Opzioni di configurazione: Application Insights di Monitoraggio di Azure per Java
Questo articolo illustra come configurare Application Insights per Monitoraggio di Azure per Java.
stringa di Connessione ion e nome del ruolo
Connessione stringa e nome del ruolo sono le impostazioni più comuni necessarie per iniziare:
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
}
}
Connessione è necessaria la stringa di Connessione ion. Il nome del ruolo è importante ogni volta che si inviano dati da applicazioni diverse alla stessa risorsa di Application Insights.
Altre informazioni e opzioni di configurazione sono disponibili nelle sezioni seguenti.
Percorso del file di configurazione
Per impostazione predefinita, Application Insights Java 3.x prevede che il file di configurazione sia denominato applicationinsights.jsone che si trovi nella stessa directory di applicationinsights-agent-3.5.2.jar.
È possibile specificare il percorso del file di configurazione usando una delle due opzioni seguenti:
- La variabile di ambiente
APPLICATIONINSIGHTS_CONFIGURATION_FILE applicationinsights.configuration.fileProprietà di sistema Java
Se si specifica un percorso relativo, viene risolto in relazione alla directory in cui applicationinsights-agent-3.5.2.jar si trova.
In alternativa, anziché usare un file di configurazione, è possibile specificare l'intero contenuto della configurazione JSON tramite la variabile APPLICATIONINSIGHTS_CONFIGURATION_CONTENTdi ambiente .
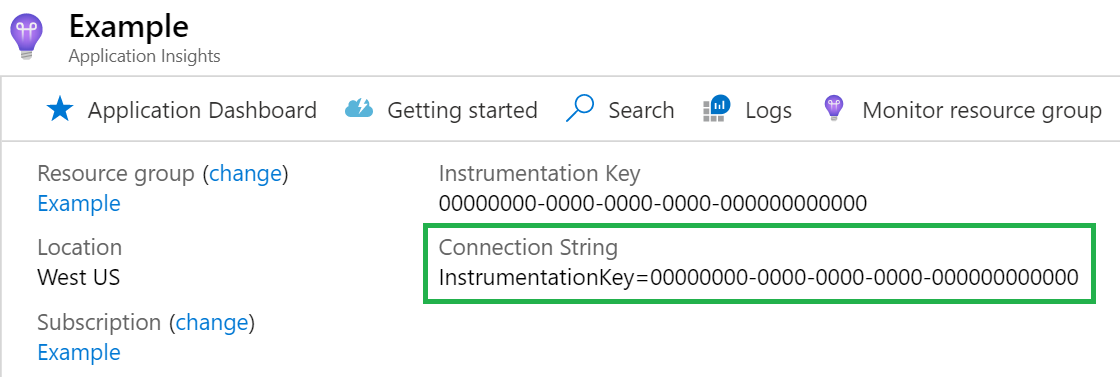
Connection string
Connessione è necessaria la stringa di Connessione ion. È possibile trovare il stringa di connessione nella risorsa di Application Insights.
{
"connectionString": "..."
}
È anche possibile impostare il stringa di connessione usando la variabile APPLICATIONINSIGHTS_CONNECTION_STRINGdi ambiente . Ha quindi la precedenza sulla stringa di connessione specificata nella configurazione JSON.
In alternativa, è possibile impostare il stringa di connessione usando la proprietà applicationinsights.connection.stringdi sistema Java . Ha anche la precedenza sulla stringa di connessione specificata nella configurazione JSON.
È anche possibile impostare il stringa di connessione specificando un file da cui caricare il stringa di connessione.
Se si specifica un percorso relativo, viene risolto in relazione alla directory in cui applicationinsights-agent-3.5.2.jar si trova.
{
"connectionString": "${file:connection-string-file.txt}"
}
Il file deve contenere solo il stringa di connessione e nient'altro.
Non impostando il stringa di connessione disabilita l'agente Java.
Se sono state distribuite più applicazioni nella stessa macchina virtuale Java (JVM) e si vuole che inviino dati di telemetria a stringa di connessione diverse, vedere override delle stringhe di Connessione ion (anteprima).
Nome del ruolo cloud
Il nome del ruolo cloud viene usato per etichettare il componente sulla mappa dell'applicazione.
Se si vuole impostare il nome del ruolo cloud:
{
"role": {
"name": "my cloud role name"
}
}
Se il nome del ruolo cloud non è impostato, il nome della risorsa di Application Insights viene usato per etichettare il componente nella mappa dell'applicazione.
