Architetture di applicazioni Web comuni
Suggerimento
Questo contenuto è un estratto dell'eBook Progettare applicazioni Web moderne con ASP.NET Core e Azure, disponibile in .NET Docs o come PDF scaricabile gratuitamente che può essere letto offline.

"Se pensi che una buona architettura sia costosa, prova la cattiva architettura." - Brian Foote e Joseph Yoder
La maggior parte delle applicazioni .NET tradizionali viene distribuita come singole unità corrispondenti a un file eseguibile o a un'unica applicazione Web in esecuzione all'interno di un unico AppDomain IIS. Questo approccio è il modello di distribuzione più semplice che funziona molto bene per molte piccole applicazioni pubbliche e interne. Tuttavia, anche tenendo presente questa singola unità di distribuzione, la maggior parte delle applicazioni aziendali complesse trae vantaggio dalla separazione logica in diversi livelli.
Cos'è un'applicazione monolitica?
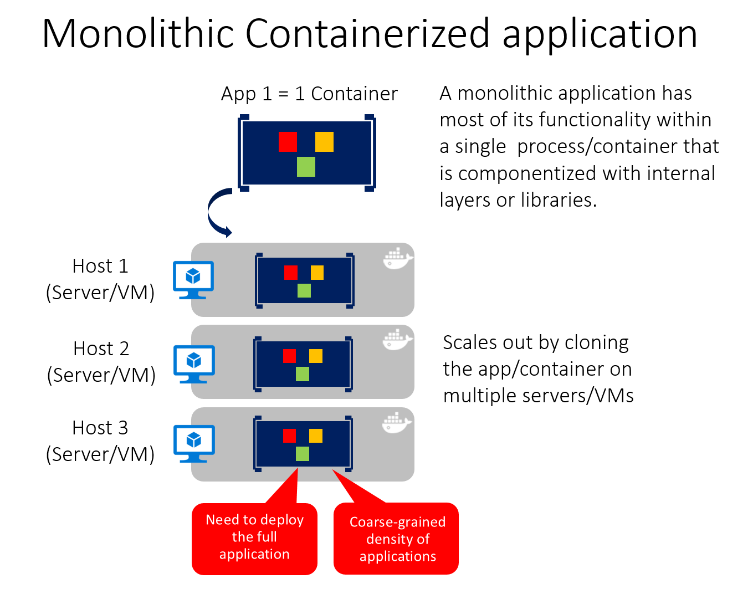
Un'applicazione monolitica è totalmente autonoma in termini di comportamento. Può interagire con altri servizi o archivi dati durante l'esecuzione delle operazioni, ma la base del suo comportamento si trova all'interno del proprio processo e l'intera applicazione viene in genere distribuita come singola unità. Se è necessario scalare questo tipo di applicazione orizzontalmente, l'intera applicazione viene in genere duplicata in più server o macchine virtuali.
Applicazioni all-in-one
Il minor numero possibile di progetti per l'architettura di un'applicazione è uno. In questa architettura l'intera logica dell'applicazione è contenuta in un unico progetto, compilata in un unico assembly e distribuita come singola unità.
Un nuovo progetto ASP.NET Core, creato in Visual Studio o dalla riga di comando, inizia come un semplice monolito "all-in-one". Contiene tutti i comportamenti dell'applicazione, incluse la presentazione, la logica di business e quella di accesso ai dati. La figura 5-1 illustra la struttura di file di un'app con un unico progetto.

Figura 5-1. App ASP.NET Core con un unico progetto.
In uno scenario basato su un unico progetto la separazione delle competenze si ottiene tramite l'uso di cartelle. Il modello predefinito include cartelle separate per le responsabilità di modelli, visualizzazioni e controller dello schema MVC, nonché altre cartelle per dati e servizi. In questa disposizione, i dettagli di presentazione devono essere limitati il più possibile alla cartella delle visualizzazioni e i dettagli di implementazione dell'accesso ai dati devono essere limitati alle classi contenute nella cartella dei dati. La logica di business deve risiedere nei servizi e le classi nella cartella dei modelli.
Anche se semplice, la soluzione monolitica in un unico progetto presenta alcuni svantaggi. Con l'aumento delle dimensioni e della complessità del progetto, anche il numero di file e cartelle continuerà ad aumentare. Le competenze dell'interfaccia utente, ovvero modelli, visualizzazioni e controller, risiedono in più cartelle che non sono raggruppate in ordine alfabetico. Il problema si complica quando altri costrutti a livello di interfaccia utente, ad esempio filtri o strumenti di associazione di modelli, vengono aggiunti nelle rispettive cartelle. La logica di business è distribuita tra le cartelle di modelli e servizi e non esiste alcuna indicazione chiara della dipendenza tra le classi e delle cartelle in cui trovano le classi. Questa mancanza di organizzazione a livello di progetto spesso determina ciò che viene definito spaghetti code (blocchi di codice complicati).
Per risolvere questi problemi, spesso le applicazioni si evolvono in soluzioni costituite da più progetti, in cui si considera che ogni progetto risieda in un determinato livello dell'applicazione.
Cosa sono i livelli logici?
Un modo per gestire la crescente complessità delle applicazioni consiste nel suddividere l'applicazione in base a responsabilità o competenze. Questo approccio si basa sul principio della separazione delle competenze e può contribuire all'organizzazione di una codebase in crescita consentendo agli sviluppatori di individuare facilmente il punto in cui è implementata una determinata funzionalità. Oltre alla semplice organizzazione del codice, l'architettura a livelli offre una serie di vantaggi.
L'organizzazione del codice in livelli consente di riusare le funzionalità comuni di basso livello all'interno dell'applicazione. Questa possibilità di riutilizzo è utile poiché consente di scrivere meno codice e di standardizzare l'applicazione su una singola implementazione, osservando il principio DRY (Don't Repeat Yourself).
Con un'architettura a livelli, le applicazioni possono imporre restrizioni su quali livelli possono comunicare con altri livelli. Questa architettura aiuta a realizzare l'incapsulamento. Quando un livello viene modificato o sostituito, dovrebbero essere interessati solo i livelli a esso correlati. Limitando i livelli che dipendono da altri livelli, l'impatto delle modifiche può essere ridotto in modo da evitare che un'unica modifica influisca sull'intera applicazione.
I livelli, e l'incapsulamento, facilitano la sostituzione delle funzionalità all'interno dell'applicazione. Un'applicazione potrebbe ad esempio usare inizialmente il proprio database SQL Server per il salvataggio permanente, ma in seguito potrebbe scegliere di usare una strategia di salvataggio permanente basata sul cloud o su un'API Web. Se l'applicazione ha incapsulato correttamente l'implementazione del salvataggio permanente all'interno di un livello logico, quello specifico livello di SQL Server potrà essere sostituito da un nuovo livello che implementa la stessa interfaccia pubblica.
Oltre al potenziale per la sostituzione delle implementazioni in risposta alle future modifiche dei requisiti, i livelli dell'applicazione possono anche semplificare la sostituzione delle implementazioni a scopo di test. Anziché scrivere test che operano sul livello dei dati reali o dell'interfaccia utente dell'applicazione, questi livelli possono essere sostituiti in fase di test con false implementazioni che restituiscono risposte note alle richieste. Questo approccio rende in genere la scrittura dei test molto più semplice e la relativa esecuzione molto più veloce rispetto all'esecuzione di test sull'infrastruttura reale dell'applicazione.
I livelli logici sono una tecnica comune per migliorare l'organizzazione del codice nelle applicazioni software aziendali ed esistono molti modi per organizzare il codice in livelli.
Nota
I livelli rappresentano la separazione logica all'interno dell'applicazione. Nel caso in cui la logica dell'applicazione sia fisicamente distribuita in server o processi separati, queste destinazioni di distribuzione fisiche separate sono denominate livelli. È possibile, e piuttosto comune, che un'applicazione a più livelli sia distribuita in un singolo livello.
Applicazioni con architettura a più livelli tradizionali
L'organizzazione più comune della logica dell'applicazione in livelli è illustrata nella figura 5-2.
