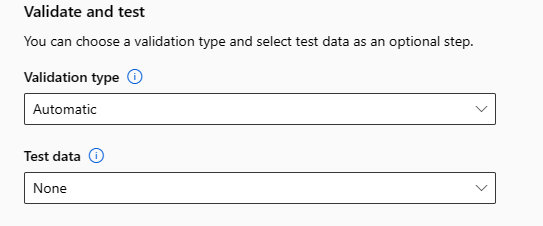
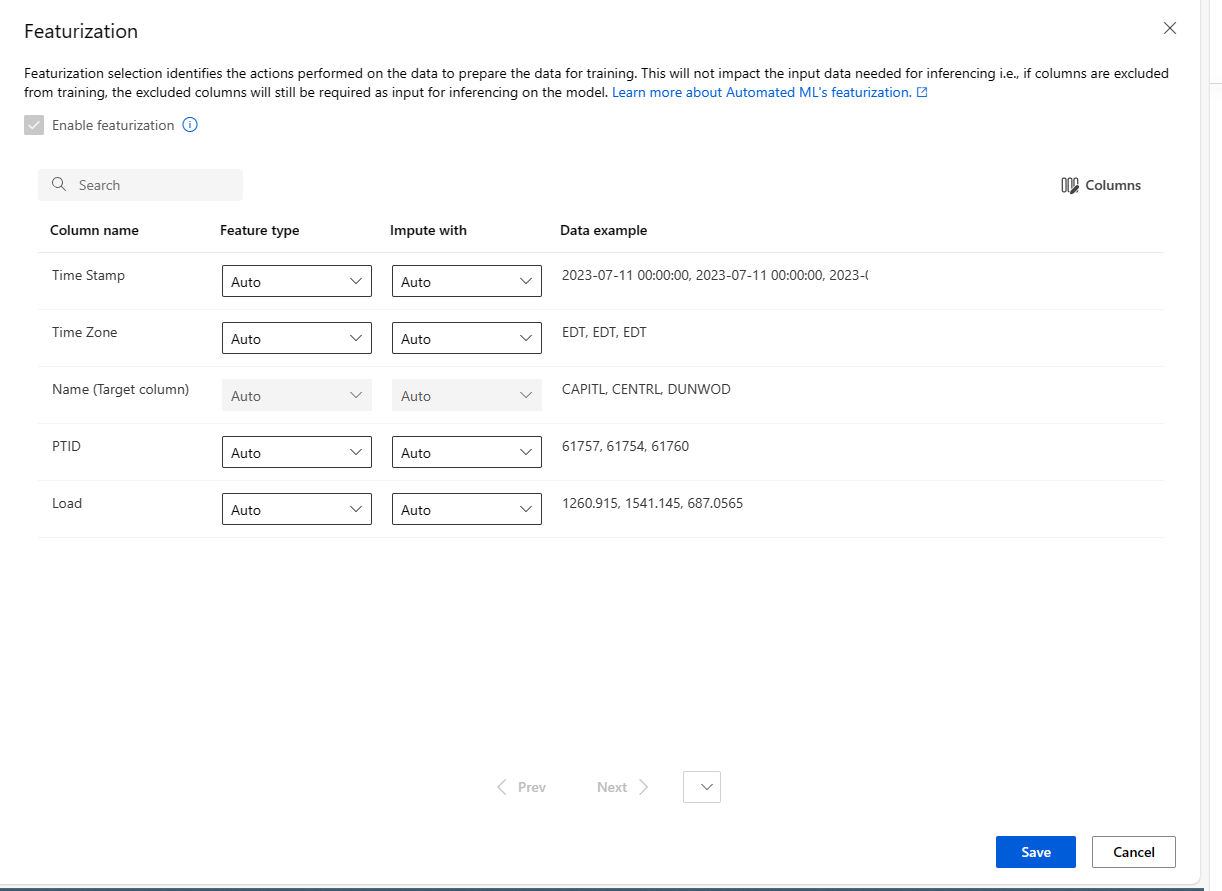
Menyesuaikan fiturisasi
Dalam formulir Fiturisasi, Anda dapat mengaktifkan/menonaktifkan fiturisasi otomatis dan menyesuaikan pengaturan fiturisasi otomatis untuk eksperimen Anda. Untuk membuka formulir ini, lihat langkah 10 di bagian Buat dan jalankan eksperimen.
