Come riconoscere le finalità dal riconoscimento vocale con Speech SDK per C#
Speech SDK dei servizi di intelligenza artificiale di Azure si integra con il servizio Language Understanding (LUIS) per fornire il riconoscimento delle finalità. Una finalità è qualcosa che l'utente desidera fare: prenotare un volo, controllare il meteo o effettuare una chiamata. L'utente può usare qualunque termine suoni naturale. LUIS esegue il mapping delle richieste utente alle finalità definite.
Nota
Un'applicazione LUIS definisce le finalità e le entità che si desidera riconoscere. È separata dall'applicazione C# che usa il servizio di riconoscimento vocale. In questo articolo, "app" sta per app LUIS, mentre "applicazione" sta per codice C#.
In questa guida si usa Speech SDK per sviluppare un'applicazione console C# che deriva le finalità dalle espressioni utente tramite il microfono del dispositivo. Scopri come:
- Creare un progetto di Visual Studio che fa riferimento al pacchetto Speech SDK NuGet
- Creare una configurazione di riconoscimento vocale e ricevere un sistema di riconoscimento delle finalità
- Ottenere il modello per l'app LUIS e aggiungere la finalità necessarie
- Specificare la lingua per il riconoscimento vocale
- Riconoscimento vocale da un file
- Usare riconoscimento asincrono continuo basato su eventi
Prerequisiti
Prima di iniziare questa guida, assicurarsi di avere gli elementi seguenti:
- Account LUIS. È possibile ottenerne uno gratuitamente tramite il portale di LUIS.
- Visual Studio 2019 (qualsiasi edizione).
LUIS e riconoscimento vocale
LUIS si integra con il servizio di riconoscimento vocale per distinguere le finalità dai contenuti vocali. Non è necessaria una sottoscrizione al servizio di riconoscimento vocale, LUIS è sufficiente.
LUIS usa due tipi di chiave:
| Tipo di chiave | Scopo |
|---|---|
| Creazione | Consente di creare e modificare a livello di codice app LUIS |
| Previsione | Usato per accedere all'applicazione LUIS in fase di esecuzione |
Per questa guida è necessario il tipo di chiave di stima. Questa guida usa l'app LUIS di home automation di esempio, che è possibile creare seguendo la guida introduttiva Usare l'app di automazione home predefinita. Se è stata creata un'app LUIS personalizzata, è possibile usarla.
Quando si crea un'app LUIS, LUIS genera automaticamente una chiave di creazione in modo da poter testare l'app usando query di testo. Questa chiave non abilita l'integrazione del servizio Voce e non funziona con questa guida. Creare una risorsa LUIS nel dashboard di Azure e assegnarla all'app LUIS. Per questa guida è possibile usare il livello di sottoscrizione gratuito.
Dopo aver creato la risorsa LUIS nel dashboard di Azure, accedere al portale LUIS, scegliere l'applicazione nella pagina App personali, quindi passare alla pagina Gestione dell'app. Infine, selezionare Risorse di Azure nella barra laterale.

Nella pagina Risorse di Azure:
Selezionare l'icona accanto a una chiave per copiarla negli Appunti. È possibile usare una delle due chiavi.
Creare il progetto e aggiungere il carico di lavoro
Per creare un progetto di Visual Studio per lo sviluppo per Windows, è necessario creare il progetto, configurare l'ambiente di sviluppo per desktop .NET in Visual Studio, installare Speech SDK e selezionare l'architettura di destinazione.
Per iniziare, creare il progetto in Visual Studio e verificare che Visual Studio sia configurato per lo sviluppo per desktop .NET:
Aprire Visual Studio 2019.
Nella finestra di avvio selezionare Crea un nuovo progetto.
Nella finestra Crea un nuovo progetto scegliere App console (.NET Framework) e quindi fare clic su Avanti.
Nella finestra Configura il nuovo progetto immettere helloworld in Nome progetto scegliere o creare il percorso della directory in Percorso e quindi selezionare Crea.
