Questo articolo descrive come un team di sviluppo ha usato le metriche per trovare colli di bottiglia e migliorare le prestazioni di un sistema distribuito. L'articolo si basa sui test di carico effettivi caricati per un'applicazione di esempio. L'applicazione proviene dalla baseline servizio Azure Kubernetes (AKS) per i microservizi, insieme a un progetto di test di carico di Visual Studio usato per generare i risultati.
Questo articolo fa parte di una serie. Leggere la prima parte qui.
Scenario: chiamare più servizi back-end per recuperare informazioni e quindi aggregare i risultati.
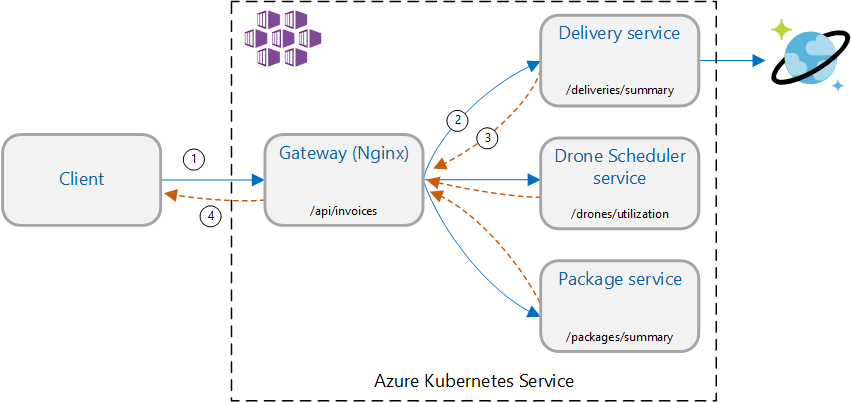
Questo scenario implica un'applicazione per la distribuzione di droni. I client possono eseguire query su un'API REST per ottenere le informazioni sulla fattura più recenti. La fattura include un riepilogo delle consegne, dei pacchetti e dell'utilizzo totale del drone del cliente. Questa applicazione usa un'architettura di microservizi in esecuzione nel servizio Azure Kubernetes e le informazioni necessarie per la fattura vengono distribuite in diversi microservizi.
Anziché il client che chiama direttamente ogni servizio, l'applicazione implementa il modello di aggregazione gateway . Usando questo modello, il client effettua una singola richiesta a un servizio gateway. Il gateway a sua volta chiama i servizi back-end in parallelo e quindi aggrega i risultati in un singolo payload di risposta.
Test 1: Prestazioni di base
Per stabilire una linea di base, il team di sviluppo ha iniziato con un test di carico passo-passo, rampando il carico da un utente simulato fino a 40 utenti, per una durata totale di 8 minuti. Il grafico seguente, tratto da Visual Studio, mostra i risultati. La riga viola mostra il carico utente e la riga arancione mostra la velocità effettiva (richieste medie al secondo).
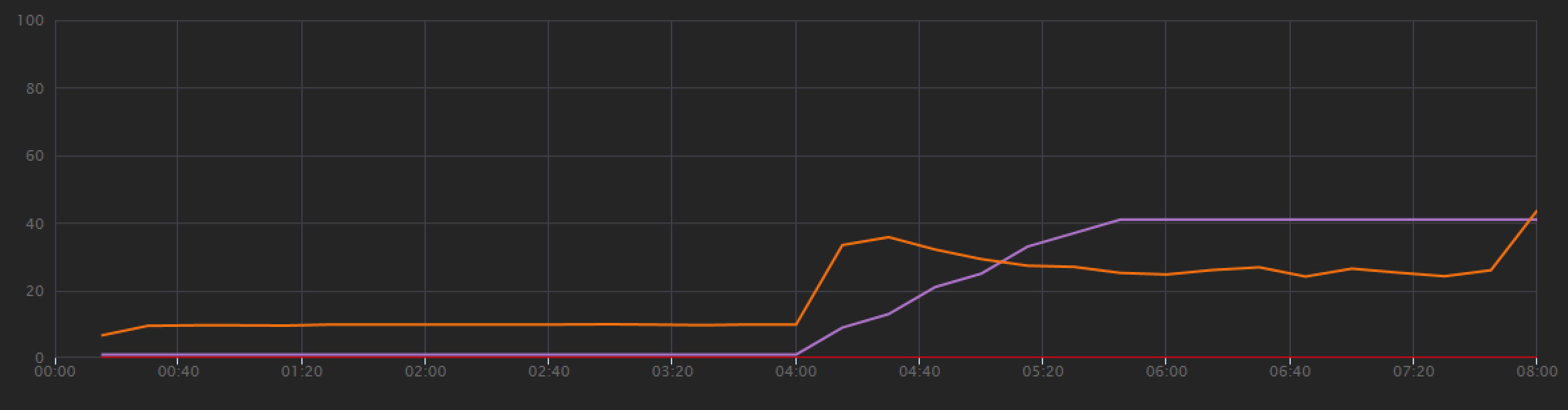
