Tutorial: Mengunggah, mengakses, dan menjelajahi data Anda di Azure Pembelajaran Mesin
BERLAKU UNTUK: Python SDK azure-ai-ml v2 (saat ini)
Python SDK azure-ai-ml v2 (saat ini)
Dalam tutorial ini, Anda akan mempelajari cara:
- Mengunggah data Anda ke penyimpanan cloud
- Membuat aset data Azure Pembelajaran Mesin
- Mengakses data Anda dalam buku catatan untuk pengembangan interaktif
- Membuat versi baru aset data
Awal proyek pembelajaran mesin biasanya melibatkan analisis data eksploratif (EDA), praproses data (pembersihan, rekayasa fitur), dan pembangunan prototipe model Pembelajaran Mesin untuk memvalidasi hipotesis. Fase proyek prototipe ini sangat interaktif. Ini meminjamkan dirinya untuk pengembangan dalam IDE atau notebook Jupyter, dengan konsol interaktif Python. Tutorial ini menjelaskan ide-ide ini.
Video ini menunjukkan cara memulai di studio Azure Pembelajaran Mesin sehingga Anda dapat mengikuti langkah-langkah dalam tutorial. Video menunjukkan cara membuat notebook, mengkloning notebook, membuat instans komputasi, dan mengunduh data yang diperlukan untuk tutorial. Langkah-langkahnya juga dijelaskan di bagian berikut.
Prasyarat
-
Untuk menggunakan Azure Pembelajaran Mesin, Anda memerlukan ruang kerja terlebih dahulu. Jika Anda tidak memilikinya, selesaikan Buat sumber daya yang Anda perlukan untuk mulai membuat ruang kerja dan pelajari selengkapnya tentang menggunakannya.
-
Masuk ke studio dan pilih ruang kerja Anda jika belum dibuka.
-
Buka atau buat buku catatan di ruang kerja Anda:
- Buat buku catatan baru, jika Anda ingin menyalin/menempelkan kode ke dalam sel.
- Atau, buka tutorial/get-started-notebooks/explore-data.ipynb dari bagian Sampel studio. Lalu pilih Kloning untuk menambahkan buku catatan ke File Anda. (Lihat tempat menemukan Sampel.)
Atur kernel Anda
Di bilah atas di atas notebook yang Anda buka, buat instans komputasi jika Anda belum memilikinya.

Jika instans komputasi dihentikan, pilih Mulai komputasi dan tunggu hingga instans berjalan.

Pastikan bahwa kernel, yang ditemukan di kanan atas, adalah
Python 3.10 - SDK v2. Jika tidak, gunakan dropdown untuk memilih kernel ini.
Jika Anda melihat banner yang mengatakan Bahwa Anda perlu diautentikasi, pilih Autentikasi.



Penting
Sisa tutorial ini berisi sel-sel buku catatan tutorial. Salin/tempelkan ke buku catatan baru Anda, atau beralihlah ke buku catatan sekarang jika Anda mengkloningnya.
Unduh data yang digunakan dalam tutorial ini
Untuk penyerapan data, Azure Data Explorer menangani data mentah dalam format ini. Tutorial ini menggunakan sampel data klien kartu kredit berformat CSV ini. Kami melihat langkah-langkahnya dilanjutkan di sumber daya Azure Pembelajaran Mesin. Dalam sumber daya tersebut, kita akan membuat folder lokal dengan nama data yang disarankan langsung di bawah folder tempat buku catatan ini berada.
Catatan
Tutorial ini bergantung pada data yang ditempatkan di lokasi folder sumber daya Azure Pembelajaran Mesin. Untuk tutorial ini, 'lokal' berarti lokasi folder di sumber daya Azure Pembelajaran Mesin tersebut.
Pilih Buka terminal di bawah tiga titik, seperti yang ditunjukkan pada gambar ini:
Jendela terminal terbuka di tab baru.
