Usare tabelle esterne con Synapse SQL
Una tabella esterna punta ai dati situati in Hadoop, BLOB del servizio di archiviazione di Azure o Azure Data Lake Storage. È possibile usare tabelle esterne per leggere o scrivere dati nei file in Archiviazione di Azure.
Con Synapse SQL, è possibile usare tabelle esterne per leggere dati esterni usando un pool SQL dedicato o un pool SQL serverless.
A seconda del tipo dell'origine dati esterna, è possibile usare due tipi di tabelle esterne:
- Tabelle esterne Hadoop che consentono di leggere ed esportare dati in vari formati di dati come CSV, Parquet e ORC. Le tabelle esterne Hadoop sono disponibili nei pool SQL dedicati, ma non nei pool SQL serverless.
- Tabelle esterne native che consentono di leggere ed esportare dati in vari formati di dati come CSV e Parquet. Le tabelle esterne native sono disponibili nei pool SQL serverless e sono in anteprima pubblica nei pool SQL dedicati. La scrittura o l'esportazione di dati tramite CREATE EXTERNAL TABLE AS SELECT (CETAS) e le tabelle esterne native è disponibile solo nel pool SQL serverless e non nei pool SQL dedicati.
Differenze principali tra tabelle esterne Hadoop e native:
| Tipo di tabella esterna | Hadoop | Nativo |
|---|---|---|
| Pool SQL dedicato | Disponibile | Solo le tabelle Parquet sono disponibili in anteprima pubblica. |
| Pool SQL serverless | Non disponibile | Disponibili |
| Formati supportati | Delimitato/CSV, Parquet, ORC, Hive RC e RC | Pool SQL serverless: delimitato/CSV, Parquet e Delta Lake Pool SQL dedicato: Parquet (anteprima) |
| Eliminazione delle partizioni delle cartelle | No | L'eliminazione delle partizioni è disponibile solo nelle tabelle partizionate create nei formati Parquet o CSV sincronizzate dai pool di Apache Spark. È possibile creare tabelle esterne in cartelle partizionate Parquet, ma le colonne di partizionamento sono inaccessibili e ignorate e l'eliminazione delle partizioni non verrà applicata. Non creare tabelle esterne in cartelle Delta Lake perché non sono supportate. Usare le viste partizionate Delta se occorre eseguire query sui dati Delta Lake partizionati. |
| Eliminazione di file (pushdown del predicato) | No | Sì, nel pool SQL serverless. Per il pushdown delle stringhe, è necessario usare le regole di confronto Latin1_General_100_BIN2_UTF8 nelle colonne VARCHAR per abilitare il pushdown. Per altre informazioni sulle regole di confronto, vedere Tipi di regole di confronto supportati per Synapse SQL. |
| Formato personalizzato per la posizione | No | Sì, usando caratteri jolly come /year=*/month=*/day=* per i formati Parquet o CSV. I percorsi di cartella personalizzati non sono disponibili in Delta Lake. Nel pool SQL serverless è anche possibile usare caratteri jolly ricorsivi /logs/** per fare riferimento a file Parquet o CSV in qualsiasi sottocartella sotto la cartella a cui si fa riferimento. |
| Analisi di cartelle ricorsive | Sì | Sì. Nei pool SQL serverless è necessario specificare /** alla fine del percorso. Nel pool dedicato le cartelle vengono sempre analizzate in modo ricorsivo. |
| Autenticazione delle risorse di archiviazione | Chiave di accesso alle risorse di archiviazione, pass-through Microsoft Entra, identità gestita, identità Microsoft Entra dell'applicazione personalizzata | Firma di accesso condiviso, pass-through di Microsoft Entra, identità gestita, identità Microsoft Entra dell'applicazione personalizzata. |
| Mapping delle colonne | Ordinale: le colonne nella definizione della tabella esterna vengono mappate alle colonne nei file Parquet sottostanti in base alla posizione. | Pool serverless: in base al nome. Le colonne nella definizione della tabella esterna vengono mappate alle colonne nei file Parquet sottostanti in base alla corrispondenza dei nomi di colonna. Pool dedicato: corrispondenza ordinale. Le colonne nella definizione della tabella esterna vengono mappate alle colonne nei file Parquet sottostanti in base alla posizione. |
| CETAS (esportazione/trasformazione) | Sì | CETAS con le tabelle native come destinazione funziona solo nel pool SQL serverless. Non è possibile usare i pool SQL dedicati per esportare i dati usando tabelle native. |
Nota
Le tabelle esterne native sono la soluzione consigliata nei pool in cui sono disponibili a livello generale. Se è necessario accedere a dati esterni, usare sempre le tabelle native nei pool serverless. Nei pool dedicati è necessario passare alle tabelle native per leggere i file Parquet una volta che sono disponibili a livello generale. Usare le tabelle Hadoop solo se è necessario accedere ad alcuni tipi non supportati nelle tabelle esterne native (ad esempio ORC, RC) o se la versione nativa non è disponibile.