La linea rossa lungo la parte inferiore del grafico mostra che non sono stati restituiti errori al client, che è incoraggiante. Tuttavia, il picco medio della velocità effettiva circa metà attraverso il test e quindi scende per il resto, anche mentre il carico continua ad aumentare. Ciò indica che il back-end non è in grado di mantenere. Il modello illustrato qui è comune quando un sistema inizia a raggiungere i limiti delle risorse, dopo aver raggiunto un massimo, la velocità effettiva in realtà scende significativamente. La contesa delle risorse, gli errori temporanei o un aumento della frequenza di eccezioni può contribuire a questo modello.
Esaminiamo i dati di monitoraggio per scoprire cosa accade all'interno del sistema. Il grafico successivo viene tratto da Application Insights. Mostra le durate medie delle chiamate HTTP dal gateway ai servizi back-end.
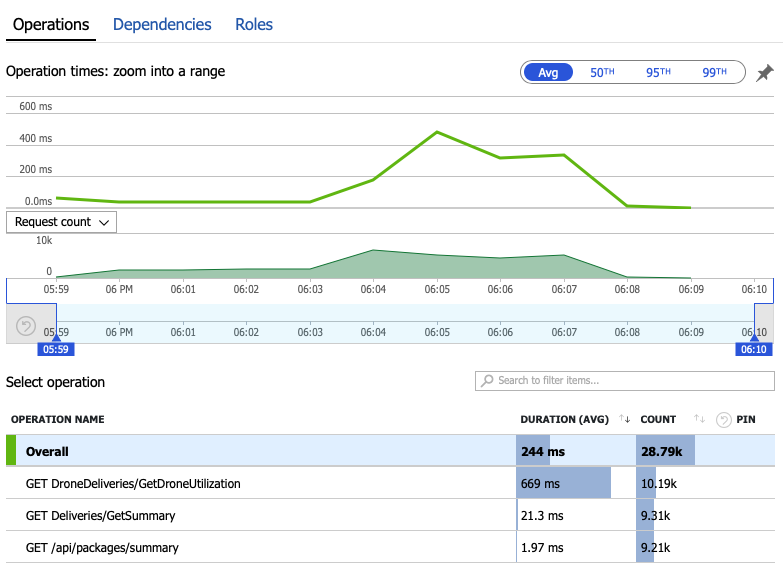
Questo grafico mostra che un'operazione in particolare, GetDroneUtilizationrichiede molto più tempo in media , in base a un ordine di grandezza. Il gateway effettua queste chiamate in parallelo, quindi l'operazione più lenta determina il tempo necessario per il completamento dell'intera richiesta.
Chiaramente il passaggio successivo è scavare nell'operazione GetDroneUtilization e cercare eventuali colli di bottiglia. Una possibilità è l'esaurimento delle risorse. Forse questo particolare servizio back-end è in esecuzione dalla CPU o dalla memoria. Per un cluster del servizio Azure Kubernetes, queste informazioni sono disponibili nella portale di Azure tramite la funzionalità Informazioni dettagliate sui contenitori di Monitoraggio di Azure. I grafici seguenti mostrano l'utilizzo delle risorse a livello di cluster:

In questo screenshot vengono visualizzati sia i valori medi che massimi. È importante esaminare più della media, perché la media può nascondere picchi nei dati. In questo caso, l'utilizzo medio della CPU rimane inferiore al 50%, ma ci sono un paio di picchi al 80%. È vicino alla capacità, ma ancora all'interno delle tolleranze. Qualcos'altro sta causando il collo di bottiglia.