Dalla barra dei menu di Visual Studio scegliere Strumenti>Ottieni strumenti e funzionalità per aprire il Programma di installazione di Visual Studio e visualizzare la finestra di dialogo Modifica.
Assicurarsi che il carico di lavoro di Sviluppo per desktop .NET sia disponibile. Se il carico di lavoro non è installato, selezionare la casella di controllo accanto e quindi selezionare Modifica per avviare l'installazione. Il download e l'installazione potrebbero richiedere alcuni minuti.
Se la casella di controllo accanto a Sviluppo per desktop .NET è già selezionata, fare clic su Chiudi per chiudere la finestra di dialogo.
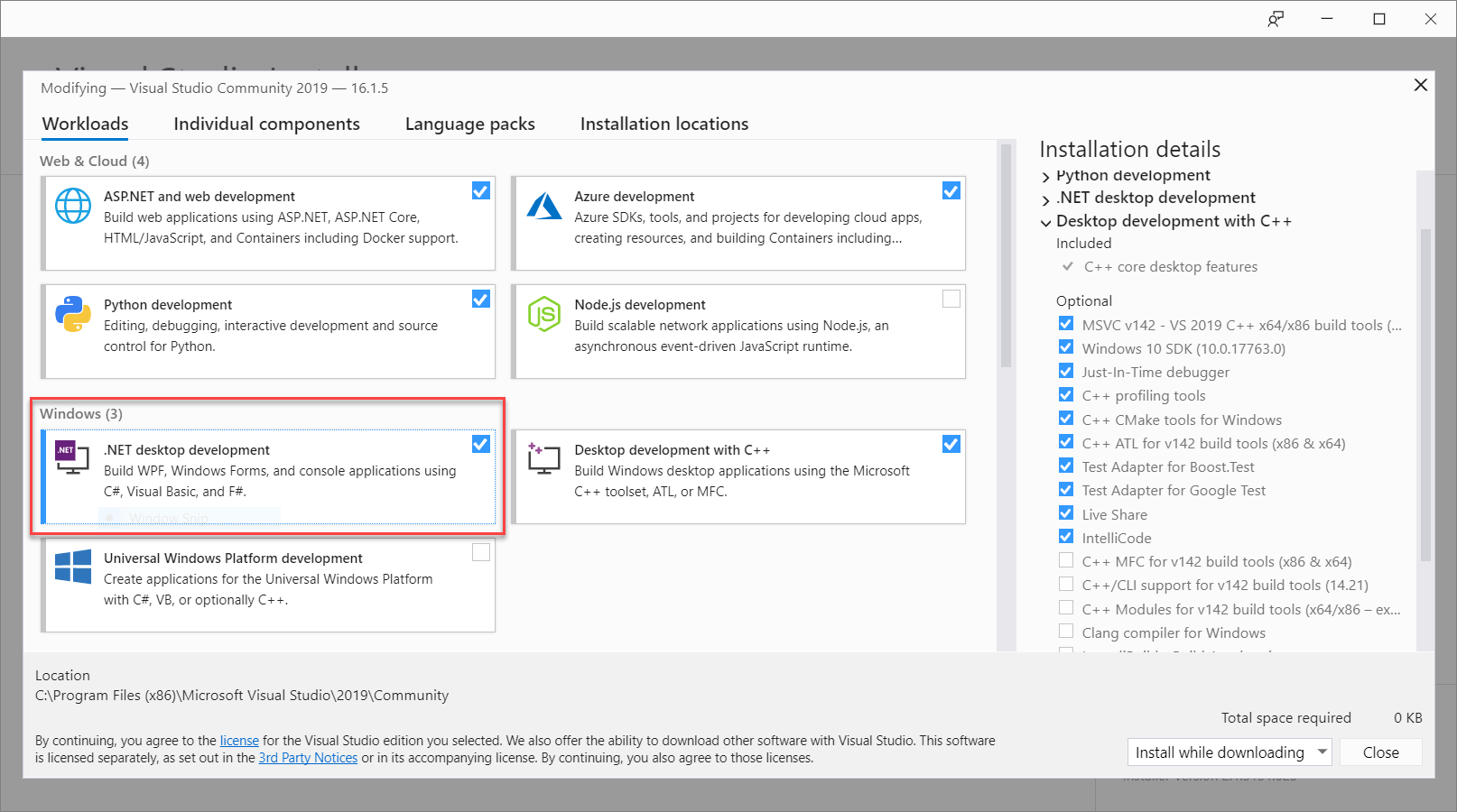
Chiudere il Programma di installazione di Visual Studio.
