Opzioni di archiviazione dati (compilazione di app cloud Real-World con Azure)
Scaricare Fix It Project o Scaricare E-book
L'e-book Building Real World Cloud Apps with Azure si basa su una presentazione sviluppata da Scott Guthrie. Illustra 13 modelli e procedure che consentono di sviluppare correttamente app Web per il cloud. Per informazioni sull'e-book, vedere il primo capitolo.
La maggior parte delle persone viene usata per i database relazionali e tende a ignorare altre opzioni di archiviazione dei dati quando progettano un'app cloud. Il risultato può essere prestazioni non ottimali, spese elevate o peggio, perché i database NoSQL (non relazionali) possono gestire alcune attività in modo più efficiente rispetto ai database relazionali. Quando i clienti ci chiedono aiuto per risolvere un problema critico di archiviazione dei dati, spesso si tratta di un database relazionale in cui una delle opzioni NoSQL avrebbe funzionato meglio. In queste situazioni il cliente sarebbe stato migliore se avesse implementato la soluzione NoSQL prima di distribuire l'app nell'ambiente di produzione.
D'altra parte, sarebbe anche un errore presupporre che un database NoSQL possa fare tutto bene o abbastanza bene. Non esiste una singola scelta di gestione dei dati ottimale per tutte le attività di archiviazione dei dati; diverse soluzioni di gestione dei dati sono ottimizzate per attività diverse. La maggior parte delle app cloud reali ha un'ampia gamma di requisiti di archiviazione dei dati e viene spesso servita al meglio da una combinazione di più soluzioni di archiviazione dati.
Lo scopo di questo capitolo è quello di offrire un'idea più ampia delle opzioni di archiviazione dei dati disponibili per un'app cloud e alcune indicazioni di base su come scegliere quelle adatte allo scenario. È consigliabile essere consapevoli delle opzioni disponibili e pensare ai punti di forza e alle debolezze prima di sviluppare un'applicazione. La modifica delle opzioni di archiviazione dei dati in un'app di produzione può essere estremamente difficile, ad esempio la necessità di modificare un motore jet mentre l'aereo è in volo.
Opzioni di archiviazione dei dati in Azure
Il cloud semplifica l'uso di un'ampia gamma di archivi dati Relazionali e NoSQL. Ecco alcune delle piattaforme di archiviazione dati che è possibile usare in Azure.

La tabella mostra quattro tipi di database NoSQL:
I database chiave/valore archiviano un singolo oggetto serializzato per ogni valore di chiave. Sono utili per archiviare grossi volumi di dati quando si vuole ottenere un solo elemento per un determinato valore di chiave e non si devono eseguire query in base ad altre proprietà dell'elemento.
Archiviazione BLOB di Azure è un database chiave/valore che funziona come l'archiviazione file nel cloud, con valori di chiave che corrispondono ai nomi di cartelle e file. È possibile recuperare un file in base alla cartella e al nome del file, non cercando i valori nel contenuto del file.
Archiviazione tabelle di Azure è anche un database chiave/valore. Ogni valore viene chiamato entità (simile a una riga, identificata da una chiave di partizione e da una chiave di riga) e contiene più proprietà (simili alle colonne, ma non tutte le entità in una tabella devono condividere le stesse colonne). L'esecuzione di query su colonne diverse dalla chiave è estremamente inefficiente e deve essere evitata. Ad esempio, è possibile archiviare i dati del profilo utente, con una partizione che archivia le informazioni su un singolo utente. È possibile archiviare dati come nome utente, hash password, data di nascita e così via, in proprietà separate di un'entità o in entità separate nella stessa partizione. Non è tuttavia consigliabile eseguire query per tutti gli utenti con un determinato intervallo di date di nascita e non è possibile eseguire una query di join tra la tabella del profilo e un'altra tabella. L'archiviazione tabelle è più scalabile e meno costosa di un database relazionale, ma non abilita query o join complessi.
Documentdatabase sono database chiave/valore in cui i valori sono documenti. "Documento" non viene usato nel senso di un documento di Word o Excel, ma significa una raccolta di campi e valori denominati, uno dei quali può essere un documento figlio. Ad esempio, in una tabella della cronologia degli ordini un documento di ordine potrebbe contenere campi numero ordine, data ordine e cliente; e il campo del cliente potrebbe avere campi nome e indirizzo. Il database codifica i dati dei campi in un formato, ad esempio XML, YAML, JSON o BSON; oppure può usare testo normale. Una funzionalità che imposta i database di documenti oltre ai database chiave/valore è la possibilità di eseguire query su campi non chiave e definire indici secondari per rendere più efficiente l'esecuzione di query. Questa possibilità rende più adatto un database di documenti per le applicazioni che devono recuperare i dati in base a criteri più complessi rispetto al valore della chiave del documento. Ad esempio, in un database dei documenti della cronologia degli ordini di vendita è possibile eseguire query su vari campi, ad esempio ID prodotto, ID cliente, nome cliente e così via. MongoDB è un database di documenti diffuso.
I database della famiglia di colonne sono archivi dati chiave/valore che consentono di strutturare l'archiviazione dei dati in raccolte di colonne correlate denominate famiglie di colonne. Ad esempio, un database di censimento potrebbe avere un gruppo di colonne per il nome di una persona (primo, secondo, ultimo), un gruppo per l'indirizzo della persona e un gruppo per le informazioni sul profilo della persona (DOB, sesso e così via). Il database può quindi archiviare ogni famiglia di colonne in una partizione separata mantenendo tutti i dati per una persona correlata alla stessa chiave. È quindi possibile leggere tutte le informazioni sul profilo senza dover leggere tutte le informazioni sul nome e sull'indirizzo. Cassandra è un database di famiglia di colonne molto diffuso.
I database a grafo archiviano le informazioni come raccolta di oggetti e relazioni. Lo scopo di un database a grafo è consentire a un'applicazione di eseguire in modo efficiente query che attraversano la rete di oggetti e le relazioni tra di esse. Ad esempio, gli oggetti potrebbero essere dipendenti in un database delle risorse umane e potrebbe essere necessario facilitare le query, ad esempio "trovare tutti i dipendenti che lavorano direttamente o indirettamente per Scott". Neo4j è un popolare database a grafo.