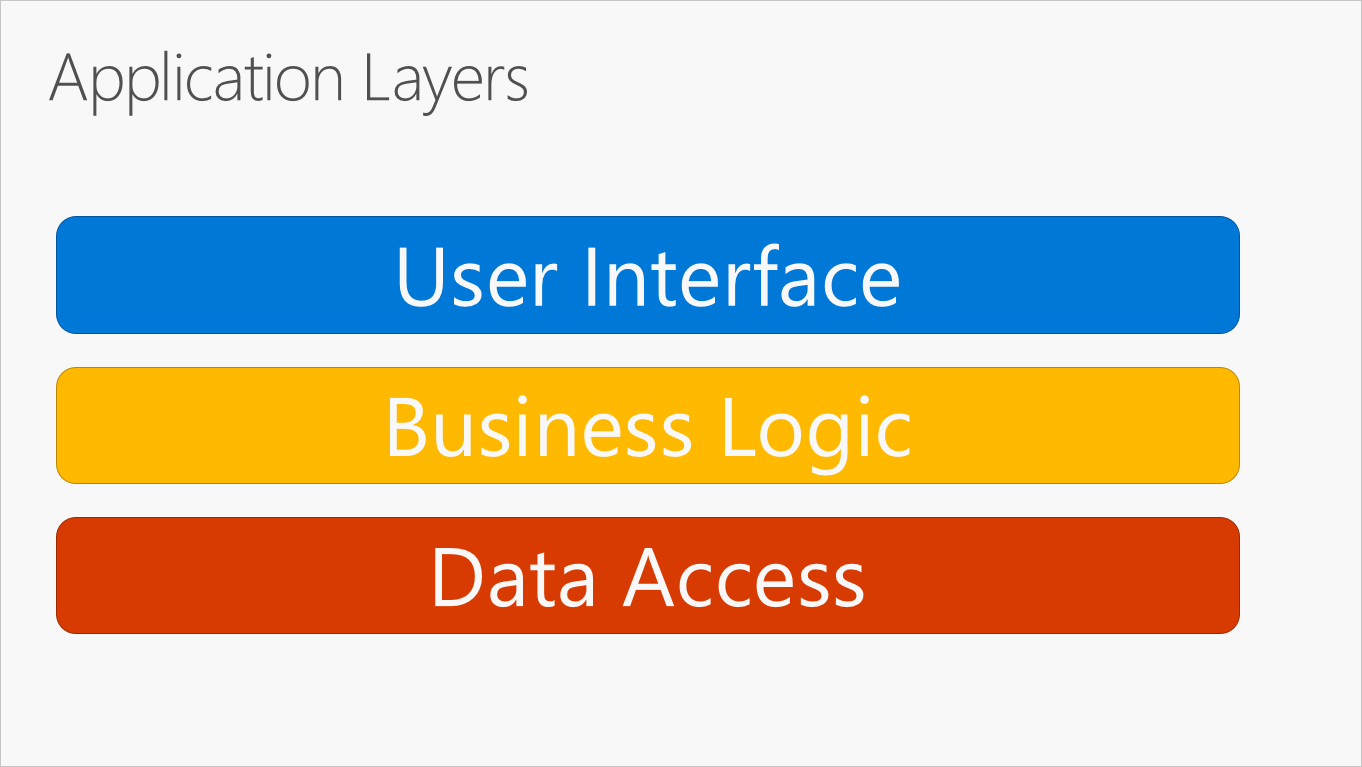
Figura 5-2. Livelli di un'applicazione tipica.
Questi livelli vengono spesso abbreviati: UI (User Interface, interfaccia utente), BLL (Business Logic Layer, livello logica di business ) e DAL (Data Access Layer, livello accesso dati). In questa architettura gli utenti inviano le richieste tramite il livello UI che interagisce solo con il livello BLL. Il livello BLL, a sua volta, può chiamare il livello DAL per le richieste di accesso ai dati. Il livello UI non deve inviare richieste direttamente al livello DAL, né deve interagire direttamente con il salvataggio permanente attraverso altri mezzi. In modo analogo, il livello BLL deve interagire con il salvataggio permanente solo passando tramite il livello DAL. In questo modo, ogni livello avrà responsabilità ben distinte.
Uno svantaggio di questo approccio tradizionale a livelli è l'esecuzione delle dipendenze dall'alto verso il basso in fase di compilazione, ovvero il livello UI dipende dal livello BLL che a sua volta dipende dal livello DAL. Ciò significa che il livello BLL, che in genere contiene la logica più importante nell'applicazione, dipende dai dettagli di implementazione dell'accesso ai dati e spesso dall'esistenza di un database. Testare la logica di business in questo tipo di architettura è spesso difficile e richiede un database di test. Per risolvere questo problema è possibile usare il principio di inversione delle dipendenze, come si vedrà nella prossima sezione.
La figura 5-3 illustra una soluzione di esempio in cui l'applicazione viene suddivisa in tre progetti in base alla responsabilità (o al livello).
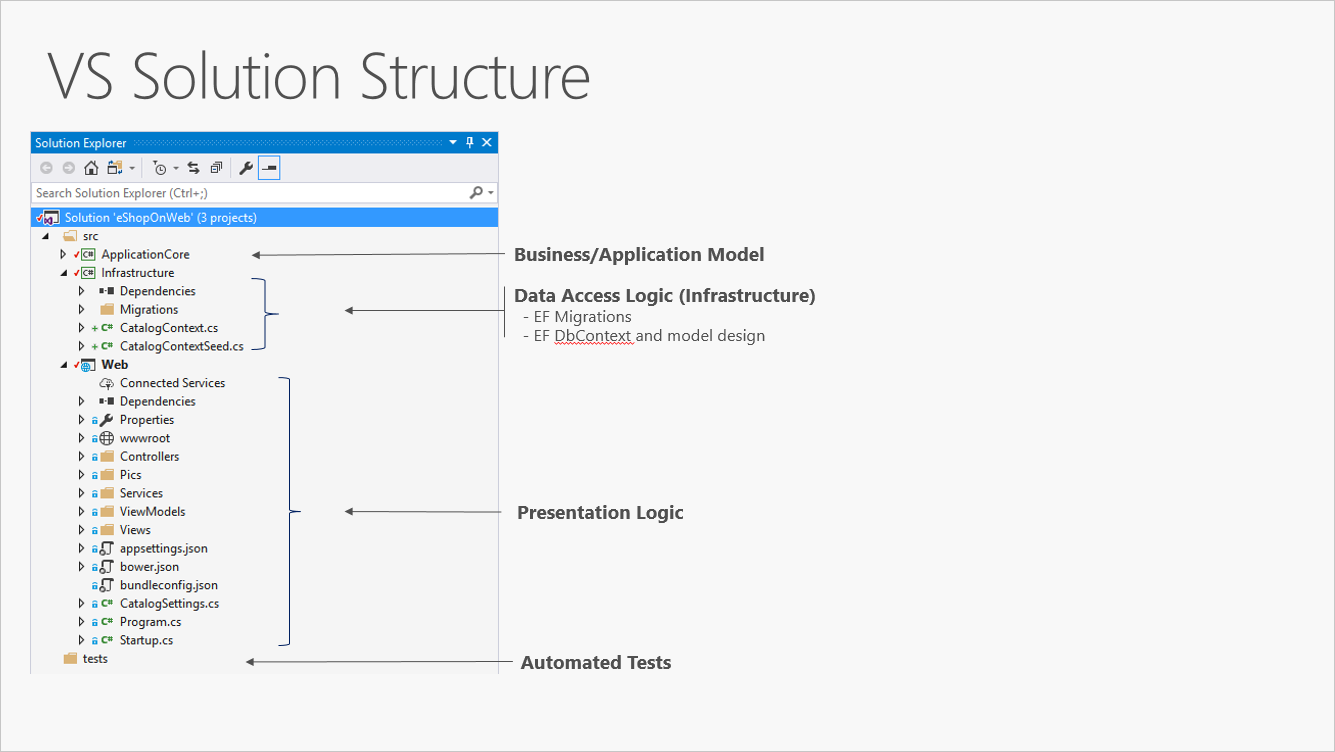
Figura 5-3. Semplice applicazione monolitica con tre progetti.
