Antipattern I/O "frammentato"
L'effetto cumulativo di un numero elevato di richieste di I/O può avere un impatto significativo sulle prestazioni e la velocità di risposta.
Descrizione del problema
Chiamate di rete e altre operazioni di I/O sono intrinsecamente lente rispetto all'attività di calcolo. Ogni richiesta di I/O è in genere presenta un overhead significativo e l'effetto cumulativo di numerose operazioni di I/O può rallentare il sistema. Di seguito sono riportate alcune cause comuni di I/O "frammentato".
Lettura e scrittura di singoli record in un database come richieste distinte
L'esempio seguente legge da un database di prodotti. Sono presenti tre tabelle, Product, ProductSubcategory e ProductPriceListHistory. Il codice recupera tutti i prodotti in una sottocategoria, insieme alle informazioni sui prezzi, eseguendo una serie di query:
- Eseguire una query per la sottocategoria sulla tabella
ProductSubcategory. - Trovare tutti i prodotti in tale sottocategoria eseguendo una query sulla tabella
Product. - Per ogni prodotto eseguire una query sui dati dei prezzi della tabella
ProductPriceListHistory.
L'applicazione usa Entity Framework per eseguire query sul database. L'esempio completo è disponibile qui.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
Questo esempio illustra il problema in modo esplicito, ma talvolta un O/RM può mascherare il problema, se recupera in modo implicito i record figlio uno alla volta. Questo è noto come "problema N+1".
Implementazione di una singola operazione logica come una serie di richieste HTTP
Ciò accade spesso quando gli sviluppatori tentano di seguire un paradigma a oggetti e trattano gli oggetti remoti come se fossero oggetti locali in memoria. Questo può comportare troppi round trip di rete. Ad esempio, l'API Web seguente espone le singole proprietà degli oggetti User tramite i singoli metodi HTTP GET.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
Anche se non c'è niente di tecnicamente errato in questo approccio, la maggior parte dei client probabilmente dovrà ottenere molte proprietà per ogni User, di conseguenza il codice client sarà simile al seguente.
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
Lettura e scrittura in un file su disco
L'I/O su file comporta l'apertura di un file e lo spostamento nel punto appropriato prima di leggere o scrivere i dati. Una volta completata l'operazione, il file può essere chiuso per risparmiare risorse del sistema operativo. Un'applicazione che legge e scrive continuamente piccole quantità di informazioni in un file genererà un considerevole sovraccarico di I/O. Anche le richieste di scrittura di piccole dimensioni possono provocare la frammentazione dei file, rallentando ulteriormente le successive operazioni di I/O.
Il seguente esempio usa un FileStream per scrivere un oggetto Customer in un file. Creando il FileStream, il file viene aperto, ed eliminandolo, il file viene chiuso L'istruzione using elimina automaticamente l'oggetto FileStream . Se l'applicazione chiama ripetutamente questo metodo man mano che vengono aggiunti nuovi clienti, l'overhead di I/O può accumularsi rapidamente.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
Come risolvere il problema
Ridurre il numero di richieste di I/O assemblando i dati in un numero inferiore di richieste di dimensioni maggiore.
Recuperare i dati da un database in una singola query, anziché in più query di dimensioni inferiori. Di seguito è riportata una versione modificata del codice che consente di recuperare informazioni sui prodotti.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
Seguire i principi di progettazione REST per le API Web. Di seguito è riportata una versione modificata dell'API Web dell'esempio precedente. Anziché metodi GET separati per ogni proprietà, c'è un singolo metodo GET che restituisce il User. Di conseguenza, il corpo di risposta per ogni richiesta ha dimensioni maggiori, ma è probabile che ogni client esegua un numero inferiore di chiamate API.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
Per l'I/O su file, considerare di memorizzare nel buffer i dati in memoria e quindi scrivere i dati memorizzati nel buffer in un file in una singola operazione. Questo approccio riduce il sovraccarico dato dall'aprire e chiudere il file ripetutamente e consente di ridurre la frammentazione dei file su disco.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
Considerazioni
I primi due esempi generano meno chiamate di I/O, ma ognuno recupera più informazioni. È necessario considerare il compromesso tra questi due fattori. La risposta esatta varia in base agli schemi di utilizzo effettivi. Ad esempio, nell'esempio dell'API Web, potrebbe risultare che i client richiedono spesso solo il nome utente. In tal caso, può rivelarsi utile esporlo come una chiamata API distinta. Per altre informazioni, vedere l'antipattern di Recupero estraneo.