Installare Speech SDK
Il passaggio successivo prevede l'installazione del pacchetto NuGet Speech SDK per potervi fare riferimento nel codice.
In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto helloworld e quindi scegliere Gestisci pacchetti NuGet per visualizzare Gestione pacchetti NuGet.
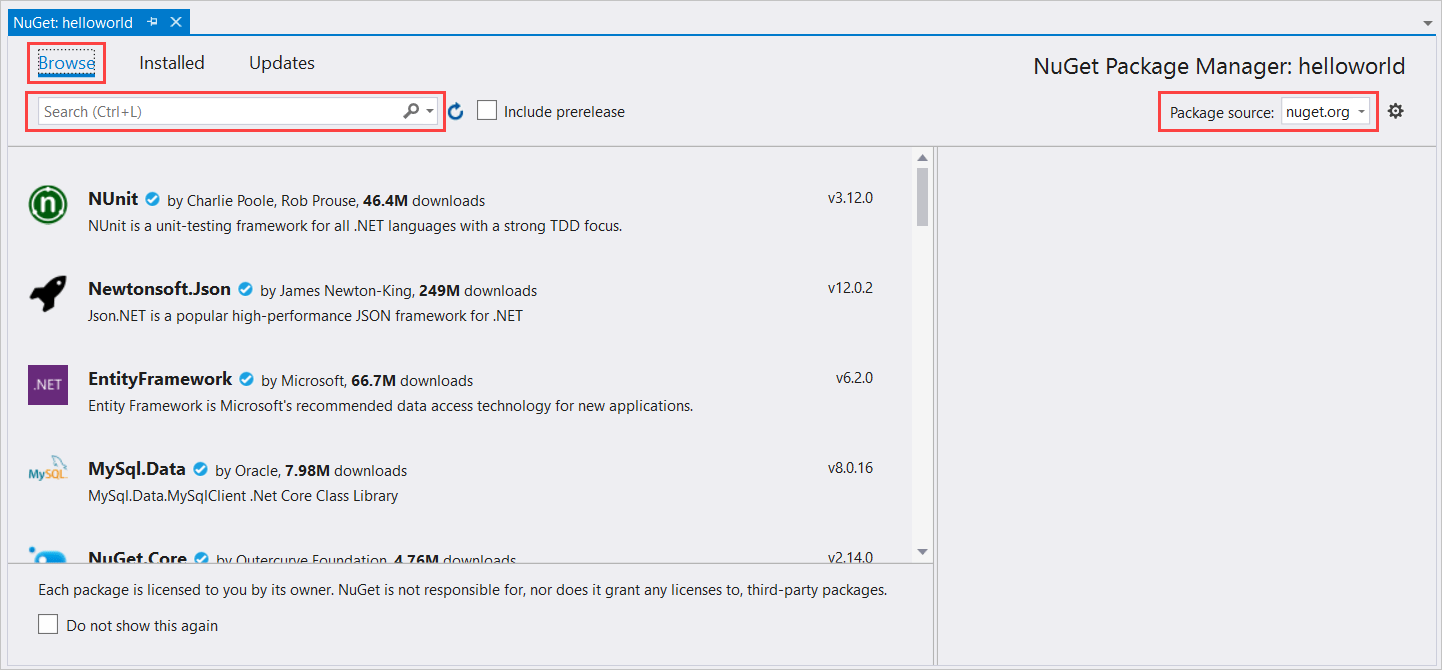
Nell'angolo in alto a destra individuare la casella a discesa Origine dei pacchetti e assicurarsi che sia selezionata l'opzione nuget.org.