Anche se questa applicazione usa diversi progetti ai fini organizzativi, viene comunque distribuita come singola unità e i client interagiranno con essa come singola app Web. Ciò consente un processo di distribuzione molto semplice. La figura 5-4 illustra come è possibile ospitare questa app usando Microsoft Azure.
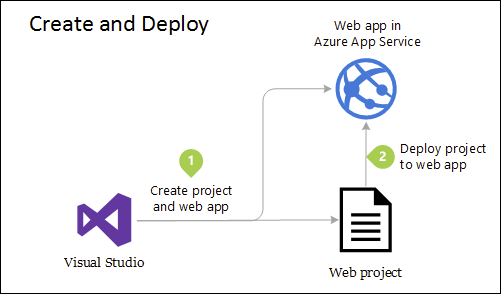
Figura 5-4. Semplice distribuzione dell'app Web di Azure
L'aumento dei requisiti dell'applicazione può determinare la necessità di soluzioni di distribuzione più solide e complesse. La figura 5-5 illustra un esempio di un piano di distribuzione più complesso che supporta funzionalità aggiuntive.
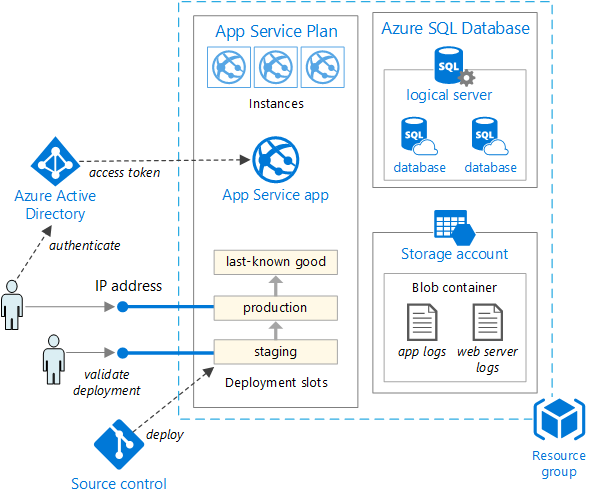
Figura 5-5. Distribuzione di un'app Web in un servizio app di Azure
L'organizzazione di questo progetto in più progetti basati sulla responsabilità consente di migliorare internamente la manutenibilità dell'applicazione.
Per trarre vantaggio dalla scalabilità su richiesta basata sul cloud è possibile scalare questa unità verticalmente oppure orizzontalmente. Per scalabilità verticale si intende l'aggiunta di CPU, memoria, spazio su disco o altre risorse aggiuntive ai server che ospitano l'app. Per scalabilità orizzontale si intende l'aggiunta di istanze aggiuntive di questi server, che si tratti di server fisici, macchine virtuali o contenitori. Quando l'app è ospitata in più istanze viene usato un servizio di bilanciamento del carico per assegnare le richieste alle istanze individuali dell'app.
L'approccio più semplice alla scalabilità di un'applicazione Web in Azure consiste nel configurare la scalabilità manualmente nel piano di servizio app dell'applicazione. La figura 5-6 illustra la schermata appropriata del dashboard di Azure in cui configurare il numero di istanze in uso per un'app.
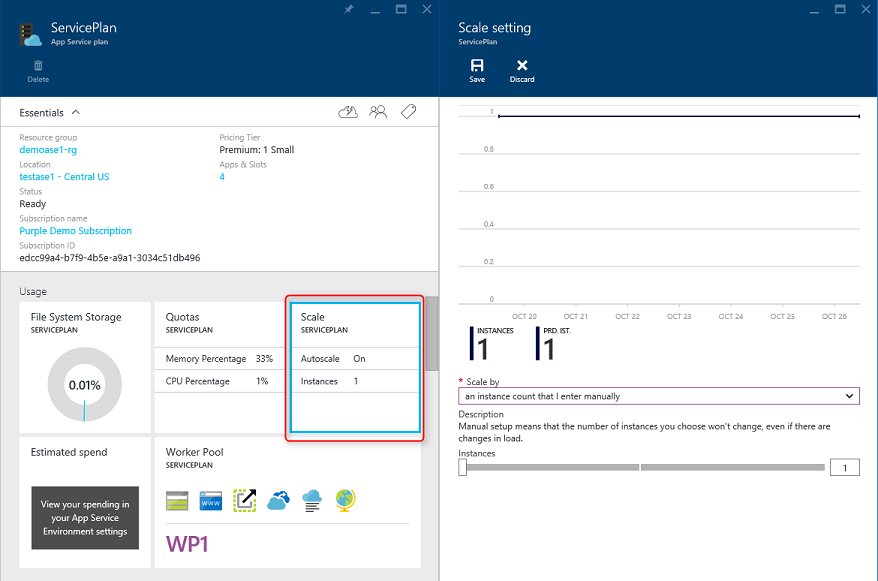
Figura 5-6. Scalabilità nel piano di servizio app in Azure.
Architettura pulita
Le applicazioni che osservano il principio DIP (Dependency Inversion Principle, principio di inversione delle dipendenze) e il principio DDD (Domain-Driven Design, progettazione basata su domini) tendono ad arrivare a un'architettura simile. Nel corso degli anni, questa architettura è stata indicata con molti nomi diversi. Uno dei primi nomi è stato Architettura esagonale, seguito da "Porte-e-adattatori". Più di recente, è stata indicata come Onion Architecture (Architettura ad anelli) o Clean Architecture (Architettura pulita). In questo e-book viene usato quest'ultimo nome, ovvero Architettura pulita.
L'applicazione di riferimento eShopOnWeb usa l'approccio Architettura pulita per organizzare il codice in progetti. È possibile trovare un modello di soluzione che puoi usare come punto di partenza per le tue soluzioni ASP.NET Core nel repository GitHub ardalis/cleanarchitecture o installando il modello da NuGet.
Nell'Architettura pulita la logica di business e il modello applicativo sono posti al centro dell'applicazione. La logica di business non dipende dall'accesso ai dati o da altre competenze dell'infrastruttura. Questa dipendenza viene invece invertita: i dettagli relativi all'infrastruttura e all'implementazione dipendono dal nucleo applicativo. Questa funzionalità si ottiene definendo le astrazioni, o interfacce, nel nucleo applicativo. Queste vengono quindi implementate dai tipi definiti nel livello infrastruttura. Un modo comune per visualizzare questa architettura è l'uso di una serie di cerchi concentrici, simile a una struttura ad anelli. La figura 5-7 illustra un esempio di questo stile di rappresentazione dell'architettura.
