Spiegazione dell'aggregazione e della visualizzazione delle metriche di Monitoraggio di Azure
Questo articolo illustra l'aggregazione delle metriche nel database time series di Monitoraggio di Azure che esegue il backup delle metriche della piattaforma di Monitoraggio di Azure e delle metriche personalizzate. Questo articolo si applica anche alle metriche standard di Application Insights.
Il contenuto di questo articolo è complesso per natura e non è necessario comprendere l'uso efficace delle metriche di Monitoraggio di Azure.
Panoramica e termini
Quando si aggiunge una metrica a un grafico, Esplora metriche pre-seleziona automaticamente l'aggregazione predefinita. L'impostazione predefinita ha senso negli scenari di base, ma è possibile usare aggregazioni diverse per ottenere altre informazioni dettagliate sulla metrica. Per visualizzare aggregazioni diverse in un grafico è necessario comprendere il modo in cui Esplora metriche li gestisce.
Definiamo prima di tutto alcuni termini:
- Valore metrico: valore di misura singolo raccolto per una risorsa specifica.
- Database Time Series : un database ottimizzato per l'archiviazione e il recupero di punti dati contenenti tutti un valore e un timestamp corrispondente.
- Periodo di tempo: un periodo di tempo generico.
- Intervallo di tempo: periodo di tempo tra la raccolta di due valori delle metriche.
- Intervallo di tempo: periodo di tempo visualizzato in un grafico. Il valore predefinito tipico è 24 ore. Sono disponibili solo intervalli specifici.
- Granularità temporale o granularità temporale: periodo di tempo usato per aggregare i valori insieme per consentire la visualizzazione in un grafico. Sono disponibili solo intervalli specifici. Il minimo corrente è 1 minuto. Il valore di granularità temporale deve essere inferiore all'intervallo di tempo selezionato per essere utile. In caso contrario, viene visualizzato un solo valore per l'intero grafico.
- Tipo di aggregazione: tipo di statistica calcolata da più valori di metrica.
- Aggregazione : processo di acquisizione di più valori di input e quindi uso di tali valori per produrre un singolo valore di output tramite le regole definite dal tipo di aggregazione. Ad esempio, accettando una media di più valori.
Riepilogo del processo
Le metriche sono una serie di valori archiviati con un timestamp. In Azure la maggior parte delle metriche viene archiviata nel database time series delle metriche di Azure. Quando si traccia un grafico, i valori delle metriche selezionate vengono recuperati dal database e quindi aggregati separatamente in base alla granularità del tempo scelta (nota anche come intervallo di tempo). È possibile selezionare le dimensioni della granularità temporale usando la selezione ora di Esplora metriche. Se non si effettua una selezione esplicita, la granularità temporale viene selezionata automaticamente in base all'intervallo di tempo attualmente selezionato. Dopo aver selezionato, i valori delle metriche acquisiti durante ogni intervallo di granularità temporale vengono aggregati e inseriti nel grafico, ovvero un punto dati per intervallo.
Tipi di aggregazione
In Esplora metriche sono disponibili cinque tipi di aggregazione di base. Esplora metriche nasconde le aggregazioni irrilevanti e non può essere usata per una determinata metrica.
- Somma : somma di tutti i valori acquisiti nell'intervallo di aggregazione. Talvolta definita aggregazione Totale.
- Conteggio : numero di misurazioni acquisite nell'intervallo di aggregazione. Count non esamina il valore della misura, ma solo il numero di record.
- Media : media dei valori delle metriche acquisiti nell'intervallo di aggregazione. Per la maggior parte delle metriche, questo valore è Sum/Count.
- Min : il valore più piccolo acquisito nell'intervallo di aggregazione.
- Max : il valore più grande acquisito nell'intervallo di aggregazione.
Si supponga, ad esempio, che un grafico mostri la metrica Network Out Total per una macchina virtuale usando l'aggregazione SUM nell'intervallo di tempo di 24 ore. L'intervallo di tempo e la granularità possono essere modificati dall'alto a destra del grafico, come illustrato nello screenshot seguente.
