Disponibilità elevata in Database di Azure per PostgreSQL - Server singolo
SI APPLICA A: Database di Azure per PostgreSQL - Server singolo
Database di Azure per PostgreSQL - Server singolo
Importante
Database di Azure per PostgreSQL - Server singolo si trova nel percorso di ritiro. È consigliabile eseguire l'aggiornamento a Database di Azure per PostgreSQL - Server flessibile. Per altre informazioni sulla migrazione a Database di Azure per PostgreSQL - Server flessibile, vedere What's happening to Database di Azure per PostgreSQL Single Server?.
Il servizio Database di Azure per PostgreSQL - Server singolo offre un livello elevato di disponibilità garantito con il contratto di servizio supportato finanziariamente per il tempo di attività. Database di Azure per PostgreSQL offre disponibilità elevata durante gli eventi pianificati, ad esempio l'operazione di calcolo della scalabilità avviata dall'utente e anche quando si verificano eventi non pianificati, ad esempio hardware, software o errori di rete sottostanti. Database di Azure per PostgreSQL può eseguire rapidamente il ripristino dalla maggior parte delle circostanze critiche, garantendo praticamente nessun tempo di inattività dell'applicazione quando si usa questo servizio.
Database di Azure per PostgreSQL è adatto per l'esecuzione di database cruciali che richiedono tempi di attività elevati. Basato sull'architettura di Azure, il servizio ha funzionalità di disponibilità elevata, ridondanza e resilienza intrinseche per ridurre i tempi di inattività del database da interruzioni pianificate e non pianificate, senza che sia necessario configurare componenti aggiuntivi.
Componenti in Database di Azure per PostgreSQL - Server singolo
| Componente | Descrizione |
|---|---|
| Postgre database SQL Server | Database di Azure per PostgreSQL offre sicurezza, isolamento, misure di sicurezza delle risorse e funzionalità di riavvio rapido per i server di database. Queste funzionalità facilitano operazioni come il ridimensionamento e l'operazione di ripristino del server di database dopo un'interruzione in pochi secondi. Le modifiche ai dati nel server di database si verificano in genere nel contesto di una transazione di database. Tutte le modifiche al database vengono registrate in modo sincrono sotto forma di log write-ahead (WAL) in Archiviazione di Azure, collegato al server di database. Durante il processo di checkpoint del database, anche le pagine di dati della memoria del server di database vengono scaricate nella risorsa di archiviazione. |
| Remote Archiviazione | Tutti i file di dati fisici postgreSQL e i file WAL vengono archiviati in Archiviazione di Azure, progettato per archiviare tre copie di dati all'interno di un'area per garantire ridondanza dei dati, disponibilità e affidabilità. Il livello di archiviazione è anche indipendente dal server di database. Può essere disconnesso da un server di database non riuscito e ricollegato a un nuovo server di database entro pochi secondi. Inoltre, Archiviazione di Azure monitora continuamente eventuali errori di archiviazione. Se viene rilevato un danneggiamento del blocco, viene risolto automaticamente creando un'istanza di una nuova copia di archiviazione. |
| Gateway | Il gateway funge da proxy di database, instrada tutte le connessioni client al server di database. |
Mitigazione del tempo di inattività pianificata
Database di Azure per PostgreSQL è progettato per offrire disponibilità elevata durante le operazioni di inattività pianificate.