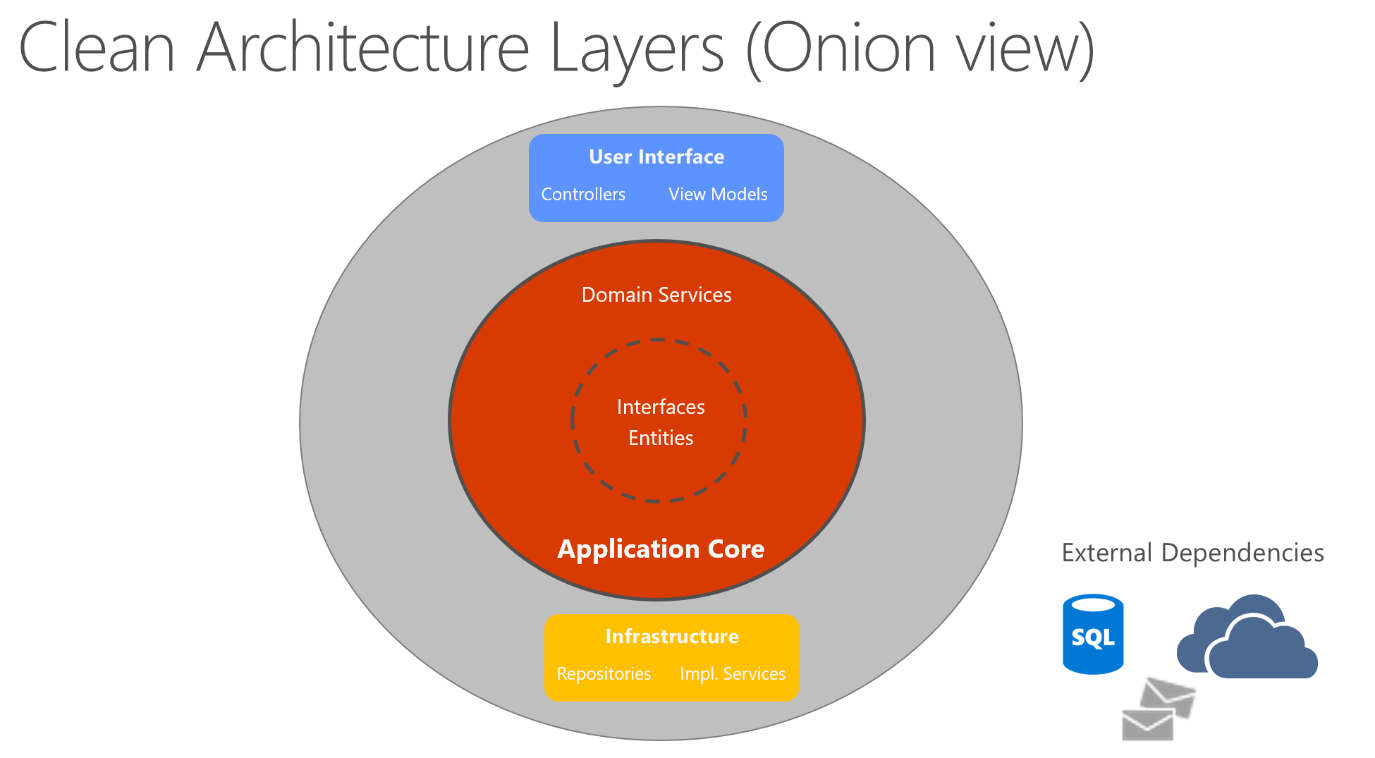
Figura 5-7. Architettura pulita, visualizzazione ad anelli
In questo diagramma le dipendenze fluiscono verso il cerchio più interno. Il nucleo applicativo prende il nome dalla sua posizione in questo diagramma. È inoltre possibile vedere dal diagramma che il nucleo applicativo non ha dipendenze da altri livelli dell'applicazione. Le entità e le interfacce dell'applicazione si trovano nella parte più centrale. All'esterno, ma ancora nel nucleo applicativo, si trovano i servizi di dominio che in genere implementano le interfacce definite nel cerchio più interno. All'esterno del nucleo applicativo, i livelli UI e Infrastruttura dipendono dal nucleo applicativo, ma non hanno dipendenze reciproche (necessariamente).
La figura 5-8 illustra un diagramma più tradizionale con livelli orizzontali che riflette meglio la dipendenza tra il livello UI e gli altri livelli.
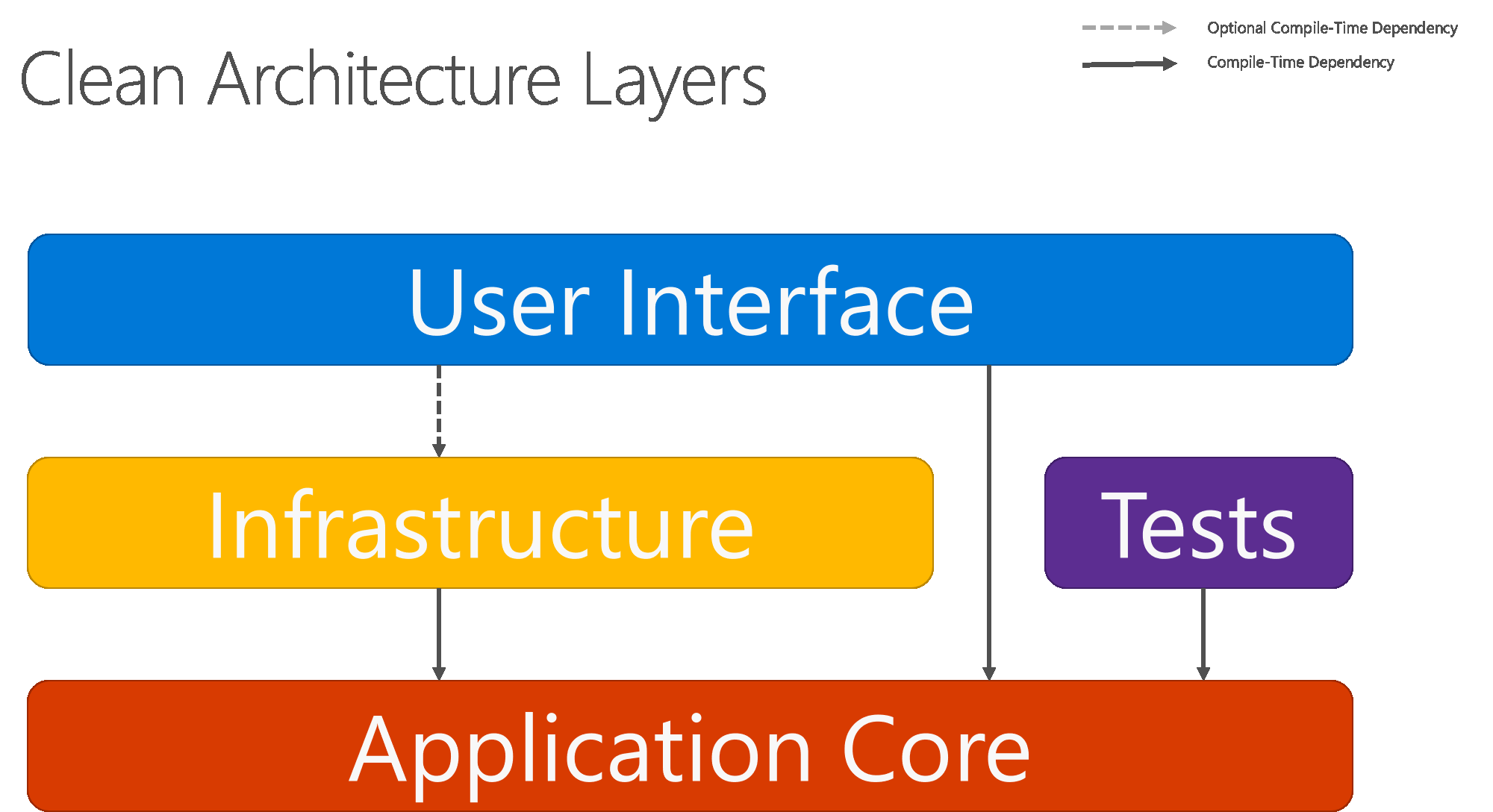
Figura 5-8. Architettura pulita, visualizzazione con livelli orizzontali
Si noti che le frecce continue rappresentano le dipendenze in fase di compilazione, mentre la freccia tratteggiata rappresenta una dipendenza solo di runtime. Nell'Architettura pulita il livello UI usa le interfacce definite nel nucleo applicativo in fase di compilazione e idealmente non dovrebbe avere alcuna conoscenza dei tipi di implementazione definiti nel livello infrastruttura. In fase di runtime, tuttavia, questi tipi di implementazione sono necessari per l'esecuzione dell'app e devono quindi essere presenti e associati alle interfacce del nucleo applicativo tramite l'inserimento di dipendenze.
La figura 5-9 illustra una visualizzazione più dettagliata dell'architettura di un'applicazione ASP.NET Core quando viene compilata seguendo queste indicazioni.