Il grafico successivo rivela il vero colpevole. Questo grafico mostra i codici di risposta HTTP dal database back-end del servizio di recapito, che in questo caso è Azure Cosmos DB. La riga blu rappresenta i codici di esito positivo (HTTP 2xx), mentre la riga verde rappresenta gli errori HTTP 429. Un codice restituito HTTP 429 indica che Azure Cosmos DB limita temporaneamente le richieste, perché il chiamante usa più unità di risorse (UR) rispetto al provisioning.

Per ottenere ulteriori informazioni dettagliate, il team di sviluppo ha usato Application Insights per visualizzare i dati di telemetria end-to-end per un esempio rappresentativo di richieste. Ecco un'istanza:
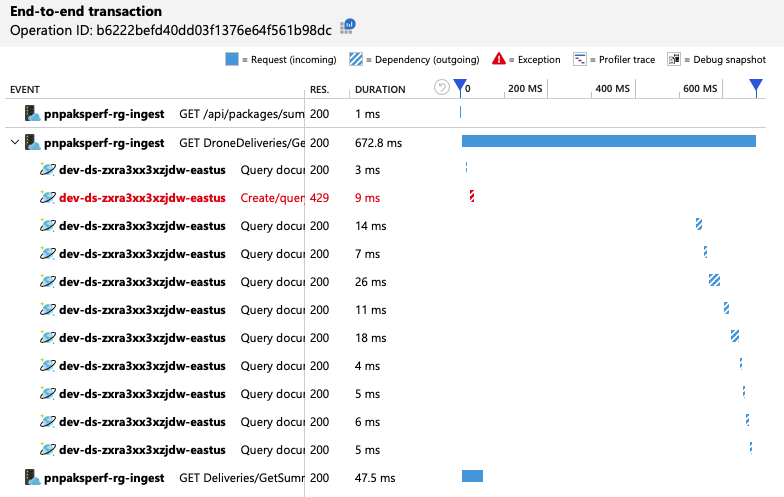
Questa visualizzazione mostra le chiamate correlate a una singola richiesta client, insieme alle informazioni sulla tempistica e ai codici di risposta. Le chiamate di primo livello sono dal gateway ai servizi back-end. La chiamata a GetDroneUtilization viene espansa per visualizzare le chiamate alle dipendenze esterne, in questo caso in Azure Cosmos DB. La chiamata in rosso ha restituito un errore HTTP 429.
Si noti il divario elevato tra l'errore HTTP 429 e la chiamata successiva. Quando la libreria client di Azure Cosmos DB riceve un errore HTTP 429, viene automaticamente disattivato e attende di ripetere l'operazione. Ciò che mostra questa visualizzazione è che durante l'operazione di 672 ms questa operazione ha impiegato la maggior parte di quel tempo in attesa di ripetere i tentativi di Azure Cosmos DB.
Ecco un altro grafico interessante per questa analisi. Mostra l'utilizzo delle UR per partizione fisica rispetto alle UR di cui è stato effettuato il provisioning per ogni partizione fisica:

Per comprendere il modo in cui Azure Cosmos DB gestisce le partizioni, è necessario comprendere il modo in cui Azure Cosmos DB gestisce le partizioni. Le raccolte in Azure Cosmos DB possono avere una chiave di partizione. Ogni valore della chiave possibile definisce una partizione logica dei dati all'interno della raccolta. Azure Cosmos DB distribuisce queste partizioni logiche in una o più partizioni fisiche . La gestione delle partizioni fisiche viene gestita automaticamente da Azure Cosmos DB. Man mano che si archiviano altri dati, Azure Cosmos DB potrebbe spostare partizioni logiche in nuove partizioni fisiche, per distribuire il carico tra le partizioni fisiche.
