Apache Spark di Azure Synapse Analytics
Apache Spark merupakan kerangka kerja pemrosesan paralel yang mendukung pemrosesan dalam memori untuk meningkatkan performa aplikasi analitik big data. Apache Spark di Azure Synapse Analytics adalah salah satu implementasi Microsoft dari Apache Spark di cloud. Azure Synapse memudahkan pembuatan dan konfigurasi kumpulan Apache Spark tanpa server di Azure. Kumpulan spark di Azure Synapse kompatibel dengan Azure Storage dan Azure Data Lake Generation 2 Storage. Jadi Anda dapat menggunakan kumpulan Spark untuk memproses data Anda yang disimpan di Azure.
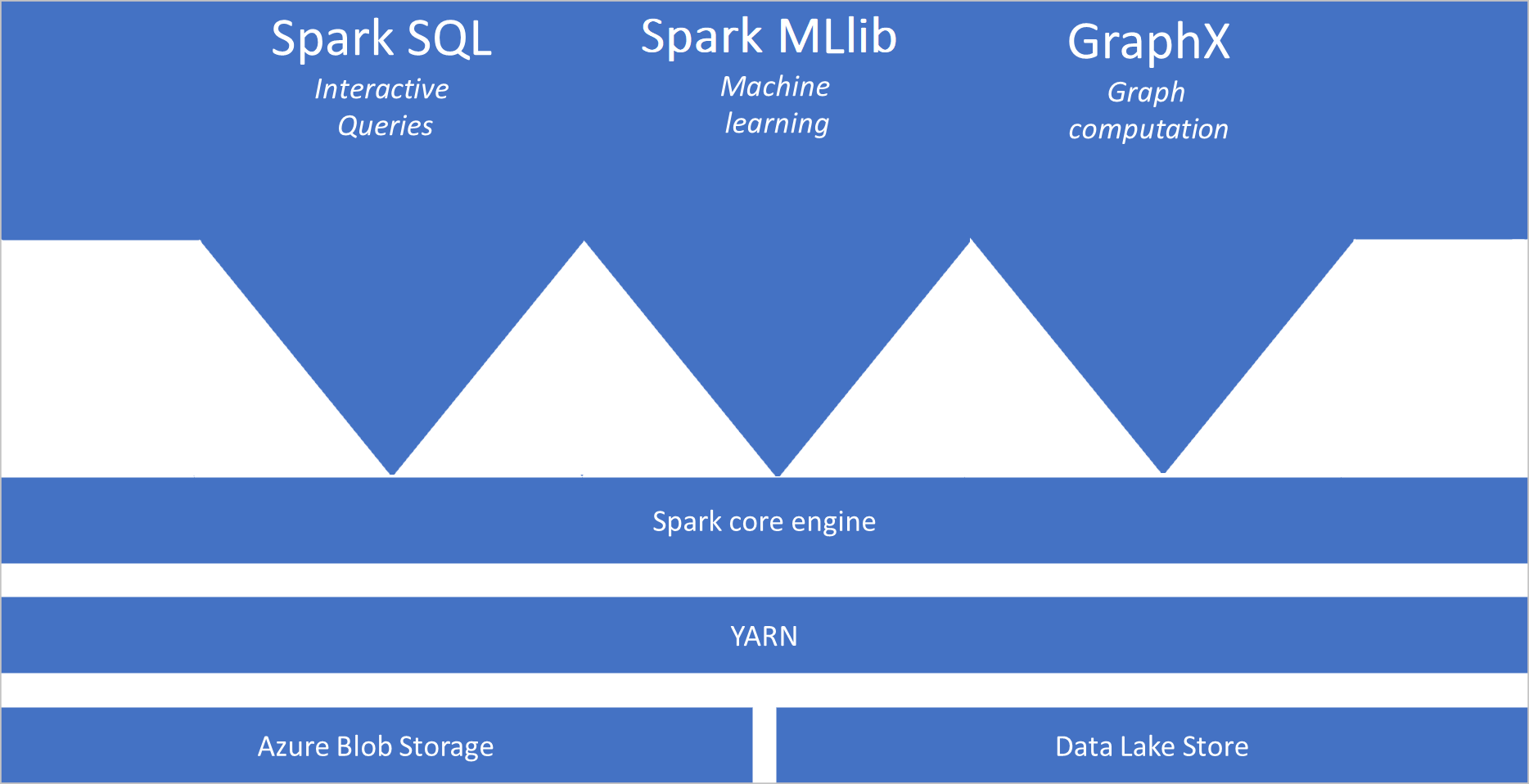
Apa yang dimaksud dengan Apache Spark
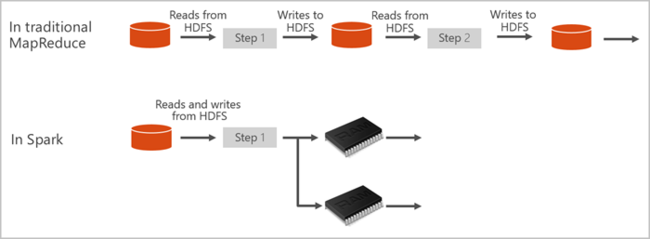
Apache menyediakan primitif untuk komputasi kluster dalam memori. Spark digunakan untuk memuat dan menyimpan data ke dalam memori dan memintanya berulang kali. Komputasi dalam memori jauh lebih cepat daripada aplikasi berbasis disk. Spark juga terintegrasi dengan beberapa bahasa pemrogram untuk memungkinkan Anda mengubah himpunan data terdistribusi seperti koleksi lokal. Tidak perlu menyusun semuanya sebagai peta dan mengurangi operasi. Anda dapat mempelajari lebih lanjut dari video Apache Spark for Synapse.
Kumpulan Spark di Azure Synapse menawarkan layanan Spark yang dikelola sepenuhnya. Manfaat membuat kumpulan Spark di Azure Synapse Analytics tercantum di sini.
| Fitur | Deskripsi |
|---|---|
| Kecepatan dan efisiensi | Instans Spark dimulai dalam waktu sekitar 2 menit untuk kurang dari 60 simpul dan sekitar 5 menit untuk lebih dari 60 simpul. Instans dinonaktifkan, secara default, 5 menit setelah pekerjaan terakhir dijalankan kecuali dibiarkan hidup oleh koneksi notebook. |