È anche possibile impostare il nome del ruolo cloud usando la variabile APPLICATIONINSIGHTS_ROLE_NAMEdi ambiente . Ha quindi la precedenza sul nome del ruolo cloud specificato nella configurazione JSON.
In alternativa, è possibile impostare il nome del ruolo cloud usando la proprietà applicationinsights.role.namedi sistema Java . Ha anche la precedenza sul nome del ruolo cloud specificato nella configurazione JSON.
Se sono state distribuite più applicazioni nella stessa JVM e si vuole che inviino dati di telemetria a nomi di ruolo cloud diversi, vedere Override del nome del ruolo cloud (anteprima).
Istanza del ruolo del cloud
Per impostazione predefinita, l'istanza del ruolo cloud è il nome del computer.
Se si vuole impostare l'istanza del ruolo cloud su un valore diverso rispetto al nome del computer:
{
"role": {
"name": "my cloud role name",
"instance": "my cloud role instance"
}
}
È anche possibile impostare l'istanza del ruolo cloud usando la variabile APPLICATIONINSIGHTS_ROLE_INSTANCEdi ambiente . Ha quindi la precedenza sull'istanza del ruolo cloud specificata nella configurazione JSON.
In alternativa, è possibile impostare l'istanza del ruolo cloud usando la proprietà applicationinsights.role.instancedi sistema Java .
Ha anche la precedenza sull'istanza del ruolo cloud specificata nella configurazione JSON.
Campionamento
Nota
Il campionamento può essere un ottimo modo per ridurre il costo di Application Insights. Assicurarsi di configurare la configurazione di campionamento in modo appropriato per il caso d'uso.
Il campionamento è basato sulla richiesta, il che significa che se una richiesta viene acquisita (campionata), quindi sono le relative dipendenze, log ed eccezioni.
Il campionamento si basa anche sull'ID traccia per garantire decisioni di campionamento coerenti in diversi servizi.
Il campionamento si applica solo ai log all'interno di una richiesta. I log che non si trovano all'interno di una richiesta (ad esempio, i log di avvio) vengono sempre raccolti per impostazione predefinita. Se si desidera campionare tali log, è possibile usare override di campionamento.
Campionamento con frequenza limitata
A partire dalla versione 3.4.0, il campionamento con frequenza limitata è disponibile ed è ora il valore predefinito.
Se non è configurato alcun campionamento, il campionamento predefinito è ora limitato a velocità configurata per acquisire al massimo (circa) cinque richieste al secondo, insieme a tutte le dipendenze e i log di tali richieste.
Questa configurazione sostituisce l'impostazione predefinita precedente, che doveva acquisire tutte le richieste. Se si desidera comunque acquisire tutte le richieste, usare il campionamento a percentuale fissa e impostare la percentuale di campionamento su 100.
Nota
Il campionamento con frequenza limitata è approssimativo perché internamente deve adattare una percentuale di campionamento "fissa" nel tempo per generare conteggi accurati degli elementi in ogni record di telemetria. Internamente, il campionamento con frequenza limitata viene ottimizzato per adattarsi rapidamente (0,1 secondi) ai carichi delle nuove applicazioni. Per questo motivo, non è consigliabile vederlo superare la frequenza configurata per molto o per molto tempo.
Questo esempio illustra come impostare il campionamento per acquisire al massimo (approssimativamente) una richiesta al secondo:
{
"sampling": {
"requestsPerSecond": 1.0
}
}
requestsPerSecond Può essere un decimale, quindi è possibile configurarlo per acquisire meno di una richiesta al secondo, se necessario. Ad esempio, un valore indica l'acquisizione al massimo di 0.5 una richiesta ogni 2 secondi.
È anche possibile impostare la percentuale di campionamento usando la variabile APPLICATIONINSIGHTS_SAMPLING_REQUESTS_PER_SECONDdi ambiente . Ha quindi la precedenza sul limite di velocità specificato nella configurazione JSON.
Campionamento a percentuale fissa
Questo esempio illustra come impostare il campionamento per acquisire circa un terzo di tutte le richieste:
{
"sampling": {
"percentage": 33.333
}
}
È anche possibile impostare la percentuale di campionamento usando la variabile APPLICATIONINSIGHTS_SAMPLING_PERCENTAGEdi ambiente . Ha quindi la precedenza sulla percentuale di campionamento specificata nella configurazione JSON.