Durante la lettura dei dati, non eseguire richieste di I/O troppo grandi. Un'applicazione deve recuperare solo le informazioni che è probabile che vengano utilizzate.
Talvolta è utile partizionare le informazioni per un oggetto in due blocchi, dati con accesso frequente, che sono responsabili della maggior parte delle richieste, e dati ad accesso meno frequente, utilizzati raramente. Spesso i dati utilizzati più di frequente sono una parte relativamente piccola dei dati totali per un oggetto, pertanto restituire solo questa parte permette di risparmiare un considerevole sovraccarico di I/O.
Durante la scrittura dei dati, evitare di bloccare risorse più a lungo del necessario, per ridurre le probabilità di contesa durante un'operazione di lunga durata. Se un'operazione di scrittura si estende su più archivi dati, file o i servizi, adottare un approccio finale coerente. Vedere il materiale sussidiario sulla coerenza dei dati.
Se si memorizzano i dati in memoria prima della loro scrittura, i dati sono vulnerabili in caso di arresto anomalo del processo. Se la velocità dei dati è soggetta a picchi o è relativamente sparsa, potrebbe essere preferibile memorizzare nel buffer i dati utilizzando una coda durevole esterna, ad esempio Hub eventi.
Si più prendere in considerazione di memorizzare nella cache i dati recuperati da un servizio o da un database. Ciò consente di ridurre il volume di I/O, evitando richieste ripetute per gli stessi dati. Per altre informazioni, vedere Procedure consigliate per la memorizzazione nella cache.
Come rilevare il problema
I sintomi dell'I/O "frammentato" includono una latenza elevata e una bassa velocità effettiva. Gli utenti finali riferiscono in genere tempi di risposta prolungati o errori causati dal timeout dei servizi a causa della maggiore contesa per le risorse di I/O.
È possibile eseguire la procedura seguente per identificare la causa di qualsiasi problema:
- Eseguire il monitoraggio del processo per il sistema di produzione per identificare le operazioni con tempi di risposta più lunghi.
- Eseguire test di carico di ogni operazione identificata nel passaggio precedente.
- Durante i test di carico, raccogliere dati di telemetria sulle richieste di accesso ai dati eseguite da ogni operazione.
- Raccogliere statistiche dettagliate per ogni richiesta inviata a un archivio dati.
- Profilare l'applicazione nell'ambiente di test per stabilire dove potrebbero verificarsi possibili colli di bottiglia di I/O.
Cercare uno qualsiasi dei seguenti sintomi:
- Un numero elevato di richieste di I/O di piccole dimensioni eseguite verso lo stesso file.
- Un numero elevato di richieste di rete di piccole dimensioni eseguite da un'istanza di applicazione verso lo stesso servizio.
- Un numero elevato di richieste di piccole dimensioni eseguite da un'istanza di applicazione verso lo stesso archivio dati.
- Applicazioni e servizi che diventano associati all'I/O.
Diagnosi di esempio
Nelle sezioni seguenti si applicano questi passaggi all'esempio illustrato in precedenza che esegue query in un database.
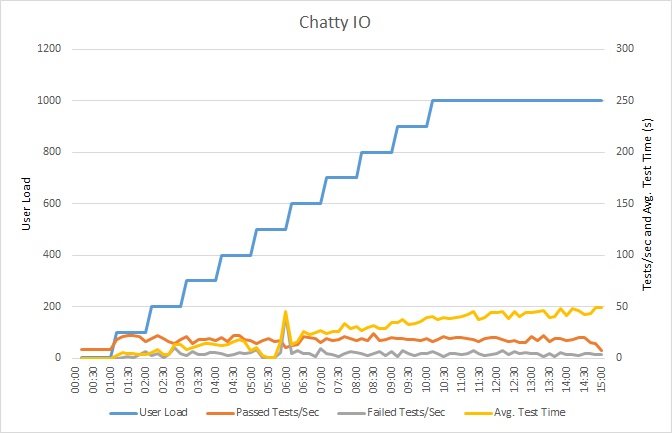
Testare il carico dell'applicazione
Questo grafico mostra i risultati del test di carico. Il tempo di risposta mediano viene misurato in decimi di secondo per richiesta. Il grafico mostra una latenza molto elevata. Con un carico di 1000 utenti, un utente potrebbe dover attendere circa un minuto per visualizzare i risultati di una query.
Nota
L'applicazione è stata distribuita come un'app Web del Servizio App di Azure, utilizzando il database SQL di Azure. Il test di carico utilizzava un carico di lavoro simulato a passaggi fino a un massimo di 1000 utenti simultanei. Il database è stato configurato con un pool di connessioni che supporta un massimo di 1000 connessioni simultanee, per ridurre le probabilità che una contesa per le connessioni possa influire sui risultati.