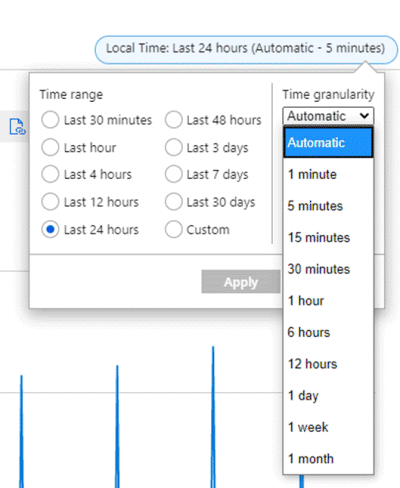
Per la granularità temporale = 30 minuti e l'intervallo di tempo = 24 ore:
- Il grafico viene disegnato da 48 punti dati. Ovvero 24 ore x 2 punti dati all'ora (60 minuti/30 minuti) aggregati di punti dati di 1 minuto.
- Il grafico a linee connette 48 punti nell'area del tracciato grafico.
- Ogni punto dati rappresenta la somma di tutti i byte di rete inviati durante ogni periodo di tempo di 30 minuti pertinente.

Fare clic sulle immagini in questa sezione per visualizzare le versioni più grandi.
Se si passa la granularità temporale a 15 minuti, il grafico viene disegnato da 96 punti dati aggregati. Ovvero, 60min/15min = 4 punti dati all'ora x 24 ore.

Per la granularità temporale di 5 minuti, si ottiene 24 x (60/5) = 288 punti.
Per la granularità temporale di 1 minuto (il più piccolo possibile nel grafico), si ottiene 24 x 60/1 = 1440 punti.

I grafici hanno un aspetto diverso per queste sommazioni, come illustrato negli screenshot precedenti. Si noti che questa macchina virtuale ha numerosi output in un piccolo periodo di tempo rispetto al resto dell'intervallo di tempo.
La granularità temporale consente di regolare il rapporto "segnale-rumore" in un grafico. Le aggregazioni più elevate rimuovono il rumore e smussano i picchi. Si notino le variazioni nel grafico inferiore di 1 minuto e come si uniformano man mano che si passa a valori di granularità più elevati.
Questo comportamento di smoothing è importante quando si inviano questi dati ad altri sistemi, ad esempio avvisi. In genere, in genere non si vuole ricevere avvisi da picchi brevi nel tempo di CPU oltre il 90%. Ma se la CPU rimane al 90% per 5 minuti, questo è probabilmente importante. Se si configura una regola di avviso sulla CPU (o su qualsiasi metrica), la granularità del tempo può ridurre il numero di falsi avvisi ricevuti.
È importante stabilire ciò che è "normale" per il carico di lavoro per sapere qual è l'intervallo di tempo migliore. Questo è uno dei vantaggi degli avvisi dinamici, che è un argomento diverso non trattato qui.
Come il sistema raccoglie le metriche
La raccolta dei dati varia in base alla metrica.
Nota
Gli esempi seguenti sono semplificati per l'illustrazione e i dati delle metriche effettivi inclusi in ogni aggregazione sono interessati dai dati disponibili quando si verifica la valutazione.
Frequenza raccolta misurazioni
Esistono due tipi di periodi di raccolta.
Regolare: la metrica viene raccolta a un intervallo di tempo coerente che non varia.
Basato sull'attività : la metrica viene raccolta in base a quando si verifica una transazione di un determinato tipo. Ogni transazione ha una voce di metrica e un timestamp. Non vengono raccolti a intervalli regolari, quindi esiste un numero variabile di record in un determinato periodo di tempo.
Granularità
La granularità minima del tempo è di 1 minuto, ma il sistema sottostante può acquisire i dati più velocemente a seconda della metrica. Ad esempio, la percentuale di CPU per una macchina virtuale di Azure viene acquisita a intervalli di tempo di 15 secondi. Poiché gli errori HTTP vengono rilevati come transazioni, possono superare facilmente più di un minuto. Altre metriche, ad esempio SQL Archiviazione, vengono acquisite a intervalli di tempo di ogni 20 minuti. Questa scelta spetta al singolo provider di risorse e al tipo. La maggior parte dei tentativi di fornire l'intervallo di tempo più piccolo possibile.
Dimensioni, suddivisione e filtro
Le metriche vengono acquisite per ogni singola risorsa. Tuttavia, il livello in cui le metriche vengono raccolte, archiviate e in grado di essere tracciate può variare. Questo livello è rappresentato da altre metriche disponibili nelle dimensioni delle metriche. Ogni singolo provider di risorse ottiene per definire il modo in cui vengono dettagliati i dati raccolti. Monitoraggio di Azure definisce solo la modalità di presentazione e archiviazione di tali dettagli.