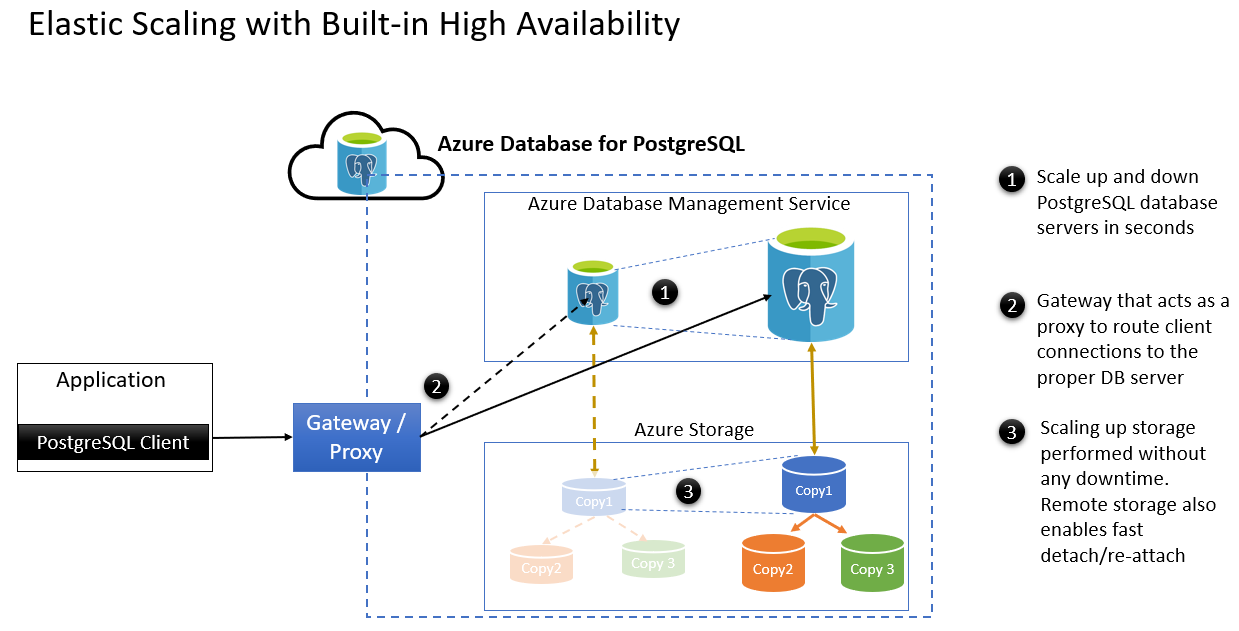
- Aumentare e ridurre i server di database PostgreSQL in pochi secondi.
- Il gateway che funge da proxy per instradare il client si connette al server di database appropriato.
- La scalabilità verticale dell'archiviazione può essere eseguita senza tempi di inattività. L'archiviazione remota consente di scollegare/ricollegare rapidamente dopo il failover. Ecco alcuni scenari di manutenzione pianificata:
| Scenario | Descrizione |
|---|---|
| Aumento/riduzione delle prestazioni di calcolo | Quando l'utente esegue un'operazione di aumento/riduzione delle prestazioni di calcolo, viene effettuato il provisioning di un nuovo server di database usando la configurazione di calcolo con scalabilità orizzontale. Nel server di database precedente, i checkpoint attivi sono autorizzati a completare, le connessioni client vengono svuotate, tutte le transazioni di cui non è stato eseguito il commit vengono annullate e quindi vengono arrestate. Lo spazio di archiviazione viene quindi scollegato dal server di database precedente e collegato al nuovo server di database. Quando l'applicazione client ritenta la connessione o tenta di stabilire una nuova connessione, il gateway indirizza la richiesta di connessione al nuovo server di database. |
| Aumento dell'archiviazione | La scalabilità verticale dell'archiviazione è un'operazione online e non interrompe il server di database. |
| Nuova distribuzione software (Azure) | Le nuove funzionalità di implementazione o correzioni di bug vengono eseguite automaticamente come parte della manutenzione pianificata del servizio. Per altre informazioni, vedere la documentazione e controllare anche il portale. |
| Aggiornamenti delle versioni secondarie | Database di Azure per PostgreSQL applica automaticamente patch ai server di database alla versione secondaria determinata da Azure. Si verifica come parte della manutenzione pianificata del servizio. Ciò comporta un breve tempo di inattività in termini di secondi e il server di database viene riavviato automaticamente con la nuova versione secondaria. Per altre informazioni, vedere la documentazione e controllare anche il portale. |
Mitigazione dei tempi di inattività non pianificati
I tempi di inattività non pianificati possono verificarsi a causa di errori imprevisti, inclusi errori hardware sottostanti, problemi di rete e bug software. Se il server di database si arresta in modo imprevisto, viene effettuato automaticamente il provisioning di un nuovo server di database in pochi secondi. L'archiviazione remota viene collegata automaticamente al nuovo server di database. Il motore PostgreSQL esegue l'operazione di ripristino usando i file WAL e di database e apre il server di database per consentire ai client di connettersi. Le transazioni di cui non è stato eseguito il commit vengono perse e devono essere ritentate dall'applicazione. Anche se non è possibile evitare tempi di inattività non pianificati, Database di Azure per PostgreSQL riduce il tempo di inattività eseguendo automaticamente operazioni di ripristino a livello di server di database e di archiviazione senza richiedere l'intervento umano.