Monitorare l'applicazione
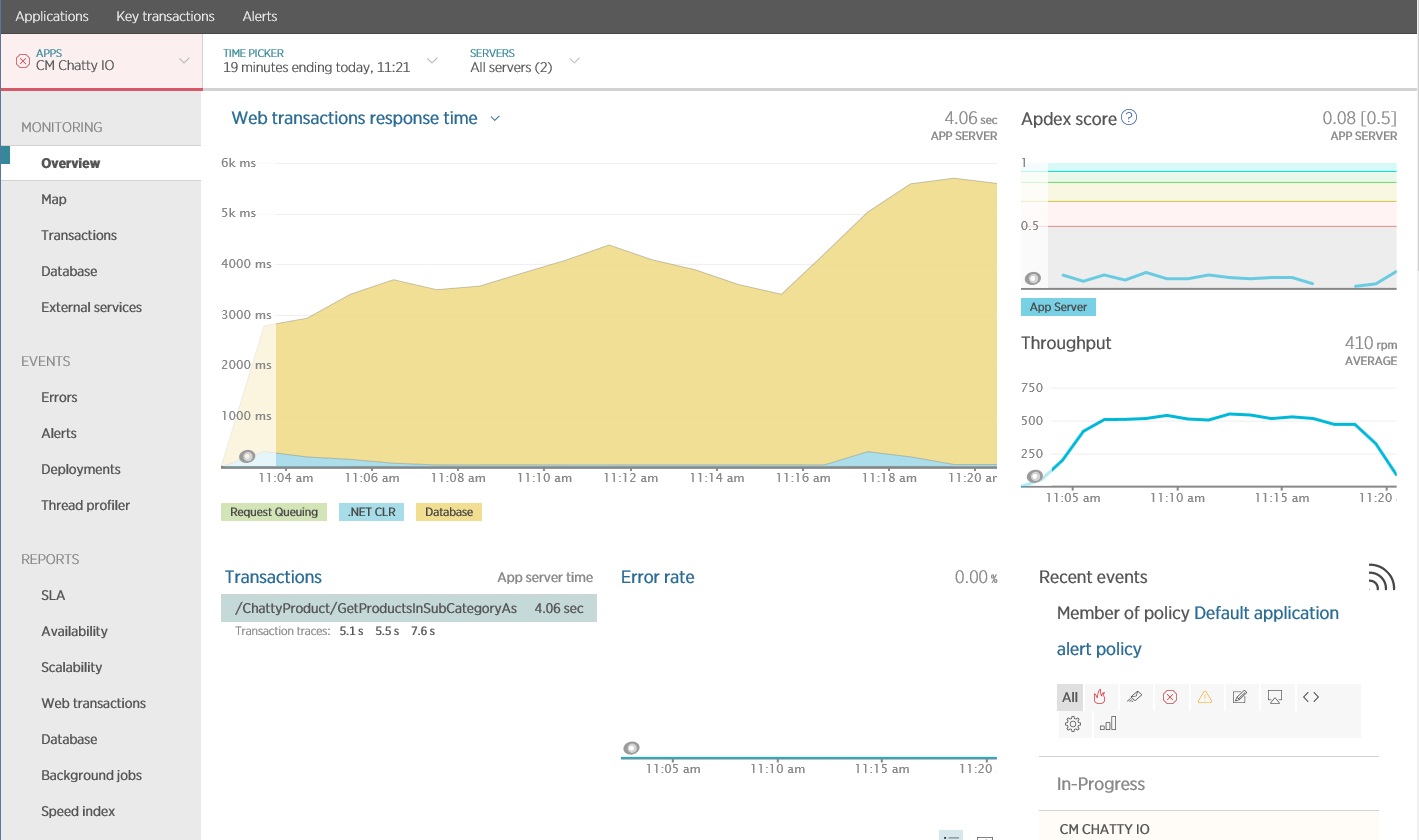
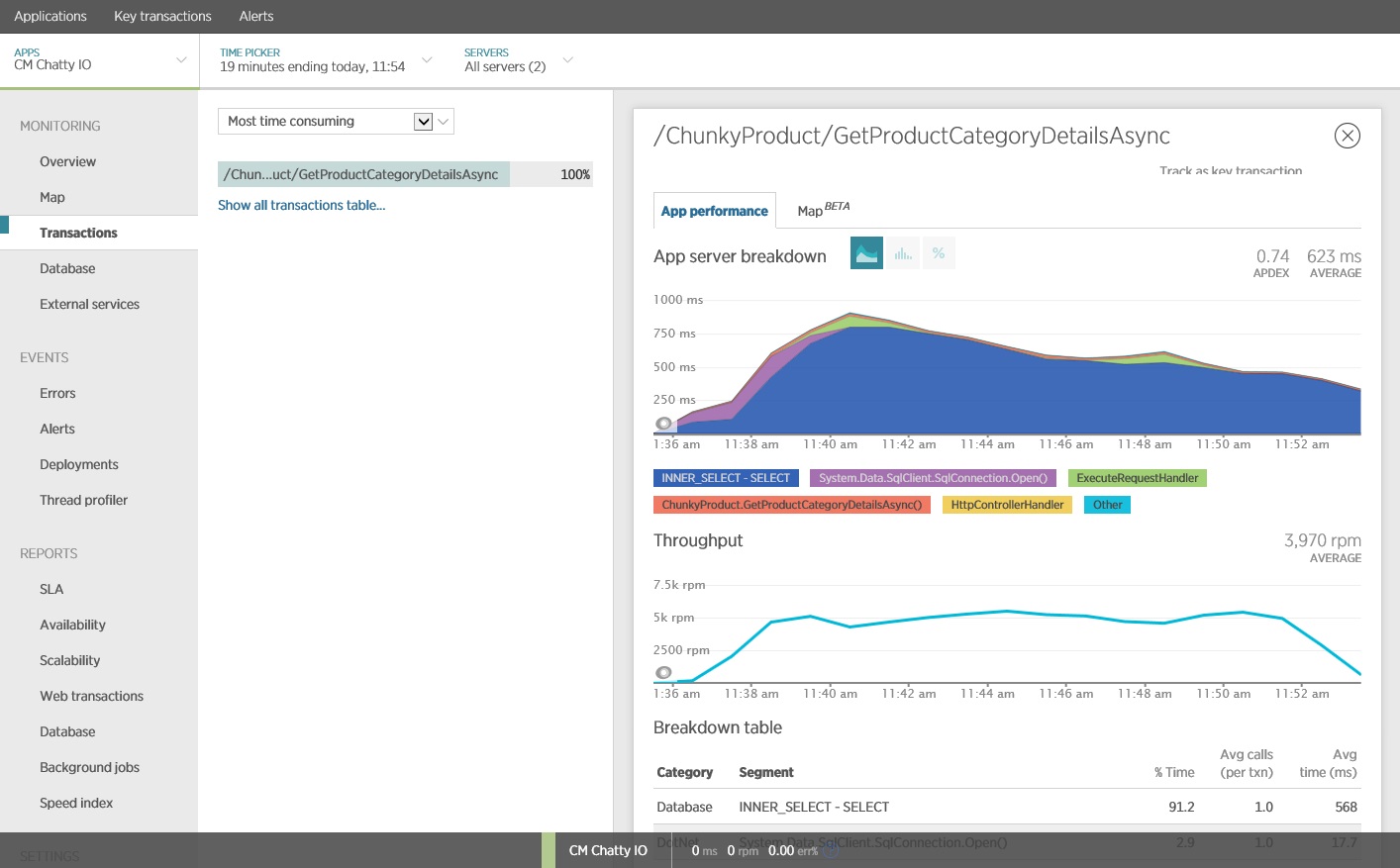
È possibile usare una pacchetto di monitoraggio delle prestazioni di applicazione (APM) per acquisire e analizzare le metriche chiave che potrebbero identificare I/O "frammentato". Quali metriche sono importanti dipende dal carico di lavoro di I/O. Per questo esempio, le richieste di I/O interessanti erano le query di database.
La figura seguente mostra i risultati generati utilizzando l'APM New Relic. Il tempo di risposta medio del database ha avuto un picco a circa 5,6 secondi per ogni richiesta durante il carico di lavoro massimo. Il sistema è in grado di supportare una media di 410 richieste al minuto per tutto il test.