Quando si crea un grafico di una metrica in Esplora metriche, è possibile "dividere" il grafico in base a una dimensione. La suddivisione di un grafico significa che si stanno esaminando i dati sottostanti per ottenere maggiori dettagli e visualizzare i dati grafici o filtrati in Esplora metriche.
Ad esempio, Microsoft.ApiManagement/service ha Location come dimensione per molte metriche.
La capacità è una di queste metriche. La dimensione Location implica che il sistema sottostante archivia un record di metrica per la capacità di ogni posizione, anziché solo uno per la quantità di aggregazione. È quindi possibile recuperare o suddividere tali informazioni in un grafico delle metriche.
Esaminando la durata complessiva delle richieste del gateway, sono presenti 2 dimensioni Location e Hostname, per segnalare di nuovo la posizione di una durata e il nome host da cui proviene.
Una delle metriche più flessibili, Richieste, ha 7 dimensioni diverse.
Per informazioni dettagliate su ogni metrica e sulle dimensioni disponibili, vedere l'articolo Metriche di Monitoraggio di Azure. Inoltre, la documentazione per ogni provider di risorse e tipo può fornire informazioni aggiuntive sulle dimensioni e sulle misure.
È possibile usare la suddivisione e il filtro insieme per esaminare un problema. Di seguito è riportato un esempio di immagine che mostra i byte di scrittura del disco medio per un gruppo di macchine virtuali in un gruppo di risorse. È disponibile un rollup di tutte le macchine virtuali con questa metrica, ma è possibile esaminare quali sono i picchi intorno alle 6:00. Sono la stessa macchina? Quanti computer sono coinvolti?

Fare clic sulle immagini in questa sezione per visualizzare le versioni più grandi.
Quando si applica la suddivisione, è possibile visualizzare i dati sottostanti, ma si tratta di un po' di confusione. Si scopre che nel grafico precedente sono presenti 20 macchine virtuali. In questo caso, è stato usato il mouse per passare il puntatore del mouse sopra il picco di grandi dimensioni alle 6:00 che indica che CH-DCVM11 è la causa. Tuttavia, è difficile visualizzare il resto dei dati associati a tale macchina virtuale a causa di altre macchine virtuali che ingombrano il grafico.

L'uso del filtro consente di pulire il grafico per vedere cosa sta realmente accadendo. È possibile controllare o deselezionare le macchine virtuali da visualizzare. Si notino le linee tratteggiate. Queste sono menzionate in una sezione successiva.

Per altre informazioni su come visualizzare i dati di divisione delle dimensioni in un grafico esplora metriche, vedere Funzionalità avanzate di Esplora metriche- filtri e suddivisione.
Valori NULL e zero
Quando il sistema prevede i dati delle metriche da una risorsa ma non lo riceve, registra un valore NULL. NULL è diverso da un valore zero, che diventa importante nel calcolo delle aggregazioni e del grafico. I valori NULL non vengono conteggiati come misurazioni valide.
I valori NULL vengono visualizzati in modo diverso in grafici diversi. I grafici a dispersione ignorano la visualizzazione di un punto nel grafico. I grafici a barre ignorano la visualizzazione della barra. Nei grafici a linee, NULL può essere visualizzato come linee tratteggiate o tratteggiate come quelle visualizzate nello screenshot nella sezione precedente. Quando si calcolano le medie che includono valori NULL, sono presenti meno punti dati da cui prendere la media. Questo comportamento può talvolta comportare un calo imprevisto dei valori in un grafico, anche se inferiore a se il valore è stato convertito in zero e usato come punto dati valido.
Le metriche personalizzate usano sempre valori NULL quando non vengono ricevuti dati. Con le metriche della piattaforma, ogni provider di risorse decide se usare zeri o valori NULL in base a ciò che ha più senso per una determinata metrica.
Gli avvisi di Monitoraggio di Azure usano i valori scritti dal provider di risorse nel database delle metriche, quindi è importante sapere in che modo il provider di risorse gestisce i valori nulli visualizzando prima i dati.
Funzionamento dell'aggregazione
I grafici delle metriche nel sistema precedente mostrano diversi tipi di dati aggregati. Il sistema preaggrega i dati in modo che i grafici richiesti possano visualizzare più rapidamente senza molti calcoli ripetuti.