Tabelle esterne nel pool SQL dedicato e nel pool SQL serverless
È possibile usare le tabelle esterne per:
- Eseguire query su Archiviazione BLOB di Azure e Azure Data Lake Gen2 con istruzioni Transact-SQL.
- Archiviare i risultati delle query in file in Archiviazione BLOB di Azure o Azure Data Lake Storage tramite CETAS.
- Importare dati da Archiviazione BLOB di Azure e Azure Data Lake Storage e archiviarli in un pool SQL dedicato (solo tabelle Hadoop nel pool dedicato).
Nota
Se eseguita in combinazione con l'istruzione CREATE TABLE AS SELECT, la selezione da una tabella esterna importa i dati in una tabella all'interno del pool SQL dedicato.
Se le prestazioni delle tabelle esterne Hadoop nei pool dedicati non soddisfano gli obiettivi di prestazioni, valutare la possibilità di caricare i dati esterni nelle tabelle del data warehouse usando l'istruzione COPY.
Per un'esercitazione sul caricamento, vedere Usare PolyBase per caricare dati da Archiviazione BLOB di Azure.
È possibile creare tabelle esterne nei pool SQL di Synapse seguendo questa procedura:
- CREATE EXTERNAL DATA SOURCE per fare riferimento a un archivio di Azure esterno e specificare le credenziali da usare per accedere alle risorse di archiviazione.
- CREATE EXTERNAL FILE FORMAT per descrivere il formato dei file CSV o Parquet.
- CREATE EXTERNAL TABLE sui file posizionati nell'origine dati con lo stesso formato di file.
Eliminazione delle partizioni delle cartelle
Le tabelle esterne native nei pool Synapse possono ignorare i file posizionati nelle cartelle non pertinenti per le query. Se i file sono archiviati in una gerarchia di cartelle (ad esempio /year=2020/month=03/day=16) e i valori per year, month e day sono esposti come colonne, le query che contengono filtri come year=2020 leggeranno i file solo dalle sottocartelle posizionate all'interno della cartella year=2020. I file e le cartelle che risiedono in altre cartelle (year=2021 o year=2022) verranno ignorati in questa query. Questa eliminazione è nota come eliminazione di partizioni.
L'eliminazione delle partizioni delle cartelle è disponibile nelle tabelle esterne native sincronizzate dai pool di Spark di Synapse. Se è stato partizionato un set di dati e si vuole sfruttare l'eliminazione delle partizioni con le tabelle esterne create, usare le viste partizionate anziché le tabelle esterne.
Eliminazione dei file
Alcuni formati di dati, ad esempio Parquet e Delta, contengono statistiche di file per ogni colonna (ad esempio, valori min/max per ogni colonna). Le query che filtrano i dati non leggeranno i file in cui i valori di colonna necessari non esistono. La query esplorerà innanzitutto i valori min/max per le colonne usate nel predicato di query per trovare i file che non contengono i dati necessari. Questi file verranno ignorati ed eliminati dal piano di query.
Questa tecnica è nota anche come pushdown del predicato di filtro e può migliorare le prestazioni delle query. Il pushdown del filtro è disponibile nei pool SQL serverless nei formati Parquet e Delta. Per sfruttare il pushdown del filtro per i tipi stringa, usare il tipo VARCHAR con le regole di confronto Latin1_General_100_BIN2_UTF8. Per altre informazioni sulle regole di confronto, vedere Tipi di regole di confronto supportati per Synapse SQL.
