Esercitazione: Eseguire query su un contenitore Docker Linux SQL Server in una rete virtuale da un notebook di Azure Databricks
Questa esercitazione illustra come integrare Azure Databricks con un contenitore Docker Linux SQL Server in una rete virtuale.
Questa esercitazione descrive come:
- Distribuire un'area di lavoro di Azure Databricks in una rete virtuale
- Installare una macchina virtuale Linux in una rete pubblica
- Installare Docker
- Installare Microsoft SQL Server in Linux contenitore docker
- Eseguire query sull'SQL Server usando JDBC da un notebook di Databricks
Prerequisiti
Creare un'area di lavoro di Databricks in una rete virtuale.
Installare Ubuntu per Windows.
Scaricare SQL Server Management Studio.
Creare una macchina virtuale Linux
Nel portale di Azure selezionare l'icona per Macchine virtuali. Selezionare quindi + Aggiungi.
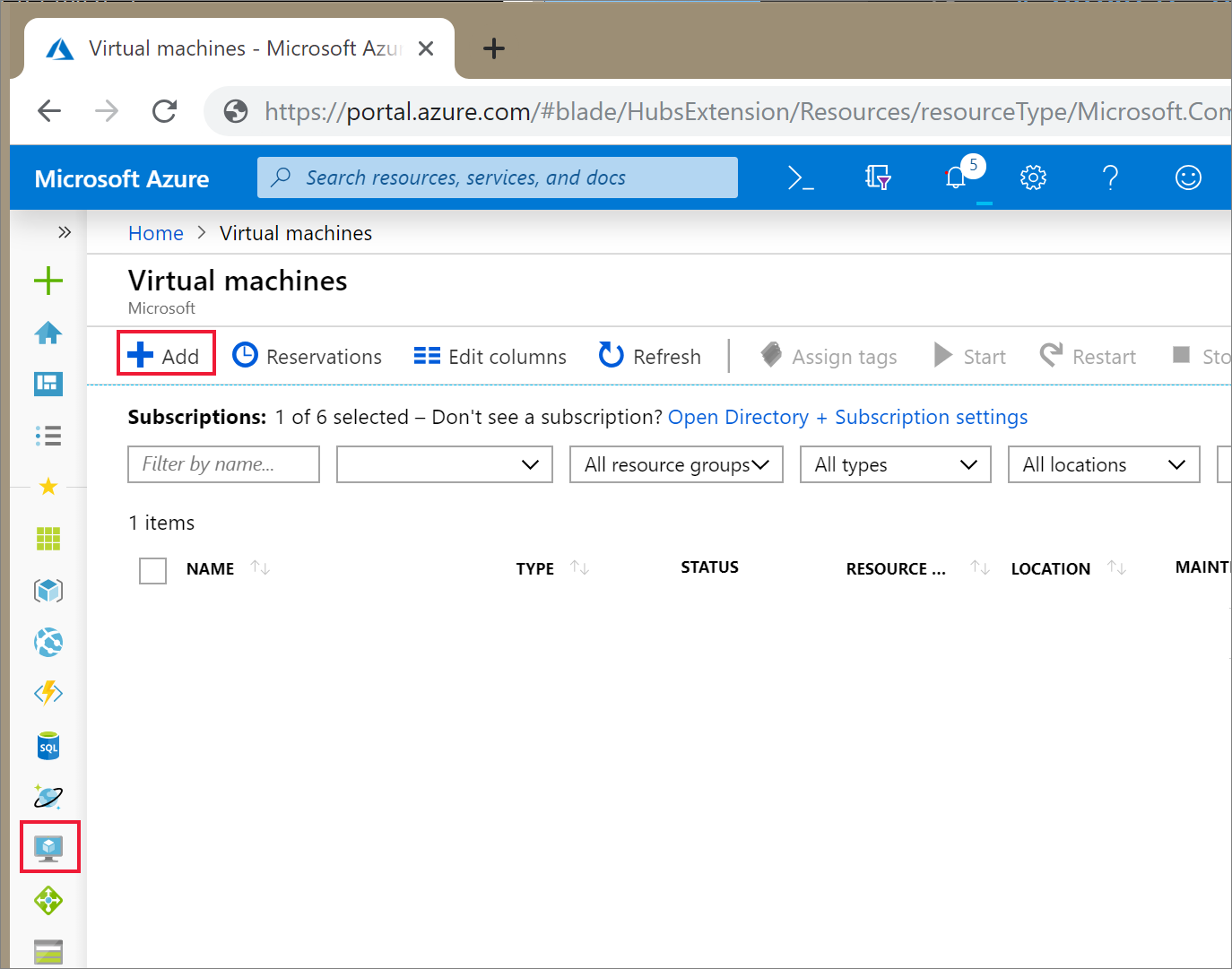
Nella scheda Nozioni di base scegliere Ubuntu Server 18.04 LTS e modificare le dimensioni della macchina virtuale in B2s. Scegliere un nome utente e una password amministratore.