In questo esempio:
- Viene raccolta una metrica transazionale fittizia denominata errori HTTP
- Il server è una dimensione per la metrica degli errori HTTP.
- Sono disponibili 3 server: Server A, B e C.
Per semplificare la spiegazione, iniziamo solo con il tipo di aggregazione SUM.
Aggregazione da sotto minuti a 1 minuto
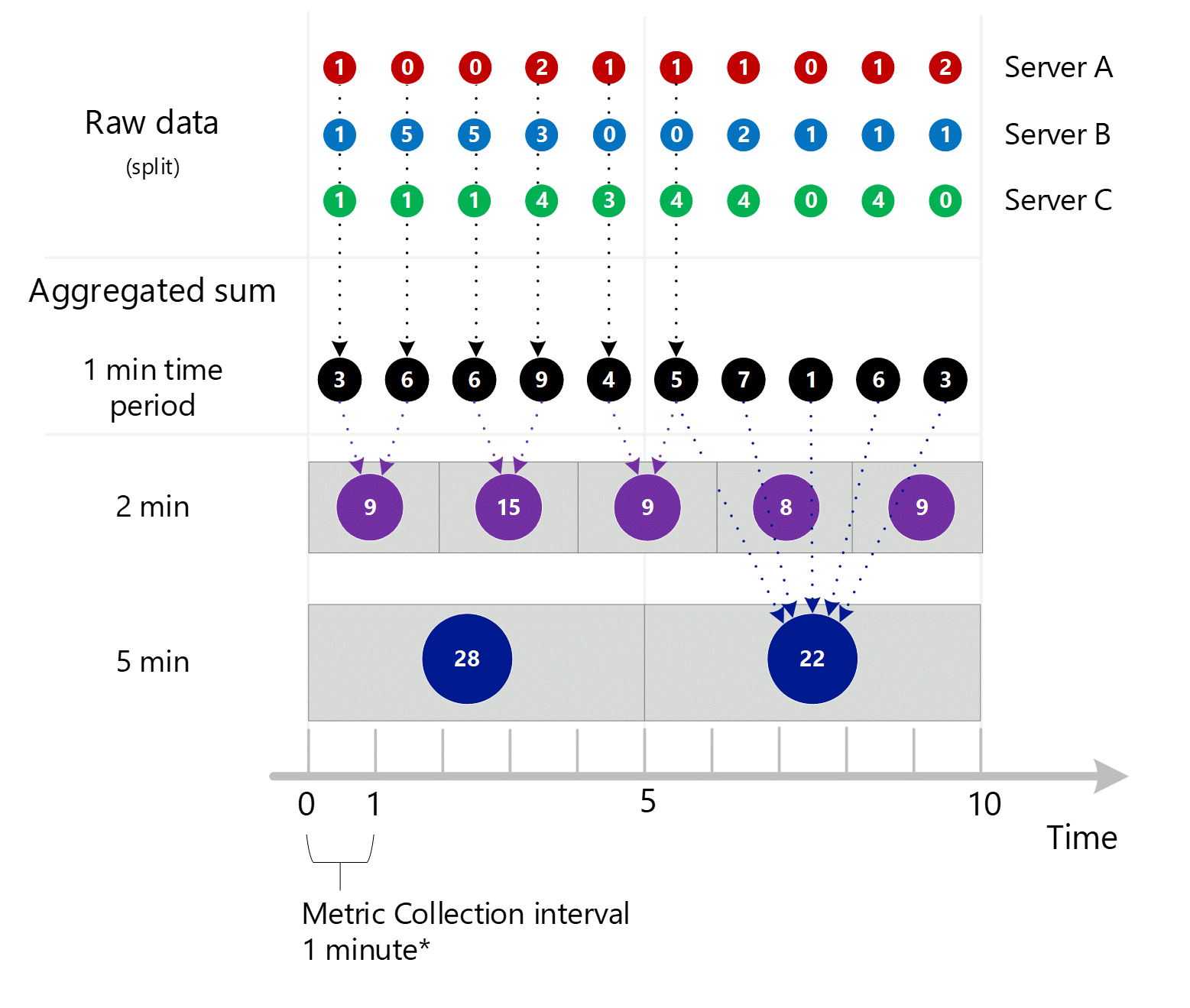
I primi dati delle metriche non elaborati vengono raccolti e archiviati nel database delle metriche di Monitoraggio di Azure. In questo caso, ogni server dispone di record delle transazioni archiviati con un timestamp perché Server è una dimensione. Dato che il periodo di tempo più piccolo che è possibile visualizzare come cliente è di 1 minuto, tali timestamp vengono prima aggregati in valori di metrica di 1 minuto per ogni singolo server. Il processo di aggregazione per il server B è illustrato nell'immagine seguente. I server A e C vengono eseguiti nello stesso modo e hanno dati diversi.
