Usare i dashboard per visualizzare le metriche di Azure Databricks
Nota
Questo articolo si basa su una libreria open source ospitata in GitHub all'indirizzo: https://github.com/mspnp/spark-monitoring.
La libreria originale supporta Azure Databricks Runtimes 10.x (Spark 3.2.x) e versioni precedenti.
Databricks ha contribuito a una versione aggiornata per supportare Azure Databricks Runtimes 11.0 (Spark 3.3.x) e versioni successive nel l4jv2 ramo in: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Si noti che la versione 11.0 non è compatibile con le versioni precedenti a causa dei diversi sistemi di registrazione usati nei runtime di Databricks. Assicurarsi di usare la compilazione corretta per il runtime di Databricks. La libreria e il repository GitHub sono in modalità di manutenzione. Non sono previsti piani per altre versioni e il supporto per i problemi sarà solo un'operazione ottimale. Per eventuali altre domande relative alla libreria o alla roadmap per il monitoraggio e la registrazione degli ambienti Azure Databricks, contattare azure-spark-monitoring-help@databricks.com.
Questo articolo illustra come configurare un dashboard di Grafana per monitorare i processi di Azure Databricks e identificare eventuali problemi di prestazioni.
Azure Databricks è un servizio di analisi veloce, potente e collaborativo basato su Apache Spark che consente di sviluppare e distribuire rapidamente soluzioni di intelligenza artificiale e analisi dei Big Data. Il monitoraggio è un componente fondamentale per l'esecuzione di carichi di lavoro di Azure Databricks nell'ambiente di produzione. Il primo passaggio consiste nel raccogliere le metriche in un'area di lavoro per l'analisi. In Azure la soluzione migliore per la gestione dei dati di log è Monitoraggio di Azure. Azure Databricks non supporta l'invio nativo dei dati di log a Monitoraggio di Azure, ma una libreria per questa funzionalità è disponibile in GitHub.
Questa libreria consente di registrare le metriche del servizio Azure Databricks, nonché le metriche degli eventi delle query di streaming della struttura Apache Spark. Dopo aver distribuito correttamente questa libreria in un cluster di Azure Databricks, è possibile distribuire ulteriormente un set di dashboard di Grafana come parte dell'ambiente di produzione.
Prerequisiti
Configurare il cluster di Azure Databricks per l'uso della libreria di monitoraggio, come descritto nel file README di GitHub.
Distribuire l'area di lavoro Azure Log Analytics
Per distribuire l'area di lavoro Azure Log Analytics, seguire questa procedura:
Passare alla directory
/perftools/deployment/loganalytics.Distribuire il modello di Azure Resource Manager logAnalyticsDeploy.json. Per altre informazioni sulla distribuzione dei modelli di Resource Manager, vedere Distribuire le risorse con i modelli di Azure Resource Manager e l'interfaccia della riga di comando di Azure. Il modello include i parametri seguenti:
- location: l'area in cui vengono distribuiti l'area di lavoro Log Analytics e i dashboard.
- serviceTier: il piano tariffario dell'area di lavoro. Vedere qui per un elenco di valori validi.
- dataRetention (facoltativo): il numero di giorni in cui i dati di log vengono conservati nell'area di lavoro Log Analytics. Il valore predefinito è 30 giorni. Se il piano tariffario è
Free, la conservazione dei dati deve essere di sette giorni. - workspaceName (facoltativo): un nome per l'area di lavoro. Se non specificato, il modello genera un nome.
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
Questo modello crea l'area di lavoro e anche un set di query predefinite usate dal dashboard.
Distribuire Grafana in una macchina virtuale
Grafana è un progetto open source che è possibile distribuire per visualizzare le metriche delle serie temporali archiviate nell'area di lavoro Azure Log Analytics usando il plug-in Grafana per Monitoraggio di Azure. Grafana viene eseguito in una macchina virtuale e richiede un account di archiviazione, una rete virtuale e altre risorse. Per distribuire una macchina virtuale con l'immagine di Grafana certificata bitnami e le risorse associate, seguire questa procedura:
Usare l'interfaccia della riga di comando di Azure per accettare le condizioni di Azure Marketplace per l'immagine di Grafana.
az vm image terms accept --publisher bitnami --offer grafana --plan defaultPassare alla directory
/spark-monitoring/perftools/deployment/grafananella copia locale del repository GitHub.Distribuire il modello di Resource Manager grafanaDeploy.json come segue:
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
Al termine della distribuzione, l'immagine bitnami di Grafana viene installata nella macchina virtuale.
