Esercitazione: Usare Personalizza esperienze in Azure Notebook
Importante
A partire dal 20 settembre 2023 non sarà possibile creare nuove risorse di Personalizza esperienze. Il servizio Personalizza esperienze viene ritirato il 1° ottobre 2026.
Questa esercitazione esegue un ciclo di Personalizza esperienze in un notebook di Azure, illustrandone il ciclo di vita completo.
Il ciclo suggerisce quale tipo di caffè dovrebbe essere ordinato da un cliente. Gli utenti e le relative preferenze sono archiviati in un set di dati degli utenti. Le informazioni relative al caffè vengono archiviate in un apposito set di dati.
Utenti e caffè
Il notebook, simulando l'interazione utente con un sito Web, seleziona a caso dal set di dati un utente, un'ora del giorno e un tipo di condizione meteo. Ecco un riepilogo delle informazioni utente:
| Clienti - funzionalità di contesto | Ora del giorno | Tipo di condizione meteo |
|---|---|---|
| Alice Bob Cathy Dave |
Morning Afternoon Evening |
Sunny Rainy Snowy |
Per consentire a Personalizza esperienze di apprendere nel tempo, il sistema conosce anche i dettagli sulla scelta di caffè per ogni persona.
| Caffè - funzionalità di azione | Tipi di temperatura | Luogo di origine | Tipo di tostatura | Organic |
|---|---|---|---|---|
| Cappacino | Alto | Kenya | Scuro | Organic |
| Cold brew | Basso | Brasile | Leggero | Organic |
| Iced mocha | Basso | Etiopia | Leggero | Not organic |
| Latte | Alto | Brasile | Scuro | Not organic |
Lo scopo del ciclo di Personalizza esperienze è trovare la corrispondenza migliore tra gli utenti e il caffè il più spesso possibile.
Il codice di questa esercitazione è disponibile nel repository GitHub di esempi di Personalizza esperienze.
Funzionamento della simulazione
All'inizio dell'esecuzione del sistema la percentuale di successo dei suggerimenti di Personalizza esperienze è compresa appena tra il 20% e il 30%. Questo successo è indicato dalla ricompensa inviata all'API Ricompensa personalizza esperienze, con un punteggio pari a 1. Dopo alcune chiamate a Classificazione e Premio, il sistema migliora.
Dopo le richieste iniziali, eseguire una valutazione offline, per consentire a Personalizza esperienze di esaminare i dati e suggerire un criterio di apprendimento migliore. Applicare i nuovi criteri di apprendimento ed eseguire di nuovo il notebook con il 20% del numero di richieste precedenti. Il ciclo offrirà prestazioni migliori con i nuovi criteri di apprendimento.
Chiamate di classificazione e ricompensa
Per ognuna delle migliaia di chiamate al servizio Personalizza esperienze il notebook di Azure Invia la richiesta di classificazione all'API REST:
- ID univoco per l'evento di classificazione/richiesta
- Caratteristiche del contesto: una scelta casuale di utente, meteo e ora del giorno, che simula un utente in un sito Web o un dispositivo mobile
- Azioni con caratteristiche: tutti i dati sul caffè, da cui Personalizza esperienze trae un suggerimento
Il sistema riceve la richiesta, quindi confronta la previsione con la scelta nota dell'utente nella stessa ora del giorno e nelle stesse condizioni meteo. Se la scelta nota è uguale a quella stimata, viene restituita a Personalizza esperienze la ricompensa 1. In caso contrario, la ricompensa restituita è 0.
Nota
Questa è una simulazione, quindi l'algoritmo per la ricompensa è semplice. In uno scenario reale l'algoritmo dovrebbe usare la logica di business, possibilmente con pesi per diversi aspetti dell'esperienza del cliente, per determinare il punteggio di ricompensa.
Prerequisiti
- Un account Azure Notebooks.
- Una risorsa di Personalizza esperienze di intelligenza artificiale di Azure.
- Se la risorsa di Personalizza esperienze è già stata usata, assicurarsi di cancellare i dati relativi alla risorsa nel portale di Azure.
- Caricare tutti i file per questo esempio in un progetto di Azure Notebooks.
Descrizioni dei file:
- Personalizer.ipynb è il notebook Jupyter per questa esercitazione.
- Il set di dati per gli utenti è archiviato in un oggetto JSON.
- Il set di dati per il caffè è archiviato in un oggetto JSON.
- JSON di richiesta di esempio è il formato previsto per una richiesta POST all'API di classificazione.