Pastikan Anda
cdke folder yang sama tempat buku catatan ini berada. Misalnya, jika buku catatan berada di folder bernama get-started-notebooks:cd get-started-notebooks # modify this to the path where your notebook is locatedMasukkan perintah ini di jendela terminal untuk menyalin data ke instans komputasi Anda:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvAnda sekarang dapat menutup jendela terminal.
Pelajari selengkapnya tentang data ini di Repositori Pembelajaran Mesin UCI.
Membuat handel ke ruang kerja
Sebelum kami menyelami kode, Anda memerlukan cara untuk mereferensikan ruang kerja Anda. Anda akan membuat ml_client handel ke ruang kerja. Anda kemudian akan menggunakan ml_client untuk mengelola sumber daya dan pekerjaan.
Di sel berikutnya, masukkan ID Langganan, nama Grup Sumber Daya, dan nama Ruang Kerja Anda. Untuk menemukan nilai-nilai ini:
- Di toolbar studio Azure Machine Learning, di kanan atas, pilih nama ruang kerja Anda.
- Salin nilai untuk ruang kerja, grup sumber daya, dan ID langganan ke dalam kode.
- Anda harus menyalin satu nilai, menutup area dan menempelkan, lalu kembali untuk nilai berikutnya.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Catatan
Membuat MLClient tidak akan menghubungkan ke ruang kerja. Inisialisasi klien malas, ia akan menunggu untuk pertama kalinya perlu melakukan panggilan (ini akan terjadi di sel kode berikutnya).
Mengunggah data ke penyimpanan cloud
Azure Pembelajaran Mesin menggunakan Pengidentifikasi Sumber Daya Seragam (URI), yang mengarah ke lokasi penyimpanan di cloud. URI memudahkan untuk mengakses data di buku catatan dan pekerjaan. Format URI data terlihat mirip dengan URL web yang Anda gunakan di browser web Anda untuk mengakses halaman web. Contohnya:
- Mengakses data dari server https publik:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Mengakses data dari Azure Data Lake Gen 2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Aset data Azure Pembelajaran Mesin mirip dengan bookmark browser web (favorit). Alih-alih mengingat jalur penyimpanan panjang (URI) yang menunjuk ke data yang paling sering digunakan, Anda dapat membuat aset data, lalu mengakses aset tersebut dengan nama yang mudah diingat.
Pembuatan aset data juga membuat referensi ke lokasi sumber data, bersama dengan salinan metadatanya. Karena data tetap berada di lokasi yang ada, Anda tidak dikenakan biaya penyimpanan tambahan, dan tidak berisiko integritas sumber data. Anda dapat membuat aset Data dari datastore Azure Pembelajaran Mesin, Azure Storage, URL publik, dan file lokal.
Tip
Untuk unggahan data berukuran lebih kecil, pembuatan aset data Azure Pembelajaran Mesin berfungsi dengan baik untuk pengunggahan data dari sumber daya komputer lokal ke penyimpanan cloud. Pendekatan ini menghindari kebutuhan akan alat atau utilitas tambahan. Namun, unggahan data berukuran lebih besar mungkin memerlukan alat atau utilitas khusus - misalnya, azcopy. Alat baris perintah azcopy memindahkan data ke dan dari Azure Storage. Pelajari selengkapnya tentang azcopy di sini.
Sel buku catatan berikutnya membuat aset data. Sampel kode mengunggah file data mentah ke sumber daya penyimpanan cloud yang ditunjuk.
Setiap kali Anda membuat aset data, Anda memerlukan versi unik untuk itu. Jika versi sudah ada, Anda akan mendapatkan kesalahan. Dalam kode ini, kita menggunakan "inisial" untuk pembacaan pertama data. Jika versi tersebut sudah ada, kita akan melewati pembuatan lagi.
Anda juga dapat menghilangkan parameter versi , dan nomor versi dibuat untuk Anda, dimulai dengan 1 dan kemudian bertahap dari sana.