Rispetto ai database relazionali, le opzioni NoSQL offrono una maggiore scalabilità e un'efficacia dei costi per l'archiviazione e l'analisi dei dati non strutturati. Il compromesso è che non forniscono funzionalità avanzate di query e integrità dei dati affidabili dei database relazionali. NoSQL funziona bene per i dati di log IIS, che comporta un volume elevato senza la necessità di eseguire query di join. NoSQL non funziona così bene per le transazioni bancarie, che richiede l'integrità assoluta dei dati e implica molte relazioni con altri dati correlati al conto.
Esiste anche una categoria più recente di piattaforma di database denominata NewSQL che combina la scalabilità di un database NoSQL con l'integrità delle query e l'integrità transazionale di un database relazionale. I database NewSQL sono progettati per l'elaborazione di query e archiviazione distribuita, spesso difficile da implementare nei database "OldSQL". NuoDB è un esempio di database NewSQL che può essere usato in Azure.
Hadoop e MapReduce
I volumi elevati di dati che è possibile archiviare nei database NoSQL possono essere difficili da analizzare in modo tempestivo. A tale scopo, è possibile usare un framework come Hadoop che implementa la funzionalità MapReduce . Essenzialmente ciò che viene eseguito da un processo MapReduce è il seguente:
- Limitare le dimensioni dei dati che devono essere elaborati selezionando fuori dall'archivio dati solo i dati effettivamente necessari per l'analisi. Ad esempio, si vuole conoscere il trucco della base utenti in base all'anno di nascita, quindi si selezionano solo gli anni di nascita dall'archivio dati del profilo utente.
- Suddividere i dati in parti e inviarli a computer diversi per l'elaborazione. Computer A calcola il numero di persone con 1950-1959 date, computer B fa 1960-1969 e così via. Questo gruppo di computer è denominato cluster Hadoop.
- Rimettere insieme i risultati di ogni parte dopo l'elaborazione delle parti. È ora disponibile un elenco relativamente breve del numero di persone per ogni anno di nascita e il compito di calcolare le percentuali in questo elenco complessivo è gestibile.
In Azure HDInsight è possibile elaborare, analizzare e ottenere nuove informazioni dai Big Data usando la potenza di Hadoop. Ad esempio, è possibile usarlo per analizzare i log del server Web:
Abilitare la registrazione del server Web nell'account di archiviazione. Questo consente di configurare Azure per scrivere log nel servizio BLOB per ogni richiesta HTTP all'applicazione. Il servizio BLOB è fondamentalmente l'archiviazione file cloud e si integra perfettamente con HDInsight.
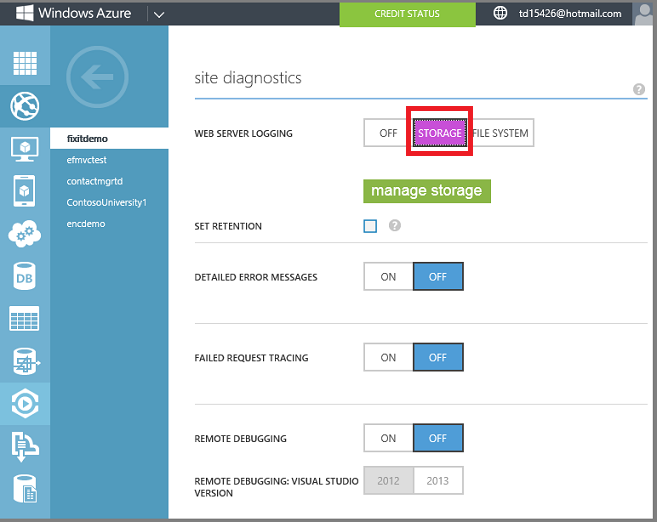
Quando l'app ottiene il traffico, i log IIS del server Web vengono scritti nell'archivio BLOB.
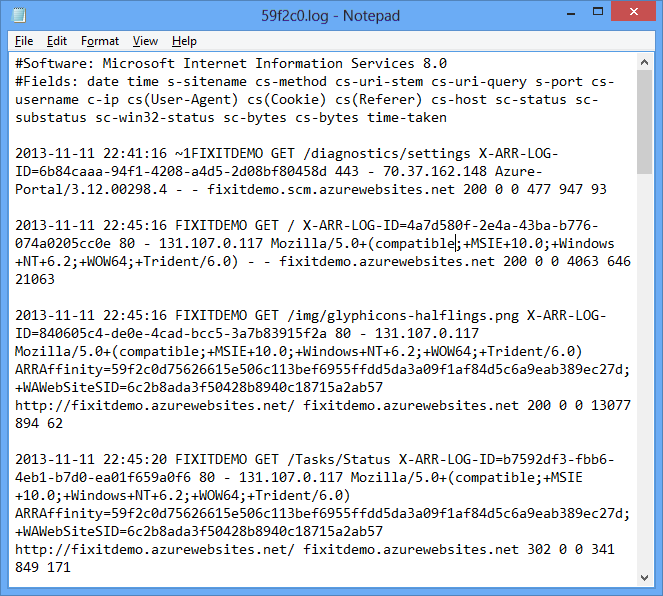
Nel portale fare clic su Nuova - creazione rapida diHDInsight - di - Servizi dati e specificare un nome del cluster HDInsight, le dimensioni del cluster (numero di nodi dati del cluster HDInsight) e un nome utente e una password per il cluster HDInsight.
È ora possibile configurare processi MapReduce per analizzare i log e ottenere risposte a domande come:
- Quali orari del giorno l'app ottiene il traffico più o meno importante?
- Da quali paesi proviene il mio traffico?
- Qual è il reddito medio del quartiere delle aree da cui proviene il mio traffico. È disponibile un set di dati pubblico che offre il reddito di quartiere in base all'indirizzo IP ed è possibile trovarne una corrispondenza con l'indirizzo IP nei log del server Web.
- In che modo il reddito di quartiere è correlato a pagine o prodotti specifici nel sito?
È quindi possibile usare le risposte a domande come queste per indirizzare gli annunci in base alla probabilità che un cliente sia interessato o probabilmente acquistare un determinato prodotto.