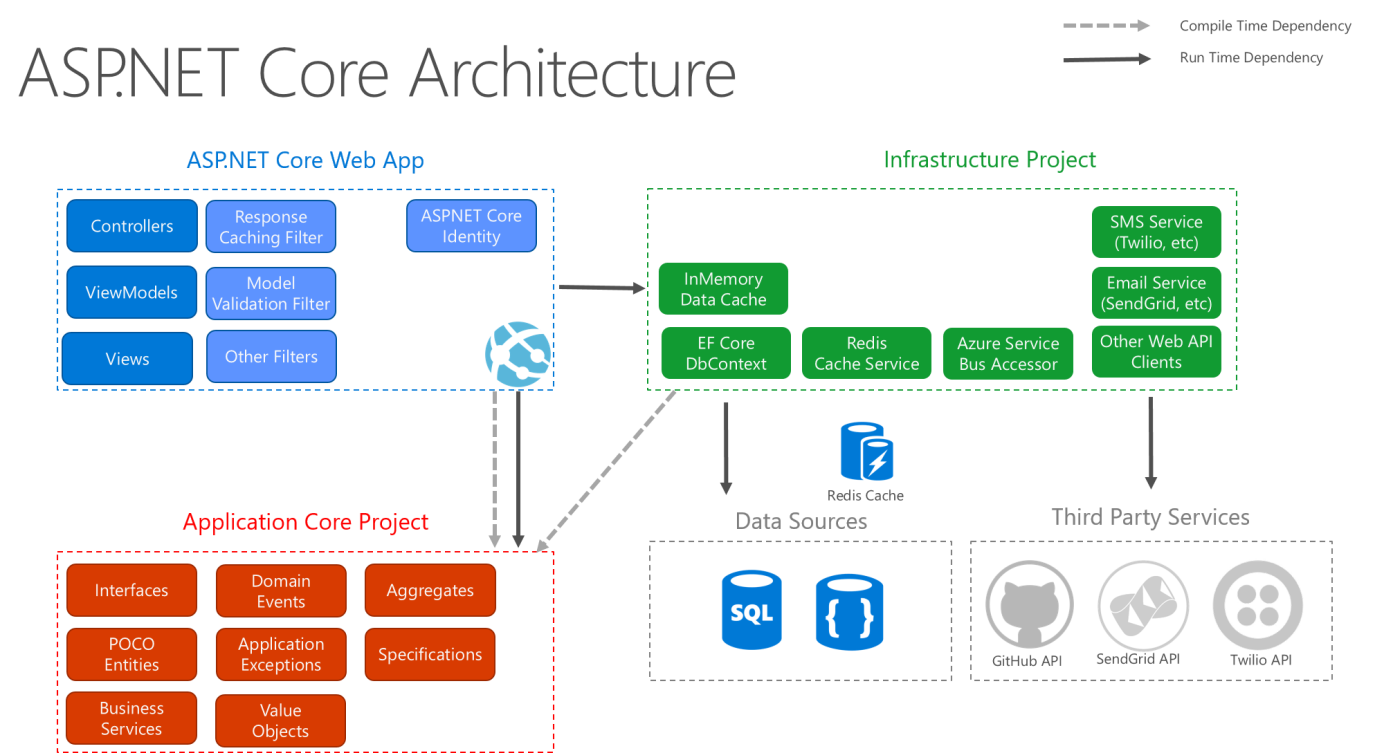
Figura 5-9. Diagramma dell'architettura ASP.NET Core in base all'Architettura pulita.
Poiché il nucleo applicativo non dipende dall'infrastruttura, la scrittura di unit test automatizzati per questo livello risulta molto semplice. Le figure 5-10 e 5-11 illustrano come i test si inseriscono in questa architettura.
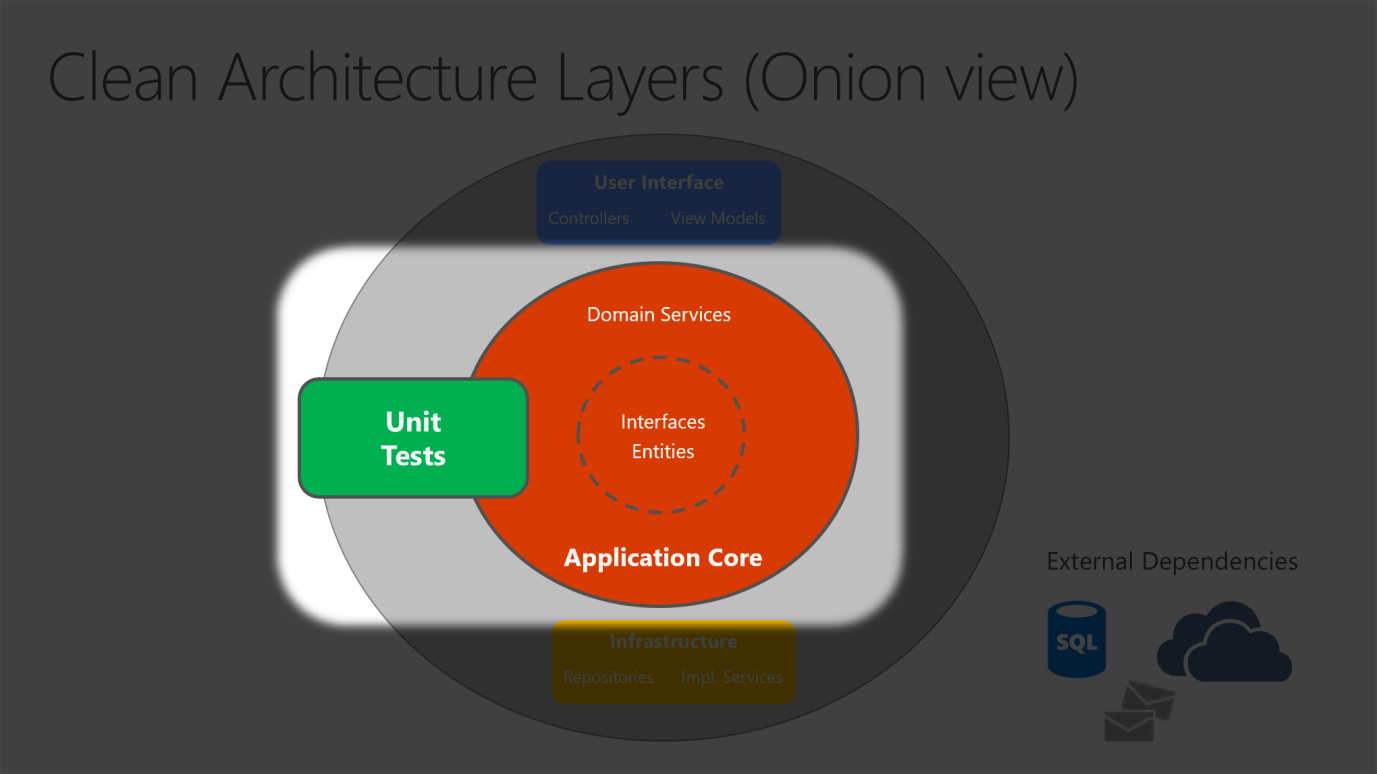
Figura 5-10. Testing unità del nucleo applicativo in isolamento.

Figura 5-11. Test di integrazione delle implementazioni di infrastruttura con dipendenze esterne.
Poiché il livello UI non ha alcuna dipendenza diretta dai tipi definiti nel progetto di infrastruttura, la sostituzione delle implementazioni per facilitare i test o in risposta a eventuali modifiche dei requisiti dell'applicazione risulta molto semplice. Grazie all'uso predefinito e al supporto dell'inserimento delle dipendenze offerti da ASP.NET Core, questa architettura rappresenta il modo più appropriato di strutturare applicazioni monolitiche complesse.
Per le applicazioni monolitiche, i progetti relativi al nucleo applicativo, all'infrastruttura e all'interfaccia utente vengono tutti eseguiti come singola applicazione. L'architettura di runtime dell'applicazione può essere simile a quella illustrata nella figura 5-12.
