Questo articolo descrive un approccio alternativo ai progetti di data warehouse denominato analisi esplorativa dei dati. Questo approccio consente di ridurre le problematiche associate alle operazioni di estrazione, trasformazione e caricamento (ETL). Si concentra prima sulla generazione di dati analitici aziendali e quindi passa alla risoluzione delle attività di modellazione ed ETL.
Architettura

Scaricare un file di Visio di questa architettura.
Per l'analisi esplorativa dei dati è necessario concentrarsi solo sul lato destro del diagramma. Azure Synapse SQL serverless viene usato come motore di calcolo sui file di data lake.
Per eseguire l'analisi esplorativa dei dati:
- Le query T-SQL vengono eseguite direttamente in Azure Synapse SQL serverless o in Azure Synapse Spark.
- Le query vengono eseguite da uno strumento grafico di esecuzione query come Power BI o Azure Data Studio.
È consigliabile rendere persistenti tutti i dati del lakehouse con Parquet o Delta.
È possibile implementare il lato sinistro del diagramma (inserimento dati) usando qualsiasi strumento di estrazione, caricamento e trasformazione (ELT). Non ha effetto sull'analisi esplorativa dei dati.
Componenti
Azure Synapse Analytics combina integrazione dei dati, data warehousing aziendale e analisi dei Big Data su dati di lakehouse. In questa soluzione:
- Un'area di lavoro Azure Synapse promuove la collaborazione tra ingegneri dei dati, scienziati dei dati, analisti dei dati e professionisti della business intelligence (BI) per le attività di analisi esplorativa dei dati.
- I pool SQL serverless di Azure Synapse analizzano i dati non strutturati e semistrutturati in Azure Data Lake Storage usando T-SQL standard.
- I pool Apache Spark serverless di Azure Synapse eseguono esplorazioni code-first in Data Lake Storage usando linguaggi Spark come Spark SQL, PySpark e Scala.
Azure Data Lake Archiviazione fornisce spazio di archiviazione per i dati che vengono quindi analizzati dai pool SQL serverless di Azure Synapse.
Azure Machine Learning fornisce i dati ad Azure Synapse Spark.
In questa soluzione viene usato Power BI per eseguire query sui dati e quindi l'analisi esplorativa dei dati.
Alternative
È possibile sostituire o integrare i pool serverless Synapse SQL con Azure Databricks.
Invece di usare un modello lakehouse con pool serverless Synapse SQL, è possibile usare pool SQL dedicati di Azure Synapse per archiviare i dati aziendali. Esaminare i casi d'uso e le considerazioni riportate in questo articolo, nonché le risorse correlate, per decidere quale tecnologia usare.
Dettagli dello scenario
Questa soluzione illustra un'implementazione dell'approccio EDA ai progetti di data warehouse. Questo approccio può ridurre le sfide delle operazioni ETL. Si concentra innanzitutto sulla generazione di informazioni dettagliate aziendali e quindi sulla risoluzione di attività di modellazione ed ETL.
Potenziali casi d'uso
Altri scenari che possono trarre vantaggio da questo modello di analisi includono:
Analisi prescrittiva. Ottenere risposte dai dati, ad esempio Qual è l'azione migliore o Come procedere?. Usare i dati per essere più guidati dai dati e meno guidati dall'istinto. I dati potrebbero essere non strutturati e provenire da numerose origini esterne di qualità variabile. È opportuno usare i dati il più rapidamente possibile per valutare la strategia aziendale senza caricare effettivamente i dati in un data warehouse. È possibile eliminare i dati dopo aver risposto alle domande.
ETL self-service. Eseguire ETL/ELT quando si eseguono attività di sandboxing dei dati (analisi esplorativa dei dati). Trasformare i dati e renderli importanti. In questo modo è possibile migliorare la scalabilità degli sviluppatori ETL.