Passare alla scheda Rete . Scegliere la rete virtuale e la subnet pubblica che include il cluster Azure Databricks. Selezionare Rivedi e crea, quindi Crea per distribuire la macchina virtuale.
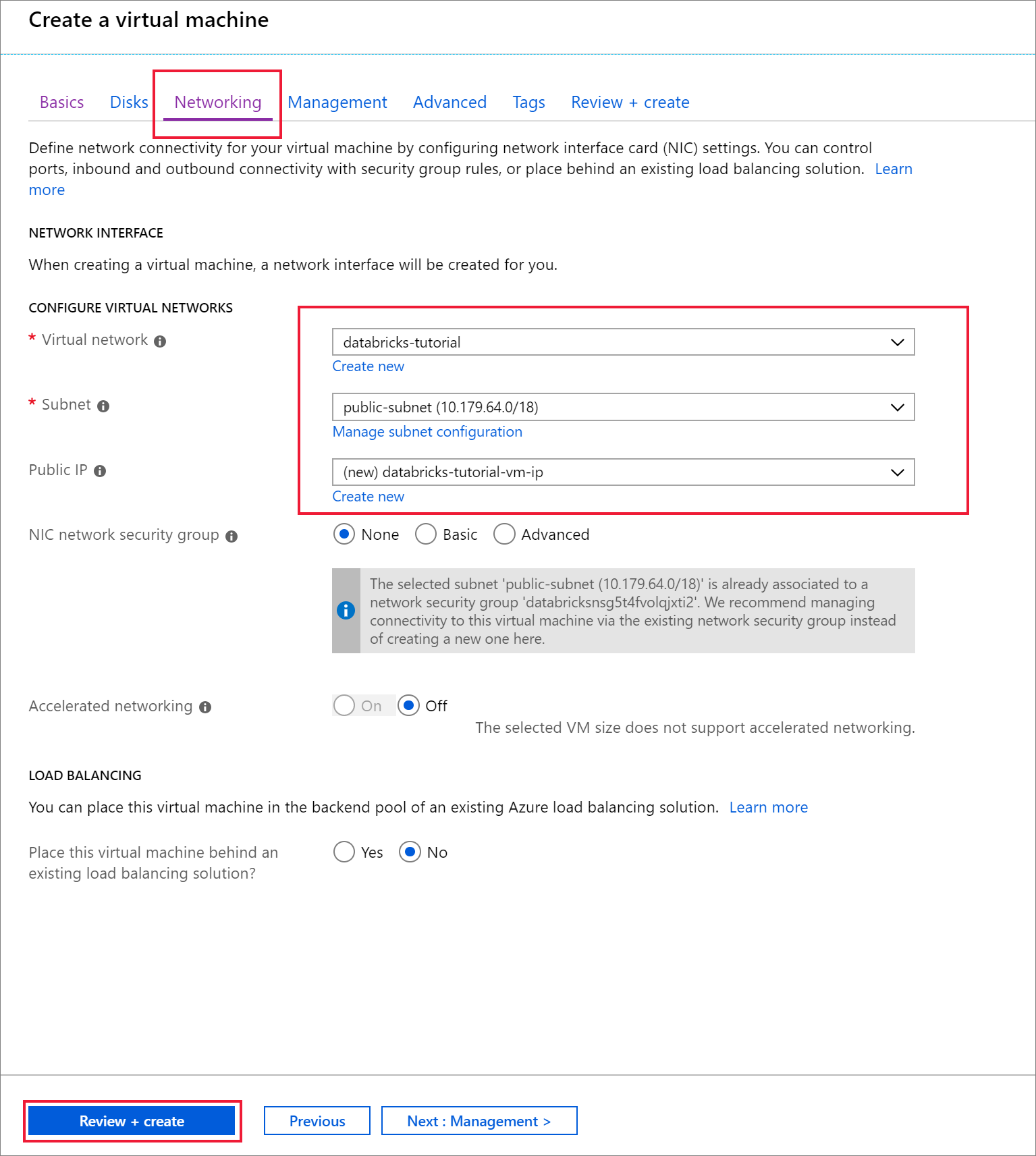
Al termine della distribuzione, passare alla macchina virtuale. Si noti l'indirizzo IP pubblico e la rete virtuale/subnet nella panoramica. Selezionare l'indirizzo IP pubblico
Modificare l'assegnazione in Statico e immettere un'etichetta di nome DNS. Selezionare Salva e riavviare la macchina virtuale.