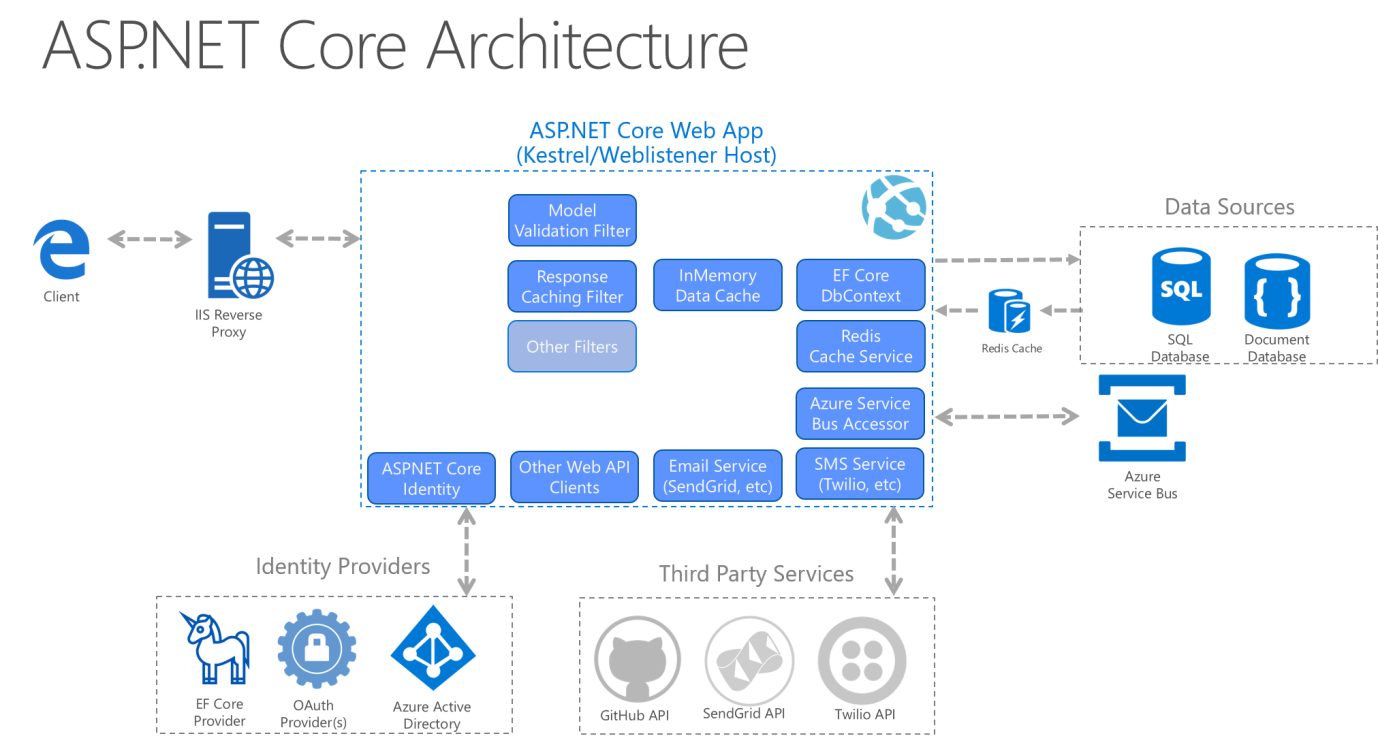
Figura 5-12. Architettura di runtime di un'app ASP.NET Core di esempio.
Organizzazione del codice nell'Architettura pulita
In una soluzione di Architettura pulita ogni progetto ha responsabilità chiare. A ogni progetto appartengono quindi determinati tipi e si troveranno spesso cartelle corrispondenti a questi tipi nel progetto appropriato.
Application Core
Il nucleo applicativo contiene il modello aziendale che include entità, servizi e interfacce. Queste interfacce includono le astrazioni per le operazioni che verranno eseguite usando l'infrastruttura, ad esempio l'accesso ai dati, l'accesso al file system, le chiamate di rete e così via. A volte i servizi o le interfacce definiti a questo livello devono operare con tipi non entità senza alcuna dipendenza dall'interfaccia utente o dall'infrastruttura. Questi tipi possono essere definiti come semplici DTO (Data Transfer Object).
Tipi del nucleo applicativo
- Entità (classi del modello aziendale persistenti)
- Aggregazioni (gruppi di entità)
- Interfacce
- Servizi di dominio
- Specifiche
- Eccezioni personalizzate e clausole guard
- Eventi e gestori di dominio
Infrastruttura
Il progetto di infrastruttura include in genere le implementazioni di accesso ai dati. In una tipica applicazione Web ASP.NET Core queste implementazioni includono la classe DbContext di Entity Framework, gli eventuali oggetti Migration EF Core che sono stati definiti e le classi delle implementazioni di accesso ai dati. Il metodo più comune per l'astrazione del codice di implementazione di accesso ai dati è tramite l'uso dello schema progettuale repository.
Oltre alle implementazioni di accesso ai dati, il progetto di infrastruttura deve contenere le implementazioni dei servizi che devono interagire con le competenze dell'infrastruttura. Questi servizi devono implementare le interfacce definite nel nucleo applicativo. Di conseguenza, l'infrastruttura deve contenere un riferimento al progetto del nucleo applicativo.
Tipi dell'infrastruttura
- Tipi EF Core (
DbContext,Migration) - Tipi di implementazione di accesso ai dati (repository)
- Servizi specifici dell'infrastruttura (ad esempio,
FileLoggeroSmtpNotifier)
Livello interfaccia utente
Il livello UI in un'applicazione MVC ASP.NET Core rappresenta il punto di ingresso per l'applicazione. Questo progetto deve fare riferimento al progetto del nucleo applicativo e i relativi tipi devono interagire con l'infrastruttura esclusivamente tramite le interfacce definite nel nucleo applicativo. Nel livello UI non devono essere consentite creazioni di istanze dirette o chiamate statiche ai tipi del livello infrastruttura.
Tipi di livello interfaccia utente
- Controller
- Filtri personalizzati
- Middleware personalizzato
- Visualizzazioni
- ViewModel
- Startup
La classe Startup o il file Program.cs è responsabile della configurazione dell'applicazione e del collegamento dei tipi di implementazione alle interfacce. La posizione in cui viene eseguita questa logica è nota come radice di composizione dell'app ed è ciò che consente l'inserimento delle dipendenze per il corretto funzionamento in fase di esecuzione.
Nota
Per collegare l'inserimento delle dipendenze durante l'avvio dell'app, il progetto a livello di interfaccia utente potrebbe avere bisogno del riferimento al progetto Infrastruttura. Questa dipendenza può essere eliminata semplicemente usando un contenitore di inserimento delle dipendenze personalizzato con supporto predefinito per il caricamento di tipi dagli assembly. Ai fini di questo esempio, l'approccio più semplice è consentire al progetto dell'interfaccia utente di fare riferimento al progetto Infrastruttura (ma gli sviluppatori devono limitare i riferimenti effettivi ai tipi del progetto Infrastruttura alla radice della composizione dell'app).
Applicazioni monolitiche e contenitori
È possibile compilare una singola applicazione o un singolo servizio Web basati sulla distribuzione monolitica e distribuirli come contenitore. All'interno dell'applicazione, il contenitore può non essere monolitico ma organizzato in più librerie, componenti o livelli. Esternamente è un singolo contenitore, con un singolo processo, una singola applicazione Web o un singolo servizio.
Per gestire questo modello, distribuire un singolo contenitore per rappresentare l'applicazione. Per la scalabilità, è sufficiente aggiungere altre copie con un servizio di bilanciamento del carico. La semplicità deriva dalla gestione di un'unica distribuzione in un singolo contenitore o una singola macchina virtuale.
È possibile includere più componenti/librerie o livelli interni in ogni contenitore, come illustrato nella figura 5-13. In base al principio secondo il quale "un contenitore esegue un'operazione e lo fa in un unico processo", tuttavia, lo schema monolitico potrebbe generare conflitti.