Per questo test di carico, è stato effettuato il provisioning dell'insieme Azure Cosmos DB con 900 UR. Il grafico mostra 100 UR per partizione fisica, che implica un totale di nove partizioni fisiche. Anche se Azure Cosmos DB gestisce automaticamente il partizionamento delle partizioni fisiche, sapendo che il conteggio delle partizioni può fornire informazioni dettagliate sulle prestazioni. Il team di sviluppo userà queste informazioni in un secondo momento, man mano che continuano a ottimizzare. Dove la linea blu attraversa la linea orizzontale viola, il consumo di UR ha superato le UR di cui è stato effettuato il provisioning. Questo è il punto in cui Azure Cosmos DB inizierà a limitare le chiamate.
Test 2: Aumentare le unità di risorsa
Per il secondo test di carico, il team ha ridimensionato la raccolta Azure Cosmos DB da 900 UR a 2500 UR. La velocità effettiva è aumentata da 19 richieste/secondo a 23 richieste/secondo e la latenza media è stata ridotta da 669 ms a 569 ms.
| Metrica | Test 1 | Test 2 |
|---|---|---|
| Velocità effettiva (req/sec) | 19 | 23 |
| Latenza media (ms) | 669 | 569 |
| Richieste riuscite | 9,8 K | 11 K |
Questi non sono enormi guadagni, ma guardando il grafico nel tempo mostra un quadro più completo:

Mentre il test precedente ha mostrato un picco iniziale seguito da un calo netto, questo test mostra una velocità effettiva più coerente. Tuttavia, la velocità effettiva massima non è significativamente superiore.
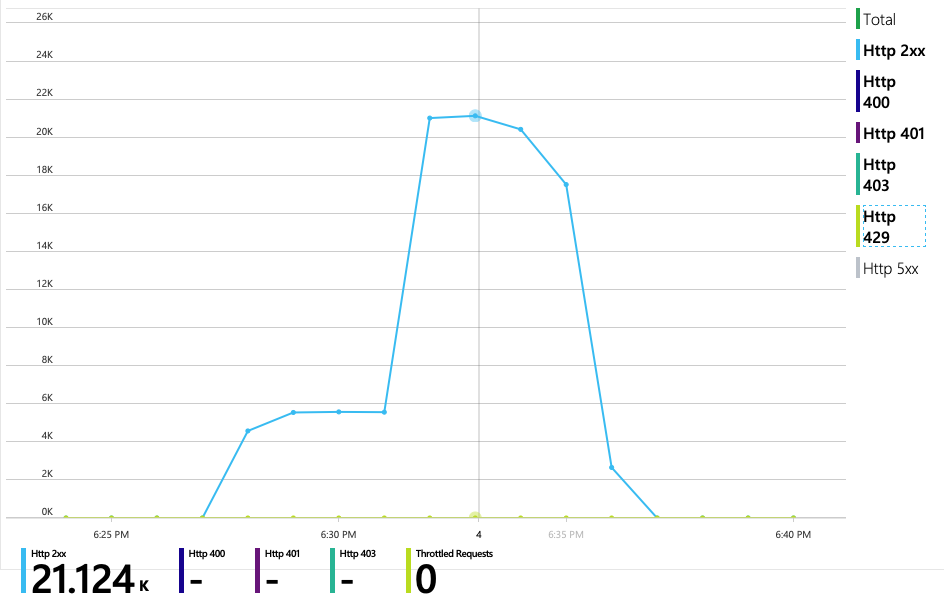
Tutte le richieste ad Azure Cosmos DB hanno restituito uno stato 2xx e gli errori HTTP 429 sono andati via:
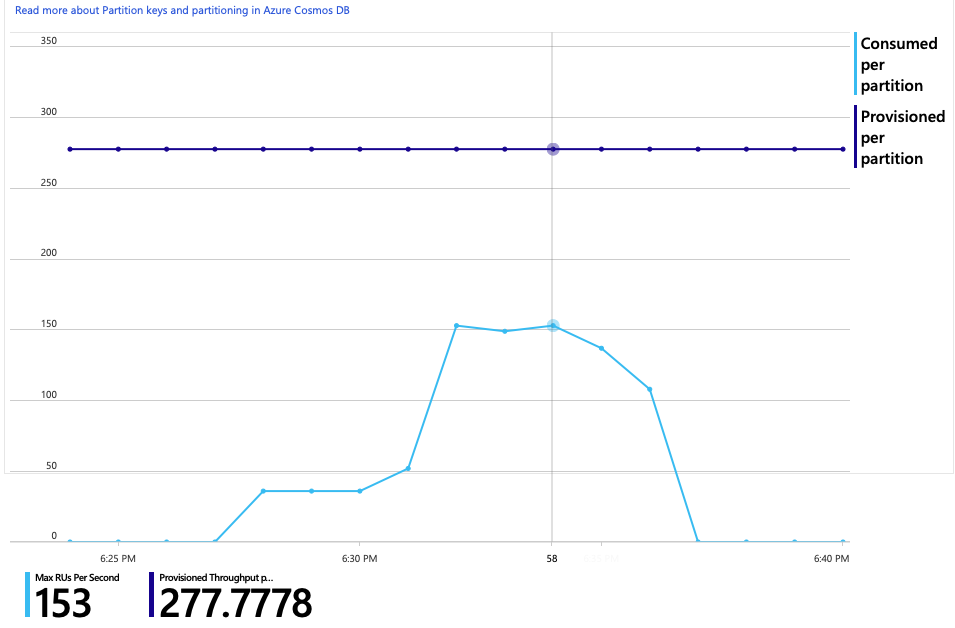