Selezionare la scheda Rete in Impostazioni. Si noti che il gruppo di sicurezza di rete creato durante la distribuzione di Azure Databricks è associato alla macchina virtuale. Selezionare Aggiungi regola porta in ingresso.
Aggiungere una regola per aprire la porta 22 per SSH. Usare le impostazioni seguenti:
Impostazione Valore suggerito Descrizione Fonte Indirizzi IP Gli indirizzi IP specificano che il traffico in ingresso da un indirizzo IP di origine specifico sarà consentito o negato da questa regola. Indirizzi IP di origine <ip pubblico> Immettere l'indirizzo IP pubblico. È possibile trovare l'indirizzo IP pubblico visitando bing.com e cercando "my IP". Intervalli di porte di origine * Consenti traffico da qualsiasi porta. Destinazione Indirizzi IP Gli indirizzi IP specificano che il traffico in uscita per un indirizzo IP di origine specifico sarà consentito o negato da questa regola. Indirizzi IP di destinazione <ip pubblico della macchina virtuale> Immettere l'indirizzo IP pubblico della macchina virtuale. È possibile trovare questa funzionalità nella pagina Panoramica della macchina virtuale. Intervalli di porte di destinazione 22 Aprire la porta 22 per SSH. Priorità 290 Assegnare alla regola una priorità. Nome ssh-databricks-tutorial-vm Assegnare alla regola un nome. 
Aggiungere una regola per aprire la porta 1433 per SQL con le impostazioni seguenti:
Impostazione Valore suggerito Descrizione Fonte Qualsiasi L'origine specifica che il traffico in ingresso da un indirizzo IP di origine specifico sarà consentito o negato da questa regola. Intervalli di porte di origine * Consenti traffico da qualsiasi porta. Destinazione Indirizzi IP Gli indirizzi IP specificano che il traffico in uscita per un indirizzo IP di origine specifico sarà consentito o negato da questa regola. Indirizzi IP di destinazione <ip pubblico della macchina virtuale> Immettere l'indirizzo IP pubblico della macchina virtuale. È possibile trovare questa funzionalità nella pagina Panoramica della macchina virtuale. Intervalli di porte di destinazione 1433 Aprire la porta 22 per SQL Server. Priorità 300 Assegnare alla regola una priorità. Nome sql-databricks-tutorial-vm Assegnare alla regola un nome. 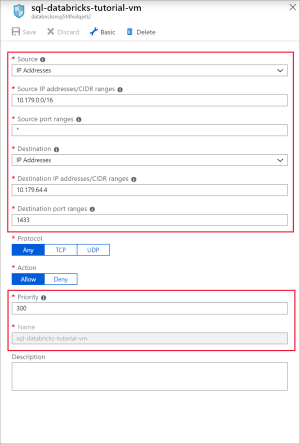
Eseguire SQL Server in un contenitore Docker
Aprire Ubuntu per Windows o qualsiasi altro strumento che consente di accedere a SSH nella macchina virtuale. Passare alla macchina virtuale nel portale di Azure e selezionare Connetti per ottenere il comando SSH necessario per connettersi.

Immettere il comando nel terminale Ubuntu e immettere la password amministratore creata quando è stata configurata la macchina virtuale.