Lo svantaggio di questo approccio diventa evidente con l'eventuale crescita dell'applicazione, che ne richiede il ridimensionamento. Se l'intera applicazione viene ridimensionata, non ci sono problemi. Tuttavia, nella maggior parte dei casi, alcune parti dell'applicazione rappresentano colli di bottiglia che richiedono il ridimensionamento, mentre altri componenti vengono usati di meno.
Usando il tipico esempio di e-commerce, la parte che probabilmente sarà necessario ridimensionare è il componente relativo alle informazioni sui prodotti. Il numero di clienti che visualizzano i prodotti è molto superiore al numero di quelli che li acquistano. Molti più clienti usano il carrello per poi usare la pipeline di pagamento, meno clienti aggiungono commenti o visualizzano la cronologia degli acquisti. E probabilmente solo pochi dipendenti, in una singola area, avranno bisogno di gestire i contenuti e le campagne di marketing. Con il ridimensionamento della progettazione monolitica, tutto il codice viene distribuito più volte.
Oltre al problema del ridimensionamento di tutti i componenti, le modifiche apportate a un singolo componente richiedono la completa riesecuzione dei test sull'intera applicazione e una ridistribuzione completa di tutte le istanze.
L'approccio monolitico è comune e molte organizzazioni usano questo approccio architetturale nelle loro attività di sviluppo. Molte stanno ottenendo buoni risultati, mentre altre stanno raggiungendo i limiti. Molte organizzazioni hanno progettato le proprie applicazioni usando questo modello perché gli strumenti e l'infrastruttura a loro disposizione erano troppo complesse per creare architetture orientate ai servizi e perché non ne hanno intravisto la necessità fino a quando le dimensioni dell'app non sono aumentate. Nel caso in cui i limiti dell'approccio monolitico stiano per essere raggiunti, la suddivisione dell'app per ottenere un uso migliore di contenitori e microservizi può costituire il passaggio logico successivo.
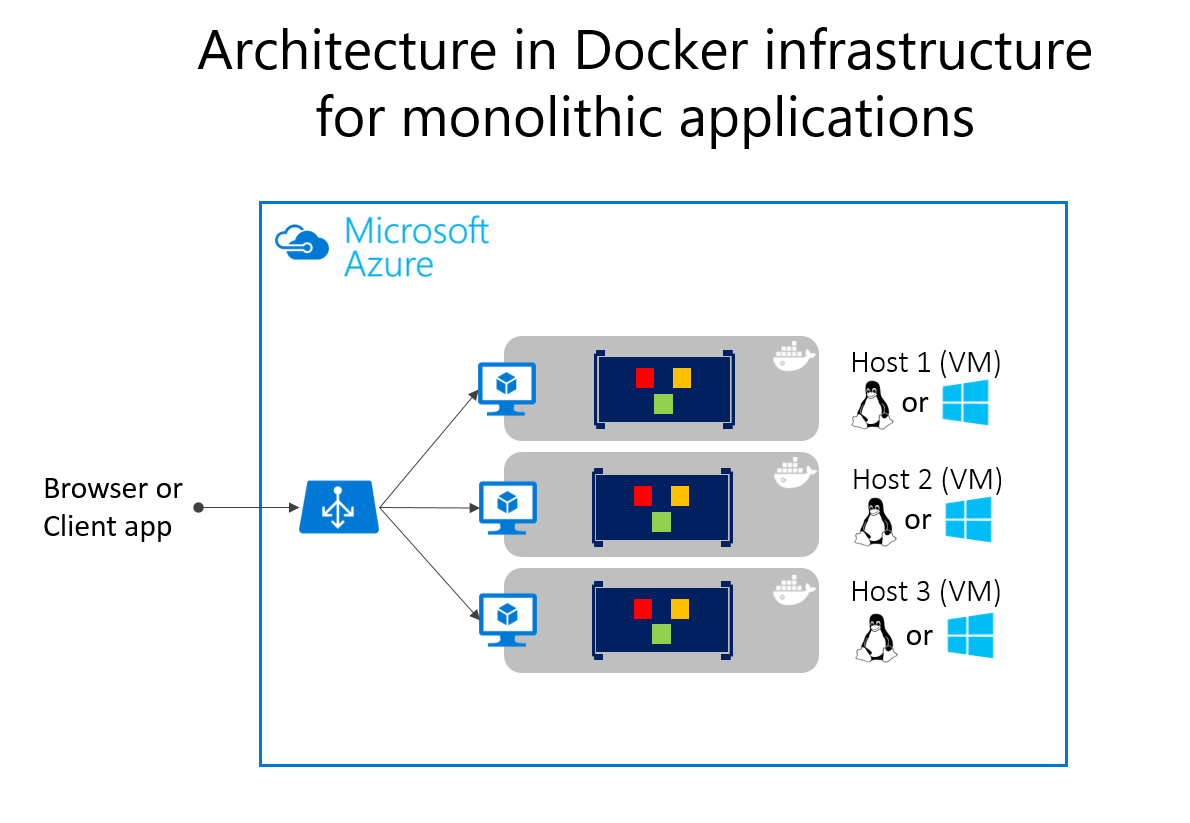
La distribuzione delle applicazioni monolitiche in Microsoft Azure può essere realizzata usando macchine virtuali dedicate per ogni istanza. Con i set di scalabilità di macchine virtuali di Microsoft Azure è possibile ridimensionare facilmente le macchine virtuali. I Servizi app di Azure sono in grado di eseguire le applicazioni monolitiche e di ridimensionare facilmente le istanze senza la necessità di gestire le macchine virtuali. I Servizi app di Azure possono eseguire anche singole istanze di contenitori Docker, semplificando la distribuzione. Usando Docker, è possibile distribuire una singola macchina virtuale come host Docker ed eseguire più istanze. Usando il bilanciamento del carico di Azure, come illustrato nella figura 5-14, è possibile gestire il ridimensionamento.
La distribuzione ai vari host può essere gestita con le tecniche di distribuzione tradizionali. Gli host Docker possono essere gestiti con comandi come docker run eseguiti manualmente o tramite automazione, ad esempio le pipeline di recapito continuo.
Applicazione monolitica distribuita come contenitore
L'uso dei contenitori per gestire le distribuzioni di applicazioni monolitiche offre alcuni vantaggi. Il ridimensionamento di istanze di contenitori è molto più veloce e semplice rispetto alla distribuzione di macchine virtuali aggiuntive. Anche quando si usano i set di scalabilità di macchine virtuali per ridimensionare le VM, la loro creazione richiede tempo. Quando viene distribuita come istanza dell'app, la configurazione dell'app viene gestita nell'ambito della macchina virtuale.
La distribuzione degli aggiornamenti come immagini Docker è molto più veloce ed efficiente per la rete. L'avvio delle immagini Docker richiede in genere pochi secondi, consentendo implementazioni più veloci. Per chiudere un'istanza di Docker, è sufficiente eseguire un comando docker stop che viene normalmente completato in meno di un secondo.
Poiché i contenitori sono implicitamente non modificabili per impostazione predefinita, le macchine virtuali danneggiate non costituiscono un problema, mentre gli script di aggiornamento potrebbero tralasciare alcune configurazioni o file specifici rimasti sul disco.
È possibile usare i contenitori Docker per una distribuzione monolitica di applicazioni Web più semplici. Questo approccio migliora le pipeline di integrazione continua e distribuzione continua e consente di ottenere risultati ottimali dalla distribuzione alla produzione, evitando situazioni in cui quello che funziona in un computer, non funziona nell'ambiente di produzione.
Un'architettura basata su microservizi offre numerosi vantaggi, ma al costo di una maggiore complessità. In alcuni casi i costi superano i vantaggi. Un'applicazione con distribuzione monolitica in esecuzione in un unico contenitore o in pochi contenitori è pertanto un'opzione migliore.
Un'applicazione monolitica potrebbe non essere facilmente scomponibile in microservizi ben distinti. I microservizi dovrebbero funzionare indipendentemente uno dall'altro per garantire un'applicazione più resiliente. Se non è possibile creare sezioni di funzionalità indipendenti dell'applicazione, una separazione aggiunge solo complessità.