Aggiornare la password di Grafana
Come parte del processo di installazione, lo script di installazione di Grafana restituisce una password temporanea per l'utente admin. Questa password temporanea è necessaria per accedere. Per ottenere la password temporanea, seguire questa procedura:
- Accedere al portale di Azure.
- Selezionare il gruppo di risorse in cui sono state distribuite le risorse.
- Selezionare la macchina virtuale in cui è stato installato Grafana. Se è stato usato il nome del parametro predefinito nel modello di distribuzione, il nome della macchina virtuale è preceduto da sparkmonitoring-vm-grafana.
- Nella sezione Supporto e risoluzione dei problemi fare clic su Diagnostica di avvio per aprire la pagina corrispondente.
- Fare clic su Log seriale nella pagina della diagnostica di avvio.
- Cercare la stringa seguente: "Setting Bitnami application password to".
- Copiare la password in una posizione sicura.
Cambiare quindi la password dell'amministratore di Grafana seguendo questa procedura:
- Nel portale di Azure selezionare la macchina virtuale e fare clic su Panoramica.
- Copiare l'indirizzo IP pubblico.
- Aprire un Web browser e passare all'URL seguente:
http://<IP address>:3000. - Nella schermata di accesso di Grafana immettere admin come nome utente e usare la password di Grafana dei passaggi precedenti.
- Dopo aver eseguito l'accesso, selezionare Configurazione (icona dell'ingranaggio).
- Selezionare Amministratore del server.
- Nella scheda Utenti selezionare l'account di accesso admin.
- Aggiornare la password.
Creare un'origine dati di Monitoraggio di Azure
Creare un'entità servizio che consenta a Grafana di gestire l'accesso all'area di lavoro Log Analytics. Per altre informazioni, vedere Creare un'entità servizio di Azure con l'interfaccia della riga di comando di Azure
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionIDPrendere nota dei valori per appId, password e tenant nell'output di questo comando:
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }Accedere a Grafana come descritto in precedenza. Selezionare Configurazione (icona dell'ingranaggio) e quindi Origini dati.
Nella scheda Origini dati fare clic su Aggiungi origine dati.
Selezionare Monitoraggio di Azure come tipo di origine dati.
Nella sezione Impostazioni immettere un nome per l'origine dati nella casella di testo Nome.
Nella sezione di dettagli dell'API Monitoraggio di Azureimmettere le informazioni seguenti:
- ID sottoscrizione: ID della sottoscrizione di Azure.
- ID tenant: l'ID tenant specificato in precedenza.
- ID client: il valore di "appId" precedente.
- Segreto client: il valore di "password" precedente.
Nella sezione di dettagli dell'API Azure Log Analyticsselezionare la casella di controllo Same Details as Azure Monitor API (Stessi dettagli dell'API Monitoraggio di Azure).
Fare clic su Salva e test. Se l'origine dati di Log Analytics è configurata correttamente, viene visualizzato un messaggio di operazione riuscita.
Creare il dashboard
Creare i dashboard in Grafana seguendo questa procedura:
Passare alla directory
/perftools/dashboards/grafananella copia locale del repository GitHub.Eseguire lo script seguente:
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shL'output dello script è un file denominato SparkMonitoringDash.json.
Tornare nel dashboard di Grafana e selezionare Crea (icona con il segno più).
Seleziona Importa
Fare clic su Carica file JSON.
Selezionare il file SparkMonitoringDash.json creato nel passaggio 2.
Nella sezione Opzioni, in ALA, selezionare l'origine dati di Monitoraggio di Azure dati creata in precedenza.
Fare clic su Importa.