Informazioni sull'analisi esplorativa dei dati
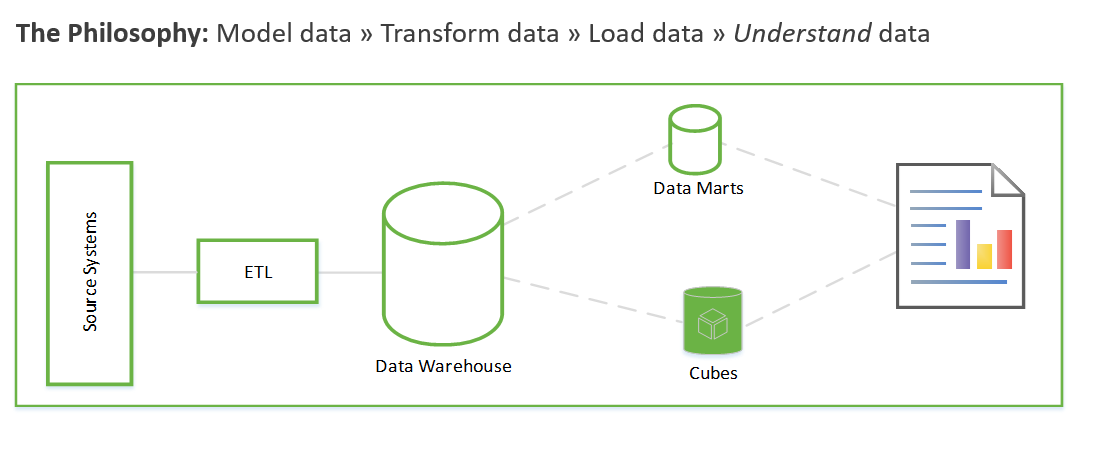
Prima di esaminare più da vicino il funzionamento dell'analisi esplorativa dei dati, è opportuno riepilogare l'approccio tradizionale ai progetti di data warehouse. L'approccio tradizionale è simile al seguente:
Raccolta dei requisiti. Documentare le operazioni da eseguire con i dati.
Modellazione dei dati. Determinare come modellare i dati numerici e degli attributi in tabelle dei fatti e delle dimensioni. In genere, questo passaggio viene eseguito prima dell'acquisizione di nuovi dati.
ETL. Acquisire i dati e passarli nel modello di dati del data warehouse.
Questi passaggi possono richiedere settimane o persino mesi. Solo a questo punto è possibile iniziare a eseguire query sui dati e risolvere il problema aziendale. Il valore per l'utente risulta evidente solo dopo la creazione dei report. L'architettura della soluzione è in genere simile alla seguente:
È possibile eseguire questa operazione in un altro modo che si concentra prima sulla generazione di dati analitici aziendali e quindi passa alla risoluzione delle attività di modellazione ed ETL. Il processo è simile a quelli di data science. Verrà visualizzata una schermata simile alla seguente:
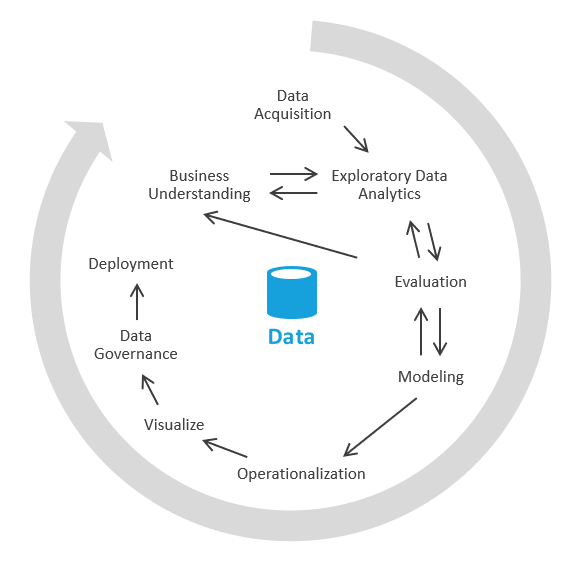
Nel settore questo processo è detto EDA o analisi esplorativa dei dati.
Di seguito sono riportati i passaggi necessari:
Acquisizione dei dati. In primo luogo, è necessario determinare le origini dati da inserire nel data lake o nella sandbox. È quindi necessario spostare i dati nell'area di destinazione del lake. In Azure sono disponibili strumenti come Azure Data Factory e App per la logica di Azure che consentono di inserire rapidamente i dati.