Il grafico dell'utilizzo delle UR rispetto alle UR con provisioning mostra che c'è un sacco di headroom. Ci sono circa 275 UR per partizione fisica e il test di carico ha raggiunto circa 100 UR usate al secondo.
Un'altra metrica interessante è il numero di chiamate ad Azure Cosmos DB per operazione riuscita:
| Metrica | Test 1 | Test 2 |
|---|---|---|
| Chiamate per operazione | 11 | 9 |
Supponendo che non si siano verificati errori, il numero di chiamate deve corrispondere al piano di query effettivo. In questo caso, l'operazione comporta una query tra partizioni che raggiunge tutte e nove le partizioni fisiche. Il valore più alto nel primo test di carico riflette il numero di chiamate che hanno restituito un errore 429.
Questa metrica è stata calcolata eseguendo una query di Log Analytics personalizzata:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
Per riepilogare, il secondo test di carico mostra un miglioramento. Tuttavia, l'operazione GetDroneUtilization richiede ancora circa un ordine di grandezza maggiore rispetto all'operazione più lenta successiva. L'analisi delle transazioni end-to-end consente di spiegare perché:
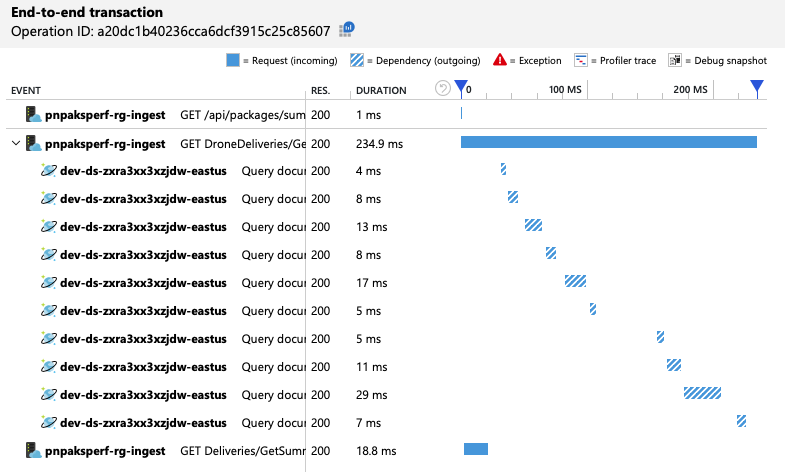
Come accennato in precedenza, l'operazione GetDroneUtilization comporta una query tra partizioni in Azure Cosmos DB. Ciò significa che il client Azure Cosmos DB deve eseguire la fanout della query in ogni partizione fisica e raccogliere i risultati. Come illustrato nella visualizzazione delle transazioni end-to-end, queste query vengono eseguite in serie. L'operazione richiede fino a quando la somma di tutte le query e questo problema peggiora solo quando le dimensioni dei dati aumentano e vengono aggiunte più partizioni fisiche.