Visualizzazioni nei dashboard
I dashboard di Azure Log Analytics e Grafana includono un set di visualizzazioni di serie temporali. Ogni grafo è un tracciato di serie temporali di dati di metriche correlate a un processo di Apache Spark, alle fasi del processo e alle attività che costituiscono ogni fase.
Le visualizzazioni sono:
Latenza del processo
Questa visualizzazione mostra la latenza di esecuzione di un processo, che offre un'idea approssimativa delle prestazioni complessive del processo. Visualizza la durata dell'esecuzione del processo dall'inizio al completamento. Si noti che l'ora di inizio del processo non corrisponde all'ora di invio del processo. La latenza è rappresentata in percentili (10%, 30%, 50%, 90%) dell'esecuzione del processo indicizzata in base a ID cluster e ID applicazione.
Latenza delle fasi
La visualizzazione mostra la latenza di ogni fase per cluster, per applicazione e per singola fase. È utile per identificare una fase specifica che viene eseguita lentamente.
Latenza delle attività
Questa visualizzazione mostra la latenza di esecuzione delle attività. La latenza è rappresentata come percentile dell'esecuzione dell'attività per cluster, nome della fase e applicazione.
Somma esecuzione attività per host
Questa visualizzazione mostra la somma della latenza di esecuzione delle attività per ogni host in esecuzione in un cluster. La visualizzazione della latenza di esecuzione delle attività per host identifica gli host con una latenza complessiva delle attività molto più elevata rispetto agli altri. Ciò può significare che le attività sono state distribuite in modo inefficiente o non uniforme agli host.
Metriche delle attività
Questa visualizzazione mostra un set di metriche per l'esecuzione di una determinata attività. Le metriche includono le dimensioni e la durata di una sequenza casuale dei dati, la durata delle operazioni di serializzazione e deserializzazione e così via. Per il set completo di metriche, visualizzare la query di Log Analytics per il pannello. Questa visualizzazione è utile per identificare le operazioni che costituiscono un'attività e l'utilizzo delle risorse di ogni operazione. I picchi nel grafo rappresentano operazioni costose che dovranno essere esaminate.
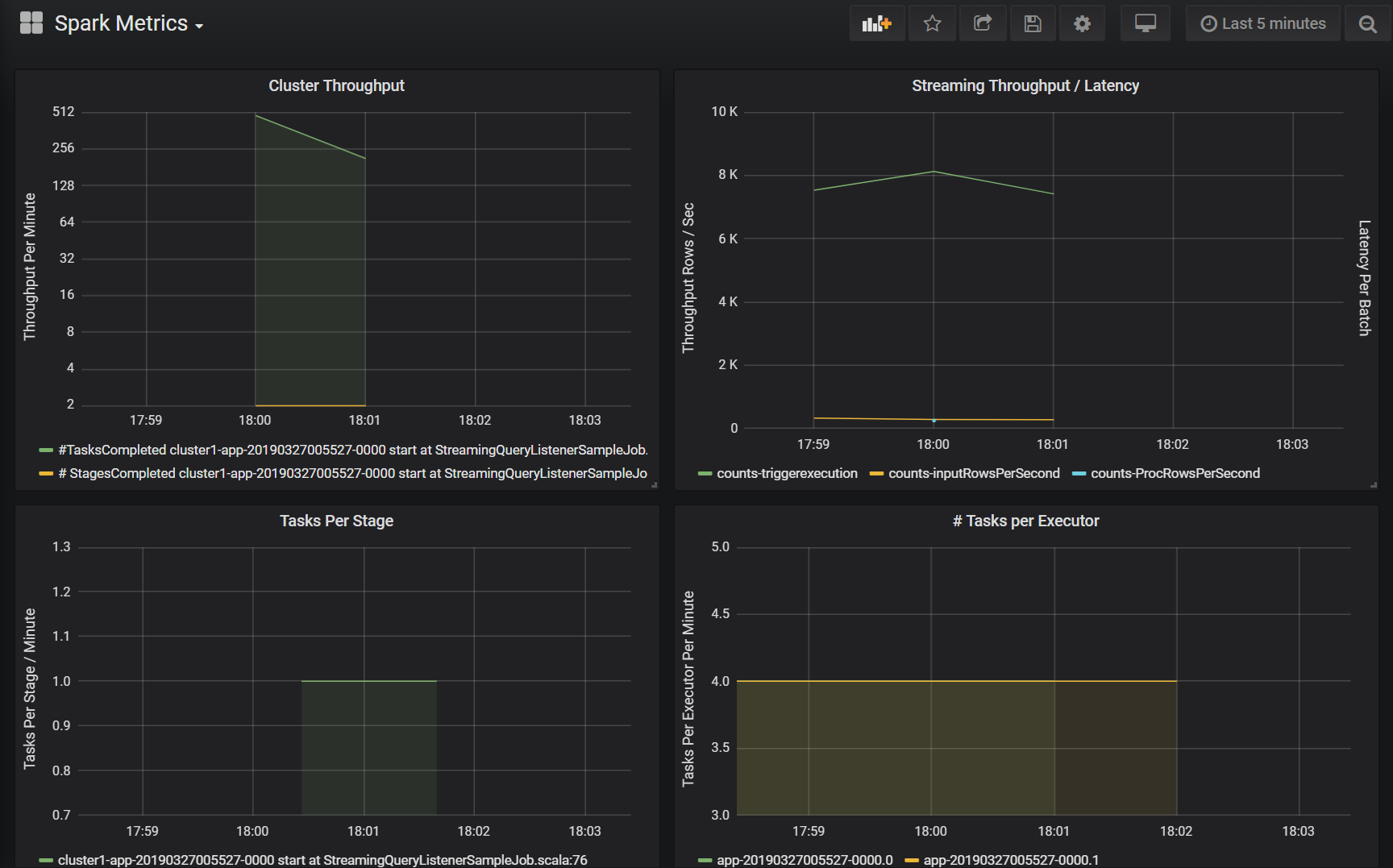
Velocità effettiva del cluster