Nota
Per la percentuale di campionamento, scegliere una percentuale vicina a 100/N, dove N è un numero intero. Attualmente il campionamento non supporta altri valori.
Override del campionamento
Le sostituzioni di campionamento consentono di eseguire l'override della percentuale di campionamento predefinita. È ad esempio possibile:
- Impostare la percentuale di campionamento su 0 o su un valore ridotto per i controlli di integrità rumorosi.
- Impostare la percentuale di campionamento su 0 o su un valore ridotto per le chiamate di dipendenza rumorose.
- Impostare la percentuale di campionamento su 100 per un tipo di richiesta importante. Ad esempio, è possibile usare
/loginanche se il campionamento predefinito è configurato per un valore inferiore.
Per altre informazioni, vedere la documentazione Degli override di campionamento.
Metriche delle estensioni di gestione Java
Per raccogliere altre metriche JMX (Java Management Extensions):
{
"jmxMetrics": [
{
"name": "JVM uptime (millis)",
"objectName": "java.lang:type=Runtime",
"attribute": "Uptime"
},
{
"name": "MetaSpace Used",
"objectName": "java.lang:type=MemoryPool,name=Metaspace",
"attribute": "Usage.used"
}
]
}
Nell'esempio di configurazione precedente:
nameè il nome della metrica assegnato a questa metrica JMX (può essere qualsiasi elemento).objectNameè il nome dell'oggettoJMX MBeanche si desidera raccogliere. È supportato l'asterisco carattere jolly (*) .attributeè il nome dell'attributo all'interno dell'oggettoJMX MBeanche si desidera raccogliere.
Sono supportati i valori delle metriche JMX numerici e booleani. Le metriche JMX booleane vengono mappate a 0 per false e 1 per true.
Per altre informazioni, vedere la documentazione sulle metriche JMX.
Dimensioni personalizzate
Per aggiungere dimensioni personalizzate a tutti i dati di telemetria:
{
"customDimensions": {
"mytag": "my value",
"anothertag": "${ANOTHER_VALUE}"
}
}
È possibile usare ${...} per leggere il valore dalla variabile di ambiente specificata all'avvio.
Nota
A partire dalla versione 3.0.2, se si aggiunge una dimensione personalizzata denominata service.version, il valore viene archiviato nella application_Version colonna nella tabella Log di Application Insights anziché come dimensione personalizzata.
Attributo ereditato (anteprima)
A partire dalla versione 3.2.0, è possibile impostare una dimensione personalizzata a livello di codice nei dati di telemetria delle richieste. Garantisce l'ereditarietà in base ai dati di telemetria delle dipendenze e dei log. Tutti vengono acquisiti nel contesto di tale richiesta.
{
"preview": {
"inheritedAttributes": [
{
"key": "mycustomer",
"type": "string"
}
]
}
}
E poi all'inizio di ogni richiesta, chiamare:
Span.current().setAttribute("mycustomer", "xyz");
Vedere anche: Aggiungere una proprietà personalizzata a un oggetto Span.
override della stringa di Connessione ion (anteprima)
Questa funzionalità è disponibile in anteprima, a partire dalla versione 3.4.0.
Connessione override delle stringhe consente di eseguire l'override del stringa di connessione predefinito. È ad esempio possibile:
- Impostare un stringa di connessione per un prefisso
/myapp1di percorso HTTP. - Impostare un altro stringa di connessione per un altro prefisso
/myapp2/di percorso HTTP.
{
"preview": {
"connectionStringOverrides": [
{
"httpPathPrefix": "/myapp1",
"connectionString": "..."
},
{
"httpPathPrefix": "/myapp2",
"connectionString": "..."
}
]
}
}
Override del nome del ruolo cloud (anteprima)
Questa funzionalità è disponibile in anteprima, a partire dalla versione 3.3.0.
Gli override del nome del ruolo cloud consentono di eseguire l'override del nome del ruolo cloud predefinito. È ad esempio possibile:
- Impostare un nome del ruolo cloud per un prefisso
/myapp1di percorso HTTP. - Impostare un altro nome del ruolo cloud per un altro prefisso
/myapp2/di percorso HTTP.
