Gestire i dati storici nelle tabelle temporali con criteri di conservazione
Si applica a:![]() Database SQL di Azure
Database SQL di Azure![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
Le tabelle temporali possono aumentare le dimensioni del database più delle tabelle normali, in particolare se si conservano i dati cronologici per un periodo di tempo più lungo. Di conseguenza, i criteri di conservazione per i dati cronologici sono un aspetto importante della pianificazione e della gestione del ciclo di vita di ogni tabella temporale. Le tabelle temporali nel database SQL di Azure e Istanza gestita di SQL di Azure sono dotate di un meccanismo di conservazione facile da usare che aiuta a eseguire questa operazione.
La conservazione della cronologia temporale può essere configurata a livello di singola tabella. Ciò consente agli utenti di creare criteri di aging flessibili. L'applicazione della conservazione della cronologia temporale è semplice e richiede l'impostazione di un solo parametro durante la creazione della tabella o la modifica dello schema.
Dopo che sono stati definiti i criteri di conservazione, il database SQL di Azure e Istanza gestita di SQL di Azure inizia a verificare periodicamente la presenza di righe di cronologia con i requisiti per la pulizia automatica dei dati. L'identificazione di righe corrispondenti e la loro rimozione dalla tabella di cronologia si verificano in modo trasparente nell'attività in background pianificata ed eseguita dal sistema. La condizione cronologica delle righe della tabella viene verificata in base alla colonna che rappresenta la fine del periodo SYSTEM_TIME. Se ad esempio il periodo di conservazione impostato è pari a sei mesi, le righe di tabella idonee per la rimozione soddisfano la condizione seguente:
ValidTo < DATEADD (MONTH, -6, SYSUTCDATETIME())
L'esempio precedente presuppone che la colonna ValidTo corrisponda alla fine del periodo SYSTEM_TIME.
Come si configurano i criteri di conservazione?
Prima di configurare criteri di conservazione per una tabella temporale, innanzitutto è necessario controllare se la conservazione della cronologia temporale è abilitata a livello di database.
SELECT is_temporal_history_retention_enabled, name
FROM sys.databases
Il flag del database is_temporal_history_retention_enabled è ON per impostazione predefinita, ma gli utenti possono modificarlo con l'istruzione ALTER DATABASE. Inoltre, viene impostato automaticamente su OFF dopo l'operazione di ripristino temporizzato. Per impostare la pulizia della cronologia temporale per il database eseguire l'istruzione seguente:
ALTER DATABASE [<myDB>]
SET TEMPORAL_HISTORY_RETENTION ON
Importante
È possibile configurare la conservazione per le tabelle temporali anche se is_temporal_history_retention_enabled è impostato su OFF. Tuttavia in questo caso la pulizia automatica delle righe obsolete non verrà attivata.
I criteri di conservazione vengono configurati durante la creazione della tabella specificando un valore per il parametro HISTORY_RETENTION_PERIOD:
CREATE TABLE dbo.WebsiteUserInfo
(
[UserID] int NOT NULL PRIMARY KEY CLUSTERED
, [UserName] nvarchar(100) NOT NULL
, [PagesVisited] int NOT NULL
, [ValidFrom] datetime2 (0) GENERATED ALWAYS AS ROW START
, [ValidTo] datetime2 (0) GENERATED ALWAYS AS ROW END
, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo)
)
WITH
(
SYSTEM_VERSIONING = ON
(
HISTORY_TABLE = dbo.WebsiteUserInfoHistory,
HISTORY_RETENTION_PERIOD = 6 MONTHS
)
);
Il database SQL di Azure e Istanza gestita di SQL di Azure consente di specificare il periodo di conservazione tramite unità di tempo diverse: DAYS, WEEKS, MONTHS e YEARS. Se HISTORY_RETENTION_PERIOD viene omesso, viene usata la conservazione INFINITE. È anche possibile usare esplicitamente la parola chiave INFINITE.
In alcuni scenari risulta utile configurare la conservazione dopo la creazione della tabella o per modificare un valore configurato in precedenza. In questi casi usare l'istruzione ALTER TABLE:
ALTER TABLE dbo.WebsiteUserInfo
SET (SYSTEM_VERSIONING = ON (HISTORY_RETENTION_PERIOD = 9 MONTHS));
Importante
Con l'impostazione di SYSTEM_VERSIONING su OFF il valore relativo al periodo di conservazione non viene mantenuto. Con l'impostazione di SYSTEM_VERSIONING su ON senza specificare esplicitamente HISTORY_RETENTION_PERIOD si ottiene come risultato un periodo di conservazione INFINITE.
Per esaminare lo stato corrente del criterio di conservazione usare la seguente query, che unisce il flag di abilitazione della conservazione temporale a livello di database con i periodi di conservazione per le singole tabelle:
SELECT DB.is_temporal_history_retention_enabled,
SCHEMA_NAME(T1.schema_id) AS TemporalTableSchema,
T1.name as TemporalTableName, SCHEMA_NAME(T2.schema_id) AS HistoryTableSchema,
T2.name as HistoryTableName,T1.history_retention_period,
T1.history_retention_period_unit_desc
FROM sys.tables T1
OUTER APPLY (select is_temporal_history_retention_enabled from sys.databases
where name = DB_NAME()) AS DB
LEFT JOIN sys.tables T2
ON T1.history_table_id = T2.object_id WHERE T1.temporal_type = 2
Modalità di eliminazione delle righe obsoleti
Il processo di pulizia dipende dal layout dell'indice della tabella di cronologia. È importante notare che solo nelle tabelle di cronologia con un indice cluster (albero B o columnstore) è possibile configurare criteri di conservazione finiti. Viene creata un'attività in background per eseguire la pulizia dei dati obsoleti per tutte le tabelle temporali con periodo di conservazione finito. La logica di pulizia per l'indice in cluster rowstore (B-tree) elimina la riga obsoleta in blocchi più piccoli (fino a 10.000) riducendo al minimo la pressione sul log del database e sul sottosistema I/O. Anche se la logica di pulizia usa l'indice albero B richiesto, l'ordine di eliminazione delle righe con durata superiore al periodo di conservazione non può essere garantito con certezza. Di conseguenza evitare qualsiasi dipendenza dall'ordine di pulizia nelle applicazioni.
L'attività di pulizia per columnstore in cluster rimuove interi gruppi di righe in una sola volta (in genere ogni gruppo contiene un milione di righe); questa procedura è molto efficace, soprattutto quando vengono generati dati cronologici a ritmo elevato.
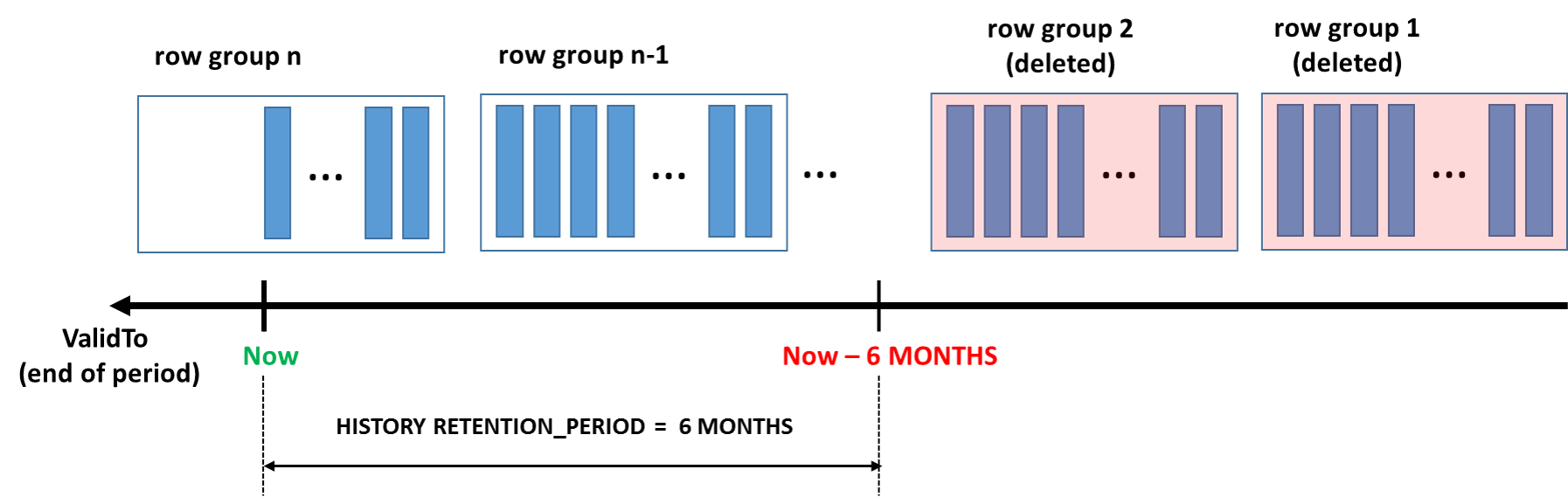
Un'ottima compressione dei dati e una pulizia efficiente dei dati conservati fanno dell'indice columnstore cluster la soluzione ottimale per gli scenari in cui il carico di lavoro genera rapidamente volumi elevati di dati cronologici. Tale modello è tipico per un l'elaborazione transazionale intensiva dei carichi di lavoro che usano tabelle temporali per il rilevamento delle modifiche e il controllo, l'analisi delle tendenze o l'inserimento dei dati IoT.
Considerazioni sull'indice
L'attività di pulizia per le tabelle con indice rowstore in cluster richiede che l'indice inizi con la colonna che corrisponde alla fine del periodo SYSTEM_TIME. Se questa colonna non esiste, non è possibile configurare un periodo di conservazione finito:
Messaggio 13765, Livello 16, Stato 1
L'impostazione del periodo di conservazione definito ha avuto esito negativo nella tabella temporale con controllo delle versioni del sistema 'temporalstagetestdb.dbo.WebsiteUserInfo' perché la tabella di cronologia 'temporalstagetestdb.dbo.WebsiteUserInfoHistory' non contiene l'indice in cluster richiesto. È consigliabile creare un columnstore cluster o indice B-tree a partire dalla colonna che corrisponde alla fine del periodo SYSTEM_TIME nella tabella di cronologia.
È importante notare che la tabella di cronologia predefinito già creata dal database SQL di Azure e Istanza gestita di SQL di Azure dispone già dell'indice in cluster, che è conforme a criteri di conservazione. Se si tenta di rimuovere l'indice in una tabella con periodo di conservazione definito, l'operazione ha esito negativo con l'errore seguente:
Messaggio 13766, livello 16, stato 1
Impossibile eliminare l'indice cluster 'WebsiteUserInfoHistory.IX_WebsiteUserInfoHistory' perché è usato per la pulizia automatica dei dati obsoleti. Si consiglia di impostare HISTORY_RETENTION_PERIOD su INFINITE nella corrispondente tabella temporale con controllo delle versioni del sistema se è necessario eliminare l'indice.
La pulizia dell'indice columnstore in cluster funziona in modo ottimale se vengono inserite righe cronologiche in ordine crescente (ordinate in base alla fine della colonna del periodo); questo viene sempre applicato quando la tabella di cronologia viene popolata esclusivamente dal meccanismo SYSTEM_VERSIONIOING. Se le righe della tabella di cronologia non sono ordinate in base alla fine della colonna del periodo (ad esempio in caso di migrazione dei dati cronologici esistenti), è necessario ricreare un indice columnstore in cluster sull'indice rowstore B-tree ordinato in modo corretto, per ottenere prestazioni ottimali.
Evitare la ricompilazione dell'indice columnstore in cluster nella tabella di cronologia con il periodo di conservazione definito, perché può cambiare l'ordine nei gruppi di righe imposti naturalmente dall'operazione di controllo delle versioni di sistema. Se è necessario ricompilare l'indice columnstore in cluster della tabella di cronologia, crearne uno nuovo al posto dell'indice B-tree conforme, mantenendo l'ordinamento in gruppi di righe necessario per la pulizia dei dati regolare. Lo stesso approccio deve essere adottato se si crea una tabella temporale con la tabella di cronologia esistente che dispone di un indice di colonna in cluster senza ordine dei dati garantito:
/*Create B-tree ordered by the end of period column*/
CREATE CLUSTERED INDEX IX_WebsiteUserInfoHistory ON WebsiteUserInfoHistory (ValidTo)
WITH (DROP_EXISTING = ON);
GO
/*Re-create clustered columnstore index*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_WebsiteUserInfoHistory ON WebsiteUserInfoHistory
WITH (DROP_EXISTING = ON);
Quando viene configurato il periodo di conservazione definito per la tabella di cronologia con l'indice columnstore in cluster, non è possibile creare indici B-tree non in cluster aggiuntivi nella tabella:
CREATE NONCLUSTERED INDEX IX_WebHistNCI ON WebsiteUserInfoHistory ([UserName])
Un tentativo di eseguire l'istruzione sopra indicata avrà esito negativo con l'errore seguente:
Messaggio 13772, livello 16, stato 1
Impossibile creare un indice non in cluster in una tabella di cronologia temporale 'WebsiteUserInfoHistory' perché ha un periodo di conservazione definito e l'indice columnstore in cluster è definito.
Esecuzione di query su tabelle con criteri di conservazione
Tutte le query sulla tabella temporale consentono di escludere automaticamente tramite filtro le righe cronolgiche definite corrispondenti, per evitare risultati imprevisti e incoerenti, poiché è possibile eliminare righe obsolete tramite l'attività di pulizia, in qualsiasi momento e in ordine arbitrario.
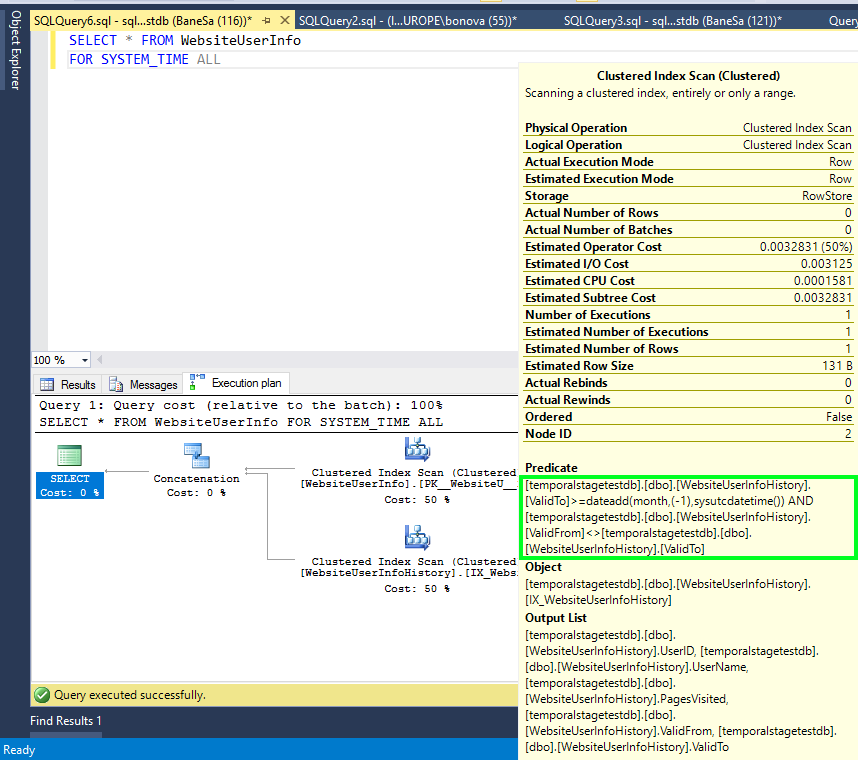
Nell'immagine seguente viene illustrato il piano di query per una query semplice:
SELECT * FROM dbo.WebsiteUserInfo FOR SYSTEM_TIME ALL;
Il piano di query include un altro filtro applicato alla fine della colonna del periodo (ValidTo) nell'operatore Clustered Index Scan nella tabella di cronologia (evidenziata). Questo esempio presuppone che il periodo di conservazione di un MONTH sia stato impostato nella tabella WebsiteUserInfo.
Tuttavia, se si esegue una query direttamente in una tabella di cronologia, è possibile vedere le righe precedenti al periodo di conservazione specificato, ma senza alcuna garanzia relativa ai risultati ripetibili. Nell'immagine seguente è mostrato il piano di esecuzione di query per la query nella tabella di cronologia senza altri filtri applicati:
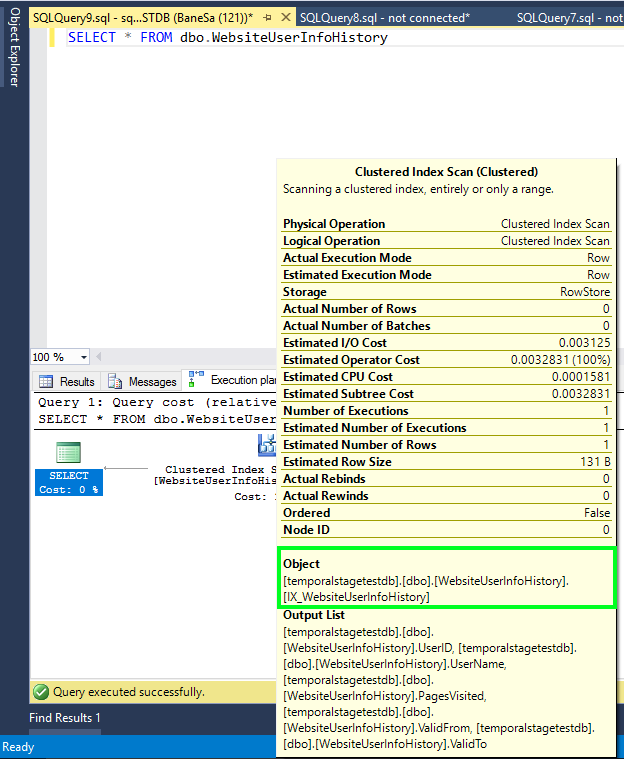
Non affidare la logica di business alla lettura della tabella di cronologia oltre il periodo di conservazione, perché si potrebbero ottenere risultati incoerenti o imprevisti. È consigliabile usare query temporali con la clausola FOR SYSTEM_TIME per l'analisi dei dati nelle tabelle temporali.
Considerazioni sul ripristino temporizzato
Quando si crea un nuovo database attraverso il ripristino di un database esistente in un punto specifico nel tempo, la conservazione temporale è disabilitata a livello di database. (Il flag is_temporal_history_retention_enabled è impostato su OFF). Questa funzionalità consente di esaminare tutte le righe di cronologia al momento del ripristino, senza doversi preoccupare che le righe obsolete vengano rimosse prima di procedere con l'esecuzione di query. È possibile usarla per esaminare i dati cronologici oltre il periodo di conservazione configurato.
Si supponga che per una tabella temporale sia specificato il periodo di conservazione MONTH. Se il database è stato creato al livello di servizio Premium, è possibile creare una copia del database con lo stato del database risalendo fino a 35 giorni prima. Una tale efficacia consentirebbe di analizzare le righe cronologiche risalenti anche a 65 giorni prima eseguendo una query direttamente nella tabella di cronologia.
Se si desidera attivare la pulizia della conservazione temporale, eseguire l'istruzione Transact-SQL seguente dopo il ripristino temporizzato:
ALTER DATABASE [<myDB>]
SET TEMPORAL_HISTORY_RETENTION ON
Passaggi successivi
Per informazioni su come usare le tabelle temporali nelle applicazioni, consultare Introduzione alle tabelle temporali.
Per informazioni dettagliate sulle tabelle temporali, vedere Tabelle temporali.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per