Raccogliere informazioni di accesso ai dati dettagliate
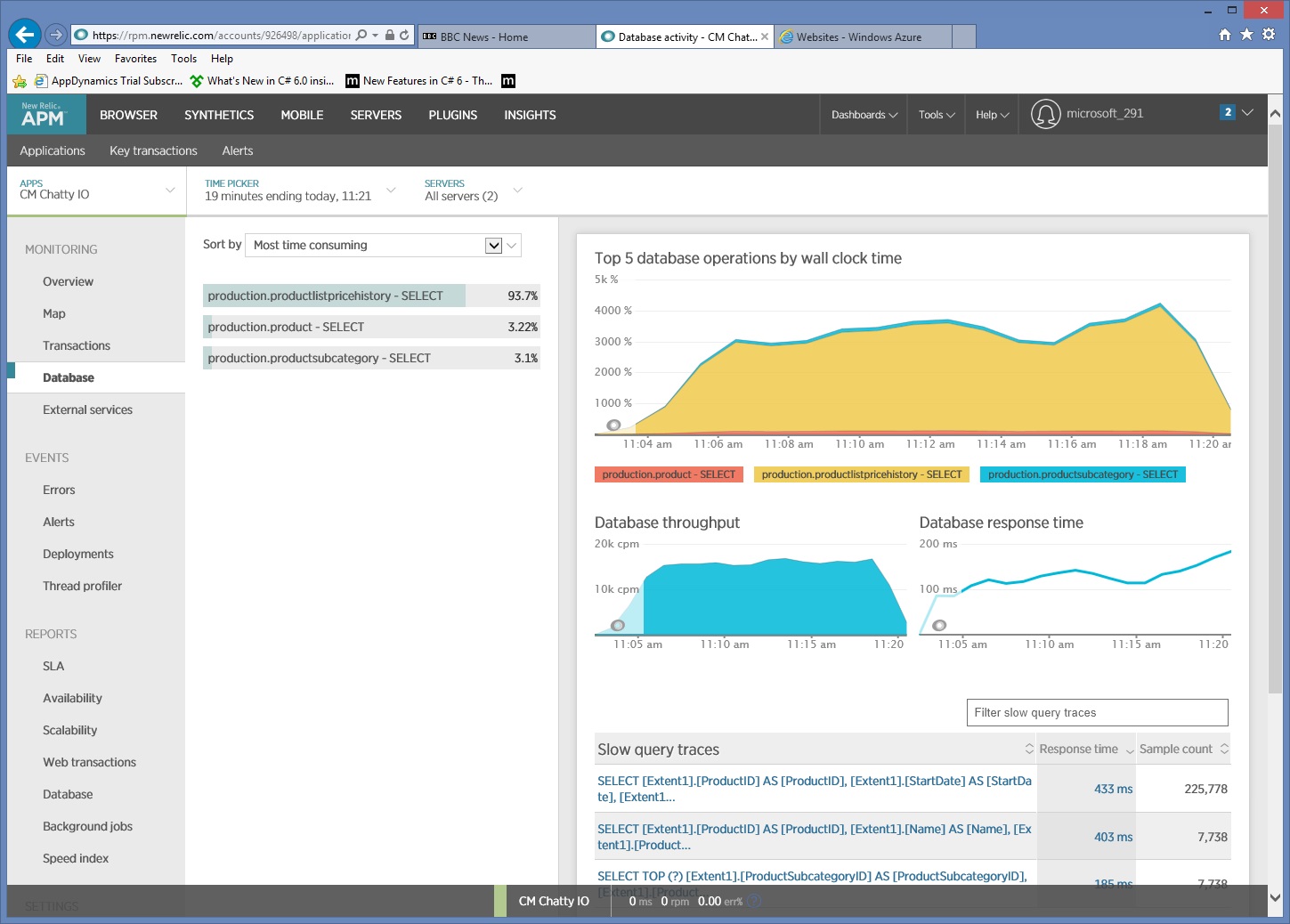
Alcuni approfondimenti nei dati di monitoraggio illustrano che l'applicazione esegue tre diverse istruzioni SQL SELECT. Queste corrispondono alle richieste generate da Entity Framework per recuperare i dati dalle tabelle ProductListPriceHistory, Product e ProductSubcategory. Inoltre, la query che recupera i dati dalla tabella ProductListPriceHistory è di gran lunga l'istruzione SELECT eseguita più di frequente, di un ordine di grandezza.