{
"preview": {
"roleNameOverrides": [
{
"httpPathPrefix": "/myapp1",
"roleName": "Role A"
},
{
"httpPathPrefix": "/myapp2",
"roleName": "Role B"
}
]
}
}
stringa di Connessione ion configurata in fase di esecuzione
A partire dalla versione 3.4.8, se è necessaria la possibilità di configurare il stringa di connessione in fase di esecuzione, aggiungere questa proprietà alla configurazione json:
{
"connectionStringConfiguredAtRuntime": true
}
Aggiungere applicationinsights-core all'applicazione:
<dependency>
<groupId>com.microsoft.azure</groupId>
<artifactId>applicationinsights-core</artifactId>
<version>3.5.2</version>
</dependency>
Usare il metodo statico configure(String) nella classe com.microsoft.applicationinsights.connectionstring.ConnectionString.
Nota
Tutti i dati di telemetria acquisiti prima di configurare il stringa di connessione verranno eliminati, pertanto è consigliabile configurarlo il prima possibile all'avvio dell'applicazione.
Dipendenze InProc incollect automatico (anteprima)
A partire dalla versione 3.2.0, se si vogliono acquisire le dipendenze del controller "InProc", usare la configurazione seguente:
{
"preview": {
"captureControllerSpans": true
}
}
Browser SDK Loader (anteprima)
Questa funzionalità inserisce automaticamente il caricatore dell'SDK del browser nelle pagine HTML dell'applicazione, inclusa la configurazione della stringa di Connessione ion appropriata.
Ad esempio, quando l'applicazione Java restituisce una risposta simile alla seguente:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Title</title>
</head>
<body>
</body>
</html>
Modifica automaticamente per restituire:
<!DOCTYPE html>
<html lang="en">
<head>
<script type="text/javascript">
!function(v,y,T){var S=v.location,k="script"
<!-- Removed for brevity -->
connectionString: "YOUR_CONNECTION_STRING"
<!-- Removed for brevity --> }});
</script>
<title>Title</title>
</head>
<body>
</body>
</html>
Lo script mira ad aiutare i clienti a tenere traccia dei dati utente Web e a inviare di nuovo i dati di telemetria lato server alle portale di Azure degli utenti. I dettagli sono disponibili in ApplicationInsights-JS.
Per abilitare questa funzionalità, aggiungere l'opzione di configurazione seguente:
{
"preview": {
"browserSdkLoader": {
"enabled": true
}
}
}
Processori di telemetria (anteprima)
È possibile usare i processori di telemetria per configurare le regole applicate ai dati di telemetria di richiesta, dipendenza e traccia. È ad esempio possibile:
- Mascherare i dati sensibili.
- Aggiungere in modo condizionale dimensioni personalizzate.
- Aggiornare il nome dell'intervallo, usato per aggregare dati di telemetria simili nella portale di Azure.
- Eliminare attributi di intervallo specifici per controllare i costi di inserimento.
Per altre informazioni, vedere la documentazione del processore di telemetria.
Nota
Per eliminare intervalli specifici (interi) per il controllo dei costi di inserimento, vedere Override del campionamento.
Strumentazione personalizzata (anteprima)
A partire dalla versione 3.3.1, è possibile acquisire intervalli per un metodo nell'applicazione:
{
"preview": {
"customInstrumentation": [
{
"className": "my.package.MyClass",
"methodName": "myMethod"
}
]
}
}
Registrazione automatica
Log4j, Logback, JBoss Logging e java.util.logging vengono gestiti automaticamente. La registrazione eseguita tramite questi framework di registrazione viene selezionata automaticamente.
La registrazione viene acquisita solo se:
- Soddisfa il livello configurato per il framework di registrazione.
- Soddisfa anche il livello configurato per Application Insights.
Ad esempio, se il framework di registrazione è configurato per registrare WARN (ed è stato configurato come descritto in precedenza) dal pacchetto com.examplee Application Insights è configurato per l'acquisizione INFO (e configurato come descritto), Application Insights acquisisce WARN (e più grave) dal pacchetto com.example.
Il livello predefinito configurato per Application Insights è INFO. Se si vuole modificare questo livello:
{
"instrumentation": {
"logging": {
"level": "WARN"
}
}
}
È anche possibile impostare il livello usando la variabile APPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_LEVELdi ambiente . Ha quindi la precedenza sul livello specificato nella configurazione JSON.