Questa visualizzazione mostra in generale gli elementi di lavoro indicizzati in base a cluster e applicazione per rappresentare la quantità di lavoro eseguita per ogni cluster e applicazione. Visualizza il numero di processi, attività e fasi completati per cluster, applicazione e fase in incrementi di un minuto.
Velocità effettiva/latenza di streaming
Questa visualizzazione è correlata alle metriche associate a una query di streaming strutturata. Il grafo mostra il numero di righe di input al secondo e il numero di righe elaborate al secondo. Le metriche di streaming sono rappresentate anche per ogni applicazione. Queste metriche vengono inviate quando viene generato l'evento OnQueryProgress durante l'elaborazione della query di streaming strutturata e la visualizzazione rappresenta la latenza di streaming come la quantità di tempo, in millisecondi, impiegato per eseguire un batch di query.
Utilizzo delle risorse per executor
Queste visualizzazioni del dashboard mostrano il tipo specifico di risorsa e il modo in cui viene utilizzata per ogni executor in ogni cluster. Consentono di identificare gli outlier nell'utilizzo delle risorse per ogni executor. Ad esempio, se l'allocazione del lavoro per un determinato executor è sbilanciata, l'utilizzo delle risorse sarà elevato rispetto ad altri executor in esecuzione nel cluster. Questo aspetto può essere identificato da picchi nell'utilizzo delle risorse per un executor.
Metriche temporali di calcolo dell'executor
Queste visualizzazioni del dashboard mostrano il rapporto del tempo di serializzazione dell'executor, il tempo di deserializzazione, il tempo di CPU e il tempo di macchina virtuale Java rispetto al tempo di calcolo complessivo dell'executor. Questo rapporto dimostra visivamente il contributo di queste quattro metriche all'elaborazione complessiva dell'executor.
Metriche di sequenza casuale
Le visualizzazioni di questo set finale mostrano le metriche di sequenza casuale dei dati associate a una query di streaming strutturata tra tutti gli executor. Sono inclusi i byte letti in sequenza casuale, i byte scritti in sequenza casuale, la memoria in sequenza casuale e l'utilizzo del disco nelle query in cui viene usato il file system.
Passaggi successivi
Risorse correlate
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per