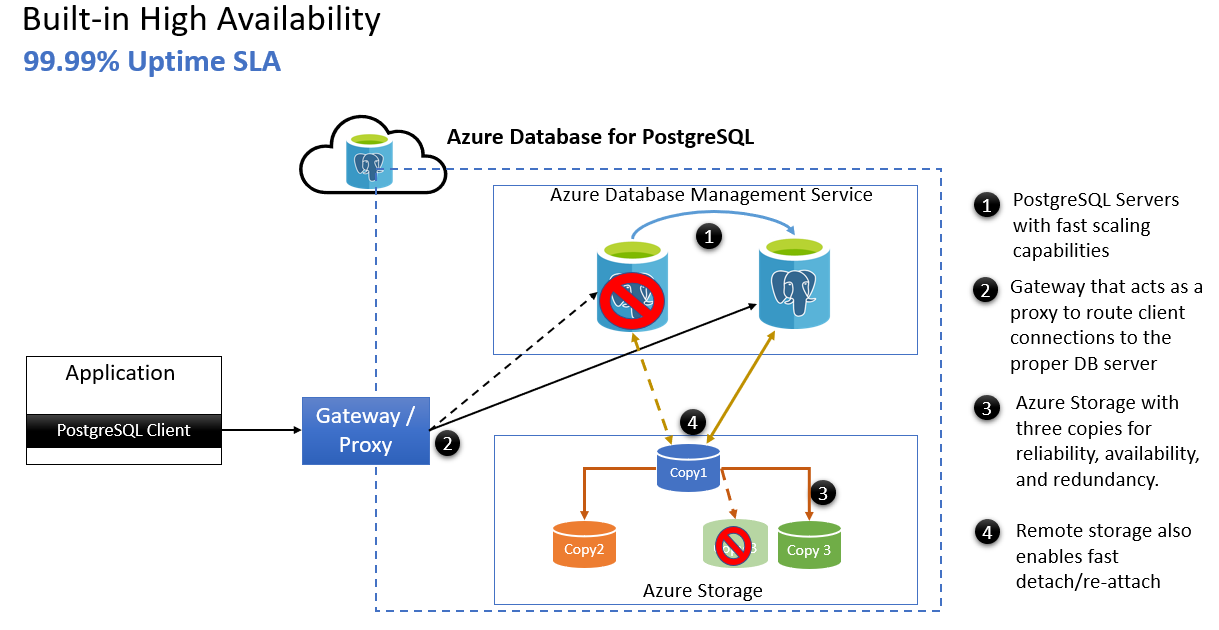
- Server PostgreSQL di Azure con funzionalità di scalabilità rapida.
- Gateway che funge da proxy per instradare le connessioni client al server di database appropriato.
- Archiviazione di Azure con tre copie per affidabilità, disponibilità e ridondanza.
- L'archiviazione remota consente anche di scollegare/ricollegare rapidamente dopo il failover del server.