Sandboxing dei dati. Inizialmente a collaborare sono un business analyst e un ingegnere esperto in analisi esplorativa dei dati tramite Azure Synapse Analytics serverless o SQL di base. In questa fase provano a scoprire dati analitici aziendali usando i nuovi dati. L'analisi esplorativa dei dati è un processo iterativo. Potrebbe essere necessario inserire più dati, parlare con esperti di dominio, porre altre domande o generare visualizzazioni.
Valutazione. Dopo aver trovato i dati analitici aziendali è necessario valutare quali operazioni eseguire con i dati. Può essere opportuno rendere persistenti i dati nel data warehouse in modo da passare alla fase di modellazione. In altri casi si può decidere di mantenere i dati nel data lake/lakehouse e usarli per l'analisi predittiva (algoritmi di apprendimento automatico). In altri casi ancora è possibile decidere di arricchire i sistemi di archiviazione con i nuovi dati analitici. In base a queste decisioni, è possibile comprendere meglio le operazioni da eseguire in seguito. Potrebbe non essere necessario eseguire le operazioni di estrazione, trasformazione e caricamento (ETL).
Questi metodi costituiscono le basi della vera analisi self-service. Usando il data lake e uno strumento di query come Azure Synapse serverless che riconosce i modelli di query data lake, è possibile mettere gli asset di dati a disposizione delle figure aziendali che conoscono un minimo il linguaggio SQL. Questo metodo consente di ridurre drasticamente il time-to-value e di rimuovere alcuni dei rischi associati alle iniziative per i dati aziendali.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Disponibilità
I pool serverless Azure Synapse SQL sono una funzionalità PaaS (Platform as a Service) in grado di soddisfare i requisiti di disponibilità elevata e ripristino di emergenza.
I pool serverless sono disponibili su richiesta. Non richiedono l'aumento o la riduzione di risorse o istanze né operazioni di amministrazione di alcun tipo. Usano un modello di pagamento in base alle query, di conseguenza non prevedono capacità inutilizzata in qualsiasi momento. I pool serverless sono ideali per:
- Esplorazioni di data science ad hoc in T-SQL.
- Prototipazione anticipata per entità di data warehouse.
- Definizione di viste che gli utenti possono usare, ad esempio in Power BI, per scenari in grado di tollerare un ritardo delle prestazioni.
- Analisi esplorativa dei dati.
Operazioni
Synapse SQL serverless usa T-SQL standard per l'esecuzione di query e le operazioni. Come strumento T-SQL è possibile usare l'interfaccia utente dell'area di lavoro Synapse, Azure Data Studio o SQL Server Management Studio.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda l'analisi dei modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
I prezzi di Data Lake Storage dipendono dalla quantità di dati archiviati e dalla frequenza di utilizzo dei dati. I prezzi di esempio includono un terabyte di dati archiviati, con ulteriori presupposti transazionali. Il terabyte si riferisce alle dimensioni del data lake e non a quelle del database legacy originale.
I prezzi del pool di Spark di Azure Synapse si basano sulle dimensioni dei nodi, sul numero di istanze e sul tempo di attività. L'esempio presuppone un nodo di calcolo di piccole dimensioni con un utilizzo compreso tra cinque ore alla settimana e 40 ore al mese.
I prezzi del pool SQL serverless di Azure Synapse si basano sui terabyte di dati elaborati. Nell'esempio si presuppone che vengano elaborati 50 TB al mese. Questa cifra si riferisce alle dimensioni del data lake e non a quelle del database legacy originale.
Collaboratori
Questo articolo viene aggiornato e gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Dave Wentzel | Principal MTC Technical Architect
Passaggi successivi
- Ingegnere dei dati percorsi di apprendimento
- Esercitazione: Introduzione ad Azure Synapse Analytics
- Creare un database singolo - Database SQL di Azure
- Architettura di Azure Synapse SQL
- Creare un account di archiviazione per Azure Data Lake Storage
- Avvio rapido di Hub eventi di Azure: Creare un hub eventi con il portale di Azure
- Guida introduttiva: Creare un processo di Analisi di flusso usando il portale di Azure
- Avvio rapido: Iniziare a usare il servizio Azure Machine Learning