Tabel berikut ini meringkas kustomisasi yang saat ini tersedia melalui studio.
| Kolom | Penyesuaian |
|---|---|
| Jenis fitur | Mengubah tipe nilai untuk kolom yang dipilih. |
| Imputasi dengan | Pilih nilai apa yang harus diimputkan nilai yang hilang dalam data Anda. |
Jalankan eksperimen dan tampilkan hasil
Pilih Selesai untuk menjalankan eksperimen Anda. Proses persiapan eksperimen dapat memakan waktu hingga 10 menit. Pekerjaan pelatihan dapat memakan waktu tambahan 2-3 menit lagi agar setiap alur selesai berjalan. Jika Anda telah menentukan untuk menghasilkan dasbor RAI untuk model terbaik yang direkomendasikan, mungkin perlu waktu hingga 40 menit.
Catatan
Algoritma yang digunakan ML otomatis memiliki keacakan melekat yang dapat menyebabkan sedikit variasi dalam skor metrik akhir model yang direkomendasikan, seperti akurasi. ML otomatis juga melakukan operasi pada data seperti pemisahan uji kereta, pemisahan validasi kereta atau validasi silang bila diperlukan. Jadi, jika Anda menjalankan eksperimen dengan pengaturan konfigurasi dan metrik utama yang sama beberapa kali, Anda mungkin akan melihat variasi dalam setiap eksperimen skor metrik akhir karena faktor-faktor ini.
Lihat detail eksperimen
Layar Pekerjaan Detail terbuka ke tab Detail. Layar ini menunjukkan ringkasan pekerjaan percobaan termasuk bilah status di bagian atas nomor pekerjaan.
Tab Model berisi daftar model yang dibuat dan diurutkan berdasarkan skor metrik. Secara default, model yang mencetak skor tertinggi berdasarkan metrik yang dipilih berada di bagian atas daftar. Saat pekerjaan pelatihan mencoba lebih banyak model, mereka ditambahkan ke daftar. Gunakan ini untuk mendapatkan perbandingan cepat dari metrik untuk model yang diproduksi sejauh ini.
Lihat detail pekerjaan pelatihan
Telusuri paling detail salah satu model yang sudah selesai untuk melihat detail pekerjaan pelatihan.
Anda dapat melihat bagan metrik performa spesifik model pada tab Metrik . Pelajari selengkapnya tentang bagan.
Ini juga tempat Anda dapat menemukan detail tentang semua properti model bersama dengan kode terkait, pekerjaan anak, dan gambar.
Melihat hasil pekerjaan uji jarak jauh (pratinjau)
Jika Anda menentukan himpunan data pengujian atau memilih pemisahan pelatihan/pengujian selama penyiapan eksperimen Anda--pada formulir Validasi dan pengujian , ML otomatis secara otomatis menguji model yang direkomendasikan secara default. Akibatnya, ML otomatis menghitung metrik uji untuk menentukan kualitas model yang direkomendasikan dan prediksinya.
Penting
Menguji model Anda dengan himpunan data uji untuk mengevaluasi model yang dihasilkan adalah fitur pratinjau. Kemampuan ini adalah fitur pratinjau eksperimental, dan dapat berubah sewaktu-waktu.
Peringatan
Fitur ini tidak tersedia untuk skenario ML otomatis berikut
Untuk melihat metrik pekerjaan uji dari model yang direkomendasikan,
- Navigasikan ke halaman Model, pilih model terbaik.
- Pilih tab Hasil pengujian (pratinjau).
- Pilih pekerjaan yang Anda inginkan, dan lihat tab Metrik .
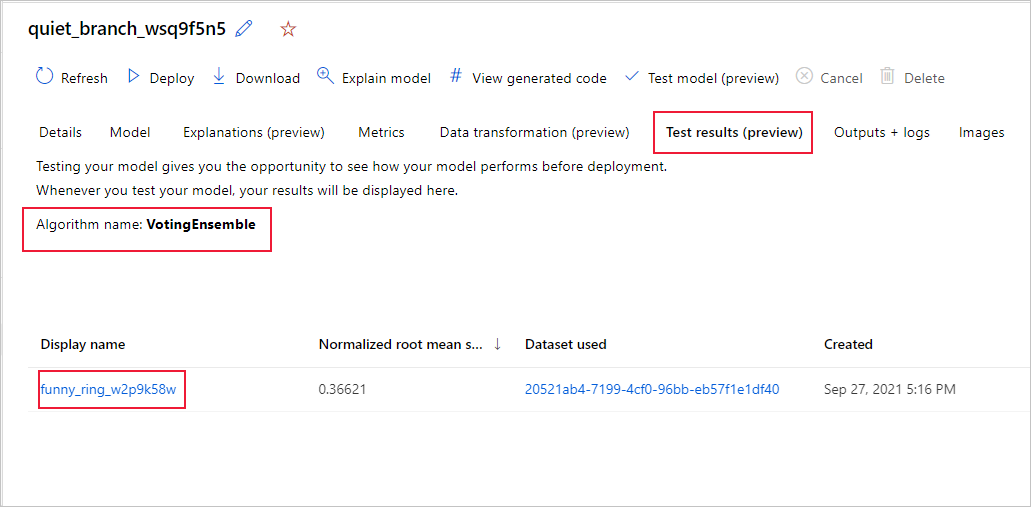
Untuk melihat prediksi pengujian yang digunakan untuk menghitung metrik pengujian,
- Navigasikan ke bagian bawah halaman dan pilih tautan di bagian Himpunan data output untuk membuka himpunan data.