Configurare la risorsa di Personalizza esperienze
Nella portale di Azure configurare la risorsa personalizza esperienze con la frequenza del modello di aggiornamento impostata su 15 secondi e un tempo di attesa ricompensa di 10 minuti. Questi valori sono disponibili nella pagina Configurazione.
| Impostazione | Valore |
|---|---|
| Frequenza di aggiornamento del modello | 15 secondi |
| Tempo di attesa per la ricompensa | 10 minuti |
Questi valori hanno una durata molto breve al fine di mostrare i cambiamenti in questa esercitazione. Non devono essere usati in uno scenario di produzione senza prima verificare che raggiungano l'obiettivo prefissato con il ciclo di Personalizza esperienze.
Configurare il notebook di Azure
- Cambiare il Kernel in
Python 3.6. - Apri il file
Personalizer.ipynb.
Eseguire le celle del notebook
Eseguire ogni cella eseguibile e attendere che venga restituito un risultato. Questo avviene quando le parentesi quadre accanto alla cella visualizzano un numero al posto di un *. Le sezioni seguenti illustrano il funzionamento di ogni cella a livello di codice e cosa aspettarsi come output.
Includere i moduli Python
Includere i moduli Python necessari. La cella non ha output.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Impostare la chiave e il nome della risorsa di Personalizza esperienze
Nel portale di Azure trovare la chiave e l'endpoint nella pagina Avvio rapido della risorsa di Personalizza esperienze. Sostituire il valore di <your-resource-name> con il nome della risorsa di Personalizza esperienze. Sostituire il valore di <your-resource-key> con la chiave di Personalizza esperienze.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
Stampare la data e l'ora correnti
Usare questa funzione per prendere nota dell'ora di inizio e di fine della funzione iterativa (iterazioni).
Queste celle non hanno output. La funzione non restituisce la data e l'ora correnti quando viene chiamata.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
Ottenere l'ora dell'ultimo aggiornamento del modello
Quando la funzione get_last_updated viene chiamata, visualizza l'ultima data e ora in cui il modello è stato aggiornato.
Queste celle non hanno output. Quando viene chiamata, la funzione restituisce la data dell'ultimo training del modello.
La funzione usa un'API REST GET per ottenere le proprietà del modello.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
Ottenere la configurazione dei criteri e del servizio
Verificare lo stato del servizio con queste due chiamate REST.
Queste celle non hanno output. Quando viene chiamata, la funzione restituisce i valori del servizio.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
Costruire gli URL e leggere i file di dati JSON
Questa cella
- crea gli URL usati nelle chiamate REST
- imposta l'intestazione di sicurezza usando la chiave della risorsa di Personalizza esperienze
- imposta il valore di inizializzazione casuale per l'ID evento di classificazione
- legge i file di dati JSON
- chiama il metodo
get_last_updated- i criteri di apprendimento sono stati rimossi nell'output dell'esempio - chiama il metodo
get_service_settings
La cella contiene l'output della chiamata alle funzioni get_last_updated e get_service_settings.
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
Verificare che l'output sia rewardWaitTime impostato su 10 minuti e modelExportFrequency sia impostato su 15 secondi.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
Risoluzione dei problemi relativi alla prima chiamata REST
Questa cella precedente è la prima cella che effettua una chiamata a Personalizza esperienze. Verificare che il codice di stato REST nell'output sia <Response [200]>. Se si riceve un errore, ad esempio il 404, ma si è certi che la chiave e il nome della risorsa siano corretti, ricaricare il notebook.
Verificare che il conteggio sia 4 sia per il caffè che per gli utenti. Se si verifica un errore, controllare di aver caricato tutti e 3 i file JSON.
Configurare il grafico delle metriche nel portale di Azure
Più avanti in questa esercitazione, il processo a esecuzione prolungata di 10.000 richieste è visibile dal browser con una casella di testo di aggiornamento. Può risultare più semplice da visualizzare in un grafico o come somma totale, al termine del processo a esecuzione prolungata. Per visualizzare queste informazioni, usare le metriche fornite con la risorsa. È possibile creare il grafico ora che è stata completata una richiesta al servizio, quindi aggiornare periodicamente il grafico mentre è in corso il processo a esecuzione prolungata.
Nel portale di Azure selezionare la risorsa di Personalizza esperienze.
Nel riquadro di spostamento della risorsa selezionare Metriche sotto Monitoraggio.
Nel grafico selezionare Aggiungi metrica.
La risorsa e lo spazio dei nomi della metrica sono già impostati. È sufficiente selezionare la metrica Chiamate riuscite e l'aggregazione Somma.
Cambiare il filtro temporale in Ultime 4 ore.

Si dovrebbero vedere tre chiamate riuscite nel grafico.
Generare un ID evento univoco
Questa funzione genera un ID univoco per ogni chiamata di classificazione. L'ID viene usato per identificare le informazioni sulle chiamate di classificazione e ricompensa. Questo valore può provenire da un processo aziendale, ad esempio un ID di visualizzazione Web o un ID di transazione.
La cella non ha output. Quando viene chiamata, la funzione restituisce l'ID univoco.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
Ottenere un utente, una condizione meteo e un'ora del giorno casuali
Questa funzione seleziona un utente, una condizione meteo e un'ora del giorno casuali, quindi li aggiunge all'oggetto JSON da inviare alla richiesta di classificazione.
La cella non ha output. Quando la funzione viene chiamata, restituisce il nome dell'utente casuale, la condizione meteo casuale e l'ora del giorno casuale.
Ecco l'elenco dei 4 utenti e delle loro preferenze (per brevità sono visualizzate solo alcune preferenze):
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
Aggiungere tutti i dati relativi al caffè
Questa funzione aggiunge l'intero elenco di caffè all'oggetto JSON da inviare alla richiesta di classificazione.
La cella non ha output. La funzione cambia il valore di rankjsonobj quando viene chiamata.
Ecco l'esempio delle caratteristiche di un singolo tipo di caffè:
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
Confrontare la stima con la preferenza nota dell'utente
Questa funzione viene chiamata dopo la chiamata dell'API di classificazione per ogni iterazione.
Confronta la preferenza dell'utente per il caffè, in base alla condizione meteo e all'ora del giorno, con il suggerimento di Personalizza esperienze per l'utente con questi stessi filtri. Se il suggerimento corrisponde, viene restituito il punteggio 1, altrimenti il punteggio è 0. La cella non ha output. Quando viene chiamata, la funzione restituisce il punteggio.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
Riprodurre a ciclo continuo le chiamate alle API di classificazione e ricompensa
La cella successiva è il lavoro principale del notebook: ottiene un utente casuale e l'elenco dei caffè e invia entrambi all'API di classificazione. Confronta la stima con le preferenze note dell'utente, quindi restituisce la ricompensa al servizio Personalizza esperienze.
Il ciclo viene eseguito per num_requests volte. Personalizza esperienze ha bisogno di qualche migliaia di chiamate per consentire alle API di classificazione e ricompensa di creare un modello.
Di seguito è riportato un esempio di codice JSON inviato all'API di classificazione. Per brevità, l'elenco dei caffè non è completo. L'intero codice JSON per il caffè è disponibile in coffee.json.
JSON inviato all'API di classificazione:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
Risposta JSON dall'API di classificazione:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
Infine, ogni ciclo mostra la selezione casuale di utente, meteo e ora del giorno e la ricompensa determinata. Una ricompensa pari a 1 indica che la risorsa di Personalizza esperienze ha selezionato il tipo di caffè corretto per l'utente, la condizione meteo e l'ora del giorno specificati.
1 Alice Rainy Morning Latte 1
La funzione usa:
- Classificazione: un'API REST POST per ottenere la classificazione.
- Ricompensa: un'API REST POST per segnalare la ricompensa.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
Eseguire il ciclo per 10.000 iterazioni
Eseguire il ciclo di Personalizza esperienze per 10.000 iterazioni. Si tratta di un evento a esecuzione prolungata. Non chiudere il browser in cui è in esecuzione il notebook. Aggiornare periodicamente il grafico delle metriche nel portale di Azure per visualizzare le chiamate totali al servizio. Quando si raggiungono circa 20.000 chiamate, una chiamata di classificazione e ricompensa per ogni iterazione del ciclo, le iterazioni sono terminate.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
Organizzare i risultati in un grafico per visualizzare i miglioramenti
Creare un grafico da count e rewards.
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
Eseguire il grafico per 10.000 richieste di classificazione
Eseguire la funzione createChart.
createChart(count,rewards)
Lettura del grafico
Questo grafico mostra l'esito positivo del modello per i criteri di apprendimento predefiniti correnti.
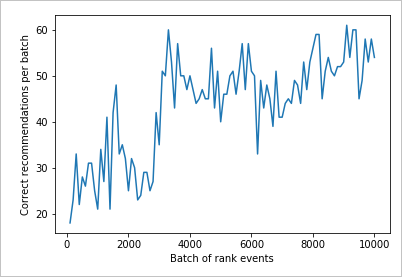
L'obiettivo ideale è che entro la fine del test il ciclo abbia ottenuto in media una percentuale di successo vicina al 100% meno l'esplorazione. Il valore predefinito dell'esplorazione è 20%.
100-20=80
Questo valore di esplorazione si trova nella pagina Configurazione della risorsa Personalizza esperienze nel portale di Azure.
Per trovare un criterio di apprendimento migliore, in base ai dati dell'API di classificazione, eseguire una valutazione offline del ciclo di personalizzazione nel portale.
Eseguire una valutazione offline
Nel portale di Azure aprire la pagina Valutazioni della risorsa di Personalizza esperienze.