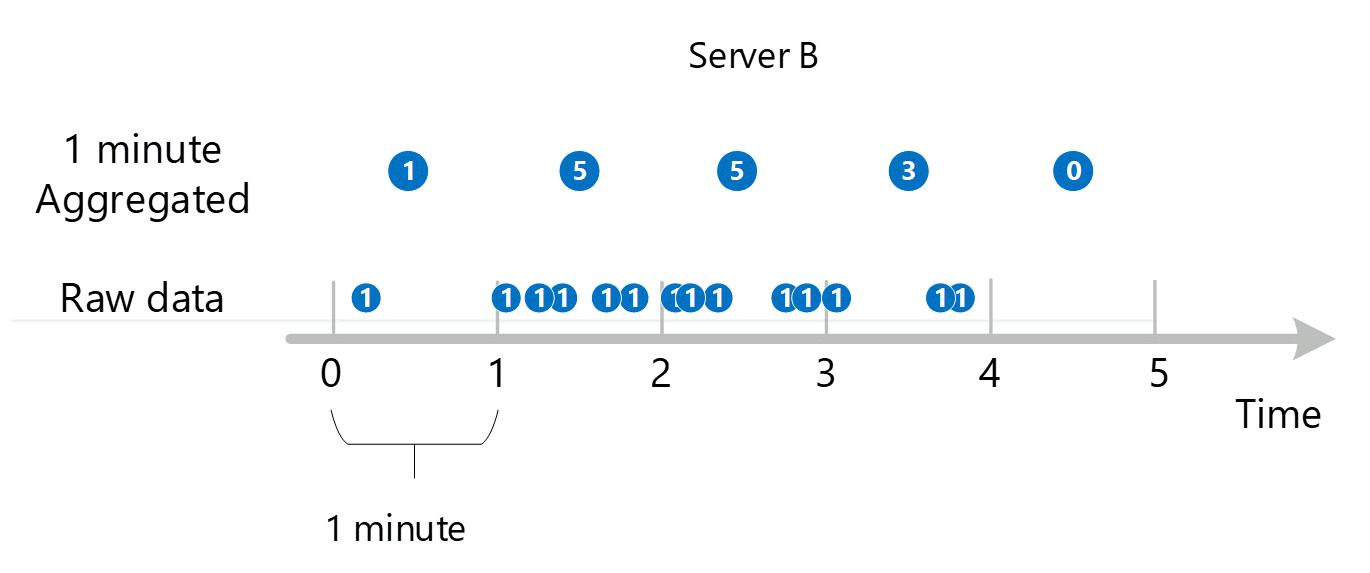
I valori aggregati di 1 minuto risultanti vengono archiviati come nuove voci nel database delle metriche in modo che possano essere raccolti per calcoli successivi.