È possibile usare questi valori validi level per specificare nel applicationinsights.json file. La tabella mostra come corrispondono ai livelli di registrazione in framework di registrazione diversi.
| Level | Log4j | Logback | JBoss | LUG |
|---|---|---|---|---|
| OFF | OFF | OFF | OFF | OFF |
| FATALE | FATALE | ERROR | FATALE | SEVERE |
| ERROR (o edizione Standard VERE) | ERROR | ERROR | ERROR | SEVERE |
| WARN (o WARNING) | AVVERTIRE | AVVERTIRE | AVVERTIRE | AVVISO |
| INFO | INFO | INFO | INFO | INFO |
| CONFIG | DEBUG | DEBUG | DEBUG | CONFIG |
| DEBUG (o FINE) | DEBUG | DEBUG | DEBUG | FINE |
| FINER | DEBUG | DEBUG | DEBUG | FINER |
| TRACE (o FINEST) | TRACE | TRACE | TRACE | FINEST |
| ALL | ALL | ALL | ALL | ALL |
Nota
Se un oggetto eccezione viene passato al logger, il messaggio di log (e i dettagli dell'oggetto eccezione) verrà visualizzato nella portale di Azure sotto la tabella anziché nella exceptionstraces tabella. Per visualizzare i messaggi di log in entrambe le traces tabelle e exceptions , è possibile scrivere una query Logs (Kusto) per l'unione tra di esse. Ad esempio:
union traces, (exceptions | extend message = outerMessage)
| project timestamp, message, itemType
Marcatori di log (anteprima)
A partire dalla versione 3.4.2, è possibile acquisire i marcatori di log per Logback e Log4j 2:
{
"preview": {
"captureLogbackMarker": true,
"captureLog4jMarker": true
}
}
Altri attributi di log per Logback (anteprima)
A partire dalla versione 3.4.3, è possibile acquisire FileName, ClassName, MethodNamee LineNumberper Logback:
{
"preview": {
"captureLogbackCodeAttributes": true
}
}
Avviso
L'acquisizione degli attributi del codice potrebbe comportare un sovraccarico delle prestazioni.
Livello di registrazione come dimensione personalizzata
A partire dalla versione 3.3.0, LoggingLevel non viene acquisito per impostazione predefinita come parte della dimensione personalizzata Tracce perché tali dati sono già acquisiti nel SeverityLevel campo.
Se necessario, è possibile riabilitare temporaneamente il comportamento precedente:
{
"preview": {
"captureLoggingLevelAsCustomDimension": true
}
}
Metriche dei micrometri selezionati automaticamente (incluse le metriche dell'attuatore Spring Boot)
Se l'applicazione usa Micrometer, le metriche inviate al Registro di sistema globale Micrometer vengono raccolte automaticamente.
Inoltre, se l'applicazione usa l'attuatore Spring Boot, anche le metriche configurate dall'attuatore Spring Boot vengono recuperate automaticamente.
Per inviare metriche personalizzate usando micrometri:
Aggiungere Micrometer all'applicazione, come illustrato nell'esempio seguente.
<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-core</artifactId> <version>1.6.1</version> </dependency>Usare il Registro di sistema globale Micrometer per creare un contatore come illustrato nell'esempio seguente.
static final Counter counter = Metrics.counter("test.counter");Usare il contatore per registrare le metriche usando il comando seguente.
counter.increment();Le metriche vengono inserite nella tabella customMetrics , con tag acquisiti nella
customDimensionscolonna. È anche possibile visualizzare le metriche in Esplora metriche nello spazio dei nomi delleLog-based metricsmetriche.Nota
Application Insights Java sostituisce tutti i caratteri non alfanumerici (ad eccezione dei trattini) nel nome della metrica Micrometer con caratteri di sottolineatura. Di conseguenza, la metrica precedente
test.counterverrà visualizzata cometest_counter.
Per disabilitare la raccolta automatica delle metriche dei micrometri e delle metriche dell'attuatore Spring Boot:
Nota
Le metriche personalizzate vengono fatturate separatamente e possono generare costi aggiuntivi. Assicurarsi di controllare le informazioni sui prezzi. Per disabilitare le metriche Micrometer e Spring Boot Authentication, aggiungere la configurazione seguente al file di configurazione.
{
"instrumentation": {
"micrometer": {
"enabled": false
}
}
}
Maschera query di Connessione ivity del database Java
I valori letterali nelle query JDBC (Java Database Connessione ivity) vengono mascherati per impostazione predefinita per evitare di acquisire accidentalmente dati sensibili.