Tempo di inattività non pianificato: scenari di errore e ripristino del servizio
Ecco alcuni scenari di errore e il modo in cui Database di Azure per PostgreSQL viene ripristinato automaticamente:
| Scenario | Ripristino automatico |
|---|---|
| Errore del server di database | Se il server di database è inattivo a causa di un errore hardware sottostante, le connessioni attive vengono eliminate e le transazioni in corso vengono interrotte. Viene distribuito automaticamente un nuovo server di database e l'archiviazione dati remota viene collegata al nuovo server di database. Al termine del ripristino del database, i client possono connettersi al nuovo server di database tramite il gateway. Il tempo di ripristino (RTO) dipende da vari fattori, tra cui l'attività al momento dell'errore, ad esempio transazioni di grandi dimensioni e la quantità di recupero da eseguire durante il processo di avvio del server di database. Le applicazioni che usano i database PostgreSQL devono essere compilate in modo da rilevare e ripetere le connessioni eliminate e le transazioni non riuscite. Quando l'applicazione ritenta, il gateway reindirizza in modo trasparente la connessione al server di database appena creato. |
| errore di Archiviazione | Le applicazioni non riscontrano alcun impatto sui problemi correlati all'archiviazione, ad esempio un errore del disco o un danneggiamento del blocco fisico. Poiché i dati vengono archiviati in tre copie, la copia dei dati viene servita dall'archiviazione sopravvissuta. I danneggiamenti dei blocchi vengono corretti automaticamente. Se una copia dei dati viene persa, viene creata automaticamente una nuova copia dei dati. |
| Errore di calcolo | Gli errori di calcolo sono eventi rari. In caso di errore di calcolo viene effettuato il provisioning di un nuovo contenitore di calcolo e l'archiviazione con i file di dati viene mappata, il motore di database PostgreSQL viene quindi portato online nel nuovo contenitore e il servizio gateway garantisce il failover trasparente senza alcuna necessità di modifiche dell'applicazione. Si noti anche che il livello di calcolo ha integrato la resilienza della zona di disponibilità e che viene attivata una nuova risorsa di calcolo in una zona di disponibilità diversa in caso di errore di calcolo az. |
Ecco alcuni scenari di errore che richiedono l'azione dell'utente per il ripristino:
| Scenario | Piano di ripristino |
|---|---|
| Errore dell'area | L'errore di un'area è un evento raro. Tuttavia, se è necessaria la protezione da un errore dell'area, è possibile configurare una o più repliche in lettura in altre aree per il ripristino di emergenza.If you need protection from a region failure, you can configure one or more read replicas in other regions for disaster recovery (DR). Per informazioni dettagliate, vedere questo articolo sulla creazione e la gestione delle repliche in lettura. In caso di errore a livello di area, è possibile alzare di livello manualmente la replica di lettura configurata nell'altra area in modo che sia il server di database di produzione. |
| Errore nella zona di disponibilità | Anche l'errore di una zona di disponibilità è un evento raro. Tuttavia, se è necessaria la protezione da un errore della zona di disponibilità, è possibile configurare una o più repliche in lettura o prendere in considerazione l'uso dell'offerta Server flessibile che offre disponibilità elevata con ridondanza della zona. |
| Errori logici/utente | Il ripristino da errori utente, ad esempio tabelle eliminate accidentalmente o dati aggiornati in modo non corretto, comporta l'esecuzione di un ripristino temporizzato (PITR), ripristinando e ripristinando i dati fino al momento precedente all'errore. Se si desidera ripristinare solo un subset di database o tabelle specifiche anziché tutti i database nel server di database, è possibile ripristinare il server di database in una nuova istanza, esportare le tabelle tramite pg_dump e quindi utilizzare pg_restore per ripristinare tali tabelle nel database. |
Riepilogo
Database di Azure per PostgreSQL offre funzionalità di riavvio rapido dei server di database, dell'archiviazione ridondante e del routing efficiente dal gateway. Per una protezione aggiuntiva dei dati, è possibile configurare i backup per la replica geografica e distribuire anche una o più repliche in lettura in altre aree. Con funzionalità di disponibilità elevata intrinseche, Database di Azure per PostgreSQL protegge i database dalle interruzioni più comuni e offre un contratto di servizio leader del settore, con supporto finanziario del 99,99% del contratto di servizio per il tempo di attività. Tutte queste funzionalità di disponibilità e affidabilità consentono ad Azure di essere la piattaforma ideale per eseguire applicazioni cruciali.
Passaggi successivi
- Informazioni sulle aree di Azure
- Informazioni sulla gestione degli errori di connettività temporanei
- Informazioni sulle modalità di replica dei dati con le repliche in lettura