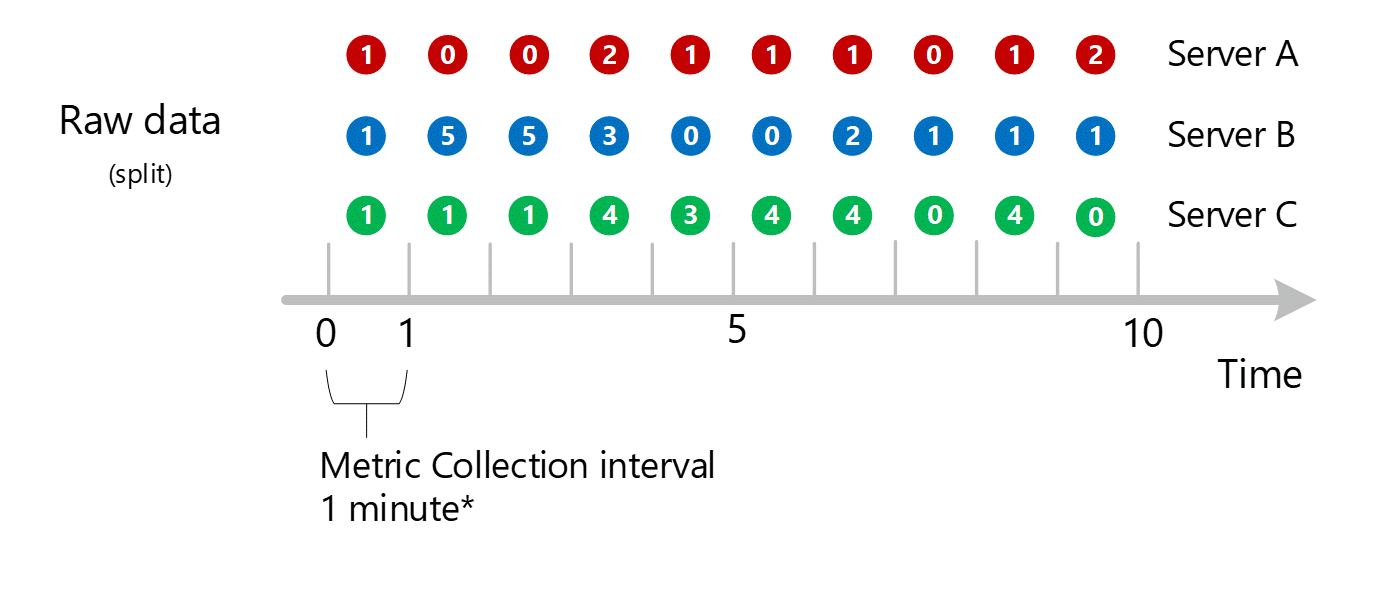
Aggregazione delle dimensioni
I calcoli di 1 minuto vengono quindi compressi per dimensione e archiviati di nuovo come singoli record. In questo caso, tutti i dati di tutti i singoli server vengono aggregati in una metrica di intervallo di 1 minuto e archiviati nel database delle metriche per l'uso nelle aggregazioni successive.

Per maggiore chiarezza, nella tabella seguente viene illustrato il metodo di aggregazione.
| Periodo | Server A | Server B | Server C | Somma (A+B+C) |
|---|---|---|---|---|
| Minuto 1 | 1 | 1 | 1 | 3 |
| Minuto 2 | 0 | 5 | 1 | 6 |
| Minuto 3 | 0 | 5 | 1 | 6 |
| Minuto 4 | 2 | 3 | 4 | 9 |
| Minuto 5 | 1 | 0 | 3 | 4 |
| Minuto 6 | 1 | 0 | 4 | 5 |
| Minuto 7 | 1 | 2 | 4 | 7 |
| Minuto 8 | 0 | 1 | 0 | 1 |
| Minuto 9 | 1 | 1 | 4 | 6 |
| Minuto 10 | 2 | 1 | 0 | 3 |
In precedenza è illustrata una sola dimensione, ma questo stesso processo di aggregazione e archiviazione si verifica per tutte le dimensioni supportate da una metrica.
- Raccogliere i valori in un set aggregato di 1 minuto in base a tale dimensione. Archiviare tali valori.
- Comprimere la dimensione in una somma aggregata di 1 minuto. Archiviare tali valori.
Verrà ora introdotta un'altra dimensione di errori HTTP denominata NetworkAdapter. Si supponga di avere un numero variabile di schede per server.
- Il server A ha 1 adattatore
- Il server B dispone di 2 schede
- Il server C dispone di 3 schede
Raccoglieremo i dati per le transazioni seguenti separatamente. Verranno contrassegnati con:
- Un'ora
- Valore .
- Il server da cui proviene la transazione
- Adattatore da cui proviene la transazione
Ognuno di questi flussi secondari verrà quindi aggregato in valori di serie temporali di 1 minuto e archiviati nel database delle metriche di Monitoraggio di Azure:
- Server A, adapter 1
- Server B, adapter 1
- Server B, adapter 2
- Server C, adapter 1
- Server C, adapter 2
- Server C, Adapter 3
Inoltre, vengono archiviate anche le aggregazioni compresse seguenti:
- Server A, Adapter 1 (perché non c'è nulla da comprimere, verrà archiviato di nuovo)
- Server B, adapter 1+2
- Server C, adapter 1+2+3
- Server ALL, Adapters ALL
Ciò mostra che le metriche con un numero elevato di dimensioni hanno un numero maggiore di aggregazioni. Non è importante conoscere tutte le permutazioni, ma solo comprendere il ragionamento. Il sistema vuole avere sia i singoli dati che i dati aggregati archiviati per il recupero rapido per l'accesso in qualsiasi grafico. Il sistema seleziona l'aggregazione archiviata più rilevante o i dati non elaborati sottostanti a seconda di ciò che si sceglie di visualizzare.