- Pada halaman Himpunan data, pilih tab Jelajahi untuk melihat prediksi dari pekerjaan uji.
- Atau, file prediksi juga dapat dilihat/diunduh dari tab Output + log, perluas folder Prediksi untuk menemukan file
predicted.csvAnda.
- Atau, file prediksi juga dapat dilihat/diunduh dari tab Output + log, perluas folder Prediksi untuk menemukan file
Atau, file prediksi juga dapat dilihat/diunduh dari tab Output + log, perluas folder Prediksi untuk menemukan file predictions.csv Anda.
Pekerjaan pengujian model menghasilkan file prediksi.csv yang disimpan di penyimpanan data default yang dibuat dengan ruang kerja. Datastore ini dapat dilihat oleh semua pengguna dengan langganan yang sama. Pekerjaan pengujian tidak disarankan untuk skenario jika salah satu informasi yang digunakan untuk atau dibuat oleh pekerjaan pengujian harus tetap privat.
Menguji model ML otomatis yang sudah ada (pratinjau)
Penting
Menguji model Anda dengan himpunan data uji untuk mengevaluasi model yang dihasilkan adalah fitur pratinjau. Kemampuan ini adalah fitur pratinjau eksperimental, dan dapat berubah sewaktu-waktu.
Peringatan
Fitur ini tidak tersedia untuk skenario ML otomatis berikut
Setelah eksperimen Anda selesai, Anda dapat menguji model yang ML otomatis hasilkan untuk Anda. Jika Anda ingin menguji model yang dihasilkan ML otomatis yang berbeda, bukan model yang direkomendasikan, Anda dapat melakukannya dengan langkah-langkah berikut.
Pilih pekerjaan eksperimen ML otomatis yang sudah ada.
Navigasikan ke tab Model dari pekerjaan dan pilih model lengkap yang ingin Anda uji.
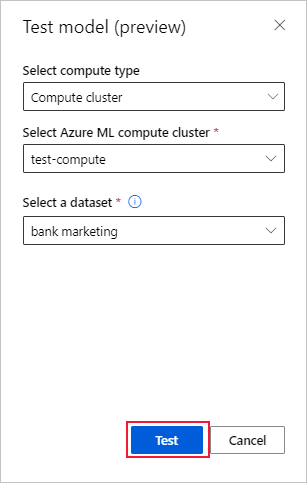
Pada halaman Detail model, pilih tombol Uji model (pratinjau) untuk membuka panel Uji model.
Pada panel Uji model, pilih kluster komputasi dan kumpulan data pengujian yang ingin Anda gunakan untuk pekerjaan uji Anda.
Pilih tombol Uji. Skema himpunan data pengujian harus sesuai dengan himpunan data pelatihan, tetapi kolom target bersifat opsional.
Setelah berhasil membuat pekerjaan uji model, halaman Detail menampilkan pemberitahuan sukses. Pilih tab Hasil pengujian untuk melihat kemajuan pekerjaan.
Untuk melihat hasil pekerjaan uji, buka halaman Detail dan ikuti langkah-langkah di bagian lihat hasil pekerjaan uji jarak jauh.