Sicurezza
Per leggere i dati, l'utente deve disporre dell'autorizzazione SELECT per la tabella esterna.
Le tabelle esterna accedono all'archiviazione di Azure sottostante tramite le credenziali con ambito database definite nell'origine dati usando le regole seguenti:
- L'origine dati senza credenziali consente alle tabelle esterne di accedere ai file disponibili pubblicamente nell'archiviazione di Azure.
- L'origine dati può disporre di credenziali che consentono alle tabelle esterne di accedere solo ai file nell'archiviazione di Azure usando il token di firma di accesso condiviso o l'identità gestita dell'area di lavoro. Per esempi, vedere l'articolo Sviluppare il controllo di accesso alle risorse di archiviazione per i file di archiviazione.
Esempio di CREATE EXTERNAL DATA SOURCE
L'esempio seguente crea un'origine dati esterna Hadoop in un pool SQL dedicato per Azure Data Lake Gen2 che punta al set di dati New York:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2018-03-28&ss=bf&srt=sco&sp=rl&st=2019-10-14T12%3A10%3A25Z&se=2061-12-31T12%3A10%3A00Z&sig=KlSU2ullCscyTS0An0nozEpo4tO5JAgGBvw%2FJX2lguw%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
L'esempio seguente crea un'origine dati esterna per Azure Data Lake Gen2 che punta al set di dati New York disponibile pubblicamente:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Esempio di CREATE EXTERNAL FILE FORMAT
L'esempio seguente crea un formato di file esterno per i dati di censimento:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Esempio di CREATE EXTERNAL TABLE
L'esempio seguente crea una tabella esterna. Restituisce la prima riga:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Creare ed eseguire query su tabelle esterne da un file in Azure Data Lake
Usando le funzionalità di esplorazione Data Lake di Synapse Studio, è ora possibile creare ed eseguire query su una tabella esterna usando un pool SQL di Synapse con un semplice clic con il pulsante destro del mouse sul file. Il movimento con un clic per creare tabelle esterne dall'account di archiviazione ADLS Gen2 è supportato solo per i file Parquet.
Prerequisiti
È necessario avere accesso all'area di lavoro con almeno il ruolo di accesso