Come illustrato nel capitolo Automatizzare tutto, la maggior parte delle funzioni che è possibile eseguire nel portale può essere automatizzata e include la configurazione e l'esecuzione di processi di analisi di HDInsight. Uno script HDInsight tipico può contenere i passaggi seguenti:
- Effettuare il provisioning di un cluster HDInsight e collegarlo all'account di archiviazione per l'input dell'archiviazione BLOB.
- Caricare i file eseguibili del processo MapReduce (file con estensione jar o .exe) nel cluster HDInsight.
- Inviare un oggetto MapReduce che archivia i dati di output nell'archivio BLOB.
- Attendere il completamento del processo.
- Eliminare il cluster HDInsight.
- Accedere all'output dall'archivio BLOB.
Eseguendo uno script che esegue tutto questo, si riduce al minimo il tempo di provisioning del cluster HDInsight, riducendo al minimo i costi.
Piattaforma distribuita come servizio (PaaS) e infrastruttura distribuita come servizio (IaaS)
Le opzioni di archiviazione dei dati elencate in precedenza includono sia soluzioni PaaS (Platform-as-a-Service) che IaaS (Infrastructure-as-a-Service). PaaS significa che microsoft gestisce l'infrastruttura hardware e software e si usa solo il servizio. database SQL è una funzionalità PaaS di Azure. Si richiedono database e, dietro le quinte, Azure configura e configura le macchine virtuali e ne configura i database. Non si ha accesso diretto alle macchine virtuali e non è necessario gestirle. IaaS significa che si configurano, configurano e gestiscono le macchine virtuali eseguite nell'infrastruttura del data center e si inseriscono gli elementi desiderati. Vengono fornite una raccolta di immagini di macchine virtuali preconfigurato per le configurazioni di macchine virtuali comuni. Ad esempio, è possibile installare immagini vm preconfigurato per Windows Server 2008, Windows Server 2012, BizTalk Server, Oracle WebLogic Server, Oracle WebLogic Server, Oracle Database e così via.
Soluzioni dati PaaS offerte da Azure includono:
- Azure SQL Database (in precedenza noto come SQL Azure). Un database relazionale cloud basato su SQL Server.
- Archiviazione tabelle di Azure. Database NoSQL chiave/valore.
- Archiviazione BLOB di Azure. Archiviazione file nel cloud.
Per IaaS, è possibile eseguire qualsiasi operazione che è possibile caricare in una macchina virtuale, ad esempio:
- Database relazionali come SQL Server, Oracle, MySQL, SQL Compact, SQLite o Postgres.
- Archivi dati chiave/valore, ad esempio Memcached, Redis, Cassandra e Riak.
- Archivi dati di colonna, ad esempio HBase.
- Database di documenti come MongoDB, RavenDB e CouchDB.
- Database graph come Neo4j.

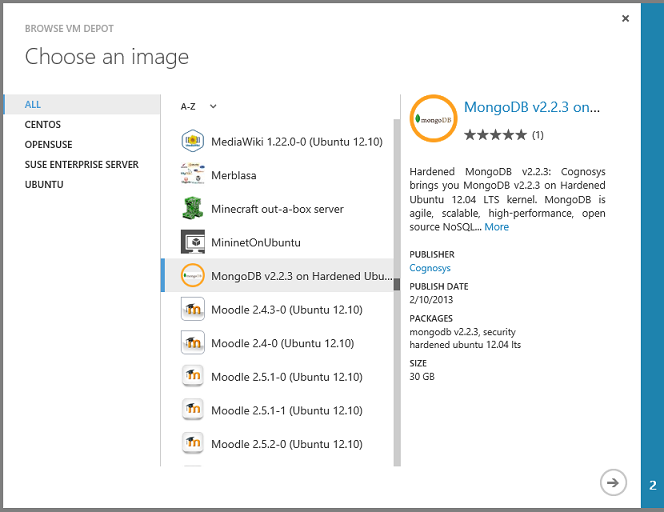
L'opzione IaaS offre opzioni di archiviazione dati quasi illimitate e molte di esse sono particolarmente facili da usare perché è possibile creare macchine virtuali usando immagini preconfigurate. Ad esempio, nel portale di gestione passare a Macchine virtuali, fare clic sulla scheda Immagini e fare clic su Sfoglia vm Depot.

Viene quindi visualizzato un elenco di centinaia di immagini di macchine virtuali preconfigurate e è possibile creare una macchina virtuale da un'immagine con un sistema di gestione del database preinstallato, ad esempio MongoDB, Neo4J, Redis, Cassandra o CouchDB:
Azure semplifica l'uso possibile delle opzioni di archiviazione dei dati IaaS, ma le offerte PaaS offrono molti vantaggi che li rendono più convenienti e pratici per molti scenari:
- Non è necessario creare macchine virtuali, è sufficiente usare il portale o uno script per configurare un archivio dati. Se si vuole un archivio dati 200 terabyte, è possibile fare clic su un pulsante o eseguire un comando e in secondi è pronto per l'uso.
- Non è necessario gestire o applicare patch alle macchine virtuali usate dal servizio; Microsoft lo fa automaticamente.- Non è necessario preoccuparsi di configurare l'infrastruttura per la scalabilità o la disponibilità elevata; Microsoft gestisce tutto ciò che per te.
- Non è necessario acquistare licenze; le tariffe di licenza sono incluse nelle tariffe del servizio.
- Si paga solo per le risorse usate.
Le opzioni di archiviazione dei dati PaaS in Azure includono offerte da provider di terze parti.
Scelta di un'opzione di archiviazione dati
Nessun approccio è giusto per tutti gli scenari. Se qualcuno dice che questa tecnologia è la risposta, la prima cosa da porre è "Qual è la domanda?", perché diverse soluzioni sono ottimizzate per cose diverse. Esistono vantaggi specifici per il modello relazionale; questo è il motivo per cui è stato intorno per così tanto tempo. Ma sono disponibili anche lati bassi per SQL che possono essere risolti con una soluzione NoSQL.