Usare il comando seguente per installare Docker nella macchina virtuale.
sudo apt-get install docker.ioVerificare l'installazione di Docker con il comando seguente:
sudo docker --versionInstallare l'immagine.
sudo docker pull mcr.microsoft.com/mssql/server:2017-latestControllare le immagini.
sudo docker imagesEseguire il contenitore dall'immagine.
sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Password1234' -p 1433:1433 --name sql1 -d mcr.microsoft.com/mssql/server:2017-latestVerificare che il contenitore sia in esecuzione.
sudo docker ps -a
Creare un database SQL
Aprire SQL Server Management Studio e connettersi al server usando il nome del server e l'autenticazione SQL. Il nome utente di accesso è SA e la password è la password impostata nel comando Docker. La password nel comando di esempio è
Password1234.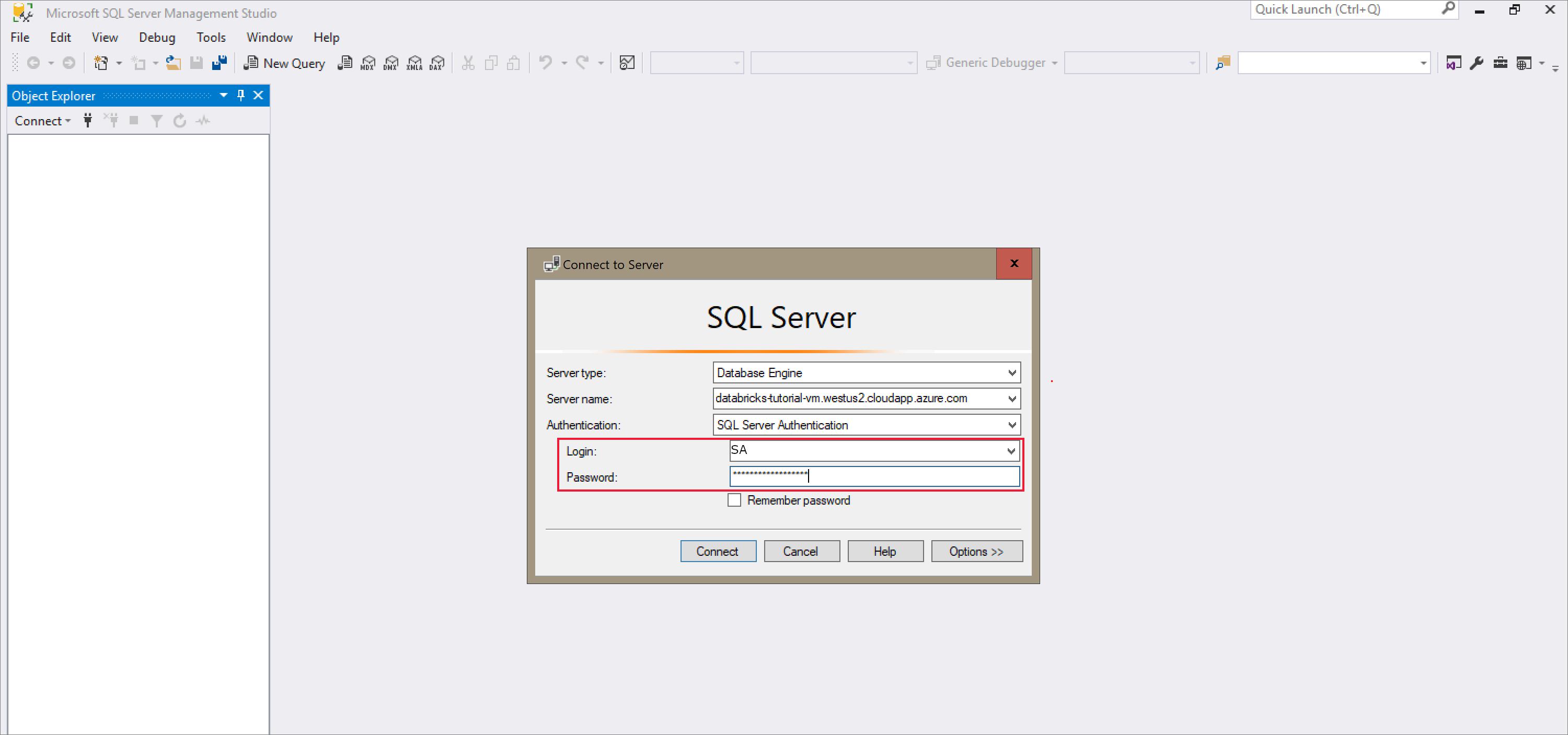
Dopo aver eseguito la connessione, selezionare Nuova query e immettere il frammento di codice seguente per creare un database, una tabella e inserire alcuni record nella tabella.