A partire dalla versione 3.4.0, questo comportamento può essere disabilitato. Ad esempio:
{
"instrumentation": {
"jdbc": {
"masking": {
"enabled": false
}
}
}
}
Maschera query Mongo
I valori letterali nelle query Mongo vengono mascherati per impostazione predefinita per evitare l'acquisizione accidentale dei dati sensibili.
A partire dalla versione 3.4.0, questo comportamento può essere disabilitato. Ad esempio:
{
"instrumentation": {
"mongo": {
"masking": {
"enabled": false
}
}
}
}
Intestazioni HTTP
A partire dalla versione 3.3.0, è possibile acquisire le intestazioni di richiesta e risposta nei dati di telemetria del server (richiesta):
{
"preview": {
"captureHttpServerHeaders": {
"requestHeaders": [
"My-Header-A"
],
"responseHeaders": [
"My-Header-B"
]
}
}
}
I nomi delle intestazioni non fanno distinzione tra maiuscole e minuscole.
Gli esempi precedenti vengono acquisiti con i nomi http.request.header.my_header_a delle proprietà e http.response.header.my_header_b.
Analogamente, è possibile acquisire le intestazioni di richiesta e risposta nei dati di telemetria del client (dipendenza):
{
"preview": {
"captureHttpClientHeaders": {
"requestHeaders": [
"My-Header-C"
],
"responseHeaders": [
"My-Header-D"
]
}
}
}
Anche in questo caso, i nomi delle intestazioni non fanno distinzione tra maiuscole e minuscole. Gli esempi precedenti vengono acquisiti con i nomi http.request.header.my_header_c delle proprietà e http.response.header.my_header_d.
Codici di risposta del server HTTP 4xx
Per impostazione predefinita, le richieste del server HTTP che generano codici di risposta 4xx vengono acquisite come errori.
A partire dalla versione 3.3.0, è possibile modificare questo comportamento per acquisirli come esito positivo:
{
"preview": {
"captureHttpServer4xxAsError": false
}
}
Eliminare dati di telemetria specifici di cui è stata selezionata l'associazione automatica
A partire dalla versione 3.0.3, è possibile eliminare specifici dati di telemetria con raccolta automatica usando queste opzioni di configurazione:
{
"instrumentation": {
"azureSdk": {
"enabled": false
},
"cassandra": {
"enabled": false
},
"jdbc": {
"enabled": false
},
"jms": {
"enabled": false
},
"kafka": {
"enabled": false
},
"micrometer": {
"enabled": false
},
"mongo": {
"enabled": false
},
"quartz": {
"enabled": false
},
"rabbitmq": {
"enabled": false
},
"redis": {
"enabled": false
},
"springScheduling": {
"enabled": false
}
}
}
È anche possibile eliminare queste strumentazioni impostando queste variabili di ambiente su false:
APPLICATIONINSIGHTS_INSTRUMENTATION_AZURE_SDK_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_CASSANDRA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JDBC_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JMS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_KAFKA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MICROMETER_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MONGO_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_RABBITMQ_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_REDIS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_SPRING_SCHEDULING_ENABLED
Queste variabili hanno quindi la precedenza sulle variabili abilitate specificate nella configurazione JSON.
Nota
Se si sta cercando un controllo più granulare, ad esempio per eliminare alcune chiamate Redis ma non tutte le chiamate Redis, vedere Override del campionamento.
Anteprime strumentazioni
A partire dalla versione 3.2.0, è possibile abilitare le strumentazioni di anteprima seguenti:
{
"preview": {
"instrumentation": {
"akka": {
"enabled": true
},
"apacheCamel": {
"enabled": true
},
"grizzly": {
"enabled": true
},
"ktor": {
"enabled": true
},
"play": {
"enabled": true
},
"r2dbc": {
"enabled": true
},
"springIntegration": {
"enabled": true
},
"vertx": {
"enabled": true
}
}
}
}
Nota
La strumentazione Akka è disponibile a partire dalla versione 3.2.2. La strumentazione della libreria HTTP Vertx è disponibile a partire dalla versione 3.3.0.
Intervallo metrico
Per impostazione predefinita, le metriche vengono acquisite ogni 60 secondi.
A partire dalla versione 3.0.3, è possibile modificare questo intervallo:
{
"metricIntervalSeconds": 300
}
A partire dalla versione 3.4.9 ga, è anche possibile impostare metricIntervalSeconds usando la variabile APPLICATIONINSIGHTS_METRIC_INTERVAL_SECONDSdi ambiente . Ha quindi la precedenza sull'oggetto metricIntervalSeconds specificato nella configurazione JSON.