Dasbor AI yang bertanggung jawab (pratinjau)
Untuk lebih memahami model Anda, Anda dapat melihat berbagai wawasan tentang model Anda menggunakan dasbor Ai Yang Bertanggung Jawab. Ini memungkinkan Anda untuk mengevaluasi dan men-debug model pembelajaran mesin Otomatis terbaik Anda. Dasbor AI yang bertanggung jawab akan mengevaluasi kesalahan model dan masalah kewajaran, mendiagnosis mengapa kesalahan tersebut terjadi dengan mengevaluasi data pelatihan dan/atau pengujian Anda, dan mengamati penjelasan model. Bersama-sama, wawasan ini dapat membantu Anda membangun kepercayaan dengan model Anda dan melewati proses audit. Dasbor AI yang bertanggung jawab tidak dapat dihasilkan untuk model pembelajaran mesin Otomatis yang ada. Ini hanya dibuat untuk model terbaik yang direkomendasikan ketika pekerjaan AutoML baru dibuat. Pengguna harus terus hanya menggunakan Penjelasan Model (pratinjau) sampai dukungan disediakan untuk model yang ada.
Untuk menghasilkan dasbor AI yang Bertanggung Jawab untuk model tertentu,
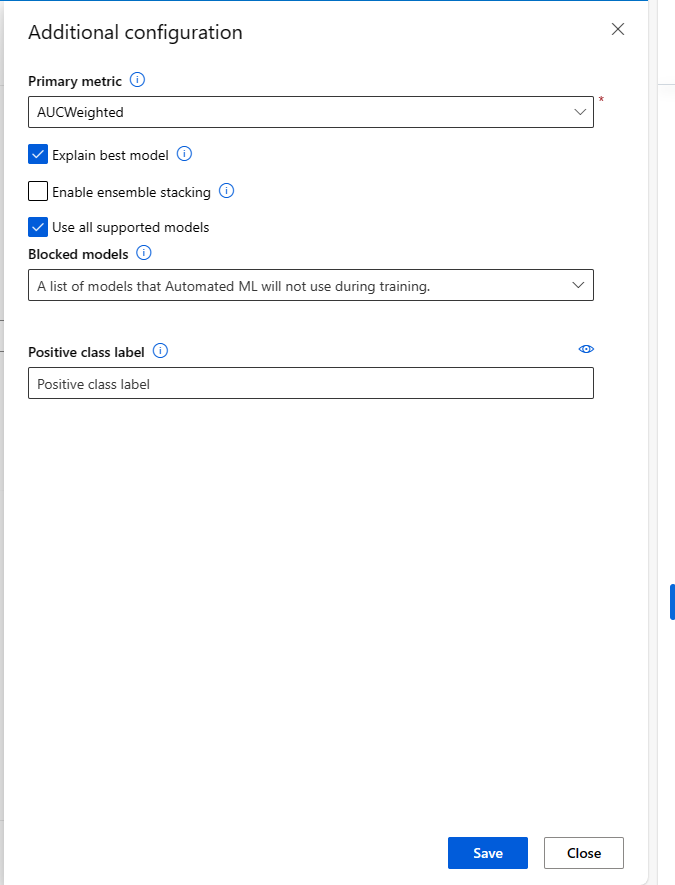