CREATE DATABASE MYDB; GO USE MYDB; CREATE TABLE states(Name VARCHAR(20), Capitol VARCHAR(20)); INSERT INTO states VALUES ('Delaware','Dover'); INSERT INTO states VALUES ('South Carolina','Columbia'); INSERT INTO states VALUES ('Texas','Austin'); SELECT * FROM states GO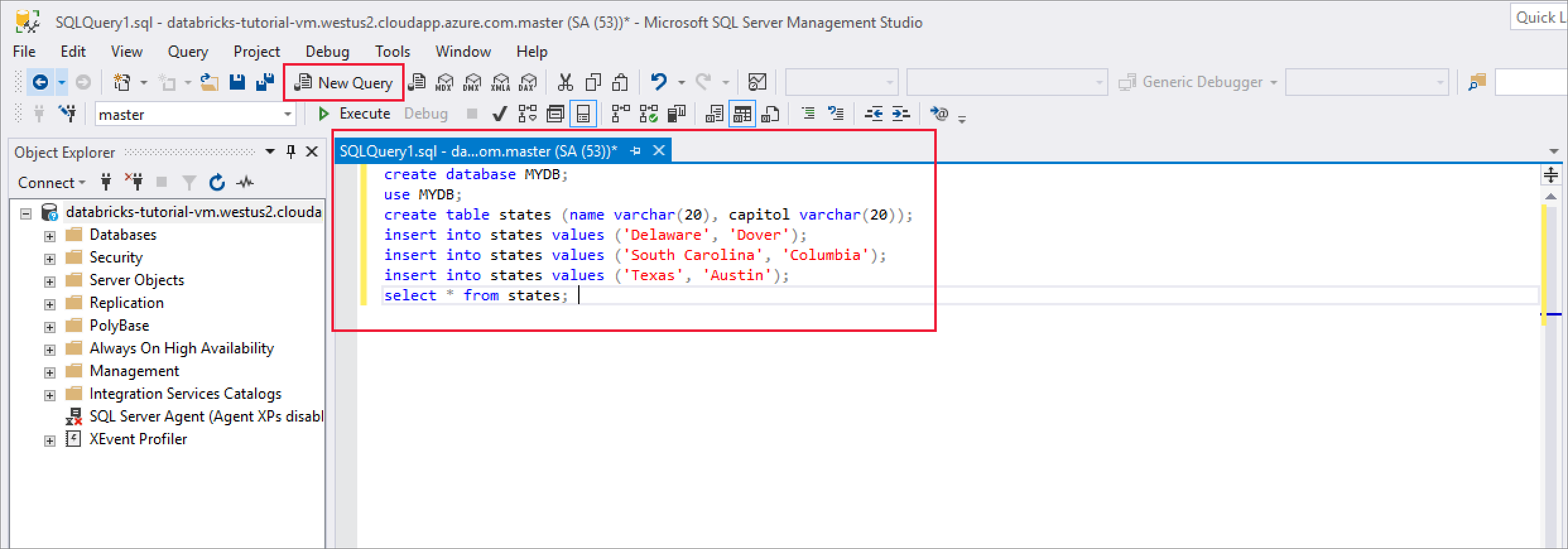
Eseguire query SQL Server da Azure Databricks
Passare all'area di lavoro di Azure Databricks e verificare che sia stato creato un cluster come parte dei prerequisiti. Selezionare quindi Crea un notebook. Assegnare un nome al notebook, selezionare Python come linguaggio e selezionare il cluster creato.