Dalam tutorial ini, kami menggunakan nama "inisial" sebagai versi pertama. Tutorial Membuat alur pembelajaran mesin produksi juga akan menggunakan versi data ini, jadi di sini kita menggunakan nilai yang akan Anda lihat lagi dalam tutorial tersebut.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Anda dapat melihat data yang diunggah dengan memilih Data di sebelah kiri. Anda akan melihat data diunggah dan aset data dibuat:
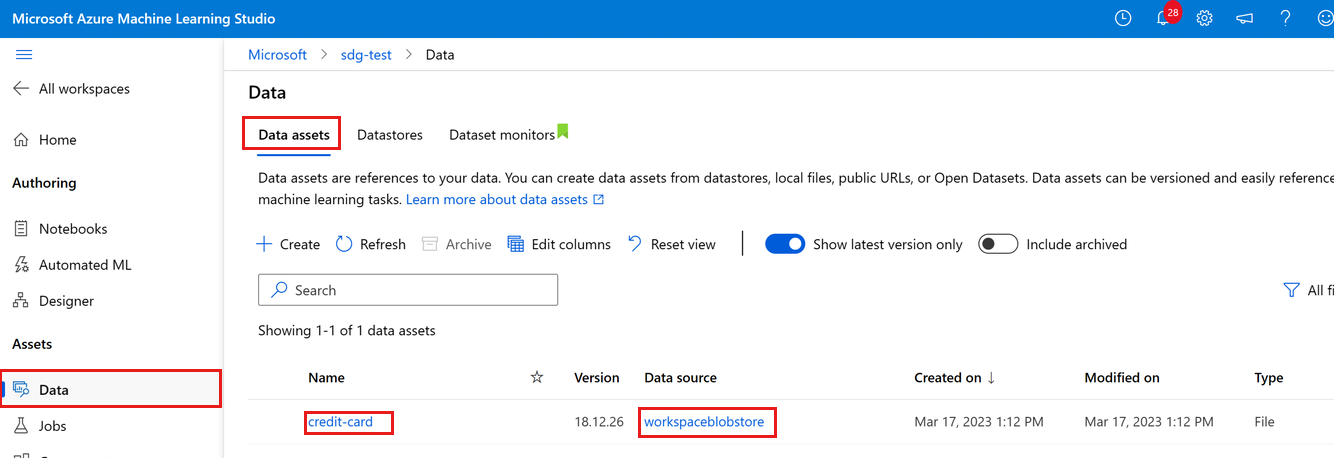
Data ini diberi nama kartu kredit, dan di tab Aset data, kita dapat melihatnya di kolom Nama . Data ini diunggah ke datastore default ruang kerja Anda bernama workspaceblobstore, yang terlihat di kolom Sumber data .
Datastore Azure Pembelajaran Mesin adalah referensi ke akun penyimpanan yang sudah ada di Azure. Datastore menawarkan manfaat berikut:
- API umum dan mudah digunakan, untuk berinteraksi dengan berbagai jenis penyimpanan (Blob/Files/Azure Data Lake Storage) dan metode autentikasi.
- Cara yang lebih mudah untuk menemukan penyimpanan data yang berguna, saat bekerja sebagai tim.
- Dalam skrip Anda, cara untuk menyembunyikan informasi koneksi untuk akses data berbasis kredensial (perwakilan layanan/SAS/kunci).
Mengakses data Anda di buku catatan
Panda secara langsung mendukung URI - contoh ini menunjukkan cara membaca file CSV dari Azure Pembelajaran Mesin Datastore:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Namun, seperti yang disebutkan sebelumnya, bisa menjadi sulit untuk mengingat URI ini. Selain itu, Anda harus mengganti semua <nilai substring> secara manual dalam perintah pd.read_csv dengan nilai nyata untuk sumber daya Anda.
Anda mungkin ingin membuat aset data untuk data yang sering diakses. Berikut adalah cara yang lebih mudah untuk mengakses file CSV di Pandas:
Penting
Di sel buku catatan, jalankan kode ini untuk menginstal azureml-fsspec pustaka Python di kernel Jupyter Anda:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Baca Mengakses data dari penyimpanan cloud Azure selama pengembangan interaktif untuk mempelajari selengkapnya tentang akses data di buku catatan.