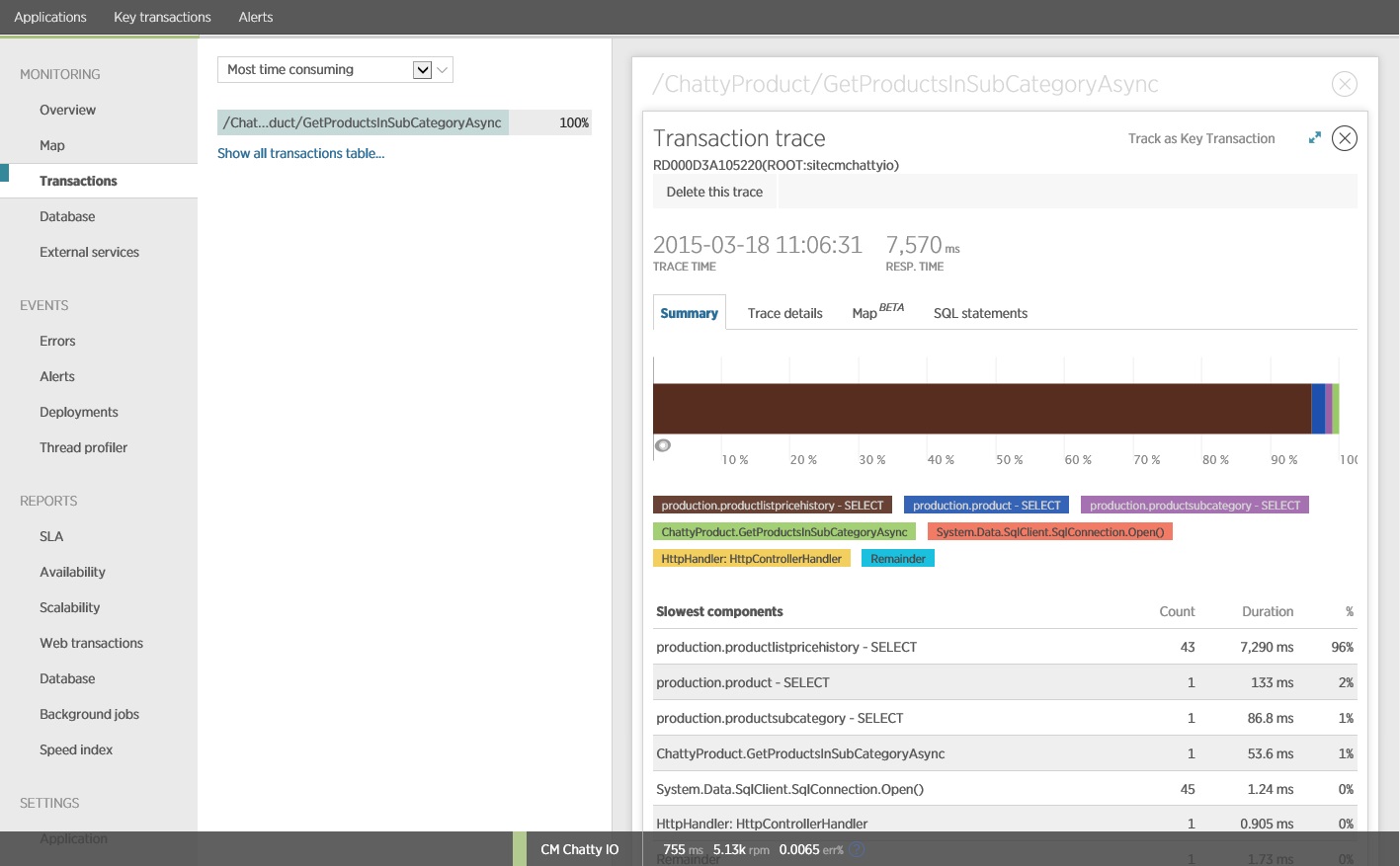
Si scopre che il metodo GetProductsInSubCategoryAsync, illustrato in precedenza, esegue 45 query SELECT. Ogni query induce l'applicazione ad aprire una nuova connessione SQL.
Nota
Questa immagine mostra le informazioni di traccia per l'istanza più lenta dell'operazione GetProductsInSubCategoryAsync nel test di carico. In un ambiente di produzione è utile esaminare le tracce delle istanze più lente, per verificare se esiste un modello che indica un problema. Se si osservano solo i valori medi, si potrebbero tralasciare i problemi che peggioreranno notevolmente in condizioni di carico.
La figura seguente mostra le istruzioni SQL effettive che sono state eseguite. La query che recupera le informazioni sui prezzi Viene eseguita per ogni singolo prodotto nella sottocategoria del prodotto. Utilizzando un join si potrebbe ridurre notevolmente il numero di chiamate al database.