Spesso il funzionamento migliore è un approccio composizionele, in cui si usa SQL e NoSQL in una singola soluzione. Anche quando le persone dicono che stanno abbracciando NoSQL, se si esegue un drill-in quello che stanno facendo spesso si trovano a usare diversi framework NoSQL: usano CouchDB e Redis e Riak per cose diverse. Anche Facebook, che usa ampiamente NoSQL, usa framework NoSQL diversi per diverse parti del servizio. La flessibilità di combinare e soddisfare gli approcci di archiviazione dei dati è una delle cose belle del cloud, perché è facile usare più soluzioni dati e integrarle in una singola app.
Ecco alcune domande da considerare quando si sceglie un approccio:
| Semantica dei dati | - Qual è la semantica di archiviazione dei dati di base e accesso ai dati (si archiviano dati relazionali o non strutturati)? I dati non strutturati, ad esempio i file multimediali, si adattano meglio all'archiviazione BLOB; una raccolta di dati correlati, ad esempio prodotti, inventari, fornitori, ordini dei clienti e così via, si adatta meglio a un database relazionale. |
|---|---|
| Supporto query | - Come è facile eseguire query sui dati? - Quali tipi di domande possono essere poste in modo efficiente? Gli archivi dati chiave/valore sono molto buoni per ottenere una singola riga data un valore chiave, ma non così buono per le query complesse. Per un archivio dati del profilo utente in cui si ottengono sempre i dati per un utente specifico, un archivio dati chiave/valore potrebbe funzionare correttamente; per un catalogo di prodotti in cui si desidera ottenere raggruppamenti diversi in base a vari attributi di prodotto un database relazionale potrebbe funzionare meglio. I database NoSQL possono archiviare grandi volumi di dati in modo efficiente, ma è necessario strutturare il database in base al modo in cui l'app esegue query sui dati e ciò rende più difficile eseguire query ad hoc. Con un database relazionale, è possibile compilare quasi qualsiasi tipo di query. |
| Proiezione funzionale | - È possibile eseguire domande, aggregazioni e così via? Se si esegue SELECT COUNT(*) da una tabella in SQL, si esegue in modo molto efficiente tutto il lavoro sul server e restituisce il numero che si sta cercando. Se si vuole lo stesso calcolo da un archivio dati NoSQL che non supporta l'aggregazione, si tratta di una query "non in uscita" inefficiente e probabilmente timeout. Anche se la query ha esito positivo, è necessario recuperare tutti i dati dal server al client e contare le righe nel client. - Quali linguaggi o tipi di espressioni possono essere usati? Con un database relazionale è possibile usare SQL. Con alcuni database NoSQL, ad esempio Archiviazione tabelle di Azure, si userà OData e tutto ciò che è possibile fare è filtrare sulla chiave primaria e ottenere proiezioni (selezionare un subset dei campi disponibili). |
| Facilità di scalabilità | - Quanto spesso e quanti dati devono ridimensionare? - La piattaforma implementa in modo nativo la scalabilità orizzontale? - Come è facile aggiungere/rimuovere capacità (dimensioni e velocità effettiva)? I database relazionali e le tabelle non vengono partizionati automaticamente per renderli scalabili, quindi sono difficili da ridimensionare oltre determinate limitazioni. Gli archivi dati NoSQL come l'archiviazione tabelle di Azure partizione intrinsecamente tutto e non esiste quasi alcun limite per l'aggiunta di partizioni. È possibile ridimensionare in modo leggibile l'archiviazione tabelle fino a 200 terabyte, ma la dimensione massima del database per Azure SQL database è di 500 gigabyte. È possibile ridimensionare i dati relazionali partizionandoli in più database, ma configurando un'applicazione per supportare tale modello comporta un sacco di lavoro di programmazione. |
| Strumentazione e gestibilità | - Come è facile strumento, monitoraggio e gestione della piattaforma? Sarà necessario tenere informati sull'integrità e sulle prestazioni dell'archivio dati, quindi è necessario conoscere in anticipo le metriche che offre una piattaforma gratuitamente e ciò che è necessario sviluppare autonomamente. |
| Gestione operativa | - Come è facile distribuire ed eseguire la piattaforma in Azure? Paas? Iaas? Linux? Archiviazione tabelle e database SQL sono facili da configurare in Azure. Le piattaforme che non sono soluzioni PaaS predefinite richiedono maggiori sforzi. |
| Supporto dell'API | - È disponibile un'API che semplifica l'uso della piattaforma? Per il servizio tabelle di Azure è disponibile un SDK con un'API .NET che supporta il modello di programmazione asincrona .NET 4.5. Se si scrive un'app .NET, sarà molto più semplice scrivere e testare il codice per il servizio tabelle di Azure rispetto a un'altra piattaforma dell'archivio dati della colonna chiave/valore che non dispone di API o di una piattaforma meno completa. |
| Integrità transazionale e coerenza dei dati | - È fondamentale che la piattaforma supporti le transazioni per garantire la coerenza dei dati? Per tenere traccia dei messaggi di posta elettronica in blocco inviati, le prestazioni e i costi di archiviazione dei dati bassi potrebbero essere più importanti del supporto automatico per le transazioni o l'integrità referenziale nella piattaforma dati, rendendo il servizio tabelle di Azure una buona scelta. Per tenere traccia dei saldi del conto bancario o degli ordini di acquisto, una piattaforma di database relazionale che offre garanzie transazionali forti sarebbe una scelta migliore. |
| Continuità aziendale | - Come è facile eseguire il backup, il ripristino e il ripristino di emergenza? Prima o più tardi i dati di produzione verranno danneggiati e sarà necessaria una funzione di annullamento. I database relazionali hanno spesso funzionalità di ripristino con granularità più fine, ad esempio la possibilità di ripristinare in un momento. Informazioni sulle funzionalità di ripristino disponibili in ogni piattaforma che si sta valutando è un fattore importante da considerare. |
| Costi | - Se più piattaforme possono supportare il carico di lavoro dei dati, come confrontano i costi? Ad esempio, se si usa ASP.NET Identity, è possibile archiviare i dati del profilo utente nel servizio tabelle di Azure o nel database di Azure SQL. Se non sono necessarie le funzionalità di query avanzate di database SQL, è possibile scegliere Tabelle di Azure in parte perché costa molto meno per una determinata quantità di archiviazione. |
In genere è consigliabile conoscere la risposta alle domande in ognuna di queste categorie prima di scegliere le soluzioni di archiviazione dati.