Test 3: Query parallele
In base ai risultati precedenti, un modo ovvio per ridurre la latenza consiste nel eseguire le query in parallelo. L'SDK client di Azure Cosmos DB ha un'impostazione che controlla il massimo grado di parallelismo.
| Valore | Descrizione |
|---|---|
| 0 | Nessun parallelismo (impostazione predefinita) |
| > 0 | Numero massimo di chiamate parallele |
| -1 | L'SDK client seleziona un grado ottimale di parallelismo |
Per il terzo test di carico, questa impostazione è stata modificata da 0 a -1. La tabella seguente riepiloga i risultati:
| Metrica | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| Velocità effettiva (req/sec) | 19 | 23 | 42 |
| Latenza media (ms) | 669 | 569 | 215 |
| Richieste riuscite | 9,8 K | 11 K | 20 K |
| Richieste limitate | 2,72 K | 0 | 0 |
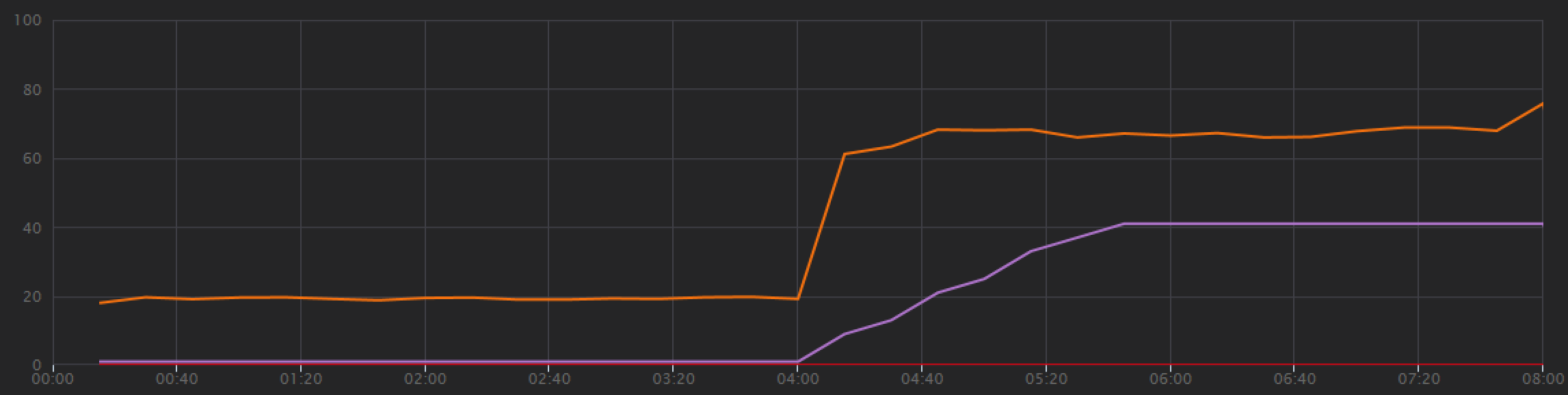
Dal grafico dei test di carico, non solo la velocità effettiva complessiva è molto più elevata (la linea arancione), ma anche la velocità effettiva mantiene il ritmo con il carico (la linea viola).