Saat mengirimkan pekerjaan ML Otomatis, lanjutkan ke bagian Pengaturan tugas di bilah navigasi kiri dan pilih opsi Tampilkan pengaturan konfigurasi tambahan.
Dalam formulir baru muncul postingan pilihan tersebut, pilih kotak centang Jelaskan model terbaik.
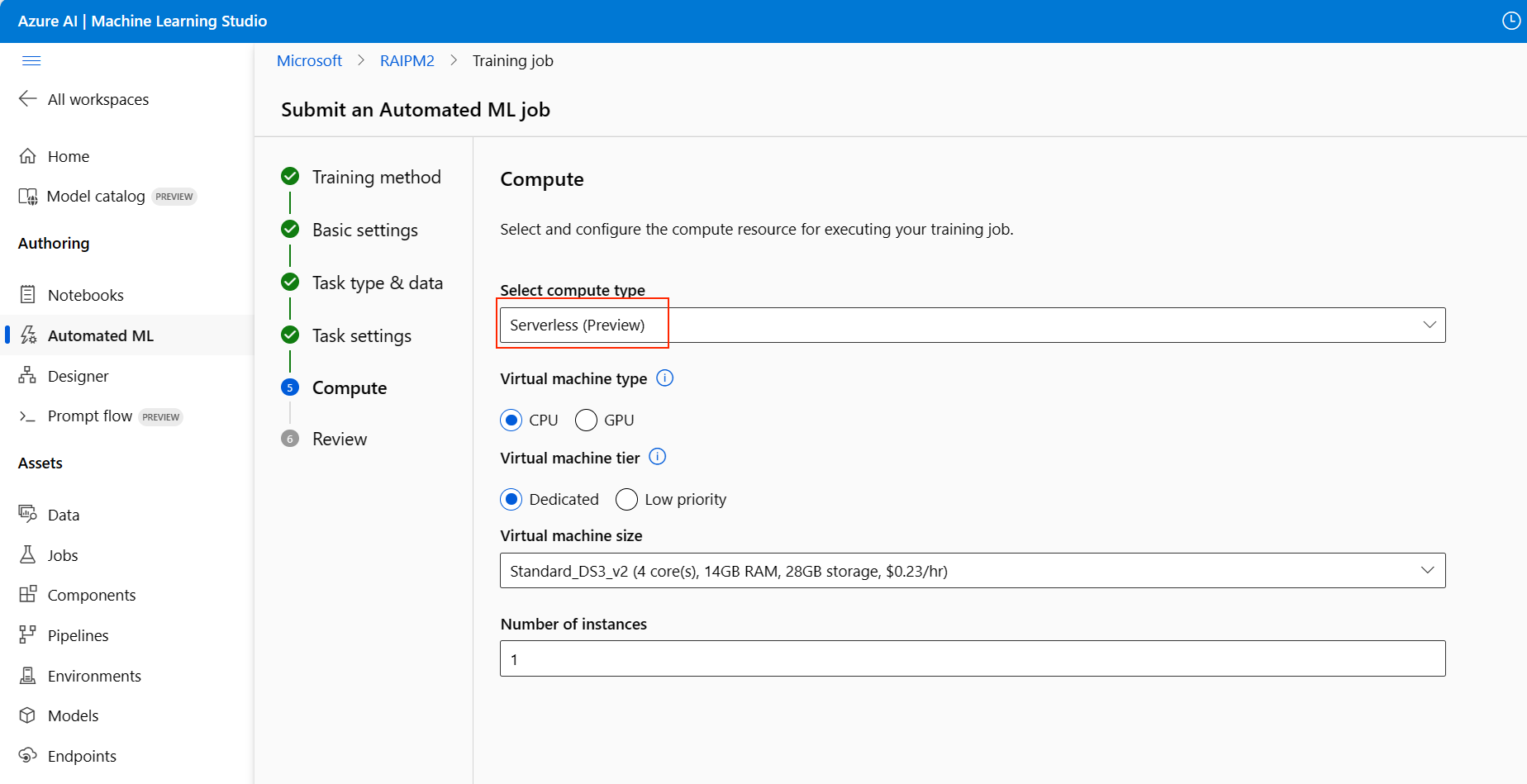
Lanjutkan ke halaman Komputasi formulir penyiapan dan pilih opsi Tanpa Server untuk komputasi Anda.
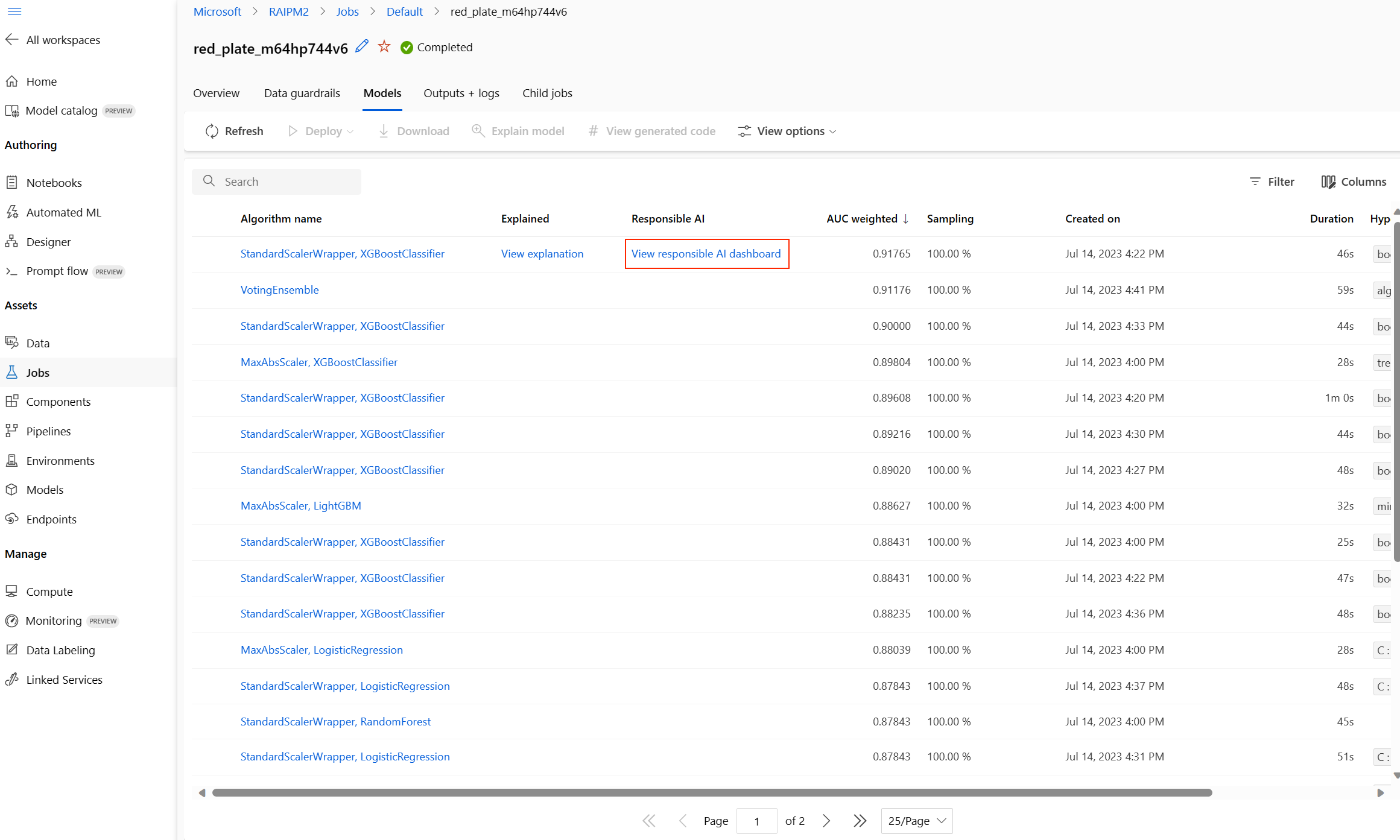
Setelah selesai, navigasikan ke halaman Model pekerjaan ML Otomatis Anda, yang berisi daftar model terlatih Anda. Pilih tautan Lihat dasbor AI yang Bertanggung Jawab:
Dasbor AI yang bertanggung jawab muncul untuk model tersebut seperti yang ditunjukkan pada gambar ini:
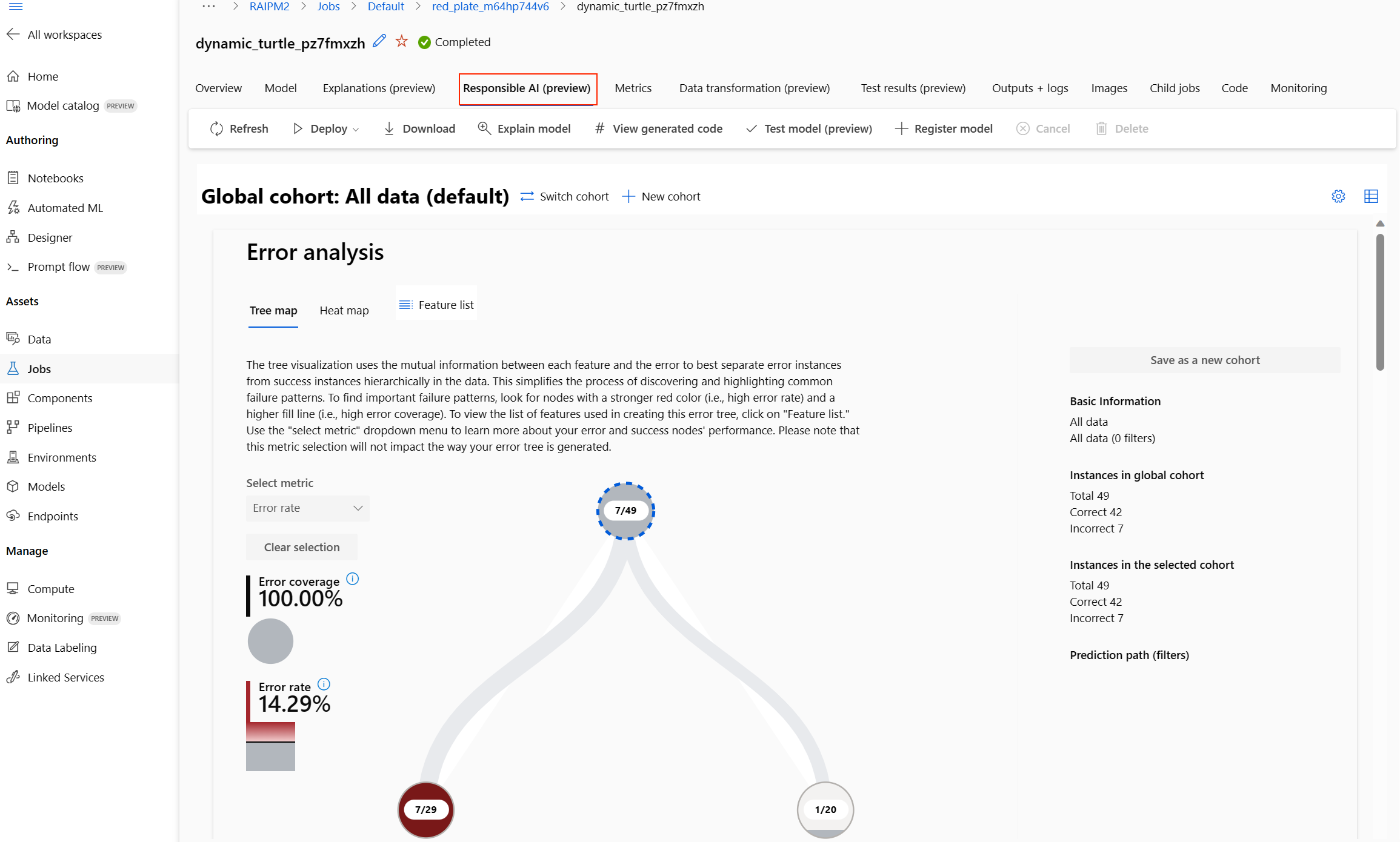
Di dasbor, Anda akan menemukan empat komponen yang diaktifkan untuk model terbaik ML Otomatis Anda:
| Komponen | Apa yang ditampilkan komponen? | Bagaimana cara membaca bagan? |
|---|---|---|