| Kemudahan penciptaan | Anda dapat membuat kumpulan Spark baru di Azure Synapse dalam hitungan menit menggunakan portal Microsoft Azure, Azure PowerShell, atau Synapse Analytics .NET SDK. Lihat Mulai menggunakan kumpulan Spark di Azure Synapse Analytics. |
| Kemudahan penggunaan | Synapse Analytics menyertakan notebook kustom yang berasal dari nteract. Anda bisa menggunakan buku catatan ini untuk visualisasi dan pemrosesan data interaktif. |
| REST API | Spark di Azure Synapse Analytics mencakup Apache Livy, server pekerjaan Spark berbasis REST API untuk mengirimkan dan memantau pekerjaan dari jarak jauh. |
| Dukungan untuk Azure Data Lake Storage Generation 2 | Kumpulan Spark di Azure Synapse dapat menggunakan Azure Data Lake Storage Generation 2 serta penyimpanan BLOB. Untuk mengetahui informasi selengkapnya tentang Data Lake Storage, lihat Ringkasan Azure Data Lake Storage. |
| Integrasi dengan ID pihak ketiga | Azure Synapse menyediakan plugin IDE untuk JetBrains' IntelliJ IDEA yang berguna untuk membuat dan mengirimkan aplikasi ke kumpulan Spark. |
| Pustaka Anaconda yang telah dimuat sebelumnya | Kolam Spark di Azure Synapse dilengkapi dengan pustaka Anaconda yang telah dipasang sebelumnya. Anaconda menyediakan hampir 200 pustaka untuk pembelajaran mesin, analisis data, visualisasi, dan sebagainya. |
| Skalabilitas | Apache Spark pada kumpulan Azure Synapse dapat mengaktifkan Auto-Scale, sehingga kumpulan tersebut menskalakan dengan menambahkan atau menghapus simpul sesuai kebutuhan. Selain itu, kumpulan Spark dapat dimatikan tanpa kehilangan data karena semua data disimpan di Azure Storage atau Data Lake Storage. |
Kumpulan Spark di Azure Synapse menyertakan komponen berikut ini yang tersedia pada kumpulan secara default:
- Spark Core. Termasuk Spark Core, Spark SQL, GraphX, and MLlib.