L'impostazione si applica alle metriche seguenti:
- Contatori delle prestazioni predefiniti: ad esempio, CPU e memoria
- Metriche personalizzate predefinite: ad esempio, temporizzazione di Garbage Collection
- Metriche JMX configurate: vedere la sezione metrica JMX
- Metriche dei micrometri: vedere la sezione Metriche del micrometro con registrazione automatica
Heartbeat
Per impostazione predefinita, Application Insights Java 3.x invia una metrica heartbeat ogni 15 minuti. Se si usa la metrica heartbeat per attivare gli avvisi, è possibile aumentare la frequenza di questo heartbeat:
{
"heartbeat": {
"intervalSeconds": 60
}
}
Nota
Non è possibile aumentare l'intervallo fino a più di 15 minuti perché i dati heartbeat vengono usati anche per tenere traccia dell'utilizzo di Application Insights.
Autenticazione
Nota
La funzionalità di autenticazione è disponibile a livello generale dalla versione 3.4.17.
È possibile usare l'autenticazione per configurare l'agente per generare le credenziali del token necessarie per l'autenticazione di Microsoft Entra. Per altre informazioni, vedere la documentazione relativa all'autenticazione.
Proxy HTTP
Se l'applicazione si trova dietro un firewall e non può connettersi direttamente ad Application Insights, fare riferimento agli indirizzi IP usati da Application Insights.
Per risolvere questo problema, è possibile configurare Application Insights Java 3.x per l'uso di un proxy HTTP.
{
"proxy": {
"host": "myproxy",
"port": 8080
}
}
È anche possibile impostare il proxy HTTP usando la variabile APPLICATIONINSIGHTS_PROXYdi ambiente , che accetta il formato https://<host>:<port>. Ha quindi la precedenza sul proxy specificato nella configurazione JSON.
Application Insights Java 3.x rispetta anche le proprietà globali https.proxyHost e https.proxyPort di sistema, se impostate, e http.nonProxyHosts, se necessario.
Ripristino da errori di inserimento
Quando si inviano dati di telemetria al servizio Application Insights non riesce, Application Insights Java 3.x archivia i dati di telemetria sul disco e continua a ripetere i tentativi dal disco.
Il limite predefinito per la persistenza del disco è 50 MB. Se si dispone di un volume di telemetria elevato o se è necessario essere in grado di eseguire il ripristino da interruzioni del servizio di inserimento o rete più lunghe, è possibile aumentare questo limite a partire dalla versione 3.3.0:
{
"preview": {
"diskPersistenceMaxSizeMb": 50
}
}
Auto-diagnostica
"Diagnostica automatica" si riferisce alla registrazione interna da Application Insights Java 3.x. Questa funzionalità può essere utile per individuare e diagnosticare i problemi con Application Insights stesso.
Per impostazione predefinita, Application Insights Java 3.x registra a livello INFO sia il file applicationinsights.log che la console, corrispondente a questa configurazione:
{
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}
Nell'esempio di configurazione precedente:
levelpuò essere uno diOFF,ERRORWARN,INFO, ,DEBUGoTRACE.pathpuò essere un percorso assoluto o relativo. I percorsi relativi vengono risolti nella directory in cuiapplicationinsights-agent-3.5.2.jarsi trova.
A partire dalla versione 3.0.2, è anche possibile impostare la diagnostica automatica level usando la variabile APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_LEVELdi ambiente . Ha quindi la precedenza sul livello di auto-diagnostica specificato nella configurazione JSON.
A partire dalla versione 3.0.3, è anche possibile impostare il percorso del file di diagnostica automatica usando la variabile APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_FILE_PATHdi ambiente . Ha quindi la precedenza sul percorso del file di diagnostica automatica specificato nella configurazione JSON.
Esempio
Questo esempio mostra l'aspetto di un file di configurazione con più componenti. Configurare opzioni specifiche in base alle esigenze.
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
},
"sampling": {
"percentage": 100
},
"jmxMetrics": [
],
"customDimensions": {
},
"instrumentation": {
"logging": {
"level": "INFO"
},
"micrometer": {
"enabled": true
}
},
"proxy": {
},
"preview": {
"processors": [
]
},
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}