Esercitazione: usare Funzioni di Azure e Python per elaborare i documenti archiviati
L'intelligence sui documenti può essere usata come parte di una pipeline di elaborazione dati automatizzata creata con Funzioni di Azure. Questa guida illustra come usare Funzioni di Azure per elaborare documenti caricati in un contenitore di Archiviazione BLOB di Azure. Questo flusso di lavoro estrae i dati della tabella dai documenti archiviati usando il modello di layout di Document Intelligence e salva i dati della tabella in un file .csv in Azure. È quindi possibile visualizzare i dati usando Microsoft Power BI (procedura non trattata in questo articolo).

In questa esercitazione apprenderai a:
- Creare un account di archiviazione di Azure.
- Creare un progetto di Funzioni di Azure.
- Estrarre i dati del layout dai moduli caricati.
- Caricare i dati del layout estratti in Archiviazione di Azure.
Prerequisiti
Sottoscrizione di Azure - Creare un account gratuito
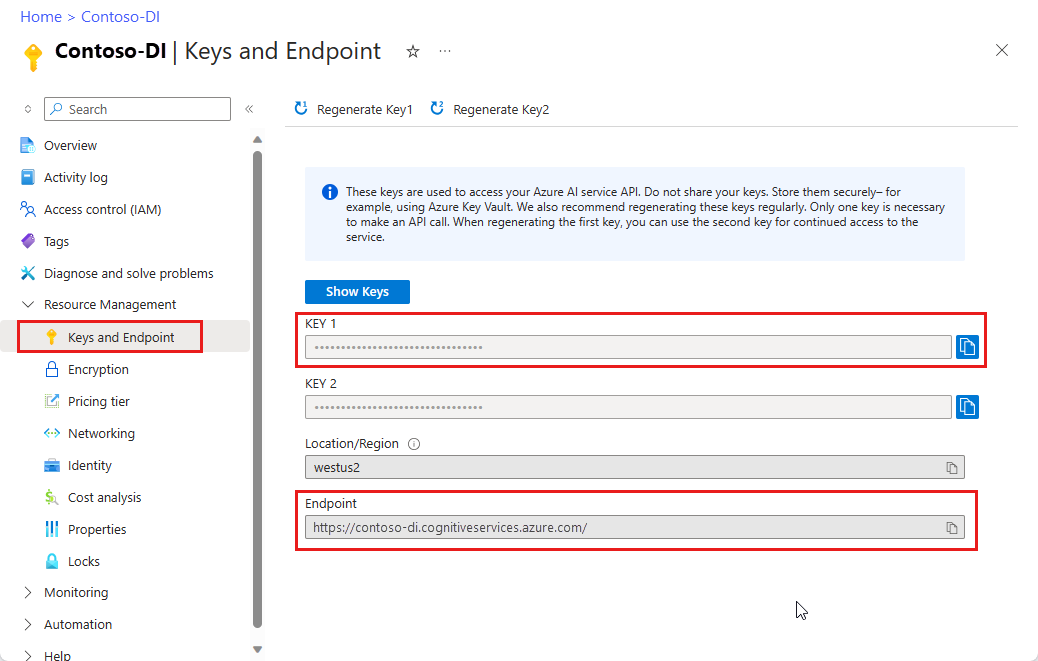
Una risorsa di Document Intelligence. Dopo aver creato la sottoscrizione di Azure, creare una risorsa di Document Intelligence nel portale di Azure per ottenere la chiave e l'endpoint. È possibile usare il piano tariffario gratuito (
F0) per provare il servizio ed eseguire in un secondo momento l'aggiornamento a un livello a pagamento per la produzione.Dopo la distribuzione della risorsa selezionare Vai alla risorsa. È necessaria la chiave e l'endpoint dalla risorsa creata per connettere l'applicazione all'API di Intelligence documenti. La chiave e l'endpoint verranno incollati nel codice seguente più avanti nell'esercitazione:
Python 3.6.x, 3.7.x, 3.8.x o 3.9.x (Python 3.10.x non è supportato per questo progetto).
La versione più recente di Visual Studio Code (VS Code) con le estensioni seguenti installate:
Estensione Funzioni di Azure. Dopo l'installazione, il logo di Azure verrà visualizzato nel riquadro di spostamento a sinistra.
Azure Functions Core Tools versione 3.x (la versione 4.x non è supportata per questo progetto).
Estensione Python per Visual Studio Code. Per altre informazioni, vedereIntroduzione a Python in Visual Studio Code
Azure Storage Explorer installato.
Un documento PDF locale da analizzare. È possibile usare il documento PDF di esempio per questo progetto.
Creare un account di Archiviazione di Azure
Creare un account di archiviazione di Azure per utilizzo generico v2 nel portale di Azure. Se non si sa come creare un account di archiviazione di Azure con un contenitore di archiviazione, seguire queste guide di avvio rapido:
- Creare un account di archiviazione. Durante la creazione dell'account di archiviazione, selezionare Standard nel campo Dettagli istanza>Prestazioni.
- Creare un contenitore. Quando si crea il contenitore, impostare Livello di accesso pubblico su Contenitore (accesso in lettura anonimo per contenitori e file) nella finestra Nuovo contenitore.
Nel riquadro di sinistra selezionare la scheda Condivisione risorse (CORS) e rimuovere i criteri CORS esistenti, se presenti.
Dopo aver distribuito l'account di archiviazione, creare due contenitori di Archiviazione BLOB vuoti denominati input e output.
Creare un progetto di Funzioni di Azure
Creare una nuova cartella denominata functions-app che conterrà il progetto e scegliere Seleziona.
Aprire Visual Studio Code e aprire il riquadro comandi (CTRL+MAIUSC+P). Cercare e scegliere Python: seleziona interprete → scegliere un interprete Python installato con la versione 3.6.x, 3.7.x, 3.8.x o 3.9.x. Con questa selezione il percorso dell'interprete Python selezionato verrà aggiunto al progetto.
Selezionare il logo di Azure nel riquadro di spostamento a sinistra.
Le risorse di Azure esistenti verranno elencate nella visualizzazione Risorse.
Selezionare la sottoscrizione di Azure usata per questo progetto e in basso dovrebbe essere visualizzata l'app Funzioni di Azure.