- Anaconda
- Apache Livy
- buku catatan nteract
Arsitektur kolam Spark
Aplikasi Spark berjalan sebagai serangkaian proses independen pada kumpulan, dikoordinasikan oleh objek SparkContext pada program utama Anda, yang disebut program driver.
SparkContext dapat terhubung ke manajer kluster, yang mengalokasikan sumber daya di seluruh aplikasi. Manajer kluster adalah Apache Hadoop YARN. Setelah terhubung, Spark memperoleh eksekutor pada node di kumpulan, yang merupakan proses yang menjalankan komputasi dan menyimpan data untuk aplikasi Anda. Selanjutnya, ia mengirimkan kode aplikasi Anda, didefinisikan oleh file JAR atau Python yang diteruskan ke SparkContext, ke pelaksana. Akhirnya, SparkContext mengirim tugas ke pelaksana untuk dijalankan.
SparkContext menjalankan fungsi utama pengguna dan menjalankan berbagai operasi paralel pada simpul. Kemudian, SparkContext mengumpulkan hasil operasi. Node membaca dan menulis data dari dan ke sistem file. Node juga menyimpan data yang diubah dalam memori sebagai Resilient Distributed Datasets (RDDs).
SparkContext terhubung ke kumpulan Spark dan bertanggung jawab untuk mengonversi aplikasi ke grafik asiklik terarah (DAG). Grafik terdiri dari tugas individual yang dijalankan dalam proses eksekutor pada node. Setiap aplikasi mendapatkan proses eksekutornya sendiri, yang tetap terjaga selama seluruh aplikasi dan tugas eksekusi di beberapa utas.
Apache Spark di Azure Synapse Analytics menggunakan kasus
Kumpulan Spark di Azure Synapse Analytics mengaktifkan skenario utama berikut:
- Teknisi Data/Penyiapan Data
Apache Spark mencakup banyak fitur bahasa untuk mendukung penyiapan dan pemrosesan data dalam volume besar sehingga dapat dibuat lebih berharga, lalu digunakan oleh layanan lain dalam Azure Synapse Analytics. Layanan ini diaktifkan melalui beberapa bahasa (C#, Scala, PySpark, Spark SQL) dan pustaka yang disediakan untuk pemrosesan dan konektivitas.
- Machine Learning
Apache Spark dilengkapi dengan MLlib, pustaka pembelajaran mesin yang dibangun pada Spark yang dapat Anda gunakan dari kumpulan Spark di Azure Synapse Analytics. Kumpulan Spark di Azure Synapse Analytics juga mencakup Anaconda, distribusi Python dengan berbagai paket untuk data science termasuk pembelajaran mesin. Saat dipadukan dengan dukungan bawaan untuk buku catatan, Anda memiliki lingkungan untuk membuat aplikasi pembelajaran mesin.
- Data Streaming
Synapse Spark mendukung streaming terstruktur Spark selama Anda menjalankan versi rilis runtime Azure Synapse Spark yang didukung. Semua pekerjaan didukung untuk hidup selama tujuh hari. Ini berlaku untuk pekerjaan batch dan streaming, dan umumnya, pelanggan mengotomatiskan proses hidupkan ulang menggunakan Azure Functions.
Di mana saya harus memulai
Gunakan artikel berikut untuk mempelajari selengkapnya tentang Apache Spark di Azure Synapse Analytics:
- Mulai cepat: Membuat kumpulan Spark di Azure Synapse
- Mulai cepat: Membuat buku catatan Apache Spark
- Tutorial: Pembelajaran mesin menggunakan Apache Spark
Catatan
Beberapa dokumentasi resmi Apache Spark bergantung pada penggunaan konsol Spark, yang tidak tersedia dalam Azure Synapse Spark. Gunakan pengalaman notebook atau IntelliJ sebagai gantinya.
Langkah berikutnya
Dalam ringkasan ini, Anda mendapatkan pemahaman dasar tentang Apache Spark di Azure Synapse Analytics. Lanjutkan ke artikel berikutnya untuk mempelajari cara membuat kumpulan Spark di Azure Synapse Analytics: