Panoramica del modello di acquisto basato su DTU
Si applica a:![]() database SQL di Azure
database SQL di Azure
Questo articolo illustra il modello di acquisto basato su DTU per database SQL di Azure.
Per altre informazioni, vedere il modello di acquisto basato su vCore e confrontare i modelli di acquisto.
Unità di transazione di database (DTU)
L'unità di transazione di database (Data Transmission Unit, DTU) rappresenta una misura combinata di CPU, memoria e operazioni di lettura e scrittura. I livelli di servizio nel modello di acquisto basato su DTU sono differenziati in base a una gamma di dimensioni di calcolo con una quantità fissa di spazio di archiviazione incluso, un periodo di conservazione fisso per i backup e un prezzo fisso. Tutti i livelli di servizio nel modello di acquisto basato su DTU offrono flessibilità di modifica delle dimensioni di calcolo con tempi di inattività minimi. Tuttavia, esiste un passaggio nel periodo in cui la connettività viene persa al database per un breve periodo di tempo, che può essere mitigata usando la logica di ripetizione dei tentativi. La fatturazione per i database singoli e i pool elastici viene effettuata con frequenza oraria in base al livello di servizio e alle dimensioni di calcolo.
Per un database singolo con dimensioni di calcolo specifiche all'interno di un livello di servizio, database SQL di Azure garantisce un determinato livello di risorse per tale database (indipendentemente da qualsiasi altro database). Questa garanzia garantisce un livello prevedibile di prestazioni. La quantità di risorse allocate per un database viene calcolata come numero di DTU ed è una misura in bundle delle risorse di calcolo, archiviazione e I/O.
Il rapporto tra queste risorse è originariamente determinato da un carico di lavoro di benchmark OLTP (Online Transaction Processing) progettato per essere tipico di carichi di lavoro OLTP reali. Quando il carico di lavoro supera la quantità di queste risorse, la velocità effettiva viene limitata, con conseguente rallentamento delle prestazioni e dei timeout.
Per i database singoli, le risorse usate dal carico di lavoro non influiscono sulle risorse disponibili per altri database nel cloud di Azure. Analogamente, le risorse usate da altri carichi di lavoro non influiscono sulle risorse disponibili per il database.
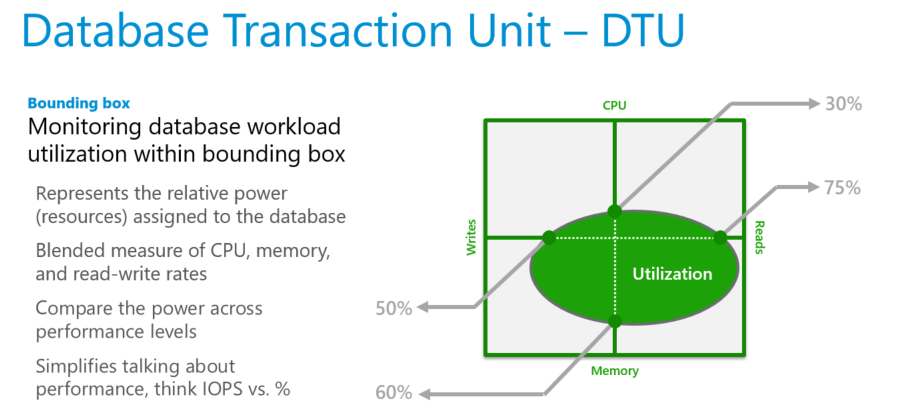
Le DTU sono più utili per comprendere le risorse relative allocate per i database con dimensioni di calcolo e livelli di servizio diversi. Ad esempio:
- Raddoppiare le DTU aumentando le dimensioni di calcolo di un database equivale al raddoppio del set di risorse disponibili per tale database.
- Un database P11 di livello di servizio Premium con 1750 DTU offre una potenza di calcolo DTU di 350 volte superiore rispetto a un database di livello di servizio di base con 5 DTU.
Per ottenere informazioni più approfondite sul consumo di risorse (DTU) del carico di lavoro, usare informazioni dettagliate sulle prestazioni delle query per:
- Identificare le query principali in base al numero di CPU/durata/esecuzione che possono essere potenzialmente ottimizzate per migliorare le prestazioni. Ad esempio, una query con utilizzo intensivo di I/O può trarre vantaggio dalle tecniche di ottimizzazione in memoria per usare meglio la memoria disponibile a un determinato livello di servizio e dimensioni di calcolo.
- Eseguire il drill-down nei dettagli di una query per visualizzarne il testo e la cronologia dell'utilizzo delle risorse.
- Visualizzare le raccomandazioni per l'ottimizzazione delle prestazioni che mostrano le azioni eseguite da database SQL Advisor.
Unità di transazione di database elastico (eDTU)
Anziché fornire un set dedicato di risorse (DTU) che potrebbero non essere sempre necessarie, è possibile inserire questi database in un pool elastico. I database in un pool elastico usano una singola istanza del motore di database e condividono lo stesso pool di risorse.
Le risorse condivise in un pool elastico vengono misurate da unità di transazione di database elastiche (eDTU). I pool elastici offrono una soluzione semplice e conveniente per gestire gli obiettivi di prestazioni per più database con modelli di utilizzo ampiamente variabili e imprevedibili. Un pool elastico garantisce che tutte le risorse non possano essere utilizzate da un database nel pool, garantendo al contempo che ogni database nel pool disponga sempre di una quantità minima di risorse necessarie.
A un pool viene assegnato un numero definito di eDTU per un prezzo prestabilito. Nel pool elastico i singoli database possono essere ridimensionati automaticamente entro i limiti configurati. Un database con un carico più pesante utilizza più eDTU per soddisfare la domanda. I database con carichi più leggeri utilizzano meno eDTU. I database senza carico non utilizzano eDTU. Poiché viene effettuato il provisioning delle risorse per l'intero pool, anziché per ogni database, i pool elastici semplificano le attività di gestione e forniscono un budget prevedibile per il pool.
È possibile aggiungere altre eDTU a un pool esistente con tempi di inattività minimi del database. Analogamente, se non sono più necessarie eDTU aggiuntive, rimuoverle da un pool esistente in qualsiasi momento. È anche possibile aggiungere o rimuovere database da un pool in qualsiasi momento. Per riservare eDTU per altri database, limitare il numero di database eDTU che possono essere usati con un carico elevato. Se un database ha un utilizzo costantemente elevato delle risorse che influisce su altri database nel pool, spostarlo all'esterno del pool e configurarlo come database singolo con una quantità prevedibile di risorse necessarie.
Carichi di lavoro che traggono vantaggio da un pool elastico di risorse
I pool sono particolarmente adatti per i database con una media di utilizzo delle risorse ridotta e picchi di utilizzo relativamente poco frequenti. Per altre informazioni, vedere Quando prendere in considerazione un pool elastico database SQL?
Determinare il numero di DTU necessarie per un carico di lavoro
Se si vuole eseguire la migrazione di un carico di lavoro di macchine virtuali locale o SQL Server esistente a database SQL, vedere Consigli sullo SKU per approssimare il numero di DTU necessarie. Per un carico di lavoro database SQL esistente, usare informazioni dettagliate sulle prestazioni delle query per comprendere il consumo di risorse del database e ottenere informazioni più approfondite per ottimizzare il carico di lavoro. La dmv (Dynamic Management View) sys.dm_db_resource_stats consente di visualizzare l'utilizzo delle risorse per l'ultima ora. La vista del catalogo sys.resource_stats visualizza l'utilizzo delle risorse per gli ultimi 14 giorni, ma con una fedeltà inferiore delle medie di cinque minuti.
Determinare l'utilizzo di DTU
Per determinare la percentuale media di utilizzo di DTU/eDTU rispetto al limite DTU/eDTU di un database o di un pool elastico, usare la formula seguente:
avg_dtu_percent = MAX(avg_cpu_percent, avg_data_io_percent, avg_log_write_percent)
I valori di input per questa formula possono essere ottenuti da sys.dm_db_resource_stats, sys.resource_stats e sys.elastic_pool_resource_stats DMV. In altre parole, per determinare la percentuale di utilizzo di DTU/eDTU per il limite DTU/eDTU di un database o di un pool elastico, selezionare il valore percentuale più grande dal seguente: avg_cpu_percent, avg_data_io_percente avg_log_write_percent in un determinato momento.
Nota
Il limite DTU di un database è determinato da CPU, letture, scritture e memoria disponibili per il database. Tuttavia, poiché il motore di database SQL usa in genere tutta la memoria disponibile per la cache dei dati per migliorare le prestazioni, il avg_memory_usage_percent valore in genere sarà vicino al 100%, indipendentemente dal carico corrente del database. Pertanto, anche se la memoria influisce indirettamente sul limite DTU, non viene usata nella formula di utilizzo DTU.
Configurazione hardware
Nel modello di acquisto basato su DTU, i clienti non possono scegliere la configurazione hardware usata per i database. Anche se un determinato database rimane in genere su un tipo specifico di hardware per molto tempo (in genere per più mesi), esistono alcuni eventi che possono causare lo spostamento di un database in hardware diverso.
Ad esempio, un database può essere spostato in hardware diverso se viene ridimensionato verso l'alto o verso il basso fino a un obiettivo di servizio diverso o se l'infrastruttura corrente in un data center sta raggiungendo i limiti di capacità o se l'hardware attualmente usato viene rimosso a causa della fine del ciclo di vita.
Se un database viene spostato in hardware diverso, le prestazioni del carico di lavoro possono cambiare. Il modello DTU garantisce che la velocità effettiva e il tempo di risposta del carico di lavoro del benchmark DTU rimangano sostanzialmente identici quando il database passa a un tipo hardware diverso, purché l'obiettivo di servizio (il numero di DTU) rimanga invariato.
Tuttavia, nell'ampio spettro dei carichi di lavoro dei clienti in esecuzione in database SQL di Azure, l'impatto dell'uso di hardware diverso per lo stesso obiettivo di servizio può essere più pronunciato. Diversi carichi di lavoro possono trarre vantaggio da diverse configurazioni hardware e funzionalità. Pertanto, per i carichi di lavoro diversi dal benchmark DTU, è possibile visualizzare le differenze di prestazioni se il database passa da un tipo di hardware a un altro.
I clienti possono usare il modello vCore per scegliere la configurazione hardware preferita durante la creazione e il ridimensionamento del database. Nel modello vCore i limiti dettagliati delle risorse di ogni obiettivo di servizio in ogni configurazione hardware sono documentati per database singoli e pool elastici. Per altre informazioni sull'hardware nel modello vCore, vedere Configurazione hardware per database SQL o Configurazione hardware per Istanza gestita di SQL.
Confrontare i livelli di servizio
La scelta di un livello di servizio dipende soprattutto dai requisiti in termini di continuità aziendale, archiviazione e prestazioni.
| Basic | Standard | Premium | |
|---|---|---|---|
| Carico di lavoro di destinazione | Sviluppo e produzione | Sviluppo e produzione | Sviluppo e produzione |
| Contratto di servizio relativo al tempo di attività | 99,99% | 99,99% | 99,99% |
| Backup | Una scelta di archiviazione di backup con ridondanza geografica, con ridondanza della zona o con ridondanza locale, conservazione di 1-7 giorni (impostazione predefinita 7 giorni) Conservazione a lungo termine disponibile fino a 10 anni |
Una scelta di archiviazione di backup con ridondanza geografica, con ridondanza della zona o con ridondanza locale, conservazione di 1-35 giorni (impostazione predefinita 7 giorni) Conservazione a lungo termine disponibile fino a 10 anni |
Scelta dell'archiviazione con ridondanza locale, ridondanza della zona o archiviazione con ridondanza geografica Conservazione di 1-35 giorni (7 giorni per impostazione predefinita), con un massimo di 10 anni di conservazione a lungo termine disponibile |
| CPU | Basso | Basso, medio, elevato | Medio, Alto |
| Operazioni di I/O al secondo (approssimative)* | 1-4 operazioni di I/O al secondo per DTU | 1-4 operazioni di I/O al secondo per DTU | >25 operazioni di I/O al secondo per DTU |
| Latenza di I/O (approssimativa) | 5 ms (lettura), 10 ms (scrittura) | 5 ms (lettura), 10 ms (scrittura) | 2 ms (lettura/scrittura) |
| Indicizzazione columnstore | N/D | Standard S3 e versioni successive | Supportata |
| OLTP in memoria | N/D | N/D | Supportata |
* Tutte le operazioni di I/O di lettura e scrittura su file di dati, incluse operazioni di I/O in background (checkpoint e writer differita).
Importante
Gli obiettivi di servizio Basic, S0, S1 e S2 offrono meno di un vCore (CPU). Per i carichi di lavoro a elevato utilizzo di CPU, è consigliabile usare un obiettivo di servizio S3 o superiore.
Negli obiettivi di servizio Basic, S0 e S1 i file di database vengono archiviati in Azure Standard Archiviazione, che usa supporti di archiviazione basati su unità disco rigido (HDD). Questi obiettivi di servizio sono più adatti per lo sviluppo, il test e altri carichi di lavoro a cui si accede raramente che sono meno sensibili alla variabilità delle prestazioni.