È possibile verificare che il client Azure Cosmos DB stia eseguendo query in parallelo esaminando la visualizzazione delle transazioni end-to-end:
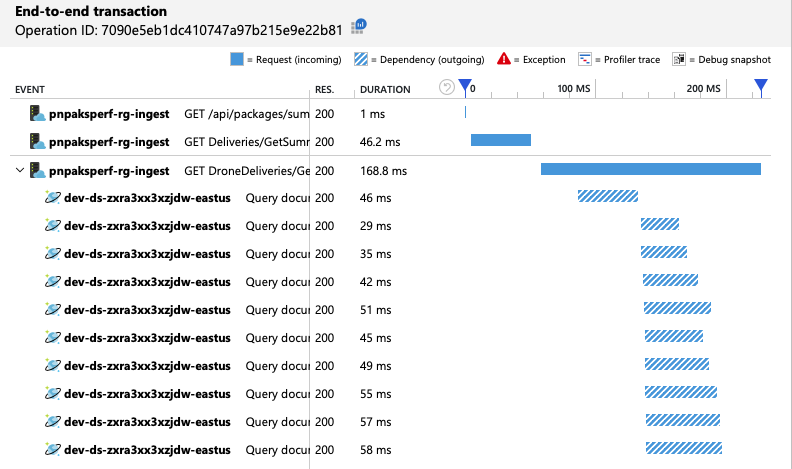
È interessante notare che un effetto collaterale dell'aumento della velocità effettiva è che anche il numero di UR utilizzate al secondo aumenta. Sebbene Azure Cosmos DB non limitasse le richieste durante questo test, l'utilizzo era vicino al limite di UR di cui è stato effettuato il provisioning:
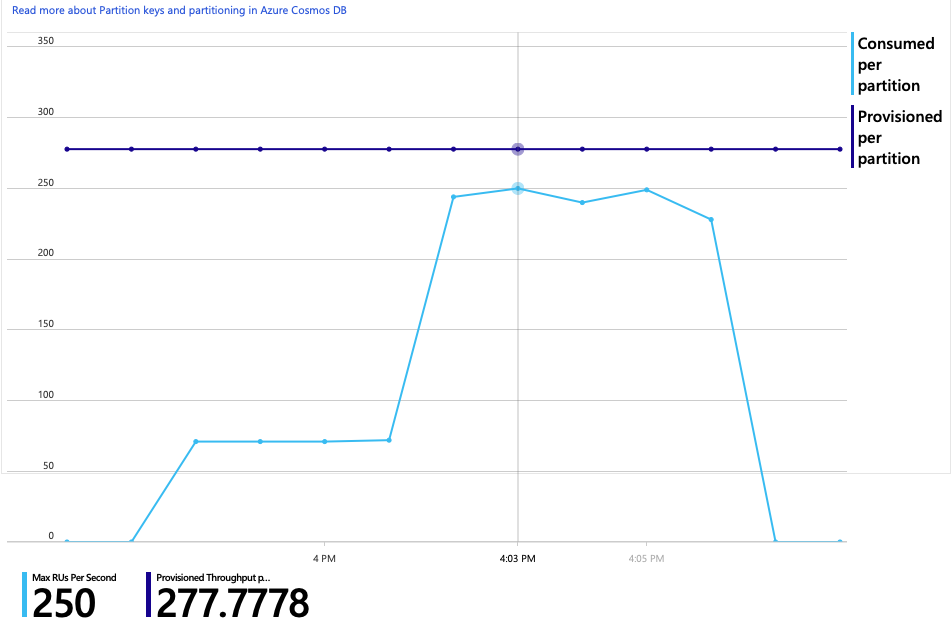
Questo grafico potrebbe essere un segnale per aumentare ulteriormente il numero di istanze del database. Tuttavia, si scopre che è possibile ottimizzare la query.
Passaggio 4: Ottimizzare la query
Il test di carico precedente ha mostrato prestazioni migliori in termini di latenza e velocità effettiva. La latenza media delle richieste è stata ridotta del 68% e la velocità effettiva è aumentata del 220%. Tuttavia, la query tra partizioni è un problema.
Il problema con le query tra partizioni è che si paga per le UR in ogni partizione. Se la query viene eseguita solo occasionalmente, ad esempio una volta all'ora, potrebbe non essere importante. Tuttavia, ogni volta che viene visualizzato un carico di lavoro con un numero elevato di operazioni di lettura che comporta una query tra partizioni, si noterà se la query può essere ottimizzata includendo una chiave di partizione. Potrebbe essere necessario riprogettare la raccolta per usare una chiave di partizione diversa.
Ecco la query per questo scenario specifico:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
Questa query seleziona i record che corrispondono a un ID proprietario e a un mese/anno specifici. Nella progettazione originale, nessuna di queste proprietà è la chiave di partizione. Ciò richiede al client di eseguire la fanout della query in ogni partizione fisica e raccogliere i risultati. Per migliorare le prestazioni delle query, il team di sviluppo ha modificato la progettazione in modo che l'ID proprietario sia la chiave di partizione per la raccolta. In questo modo, la query può specificare come destinazione una partizione fisica specifica. Azure Cosmos DB gestisce automaticamente questa operazione. Non è necessario gestire il mapping tra i valori della chiave di partizione e le partizioni fisiche.