| Analisis Kesalahan | Gunakan analisis kesalahan saat Anda perlu: Dapatkan pemahaman mendalam tentang bagaimana kegagalan model didistribusikan di seluruh himpunan data dan di beberapa dimensi input dan fitur. Uraikan metrik performa agregat untuk menemukan kohor yang salah secara otomatis untuk menginformasikan langkah-langkah mitigasi yang ditargetkan. |
Bagan Analisis Kesalahan |
| Gambaran Umum dan Kewajaran Model | Gunakan komponen ini untuk: Dapatkan pemahaman mendalam tentang performa model Anda di berbagai kohor data. Pahami masalah kewajaran model Anda dengan melihat metrik disparitas. Metrik ini dapat mengevaluasi dan membandingkan perilaku model di seluruh subgrup yang diidentifikasi dalam hal fitur sensitif (atau tidak sensitif). |
Gambaran Umum Model dan Bagan Kewajaran |
| Penjelasan Model | Gunakan komponen penjelasan model untuk menghasilkan deskripsi yang dapat dipahami manusia tentang prediksi model pembelajaran mesin dengan melihat: Penjelasan Global: Misalnya, fitur apa yang memengaruhi perilaku keseluruhan model alokasi pinjaman? Penjelasan lokal: Misalnya, mengapa aplikasi pinjaman pelanggan disetujui atau ditolak? |
Bagan Keterjelasan Model |
| Analisis Data | Gunakan analisis data saat Anda perlu: Menjelajahi statistik himpunan data Anda dengan memilih filter yang berbeda untuk membagi data Anda ke dimensi yang berbeda (juga dikenal sebagai kohor). Memahami distribusi himpunan data Anda di berbagai kelompok dan grup fitur. Tentukan apakah temuan Anda yang terkait dengan kewajaran, analisis kesalahan, dan kausalitas (berasal dari komponen dasbor lain) adalah hasil dari distribusi himpunan data Anda. Tentukan di area mana untuk mengumpulkan lebih banyak data untuk mengurangi kesalahan yang berasal dari masalah representasi, kebisingan label, kebisingan fitur, bias label, dan faktor serupa. |
Bagan Data Explorer |
- Anda selanjutnya dapat membuat kohor (subgrup titik data yang berbagi karakteristik yang ditentukan) untuk memfokuskan analisis Anda pada setiap komponen pada kohor yang berbeda. Nama kohor yang saat ini diterapkan ke dasbor selalu ditampilkan di kiri atas di atas dasbor Anda. Tampilan default di dasbor Anda adalah seluruh himpunan data Anda, berjudul "Semua data" (secara default). Pelajari selengkapnya tentang kontrol global dasbor Anda di sini.