Nell'angolo in alto a sinistra fare clic su Sfoglia.
Nella casella di ricerca digitare Microsoft.CognitiveServices.Speech e premere INVIO.
Nei risultati della ricerca selezionare il pacchetto Microsoft.CognitiveServices.Speech e quindi selezionare Installa per installare la versione stabile più recente.
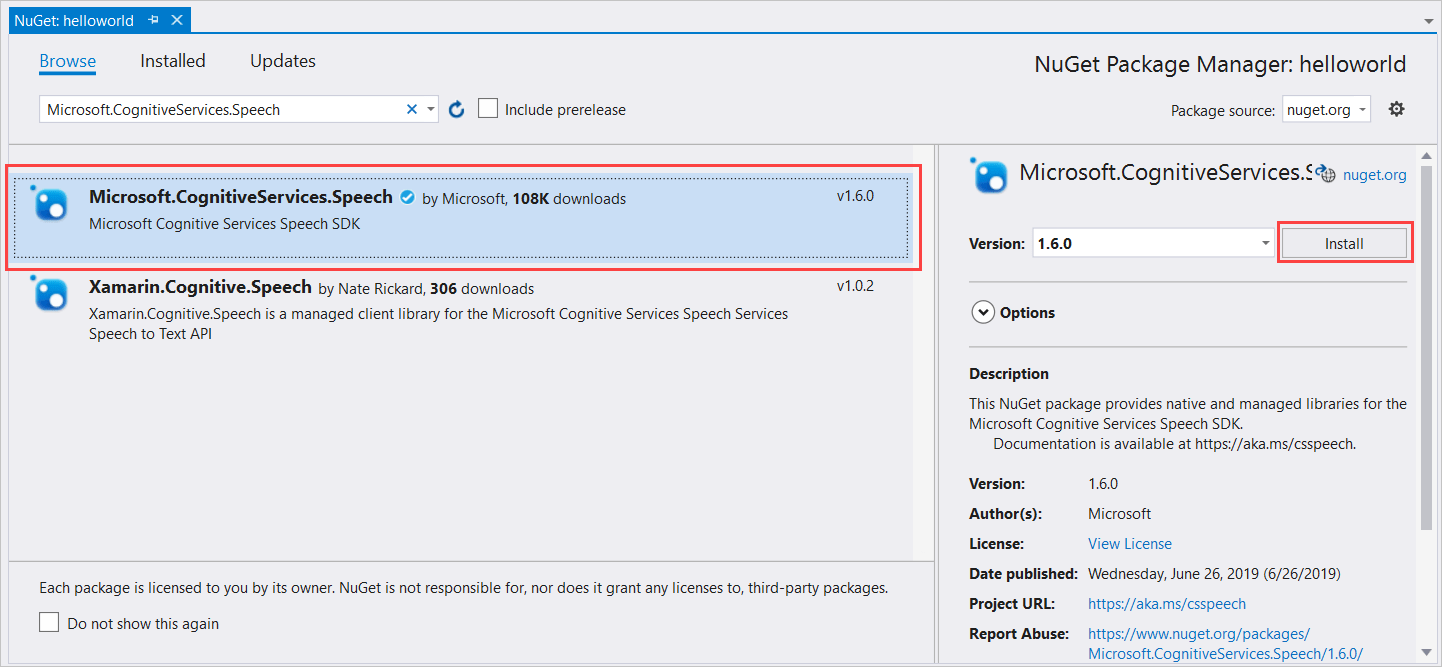
Accettare tutti i contratti e le licenze per avviare l'installazione.