Per un'applicazione potrebbe non essere necessaria la scalabilità delle funzionalità in modo indipendente. Molte applicazioni, quando è necessario ridimensionare più di una singola istanza, possono farlo tramite il processo relativamente semplice di clonazione dell'intera istanza. Il lavoro aggiuntivo per separare l'applicazione in servizi distinti offre vantaggi minimi quando il ridimensionamento delle istanze complete dell'applicazione è semplice ed economicamente conveniente.
Nelle prime fasi di sviluppo di un'applicazione, i limiti funzionali naturali potrebbero inoltre non essere ancora chiari. Durante lo sviluppo di un prodotto valido minimo, la separazione naturale potrebbe non essere ancora emersa. Alcune di queste condizioni potrebbero essere temporanee. Si potrebbe iniziare creando un'applicazione monolitica e successivamente separare alcune funzionalità da sviluppare e distribuire come microservizi. Altre condizioni potrebbero essere essenziali per i problemi dell'applicazione, vale a dire che l'applicazione potrebbe non essere mai suddivisa in più microservizi.
La separazione di un'applicazione in più processi distinti presenta anche il problema del sovraccarico. La separazione delle funzionalità in processi diversi incrementa la complessità. I protocolli di comunicazione diventano più complessi. Invece delle chiamate ai metodi, è necessario usare comunicazioni asincrone tra i servizi. Quando si passa a un'architettura di microservizi, è necessario aggiungere molti dei blocchi predefiniti implementati nella versione dei microservizi dell'applicazione eShopOnContainers: gestione del bus di eventi, resilienza dei messaggi e nuovi tentativi, coerenza futura e altro ancora.
L'applicazione di riferimento eShopOnWeb, molto più semplice, supporta l'utilizzo del contenitore monolitico a contenitore singolo. L'applicazione include un'applicazione Web con visualizzazioni MVC tradizionali, API Web e Razor Pages. Facoltativamente, è possibile eseguire il componente amministratore basato su Blazor dell'applicazione, che richiede anche l'esecuzione di un progetto API separato.
L'applicazione può essere avviata dalla radice della soluzione usando i comandi docker-compose build e docker-compose up. Questo comando configura un contenitore per l'istanza Web usando l'oggetto Dockerfile all'interno della radice del progetto Web ed esegue il contenitore in una porta specifica. È possibile scaricare l'origine per questa applicazione da GitHub ed eseguirla in locale. Anche questa applicazione monolitica trae vantaggio dalla distribuzione in un ambiente basato su contenitori.
Da una parte, la distribuzione in contenitori significa che ogni istanza dell'applicazione è eseguita nello stesso ambiente. Questo approccio include l'ambiente di sviluppo in cui hanno luogo le fasi di test preliminare e di sviluppo. Il team di sviluppo può eseguire l'applicazione in un ambiente basato su contenitori corrispondente all'ambiente di produzione.
Inoltre, la scalabilità orizzontale delle applicazioni incluse in contenitori è garantita a un costo inferiore. L'uso di un ambiente basato su contenitori consente una maggiore condivisione di risorse rispetto agli ambienti di macchine virtuali tradizionali.
Infine, l'inserimento dell'applicazione in contenitori impone una separazione tra la logica di business e il server di archiviazione. Di pari passo con la scalabilità orizzontale dell'applicazione, i diversi contenitori si baseranno tutti su un singolo supporto di archiviazione fisica, che sarà in genere un server a disponibilità elevata che esegue un database SQL Server.
Supporto Docker
Il progetto eShopOnWeb viene eseguito in .NET. Pertanto, può essere eseguito sia in contenitori basati su Linux che in contenitori basati su Windows. Si noti che per la distribuzione di Docker viene usato lo stesso tipo di host per SQL Server. I contenitori basati su Linux consentono un footprint minore e sono preferibili.
È possibile usare Visual Studio 2017 o versione successiva per aggiungere il supporto per Docker a un'applicazione esistente facendo clic con il pulsante destro del mouse su un progetto in Esplora soluzioni e scegliendo Aggiungi>Supporto Docker. Questo passaggio aggiunge i file necessari e modifica il progetto per il loro uso. L'esempio eShopOnWeb corrente include già i file.
Il file docker-compose.yml a livello di soluzione contiene informazioni sulle immagini da compilare e i contenitori da avviare. Il file consente di usare il comando docker-compose per avviare più applicazioni contemporaneamente. In questo caso avvia solo il progetto Web. È anche possibile usarlo per configurare le dipendenze, ad esempio un contenitore di database separato.
version: '3'
services:
eshopwebmvc:
image: eshopwebmvc
build:
context: .
dockerfile: src/Web/Dockerfile
environment:
- ASPNETCORE_ENVIRONMENT=Development
ports:
- "5106:5106"
networks:
default:
external:
name: nat
Il file docker-compose.yml fa riferimento a Dockerfile nel progetto Web. L'oggetto Dockerfile viene usato per specificare quale contenitore di base sarà usato e in che modo verrà configurata di conseguenza l'applicazione. In Dockerfile di Web:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.sln .
COPY . .
WORKDIR /app/src/Web
RUN dotnet restore
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0 AS runtime
WORKDIR /app
COPY --from=build /app/src/Web/out ./
ENTRYPOINT ["dotnet", "Web.dll"]
Risoluzione dei problemi relativi a Docker
Dopo avere avviato l'applicazione in contenitori, questa rimane in esecuzione fino a quando non viene arrestata. È possibile visualizzare quali contenitori sono in esecuzione usando il comando docker ps. È possibile arrestare un contenitore in esecuzione usando il comando docker stop e specificando l'ID del contenitore.
I contenitori Docker in esecuzione potrebbero essere associati a porte che potrebbero altrimenti essere usate nell'ambiente di sviluppo. Se si tenta di eseguire un'applicazione o il debug dell'applicazione usando la stessa porta di un contenitore Docker in esecuzione, viene visualizzato un errore indicante l'impossibilità da parte del server di collegarsi a tale porta. L'arresto del contenitore dovrebbe anche in questo caso risolvere il problema.
Se si vuole aggiungere il supporto per Docker all'applicazione tramite Visual Studio, assicurarsi che Docker Desktop sia in esecuzione quando si esegue questa operazione. La procedura guidata non verrà eseguita correttamente se Docker Desktop non è in esecuzione quando la procedura viene avviata. Inoltre, la procedura guidata esamina la scelta del contenitore corrente per aggiungere il supporto per Docker corretto. Se si vuole aggiungere il supporto per i contenitori Windows, è necessario eseguire la procedura guidata mentre Docker Desktop è in esecuzione con i contenitori Windows configurati. Se si vuole aggiungere il supporto per i contenitori Linux, eseguire la procedura guidata mentre Docker è in esecuzione con i contenitori Linux configurati.
Altri stili di architettura dell'applicazione Web
- Web-Coda-Ruolo di lavoro: i componenti principali di questa architettura sono un front-end Web che gestisce le richieste client e un ruolo di lavoro che esegue attività a elevato utilizzo di risorse, flussi di lavoro a esecuzione prolungata o processi batch. Il front-end Web comunica con il ruolo di lavoro tramite una coda di messaggi.
- Livello N: un'architettura a più livelli divide un'applicazione in livelli logici e livelli fisici.
- Microservizi: un'architettura di microservizi è costituita da un insieme di servizi autonomi di piccole dimensioni. Ogni servizio è indipendente e deve implementare una singola funzionalità aziendale all'interno di un contesto delimitato.
Riferimenti - Architetture Web comuni
- Architettura pulita
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html - Architettura ad anelli
https://jeffreypalermo.com/blog/the-onion-architecture-part-1/ - Schema repository
https://deviq.com/repository-pattern/ - Modello di soluzione con Architettura pulita
https://github.com/ardalis/cleanarchitecture - Architecting Microservices e-book (E-book Progettazione di microservizi)
https://aka.ms/MicroservicesEbook - Progettazione basata su domini (DDD)
https://learn.microsoft.com/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per