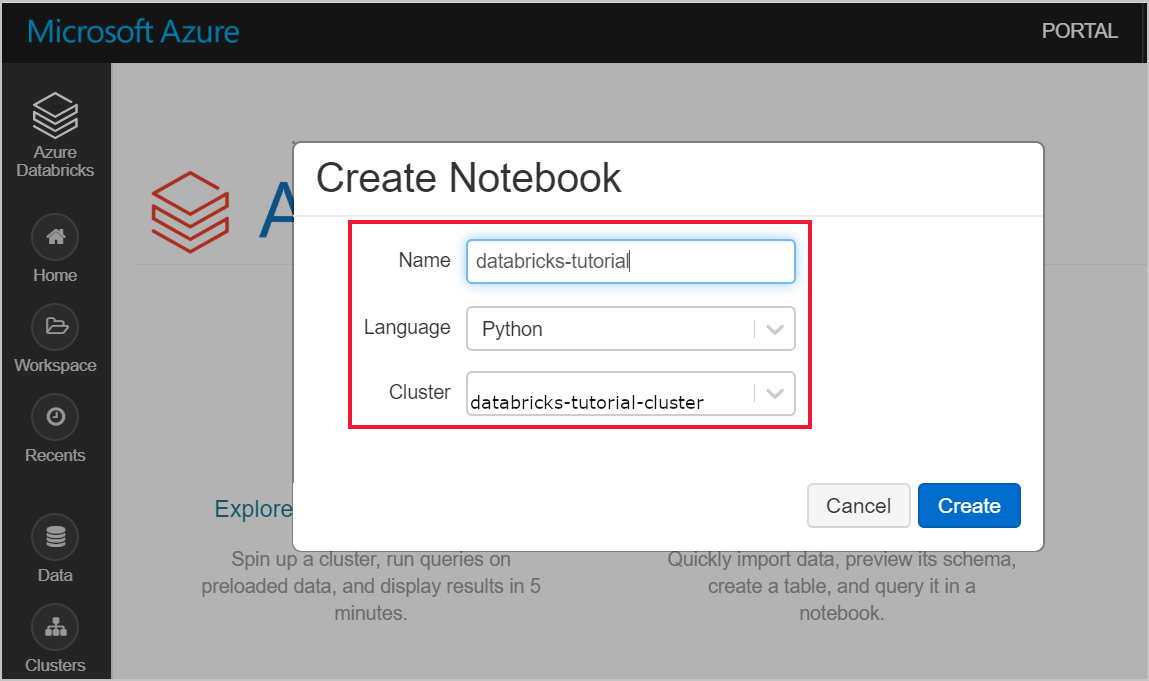
Usare il comando seguente per eseguire il ping dell'indirizzo IP interno della macchina virtuale SQL Server. Il ping dovrebbe avere esito positivo. In caso contrario, verificare che il contenitore sia in esecuzione ed esaminare la configurazione del gruppo di sicurezza di rete.If not not, verify that the container is running, and review the network security group (NSG) configuration.
%sh ping 10.179.64.4È anche possibile usare il comando nslookup per esaminare.
%sh nslookup databricks-tutorial-vm.westus2.cloudapp.azure.comDopo aver eseguito il ping del SQL Server, è possibile eseguire query sul database e sulle tabelle. Eseguire il codice Python seguente:
jdbcHostname = "10.179.64.4" jdbcDatabase = "MYDB" userName = 'SA' password = 'Password1234' jdbcPort = 1433 jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, userName, password) df = spark.read.jdbc(url=jdbcUrl, table='states') display(df)
Pulire le risorse
Quando non sono più necessari, eliminare il gruppo di risorse, l'area di lavoro di Azure Databricks e tutte le risorse correlate. L'eliminazione del processo evita la fatturazione non necessaria. Se si prevede di usare l'area di lavoro di Azure Databricks in futuro, è possibile arrestare il cluster e riavviarlo in un secondo momento. Se non si intende continuare a usare questa area di lavoro di Azure Databricks, eliminare tutte le risorse create in questa esercitazione seguendo questa procedura:
Nel menu a sinistra nel portale di Azure fare clic su Gruppi di risorse e quindi sul nome del gruppo di risorse creato.
Nella pagina del gruppo di risorse selezionare Elimina, digitare il nome della risorsa da eliminare nella casella di testo e quindi selezionare di nuovo Elimina .
Passaggi successivi
Passare all'articolo successivo per informazioni su come estrarre, trasformare e caricare dati usando Azure Databricks.