Selezionare Crea valutazione.
Immettere i dati necessari per il nome della valutazione e l'intervallo di date per la valutazione del ciclo. L'intervallo di date deve includere solo i giorni sui quali ci si vuole concentrare per la valutazione.
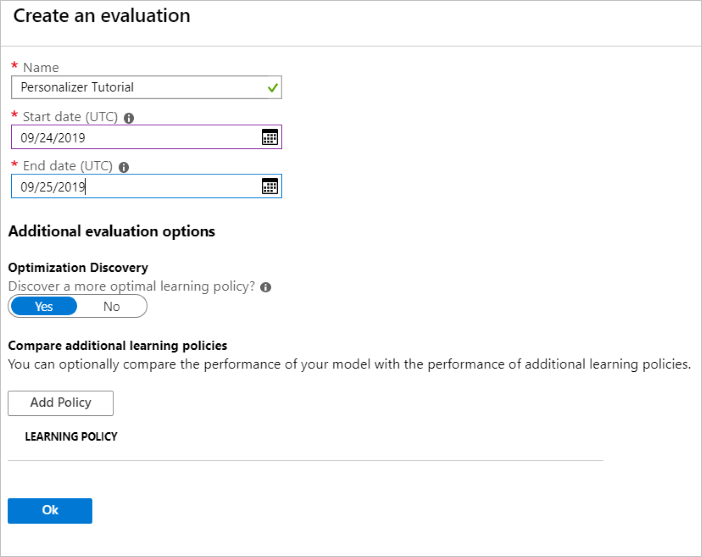
Lo scopo dell'esecuzione di questa valutazione offline è determinare se esistono criteri di apprendimento migliori per le funzionalità e le azioni usate in questo ciclo. Per trovare questi criteri di apprendimento migliori, assicurarsi che l'opzione Individuazione ottimizzazione sia attivata.
Scegliere OK per iniziare la valutazione.
Questa pagina Valutazioni mostra la nuova valutazione e il suo stato corrente. Il tempo necessario per l'esecuzione della valutazione dipende dalla quantità di dati disponibili. È possibile tornare a questa pagina dopo alcuni minuti per visualizzare i risultati.
Al termine della valutazione, selezionare la valutazione e quindi Confronto tra vari criteri di apprendimento. Vengono visualizzati i criteri di apprendimento disponibili e il modo in cui si comporterebbero con i dati.
Selezionare il criterio di apprendimento elencato per primo nella tabella e quindi selezionare Applica. Viene così applicato il criterio di apprendimento migliore al modello e viene ripetuto il training.
Impostare la frequenza di aggiornamento del modello su 5 minuti
- Nel portale di Azure, sempre nella risorsa Personalizza esperienze, selezionare la pagina Configurazione.
- Impostare Frequenza di aggiornamento del modello e Tempo di attesa per la ricompensa su 5 minuti e selezionare Salva.
Altre informazioni sulle opzioni Tempo di attesa per la ricompensa e Frequenza di aggiornamento del modello.
#Verify new learning policy and times
get_service_settings()
Verificare che i valori rewardWaitTime e modelExportFrequency dell'output siano entrambi impostati su 5 minuti.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
Convalidare i nuovi criteri di apprendimento
Tornare al file di Azure Notebooks ed eseguire lo stesso ciclo, ma solo per 2.000 iterazioni. Aggiornare periodicamente il grafico delle metriche nel portale di Azure per visualizzare le chiamate totali al servizio. Quando si raggiungono circa 4.000 chiamate, una chiamata di classificazione e ricompensa per ogni iterazione del ciclo, le iterazioni sono terminate.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
Eseguire il grafico per 2.000 richieste di classificazione
Eseguire la funzione createChart.
createChart(count2,rewards2)
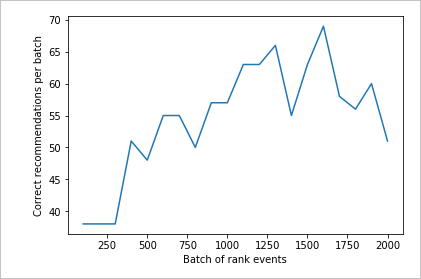
Esaminare il secondo grafico
Il secondo grafico dovrebbe mostrare un visibile aumento dell'allineamento delle stime di classificazione alle preferenze dell'utente.
Pulire le risorse
Se non si prevede di continuare la serie di esercitazioni, pulire le risorse seguenti:
- Eliminare il progetto di Azure Notebooks.
- Eliminare la risorsa di Personalizza esperienze.
Passaggi successivi
Il notebook Jupyter e i file di dati usati in questo esempio sono disponibili nel repository GitHub per Personalizza esperienze.