Inoltre, il carico di lavoro potrebbe avere requisiti specifici che alcune piattaforme possono supportare meglio di altre. Ad esempio:
- L'applicazione richiede funzionalità di controllo?
- Quali sono i requisiti di longevità dei dati: è necessario automatizzare le funzionalità di archiviazione o eliminazione?
- Hai esigenze di sicurezza specializzate? Ad esempio, i dati includono informazioni personali (informazioni personali) ma è necessario essere in grado di assicurarsi che le informazioni personali siano escluse dai risultati delle query.
- Se si dispone di alcuni dati che non possono essere archiviati nel cloud per motivi normativi o tecnologici, potrebbe essere necessaria una piattaforma di archiviazione dati cloud che facilita l'integrazione con l'archiviazione locale.
Demo: uso di database SQL in Azure
L'app Correzione it usa un database relazionale per archiviare le attività. Lo script di creazione dell'ambiente Windows PowerShell illustrato nel capitolo Automatizzare tutto crea due istanze di database SQL. È possibile visualizzare questi elementi nel portale facendo clic sulla scheda Database SQL .
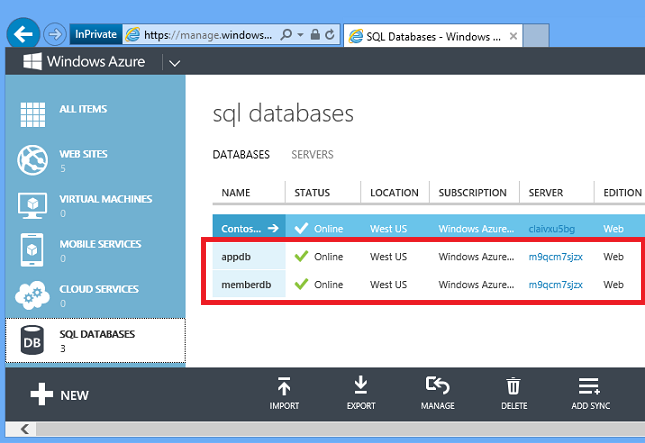
È anche facile creare database usando il portale.
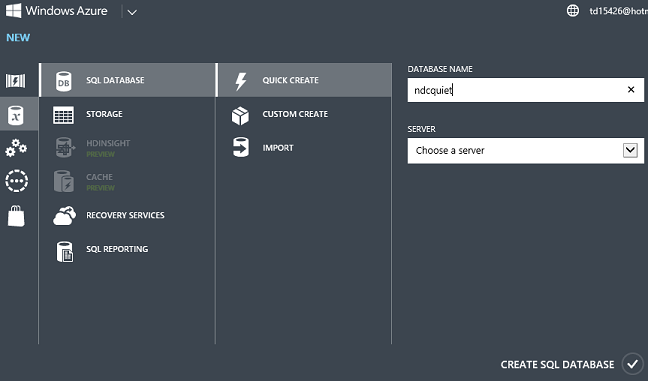
Fare clic su Nuovo - Servizi dati -- database SQL -- Quick Crea, immettere un nome di database, scegliere un server già presente nell'account o crearne uno nuovo e fare clic su Crea database SQL.
Attendere alcuni secondi e avere un database in Azure pronto per l'uso.
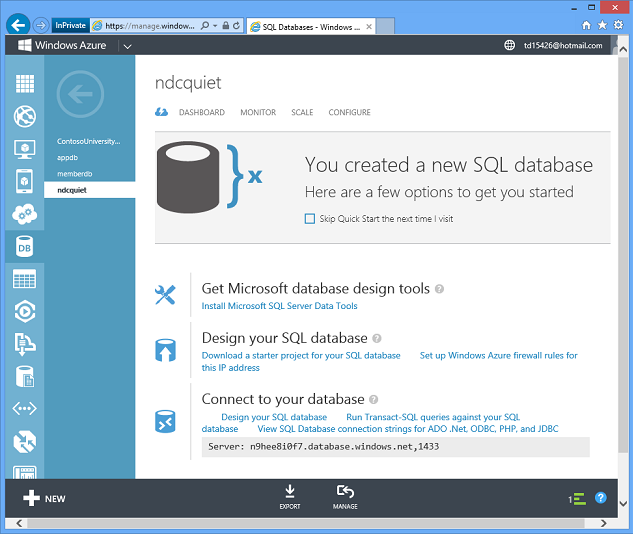
Azure esegue quindi in pochi secondi le operazioni che potrebbero richiedere un giorno o una settimana o più per l'esecuzione nell'ambiente locale. Inoltre, poiché è possibile creare automaticamente database in uno script o usando un'API di gestione, è possibile aumentare dinamicamente il numero di istanze distribuendo i dati tra più database, purché l'applicazione sia stata programmata per tale operazione.
Questo è un esempio del modello Platform-as-a-Service. Non è necessario gestire i server. Non è necessario preoccuparsi dei backup, lo facciamo. È in esecuzione a disponibilità elevata. I dati nel database vengono replicati automaticamente in tre server. Se un computer muore, viene eseguito automaticamente il failover e non si perde alcun dato. Il server viene patchato regolarmente, non è necessario preoccuparsi di questo.
Fare clic su un pulsante per ottenere la stringa di connessione esatta necessaria e iniziare immediatamente a usare il nuovo database.
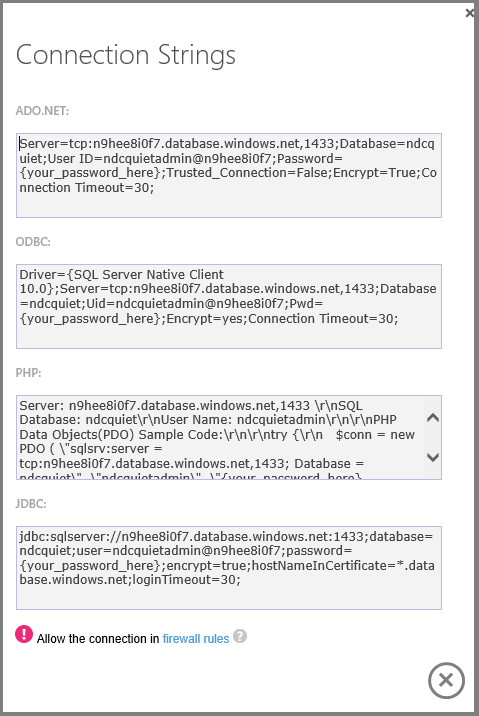
Il dashboard mostra la cronologia delle connessioni e la quantità di spazio di archiviazione usato.