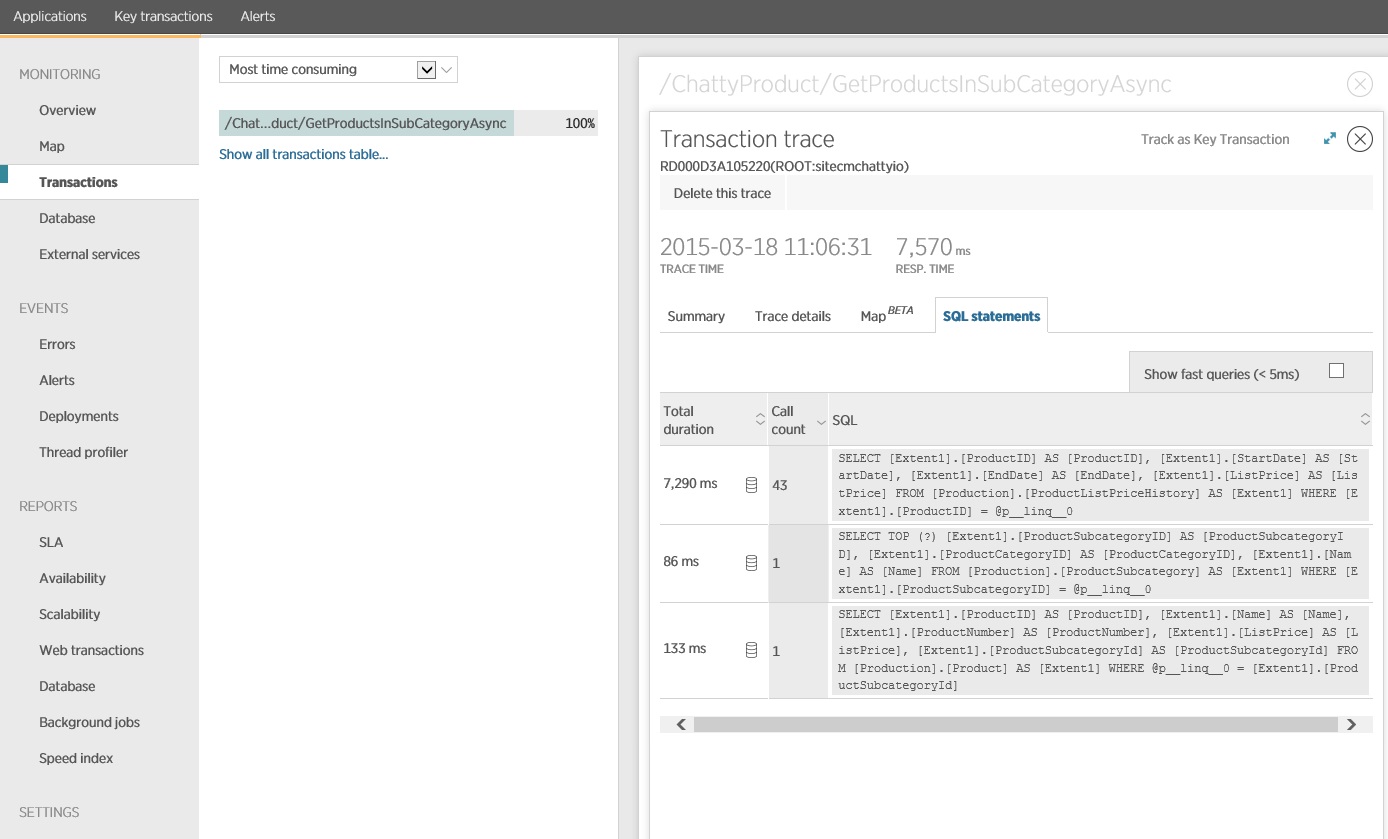
Se si utilizza un O/RM, ad esempio Entity Framework, il monitoraggio delle query SQL può consentire di comprendere la modalità in cui O/RM converte le chiamate a livello di codice in istruzioni SQL e indicare le aree in cui l'accesso ai dati può essere ottimizzato.
Implementare la soluzione e verificare il risultato
Riscrivendo la chiamata a Entity Framework sono stati ottenuti i risultati seguenti.
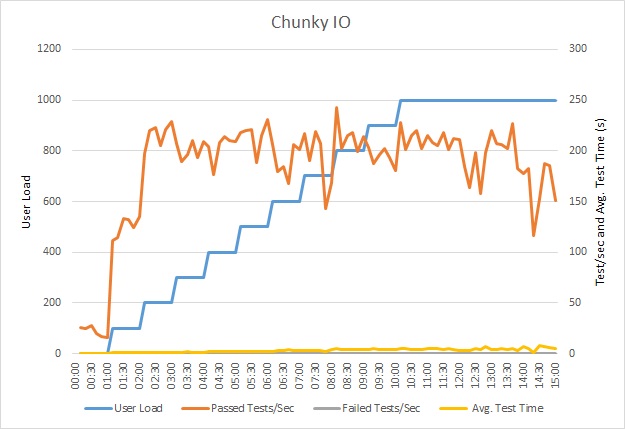
Questo test di carico è stato eseguito nella stessa distribuzione, utilizzando lo stesso profilo di carico. Questa volta grafico mostra una latenza molto inferiore. Il tempo medio di richiesta con 1000 utenti è compreso tra 5 e 6 secondi, più basso di circa un minuto.