Membuat versi baru aset data
Anda mungkin telah memperhatikan bahwa data membutuhkan sedikit pembersihan ringan, agar pas untuk melatih model pembelajaran mesin. Ini memiliki:
- dua header
- kolom ID klien; kami tidak akan menggunakan fitur ini di Pembelajaran Mesin
- spasi dalam nama variabel respons
Selain itu, dibandingkan dengan format CSV, format file Parquet menjadi cara yang lebih baik untuk menyimpan data ini. Parquet menawarkan kompresi, dan mempertahankan skema. Oleh karena itu, untuk membersihkan data dan menyimpannya di Parquet, gunakan:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Tabel ini memperlihatkan struktur data dalam file default_of_credit_card_clients.csv asli . File CSV diunduh pada langkah sebelumnya. Data yang diunggah berisi 23 variabel penjelasan dan 1 variabel respons, seperti yang ditunjukkan di sini:
| Nama Kolom | Tipe Variabel | Deskripsi |
|---|---|---|
| X1 | Jelas | Jumlah kredit yang diberikan (dolar NT): termasuk kredit konsumen individu dan kredit keluarga mereka (tambahan). |
| X2 | Jelas | Jenis kelamin (1 = laki-laki; 2 = perempuan). |
| X3 | Jelas | Pendidikan (1 = sekolah pascasarjana; 2 = universitas; 3 = SMA; 4 = lainnya). |
| X4 | Jelas | Status perkawinan (1 = menikah; 2 = tunggal; 3 = lainnya). |
| X5 | Jelas | Usia (tahun). |
| X6-X11 | Jelas | Riwayat pembayaran sebelumnya. Kami melacak catatan pembayaran bulanan terakhir (dari April hingga September 2005). -1 = bayar duly; 1 = penundaan pembayaran selama satu bulan; 2 = penundaan pembayaran selama dua bulan; . . .; 8 = penundaan pembayaran selama delapan bulan; 9 = penundaan pembayaran selama sembilan bulan ke atas. |
| X12-17 | Jelas | Jumlah laporan tagihan (dolar NT) dari April hingga September 2005. |
| X18-23 | Jelas | Jumlah pembayaran sebelumnya (dolar NT) dari April hingga September 2005. |
| Y | Respons | Pembayaran default (Ya = 1, Tidak = 0) |
Selanjutnya, buat versi baru aset data (data secara otomatis diunggah ke penyimpanan cloud). Untuk versi ini, kita akan menambahkan nilai waktu, sehingga setiap kali kode ini dijalankan, nomor versi yang berbeda akan dibuat.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
File parkek yang dibersihkan adalah sumber data versi terbaru. Kode ini menunjukkan kumpulan hasil versi CSV terlebih dahulu, lalu versi Parquet:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Membersihkan sumber daya
Jika Anda berencana untuk melanjutkan sekarang ke tutorial lain, lewati ke Langkah berikutnya.
Menghentikan instans komputasi
Jika Anda tidak akan menggunakannya sekarang, hentikan instans komputasi:
- Di studio, di area navigasi kiri, pilih Komputasi.
- Di tab atas, pilih Instans komputasi
- Pilih instans komputasi dalam daftar.
- Di toolbar atas, pilih Hentikan.
Menghapus semua sumber daya
Penting
Sumber daya yang Anda buat sebagai prasyarat untuk tutorial dan artikel cara penggunaan Azure Machine Learning lainnya.
Jika Anda tidak berencana menggunakan sumber daya yang sudah Anda buat, hapus sehingga Anda tidak dikenakan biaya apa pun:
Dari portal Microsoft Azure, pilih Grup sumber daya dari sisi sebelah kiri.
Dari daftar, pilih grup sumber daya yang Anda buat.
Pilih Hapus grup sumber daya.
Masukkan nama grup sumber daya. Kemudian pilih Hapus.
Langkah berikutnya
Baca Membuat aset data untuk informasi selengkapnya tentang aset data.
Baca Membuat penyimpanan data untuk mempelajari selengkapnya tentang penyimpanan data.
Lanjutkan dengan tutorial untuk mempelajari cara mengembangkan skrip pelatihan.