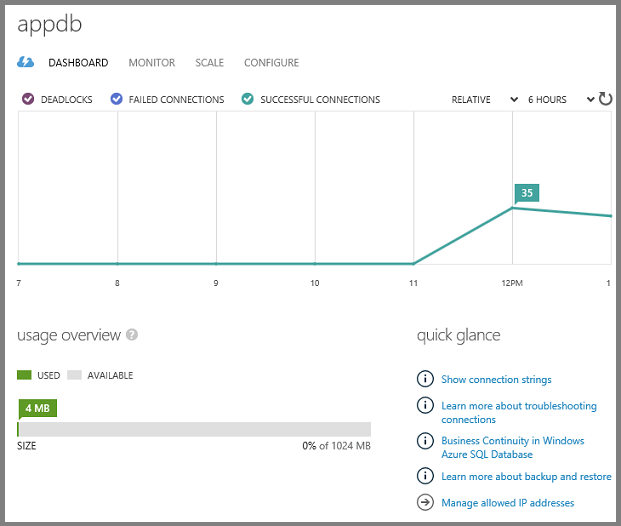
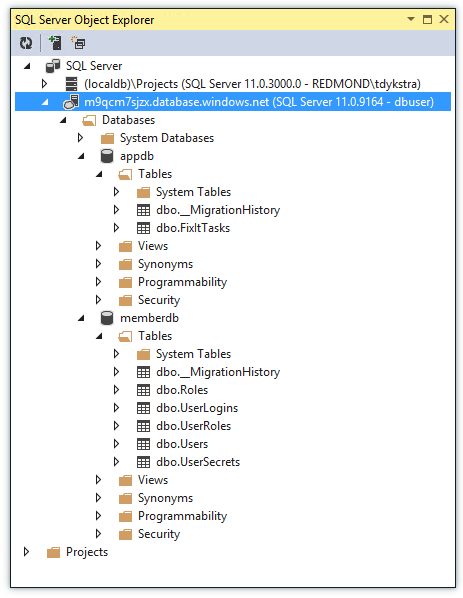
È possibile gestire i database nel portale o usando gli strumenti di SQL Server già noti, tra cui SQL Server Management Studio (SSMS) e gli strumenti di Visual Studio SQL Server Esplora oggetti (SSOX) e Esplora server.
Un altro aspetto interessante è il modello di determinazione prezzi. È possibile iniziare lo sviluppo con un database gratuito di 20 MB e un database di produzione inizia a circa $ 5 al mese. Si paga solo per la quantità di dati effettivamente archiviati nel database, non per la capacità massima. Non è necessario acquistare una licenza.
database SQL è facile da ridimensionare. Per l'app Fix It, il database creato nello script di automazione è limitato a 1 giga. Se si vuole aumentare le prestazioni fino a 150 giga, è sufficiente accedere al portale e modificare tale impostazione oppure eseguire un comando API REST e in pochi secondi si dispone di un database di 150 giga in cui è possibile distribuire i dati.
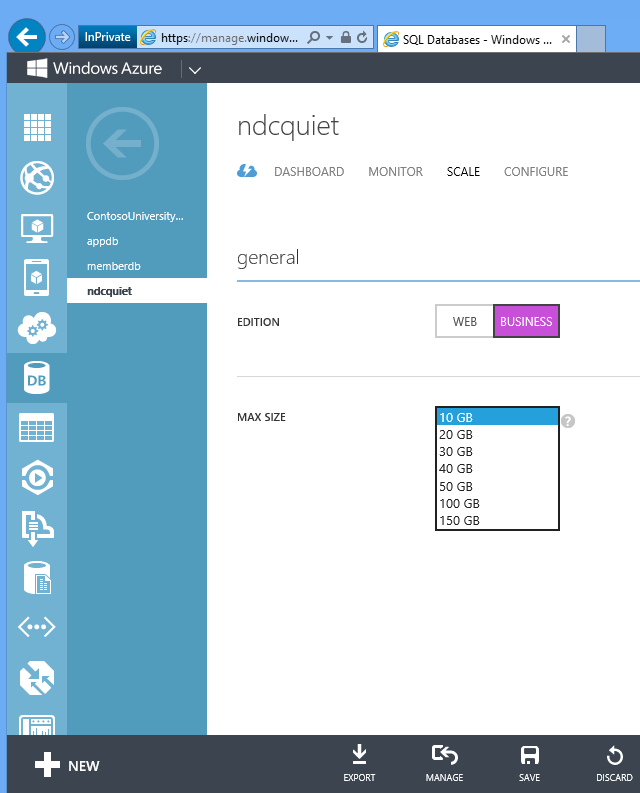
Questa è la potenza del cloud per mettere in piedi l'infrastruttura rapidamente e facilmente e iniziare subito a usarla.
L'app Fix It usa due database SQL, uno per l'appartenenza (autenticazione e autorizzazione) e uno per i dati e questo è tutto ciò che è necessario fare per eseguirne il provisioning e ridimensionarlo. Si è visto in precedenza come effettuare il provisioning dei database tramite script Windows PowerShell e ora si è visto anche quanto sia facile eseguire nel portale.
Entity Framework e accesso diretto al database tramite ADO.NET
L'app Fix It accede a questi database usando Entity Framework, orm consigliato da Microsoft (mapper relazionale a oggetti) per le applicazioni .NET. Un ORM è un ottimo strumento che facilita la produttività degli sviluppatori, ma la produttività è a scapito delle prestazioni ridotte in alcuni scenari. In un'app cloud reale non si farà una scelta tra l'uso di Entity Framework o l'uso diretto di ADO.NET. Si useranno entrambi. Nella maggior parte dei casi, quando si scrive codice che funziona con il database, ottenere prestazioni massime non è critico ed è possibile sfruttare la codifica e i test semplificati che si ottengono con Entity Framework. In situazioni in cui il sovraccarico di Entity Framework causa prestazioni inaccettabili, è possibile scrivere ed eseguire query personalizzate usando ADO.NET, idealmente chiamando stored procedure.