Aggregazione senza dimensioni
Poiché questa metrica ha un server di dimensioni, è possibile accedere ai dati sottostanti per il server A, B e C sopra tramite suddivisione e filtro, come illustrato in precedenza in questo articolo. Se la metrica non ha server come dimensione, il cliente può accedere solo alle somme aggregate di 1 minuto visualizzate in nero nel diagramma. Ovvero, i valori di 3, 6, 6, 9 e così via. Il sistema non eseguirà anche il lavoro sottostante per aggregare valori suddivisi che non li userebbe mai in Esplora metriche o inviarli tramite l'API REST delle metriche.
Visualizzazione delle granularità temporali superiori a 1 minuto
Se si richiedono metriche con una granularità maggiore, il sistema usa le somme aggregate di 1 minuto per calcolare le somme per le granularità temporali più elevate. Di seguito, le linee tratteggiate mostrano il metodo di somma per le granularità di tempo di 2 minuti e 5 minuti. Anche in questo caso, viene visualizzato solo il tipo di aggregazione SUM per semplicità.
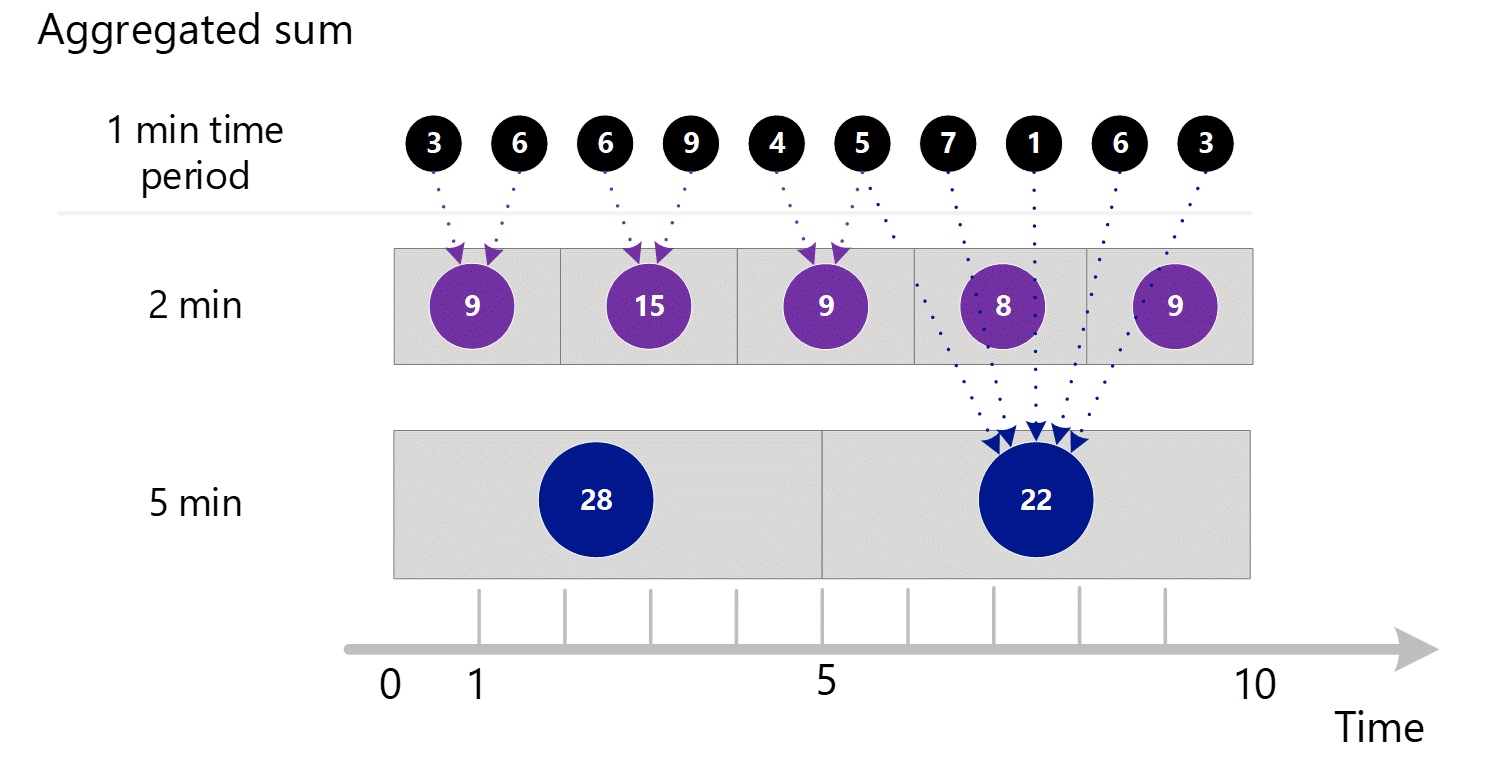
Per la granularità di 2 minuti.