Suggerimento
Per visualizzare i limiti effettivi di governance delle risorse per un database o un pool elastico, eseguire una query sulla vista sys.dm_user_db_resource_governance . Per un database singolo, viene restituita una riga. Per un database in un pool elastico, viene restituita una riga per ogni database nel pool.
Nota
È possibile ottenere un database gratuito in database SQL di Azure al livello di servizio Basic con un account Gratuito di Azure. Per informazioni, vedere Crea un database cloud gestito con il tuo account Azure gratuito.
Limiti delle risorse
I limiti delle risorse variano per i database singoli e in pool.
Limiti di archiviazione per database singolo
In database SQL di Azure, le dimensioni di calcolo sono espresse in termini di unità di transazione di database (DTU) per database singoli e unità di transazione di database elastici (eDTU) per i pool elastici. Per altre informazioni, vedere Limiti delle risorse per database singoli.
| Basic | Standard | Premium | |
|---|---|---|---|
| Dimensioni massime di archiviazione | 2 GB | 1 TB | 4 TB |
| Numero massimo di DTU | 5 | 3000 | 4000 |
Importante
In alcune circostanze, può essere necessario compattare un database per recuperare spazio inutilizzato. Per altre informazioni, vedere Gestire lo spazio file nel database SQL di Azure.
Limiti del pool elastico
Per altre informazioni, vedere Limiti delle risorse per i database in pool.
| Base | Standard | Premium | |
|---|---|---|---|
| Dimensioni massime di archiviazione per database | 2 GB | 1 TB | 1 TB |
| Dimensioni massime di archiviazione per pool | 156 GB | 4 TB | 4 TB |
| Numero massimo di eDTU per database | 5 | 3000 | 4000 |
| Numero massimo di eDTU per pool | 1600 | 3000 | 4000 |
| Numero massimo di database per pool | 500 | 500 | 100 |
Importante
Più di 1 TB di spazio di archiviazione nel livello Premium sono attualmente disponibili in tutte le aree, ad eccezione della Cina orientale, della Cina settentrionale, della Germania centrale e della Germania nord-orientale. In queste aree la quantità massima di spazio di archiviazione nel livello Premium è limitata a 1 TB. Per altre informazioni, vedere le limitazioni correnti di P11 e P15.
Importante
In alcune circostanze, può essere necessario compattare un database per recuperare spazio inutilizzato. Per altre informazioni, vedere Gestire lo spazio file nel database SQL di Azure.
Benchmark DTU
Le caratteristiche fisiche (CPU, memoria, I/O) associate a ogni misura DTU vengono calibrate usando un benchmark che simula un carico di lavoro del database reale.
Informazioni sullo schema, i tipi di transazione usati, la combinazione di carichi di lavoro, gli utenti e la velocità, le regole di ridimensionamento e le metriche associate al benchmark DTU.
Confrontare i modelli di acquisto basati su DTU e vCore
Anche se il modello di acquisto basato su DTU si basa su una misura in bundle di risorse di calcolo, archiviazione e I/O, confrontando il modello di acquisto vCore per database SQL di Azure consente di scegliere e ridimensionare in modo indipendente le risorse di calcolo e archiviazione.
Il modello di acquisto basato su vCore consente anche di usare Vantaggio Azure Hybrid per SQL Server per risparmiare sui costi e offre opzioni serverless e Hyperscale per database SQL di Azure non disponibili nel modello di acquisto basato su DTU.
Per altre informazioni, vedere Confrontare i modelli di acquisto basati su vCore e DTU di database SQL di Azure.
Passaggi successivi
Per altre informazioni sui modelli di acquisto e sui concetti correlati, vedere gli articoli seguenti:
- Per informazioni dettagliate sulle dimensioni di calcolo specifiche e sulle opzioni relative alle dimensioni di archiviazione disponibili per database singoli, vedere Limiti delle risorse basate su DTU del database SQL per database singoli.
- Per informazioni dettagliate sulle dimensioni di calcolo specifiche e sulle opzioni relative alle dimensioni di archiviazione disponibili per i pool elastici, vedere Limiti delle risorse basate su DTU del database SQL.
- Per informazioni sul benchmark associato al modello di acquisto basato su DTU, vedere Benchmark DTU.
- Confrontare i modelli di acquisto basati su vCore e DTU di database SQL di Azure.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per