Qualsiasi metodo usato per accedere al database, si vuole ridurre al minimo la "chattiness" il più possibile. In altre parole, se è possibile ottenere tutti i dati necessari in un set di risultati di query più grande anziché decine o centinaia di più piccoli, è preferibile in genere. Ad esempio, se è necessario elencare gli studenti e i corsi a cui sono iscritti, in genere è preferibile ottenere tutti i dati in una query di join anziché ottenere gli studenti in una query ed eseguire query separate per i corsi di ogni studente.
Database SQL e Entity Framework nell'app Fix It
Nell'app Fix It la FixItContext classe , che deriva dalla classe Entity Framework DbContext , identifica il database e specifica le tabelle nel database. Il contesto specifica un set di entità (tabella) per le attività e il codice passa al contesto il nome della stringa di connessione. Tale nome fa riferimento a una stringa di connessione definita nel file Web.config.
public class MyFixItContext : DbContext
{
public MyFixItContext()
: base("name=appdb")
{
}
public DbSet<MyFixIt.Persistence.FixItTask> FixItTasks { get; set; }
}
La stringa di connessione nel file Web.config è denominata appdb (in questo caso punta al database di sviluppo locale):
<connectionStrings>
<add name="DefaultConnection" connectionString="Data Source=(LocalDb)\v11.0;Initial Catalog=aspnet-MyFixIt-20130604091232_4;Integrated Security=True" providerName="System.Data.SqlClient" />
<add name="appdb" connectionString="Data Source=(localdb)\v11.0; Initial Catalog=MyFixItContext-20130604091609_11;Integrated Security=True; MultipleActiveResultSets=True" providerName="System.Data.SqlClient" />
</connectionStrings>
Entity Framework crea una tabella FixItTasks in base alle proprietà incluse nella classe di FixItTask entità. Si tratta di una semplice classe POCO (Plain Old CLR Object), che significa che non eredita da o ha dipendenze da Entity Framework. Entity Framework è tuttavia in grado di creare una tabella basata su di essa ed eseguire operazioni CRUD (create-read-update-delete) con esso.
public class FixItTask
{
public int FixItTaskId { get; set; }
public string CreatedBy { get; set; }
[Required]
public string Owner { get; set; }
[Required]
public string Title { get; set; }
public string Notes { get; set; }
public string PhotoUrl { get; set; }
public bool IsDone { get; set; }
}
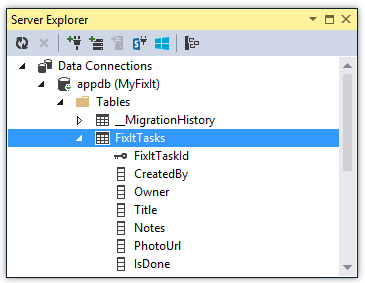
L'app Fix It include un'interfaccia del repository usata per le operazioni CRUD che usano l'archivio dati.
public interface IFixItTaskRepository
{
Task<List<FixItTask>> FindOpenTasksByOwnerAsync(string userName);
Task<List<FixItTask>> FindTasksByCreatorAsync(string userName);
Task<MyFixIt.Persistence.FixItTask> FindTaskByIdAsync(int id);
Task CreateAsync(FixItTask taskToAdd);
Task UpdateAsync(FixItTask taskToSave);
Task DeleteAsync(int id);
}
Si noti che i metodi del repository sono tutti asincroni, in modo che tutti gli accessi ai dati possano essere eseguiti in modo completamente asincrono.
L'implementazione del repository chiama i metodi asincroni di Entity Framework per lavorare con i dati, incluse le query LINQ e per le operazioni di inserimento, aggiornamento ed eliminazione. Di seguito è riportato un esempio di codice per la ricerca di un'attività Correggi.
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
try
{
fixItTask = await db.FixItTasks.FindAsync(id);
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed, "id={0}", id);
}
catch(Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
Si noterà anche un po' di temporizzazione e codice di registrazione degli errori, che verrà esaminato più avanti nel capitolo Monitoraggio e telemetria.
Scelta di database SQL (PaaS) e SQL Server in una macchina virtuale (IaaS) in Azure
Un aspetto interessante di SQL Server e database Azure SQL è che il modello di programmazione principale per entrambi è identico. È possibile usare la maggior parte delle stesse competenze in entrambi gli ambienti. È anche possibile usare un database SQL Server in fase di sviluppo e un'istanza di database SQL nel cloud, che è il modo in cui è configurata l'app Fix It.
In alternativa, è possibile eseguire lo stesso SQL Server nel cloud eseguito in locale installandolo nelle macchine virtuali IaaS. Per alcune applicazioni legacy, l'esecuzione di SQL Server in una macchina virtuale potrebbe essere una soluzione migliore. Poiché un database SQL Server viene eseguito in una macchina virtuale dedicata, dispone di più risorse disponibili rispetto a un database database SQL eseguito in un server condiviso. Ciò significa che un database SQL Server può essere più grande e continuare a funzionare correttamente. In generale, le dimensioni e le dimensioni della tabella del database sono inferiori, migliore è il caso d'uso per database SQL (PaaS).
Ecco alcune linee guida su come scegliere tra i due modelli.
| Database SQL di Azure (PaaS) | SQL Server in una macchina virtuale (IaaS) |
|---|---|
| Professionisti : non è necessario creare o gestire macchine virtuali, aggiornare o applicare patch al sistema operativo o a SQL; Azure esegue questa operazione per l'utente. - Disponibilità elevata predefinita, con un contratto di servizio a livello di database. - Costo totale di proprietà (TCO) basso perché si paga solo per ciò che si usa (nessuna licenza richiesta). - Valido per la gestione di un numero elevato di database più piccoli (<=500 GB ciascuno). - Creare in modo dinamico nuovi database per abilitare la scalabilità orizzontale. | Vantaggi: compatibile con le funzionalità con le SQL Server locali. - Può implementare SQL Server disponibilità elevata tramite AlwaysOn in 2 macchine virtuali con contratto di servizio a livello di macchina virtuale. - Si ha il controllo completo sulla modalità di gestione di SQL. - Può riutilizzare le licenze SQL di cui si è già proprietari o pagare per un'ora. - Soluzione valida per la gestione di database di dimensioni minori ma maggiori (1 TB+). |
| Contro - Alcune lacune delle funzionalità rispetto alle SQL Server locali (mancanza di integrazione CLR, TDE, supporto della compressione, SQL Server Reporting Services e così via) - Limite di dimensioni del database di 500 GB. | Contro: Aggiornamenti/patch (sistema operativo e SQL) sono responsabilità dell'utente: la creazione e la gestione dei database sono responsabilità dell'utente: operazioni di I/O al secondo del disco (operazioni di input/output al secondo) limitate a circa 8000 (tramite 16 unità dati). |
Se si vuole usare SQL Server in una macchina virtuale, è possibile usare la propria licenza di SQL Server oppure pagare una per ora. Ad esempio, nel portale o tramite l'API REST è possibile creare una nuova macchina virtuale usando un'immagine SQL Server.