Selezionare la sezione Area di lavoro (locale) sotto le risorse elencate. Selezionare il simbolo più e scegliere il pulsante Crea funzione.

Quando richiesto, scegliere Crea nuovo progetto e passare alla directory function-app. Scegli Seleziona.
Verrà richiesto di configurare diverse impostazioni:
Selezionare un linguaggio → scegliere Python.
Selezionare un interprete Python per creare un ambiente virtuale → selezionare l'interprete impostato come predefinito in precedenza.
Selezionare un modello → scegliere il trigger di Archiviazione BLOB di Azure e assegnare al trigger un nome o accettare quello predefinito. Premere INVIO per confermare.
Selezionare l'impostazione → scegliere ➕Creare nuova impostazione dell'app locale dal menu a discesa.
Selezionare la sottoscrizione → scegliere la sottoscrizione di Azure con l'account di archiviazione creato → selezionare l'account di archiviazione → quindi selezionare il nome del contenitore di input dell'archiviazione (in questo caso
input/{name}). Premere INVIO per confermare.Selezionare la modalità di apertura del progetto → scegliere Apri il progetto nella finestra corrente dal menu a discesa.
Dopo aver completato questi passaggi, VS Code aggiungerà un nuovo progetto Funzione di Azure con uno script Python __init__.py. Questo script verrà attivato ogni volta che si carica un file nel contenitore di archiviazione input:
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
Testare la funzione
Premere F5 per eseguire la funzione di base. VS Code chiederà di selezionare un account di archiviazione con cui interfacciarsi.
Selezionare l'account di archiviazione creato e continuare.
Aprire Azure Storage Explorer e caricare il documento PDF di esempio nel contenitore input. Controllare quindi il terminale di VS Code. Nel log deve essere indicato che lo script è stato attivato dal caricamento del PDF.

Arrestare lo script prima di continuare.
Aggiungere il codice per l'elaborazione dei documenti
Successivamente, si aggiungerà il proprio codice allo script Python per chiamare il servizio Document Intelligence e analizzare i documenti caricati usando il modello di layout di Document Intelligence.
In VS Code passare al file requirements.txt della funzione. Questo file definisce le dipendenze per lo script. Aggiungere i pacchetti Python seguenti al file:
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpyAprire quindi lo script __init__.py. Aggiungere le istruzioni
importseguenti:import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pdÈ possibile lasciare invariata la funzione
maingenerata. Il codice personalizzato verrà aggiunto all'interno di questa funzione.# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")Il blocco di codice seguente chiama l'API Analisi layout di Document Intelligence nel documento caricato. Immettere i valori di endpoint e chiave.
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)Importante
Al termine, ricordarsi di rimuovere la chiave dal codice e non renderlo mai pubblico. Per la produzione, utilizzare un modo sicuro per archiviare e accedere alle credenziali, ad esempio Azure Key Vault. Per altre informazioni, vederel'articolo sulla sicurezza di Servizi di Azure AI.
Aggiungere quindi il codice per eseguire una query sul servizio e ottenere i dati restituiti.
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_jsonAggiungere il codice seguente per connettersi al contenitore output di Archiviazione di Azure. Immettere i valori personalizzati per il nome e la chiave dell'account di archiviazione. È possibile ottenere la chiave nella scheda Chiavi di accesso della risorsa di archiviazione nel portale di Azure.
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")Il codice seguente analizza la risposta restituita di Document Intelligence, costruisce un file .csv e lo carica nel contenitore di output .
Importante
È probabile che sia necessario modificare questo codice in modo che corrisponda alla struttura dei propri documenti.
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1Infine, l'ultimo blocco di codice carica la tabella estratta e i dati di testo nell'elemento di Archiviazione BLOB.
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
Eseguire la funzione
Premere F5 per eseguire nuovamente la funzione.
Usare Azure Storage Explorer per caricare un modulo PDF di esempio nel contenitore di archiviazione input. Questa azione dovrebbe attivare l'esecuzione dello script e dovrebbe visualizzare il file CSV risultante (visualizzato come tabella) nel contenitore output.
È possibile connettere questo contenitore a Power BI per creare visualizzazioni avanzate dei dati in esso presenti.
Passaggi successivi
In questa esercitazione si è appreso come usare una funzione di Azure scritta in Python per elaborare automaticamente i documenti PDF caricati e restituirne il contenuto in un formato più descrittivo per i dati. In seguito verrà illustrato come usare Power BI per visualizzare i dati.
- Che cos'è l'intelligence sui documenti?
- Altre informazioni sul modello di layout