Storage Blob Data Contributorall'account ADLS Gen2 o elenchi di controllo di accesso (ACL) che consentono di eseguire query sui file.È necessario avere almeno le autorizzazioni per creare una tabella esterna ed eseguire query su tabelle esterne nel pool SQL (dedicato o serverless) di Synapse.
Nel pannello Dati selezionare il file da cui creare la tabella esterna:

Verrà visualizzata una finestra di dialogo. Selezionare il pool SQL dedicato o il pool SQL serverless, assegnare un nome alla tabella e selezionare Apri script:

Lo script SQL viene generato automaticamente deducendo lo schema dal file:
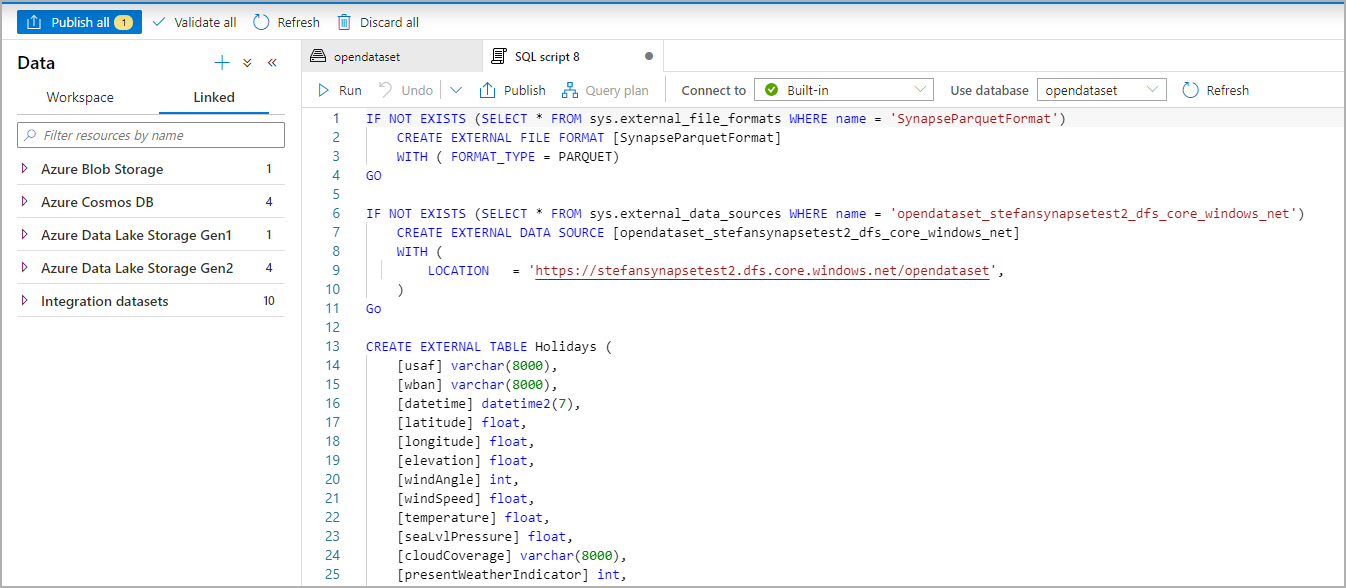
Eseguire lo script. Lo script eseguirà automaticamente SELECT TOP 100*:
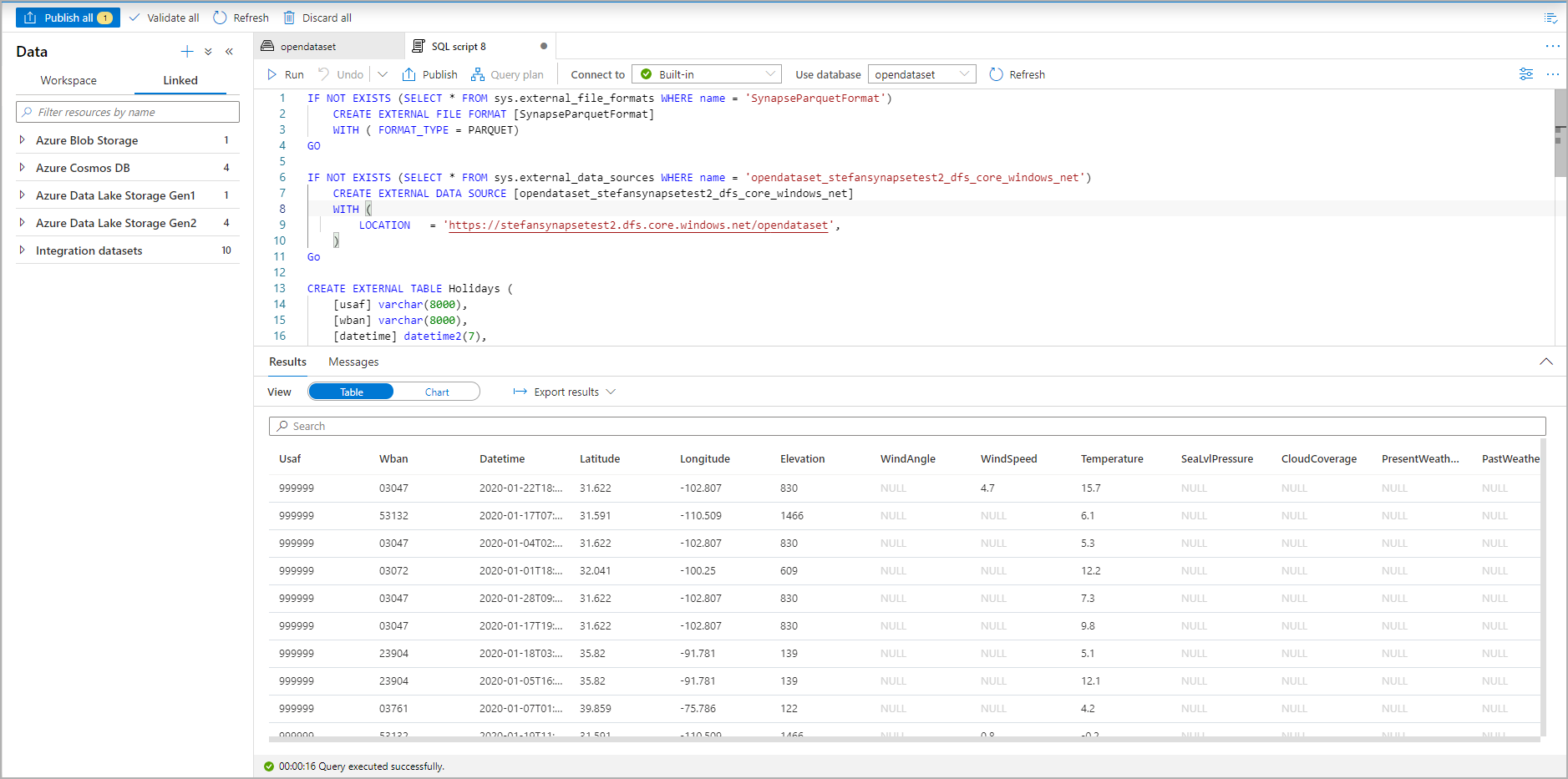
La tabella esterna è stata creata. Per l'esplorazione futura del contenuto di questa tabella esterna, l'utente può eseguire una query direttamente dal riquadro Dati:
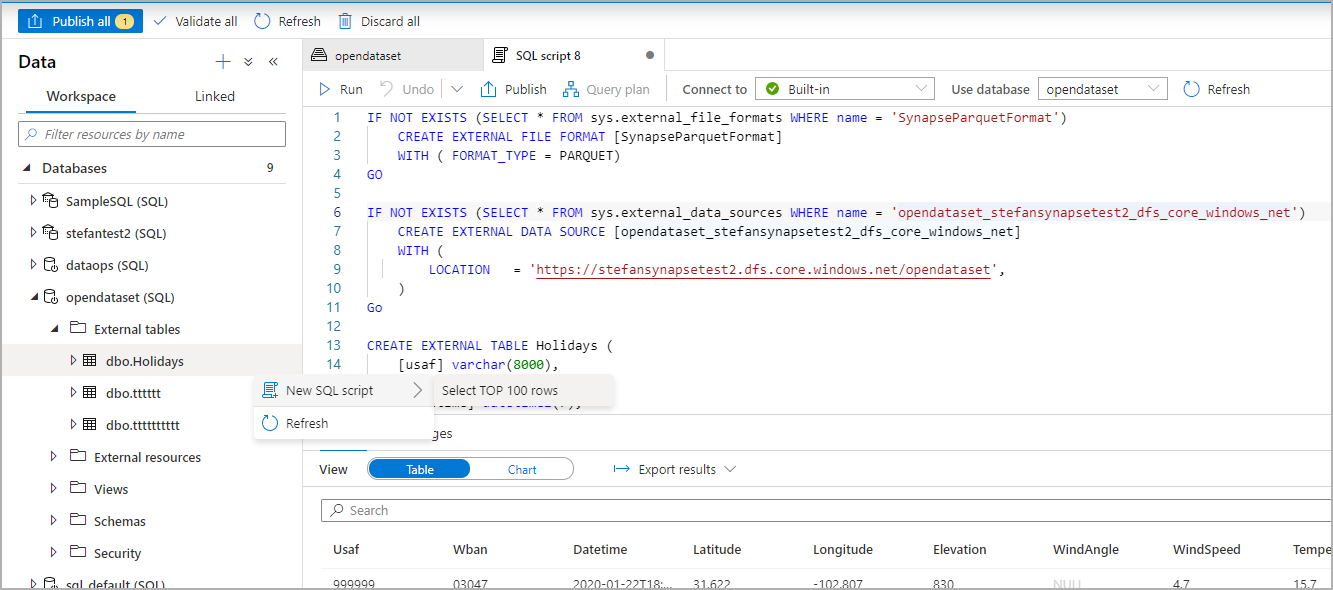
Passaggi successivi
Per informazioni su come salvare i risultati delle query in una tabella esterna in Archiviazione di Azure, vedere l'articolo CETAS. In alternativa, è possibile eseguire query sulle tabelle esterne di Apache Spark per Azure Synapse.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per