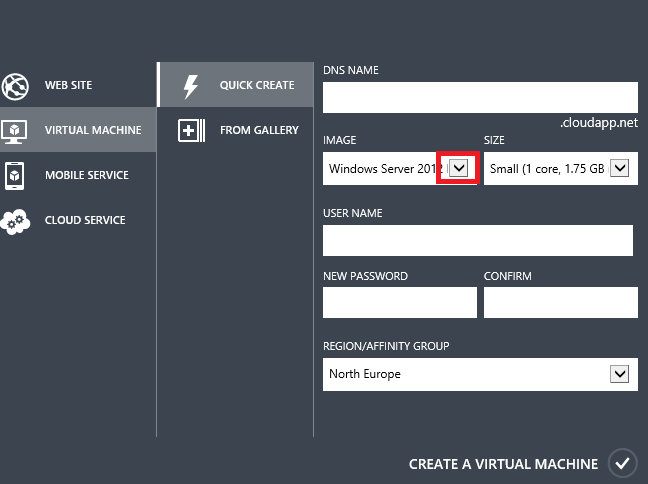

Quando si crea una macchina virtuale con un'immagine SQL Server, il costo della licenza SQL Server viene valutata in base all'ora in base all'utilizzo della macchina virtuale. Se hai un progetto che verrà eseguito solo per un paio di mesi, è più economico pagare per ora. Se pensi che il tuo progetto durerà per anni, è più economico acquistare la licenza come normalmente fai.
Riepilogo
Il cloud computing consente di combinare e abbinare gli approcci di archiviazione dei dati in base alle esigenze dell'applicazione. Se si sta creando una nuova applicazione, considerare attentamente le domande elencate qui per scegliere approcci che continueranno a funzionare correttamente quando l'applicazione cresce. Il capitolo successivo illustra alcune strategie di partizionamento che è possibile usare per combinare più approcci di archiviazione dei dati.
Risorse
Per ulteriori informazioni, vedere le risorse seguenti.
Scelta di una piattaforma di database:
- Accesso ai dati per soluzioni Highly-Scalable: uso di SQL, NoSQL e persistenza polyglot. E-book di Microsoft Patterns and Practices che illustra in modo approfondito i diversi tipi di archivi dati disponibili per le applicazioni cloud.
- Modelli e procedure Microsoft - Linee guida di Azure. Vedere Informazioni di base sulla coerenza dei dati, replica dei dati e linee guida per la sincronizzazione, modello di tabella degli indici, modello vista materializzata.
- BASE: alternativa acida. Articolo sui compromessi tra coerenza dei dati e scalabilità.
- Sette database in sette settimane: guida ai database moderni e allo spostamento NoSQL. Libro di Eric Redmond e Jim R. Wilson. Altamente consigliato per presentarsi alla gamma di piattaforme di archiviazione dei dati attualmente disponibili.
Scelta tra SQL Server e database SQL:
- Anteprima Premium per linee guida per database SQL. Introduzione a database SQL Premium e indicazioni su quando sceglierla rispetto alle edizioni Web e Business di database SQL.
- Linee guida e limitazioni (Azure SQL database). Pagina del portale che collega alla documentazione sulle limitazioni di database SQL, inclusa una delle funzionalità SQL Server che database SQL non supporta.
- SQL Server in Azure Macchine virtuali. Pagina del portale che collega alla documentazione relativa all'esecuzione di SQL Server in Azure.
- Scott Guthrie illustra i database SQL in Azure. Introduzione al video di 6 minuti per database SQL di Scott Guthrie.
- Modelli di applicazione e strategie di sviluppo per SQL Server in Azure Macchine virtuali.
Uso di Entity Framework e database SQL in un'app Web ASP.NET
- Introduzione con EF 6 usando MVC 5. Serie di esercitazioni in nove parti che illustrano come creare un'app MVC che usa Entity Framework e distribuisce il database in Azure e database SQL.
- ASP.NET distribuzione Web con Visual Studio. Serie di esercitazioni in dodici parti che illustrano in modo più approfondito come distribuire un database usando Entity Framework Code First.
- Distribuire un'app Secure ASP.NET MVC 5 con appartenenza, OAuth e database SQL in un sito Web di Azure. Esercitazione dettagliata che illustra come creare un'app Web che usa l'autenticazione, archivia le tabelle delle applicazioni nel database di appartenenza, modifica lo schema del database e distribuisce l'app in Azure.
- ASP.NET mappa del contenuto di accesso ai dati. Collegamenti alle risorse per l'uso di Entity Framework e database SQL.
Uso di MongoDB in Azure:
- MongoDB Atlas in Azure. Pagina del portale per la documentazione sull'esecuzione di MongoDB Atlas in Azure.
- Creare un sito Web di Azure che si connette a MongoDB in esecuzione in una macchina virtuale in Azure. Esercitazione dettagliata che illustra come usare un database MongoDB in un'applicazione Web ASP.NET.
HDInsight (Hadoop in Azure):
- HDInsight. Documentazione del portale per HDInsight nel sito Web di Azure .
- Hadoop e HDInsight: Big Data in Azure. Articolo di MSDN Magazine di Bruno Terkaly e Ricardo Villalobos, che presenta Hadoop in Azure.
- Modelli e procedure Microsoft - Linee guida di Azure. Vedere Modello MapReduce.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per