Edit dan kirim pekerjaan (pratinjau)
Penting
Kemampuan untuk menyalin, mengedit, dan mengirimkan eksperimen baru berdasarkan eksperimen yang ada adalah fitur pratinjau. Kemampuan ini adalah fitur pratinjau eksperimental, dan dapat berubah sewaktu-waktu.
Dalam skenario di mana Anda ingin membuat eksperimen baru berdasarkan setelan eksperimen yang ada, Azure Machine Learning otomatis menyediakan opsi untuk melakukannya dengan Edit dan kirim di antarmuka pengguna studio.
Fungsionalitas ini terbatas pada eksperimen yang dimulai dari antarmuka pengguna studio dan memerlukan skema data untuk eksperimen baru agar sesuai dengan eksperimen asli.
Tombol Edit dan kirim membuka wizard Buat pekerjaan ML Otomatis baru dengan pengaturan data, komputasi, dan eksperimen yang telah diisi sebelumnya. Anda dapat menelusuri setiap formulir dan mengedit pilihan sesuai kebutuhan untuk eksperimen baru Anda.
Sebarkan model anda
Setelah Anda memiliki model terbaik, saatnya untuk menyebarkannya sebagai layanan web untuk memprediksi data baru.
Tip
Jika Anda ingin menyebarkan model yang dihasilkan melalui automl paket dengan Python SDK, Anda harus mendaftarkan model Anda) ke ruang kerja.
Setelah model Anda terdaftar, temukan di studio dengan memilih Model di panel kiri. Setelah membuka model anda, Anda dapat memilih tombol Sebarkan di bagian atas layar, lalu ikuti instruksi seperti yang dijelaskan di langkah 2 bagian Sebarkan model Anda.
ML otomatis membantu Anda menyebarkan model tanpa menulis kode:
Anda memiliki beberapa opsi untuk penyebaran.
Opsi 1: sebar model terbaik, sesuai dengan kriteria metrik yang Anda tentukan.
- Setelah eksperimen selesai, navigasi ke halaman pekerjaan induk dengan memilih Pekerjaan 1 di bagian atas layar.
- Pilih model yang tercantum di bagian Ringkasan model terbaik.
- Pilih Sebar di kiri atas jendela.
Opsi 2: Untuk menyebarkan iterasi model tertentu dari eksperimen ini.
- Pilih model yang diinginkan dari tab Model
- Pilih Sebar di kiri atas jendela.
Isi panel Sebar model.
Bidang Nilai Nama Masukkan nama yang unik untuk penyebaran Anda. Deskripsi Masukkan deskripsi untuk mengidentifikasi dengan lebih baik untuk apa penyebaran ini. Tipe komputasi Pilih jenis titik akhir yang ingin Anda terapkan: Azure Kubernetes Service (AKS) atau Azure Container Instance (ACI). Nama komputasi Berlaku hanya untuk AKS: Pilih nama kluster AKS yang ingin Anda sebarkan. Aktifkan autentikasi Pilih untuk mengizinkan autentikasi berbasis token atau berbasis kunci. Gunakan aset penyebaran kustom Aktifkan fitur ini jika Anda ingin mengunggah skrip skor dan file lingkungan Anda sendiri. Jika tidak, ML otomatis menyediakan aset ini untuk Anda secara default. Pelajari lebih lanjut tentang skrip skor. Penting
Nama file harus kurang dari 32 karakter dan harus dimulai dan diakhiri dengan alfanumerik. Dapat mencakup tanda hubung, garis bawah, titik, dan alfanumerik di antaranya. Spasi tidak diperbolehkan.
Menu Tingkat Lanjut menawarkan fitur penyebaran default seperti pengumpulan data dan pengaturan pemanfaatan sumber daya. Jika Anda ingin mengganti default ini, lakukan di menu ini.
Pilih Sebarkan. Penyebaran dapat memakan waktu sekitar 20 menit. Setelah penyebaran dimulai, tab Ringkasan model muncul. Lihat kemajuan penyebaran di bawah bagian Status deploi.
Sekarang Anda memiliki layanan web operasional untuk menghasilkan prediksi! Anda bisa menguji prediksi dengan mengkueri layanan dari dukungan Power BI Azure Machine Learning bawaan.
Langkah berikutnya
- Memahami hasil pembelajaran mesin otomatis.
- Pelajari lebih lanjut Azure Machine Learning dan Azure Machine Learning.