| Periodo | Somme |
|---|---|
| Minuto 1 e 2 | (3 + 6) = 9 |
| Minuto 3 e 4 | (6 + 9) = 15 |
| Minuto 4 e 5 | (4 + 5) = 9 |
| Minuto 6 e 7 | (7 + 1) = 8 |
| Minuto 8 e 9 | (6 + 3) = 9 |
Per una granularità di 5 minuti.
| Periodo | Somme |
|---|---|
| Minuto da 1 a 5 | 3 + 6 + 6 + 9 + 4 = 28 |
| Minuto da 6 a 10 | 5 + 7 + 1 + 6 + 3 = 22 |
Il sistema usa i dati aggregati archiviati che offrono prestazioni ottimali.
Di seguito è riportato il diagramma più ampio del processo di aggregazione di 1 minuto, con alcune delle frecce lasciate per migliorare la leggibilità.
Esempio più complesso
Di seguito è riportato un esempio più ampio che usa i valori per una metrica fittizia denominata Tempo di risposta HTTP in millisecondi. Qui introduciamo altri livelli di complessità.
- Viene mostrata l'aggregazione per Sum, Count, Min e Max e il calcolo per Average.
- Vengono mostrati i valori NULL e il modo in cui influiscono sui calcoli.
Si consideri l'esempio seguente. Le caselle e le frecce mostrano esempi di come vengono aggregati e calcolati i valori.
Lo stesso processo di preaggregazione di 1 minuto descritto nella sezione precedente si verifica per Sum, Count, Minimum e Maximum. Tuttavia, average is NOT pre-aggregated. Viene ricalcolato usando dati aggregati per evitare errori di calcolo.

Prendere in considerazione il minuto 6 per l'aggregazione di 1 minuto come evidenziato in precedenza. Questo minuto è il punto in cui il server B è andato offline e ha interrotto i dati dei report, forse a causa di un riavvio.
Dal minuto 6 precedente, i tipi di aggregazione calcolati di 1 minuto sono:
| Tipo di aggregazione | Valore | Note |
|---|---|---|
| Sum | 53+20=73 | |
| Conteggio | 2 | Mostra l'effetto dei valori NULL. Il valore sarebbe stato 3 se il server fosse online. |
| Requisiti minimi | 20 | |
| Massimo | 53 | |
| Media | 73 / 2 | Sempre la somma divisa per il conteggio. Non viene mai archiviato e sempre ricalcolato per ogni granularità temporale usando i numeri aggregati per tale granularità. Si noti il ricalcolo per le granularità di tempo di 5 minuti e 10 minuti, come evidenziato in precedenza. |
Il colore del testo rosso indica i valori che potrebbero essere considerati fuori dall'intervallo normale e mostra come si propagano (o non riescono) man mano che la granularità del tempo sale. Si noti come mine max indicano che ci sono anomalie sottostanti mentre mediae somme perdono tali informazioni man mano che la granularità del tempo sale.
È anche possibile notare che gli NUL forniscono un calcolo migliore della media rispetto a se invece sono stati usati zeri.
Nota
Anche se non nel caso di questo esempio, Count è uguale a Sum nei casi in cui una metrica viene sempre acquisita con il valore 1. Ciò è comune quando una metrica tiene traccia dell'occorrenza di un evento transazionale, ad esempio il numero di errori HTTP indicati in un esempio precedente in questo articolo.