Dopo il passaggio della raccolta alla nuova chiave di partizione, si è verificato un notevole miglioramento del consumo di UR, che si traduce direttamente in costi inferiori.
| Metrica | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| UR per operazione | 29 | 29 | 29 | 3.4 |
| Chiamate per operazione | 11 | 9 | 10 | 1 |
La visualizzazione delle transazioni end-to-end indica che, come previsto, la query legge una sola partizione fisica:
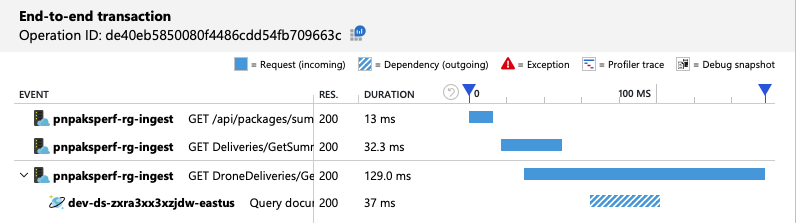
Il test di carico mostra una velocità effettiva e una latenza migliorate:
| Metrica | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Velocità effettiva (req/sec) | 19 | 23 | 42 | 59 |
| Latenza media (ms) | 669 | 569 | 215 | 176 |
| Richieste riuscite | 9,8 K | 11 K | 20 K | 29 K |
| Richieste limitate | 2.72 K | 0 | 0 | 0 |
Una conseguenza delle prestazioni migliorate è che l'utilizzo della CPU del nodo diventa molto elevato:
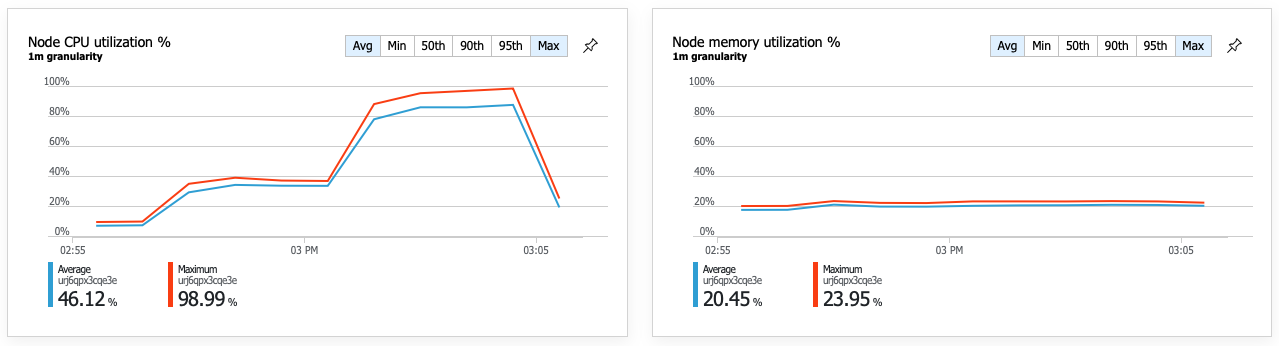
Verso la fine del test di carico, la CPU media ha raggiunto circa il 90% e la CPU massima ha raggiunto il 100%. Questa metrica indica che la CPU è il collo di bottiglia successivo nel sistema. Se è necessaria una velocità effettiva maggiore, il passaggio successivo potrebbe aumentare il servizio di recapito in più istanze.
Riepilogo
Per questo scenario sono stati identificati i colli di bottiglia seguenti:
- Richieste di limitazione delle richieste di Azure Cosmos DB a causa del provisioning di UR insufficienti.
- Latenza elevata causata dalla query su più partizioni di database in seriale.
- Query tra partizioni inefficienti, perché la query non includeva la chiave di partizione.
Inoltre, l'utilizzo della CPU è stato identificato come un potenziale collo di bottiglia su larga scala. Per diagnosticare questi problemi, il team di sviluppo ha esaminato:
- Latenza e velocità effettiva dal test di carico.
- Errori e consumo ur di Azure Cosmos DB.
- Visualizzazione delle transazioni end-to-end in Application Insights.
- Utilizzo della CPU e della memoria nei contenitori di Monitoraggio di Azure.
Passaggi successivi
Esaminare gli antipattern delle prestazioni