Questa volta il sistema ha supportato una media di 3.970 richieste al minuto, rispetto alle 410 per il test precedente.
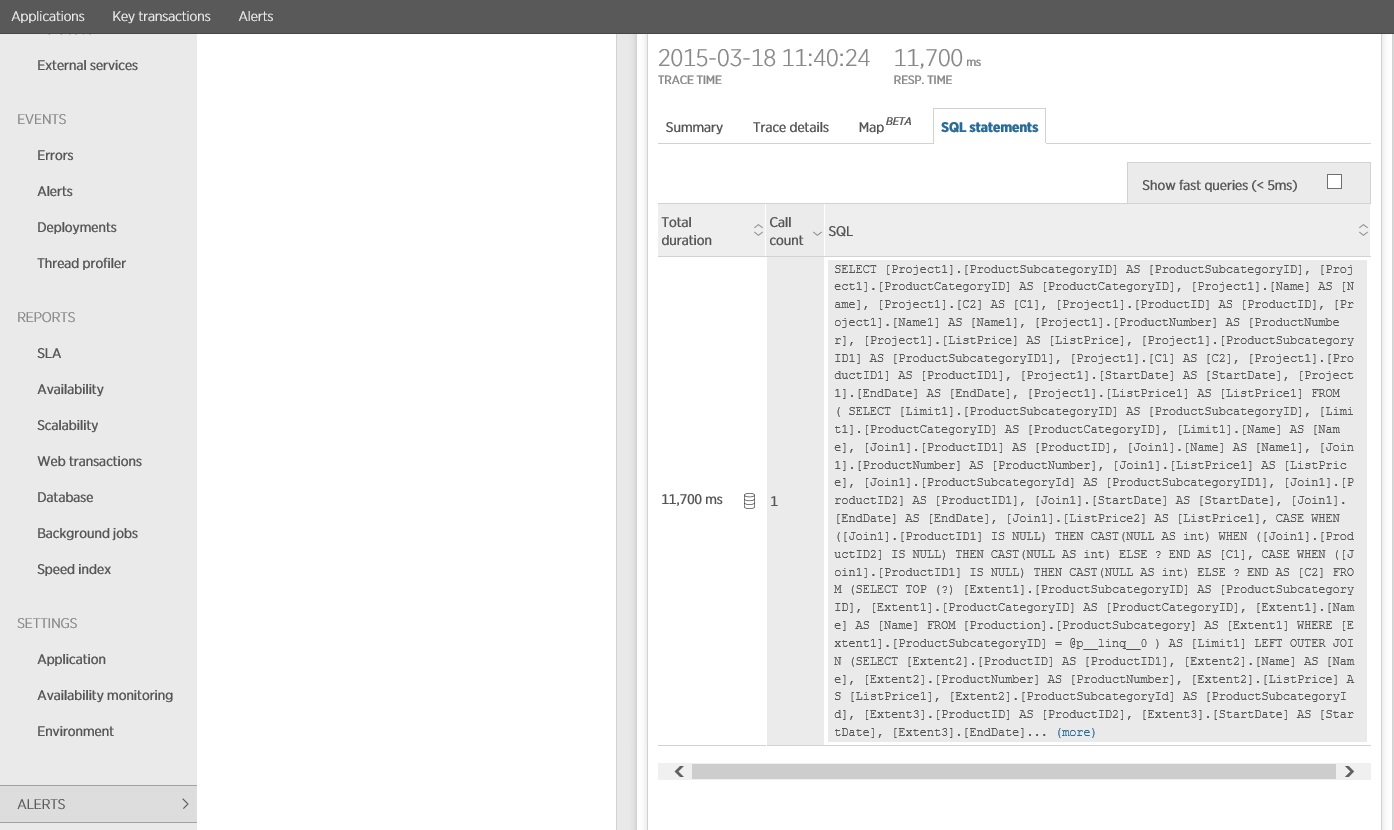
Monitorando l'istruzione SQL si vede che tutti i dati vengono recuperati in una singola istruzione SELECT. Anche se questa query è notevolmente più complessa, viene eseguita una sola volta per ogni operazione. E mentre i join complessi possono diventare costosi, i sistemi di database relazionali sono ottimizzati per questo tipo di query.
Risorse correlate
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per