Dopo aver installato il pacchetto, viene visualizzato un messaggio di conferma nella finestra della Console di Gestione pacchetti.
Scegliere l'architettura di destinazione
A questo punto, per compilare ed eseguire l'applicazione console, creare una configurazione della piattaforma corrispondente all'architettura del computer.
Nella barra dei menu selezionare Compila>Gestione configurazione. Verrà visualizzata finestra di dialogo Gestione configurazione.
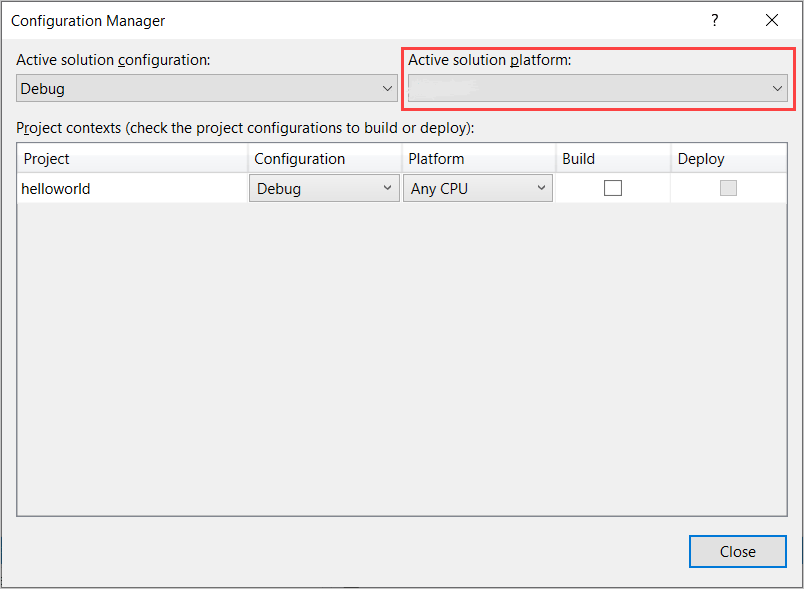
Nella casella a discesa Piattaforma soluzione attiva selezionare Nuova. Verrà visualizzata la finestra di dialogo Nuova piattaforma soluzione.
Nella casella a discesa Digitare o selezionare la nuova piattaforma:
- Se è in esecuzione Windows a 64 bit, selezionare x64.
- Se è in esecuzione Windows a 32 bit, selezionare x86.
Fare clic su OK e quindi su Chiudi.
Aggiunta del codice
Aggiungere il codice al progetto.
In Esplora soluzioni aprire il file Program.cs.
Sostituire il blocco di istruzioni
usingall'inizio del file con le dichiarazioni seguenti:using System; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent;Sostituire il metodo fornito
Main()con l'equivalente asincrono seguente:public static async Task Main() { await RecognizeIntentAsync(); Console.WriteLine("Please press Enter to continue."); Console.ReadLine(); }Creare un metodo asincrono vuoto
RecognizeIntentAsync(), come illustrato di seguito:static async Task RecognizeIntentAsync() { }Nel corpo di questo nuovo metodo aggiungere questo codice:
// Creates an instance of a speech config with specified subscription key // and service region. Note that in contrast to other services supported by // the Cognitive Services Speech SDK, the Language Understanding service // requires a specific subscription key from https://www.luis.ai/. // The Language Understanding service calls the required key 'endpoint key'. // Once you've obtained it, replace with below with your own Language Understanding subscription key // and service region (e.g., "westus"). // The default language is "en-us". var config = SpeechConfig.FromSubscription("YourLanguageUnderstandingSubscriptionKey", "YourLanguageUnderstandingServiceRegion"); // Creates an intent recognizer using microphone as audio input. using (var recognizer = new IntentRecognizer(config)) { // Creates a Language Understanding model using the app id, and adds specific intents from your model var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId"); recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1"); recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2"); recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here"); // Starts recognizing. Console.WriteLine("Say something..."); // Starts intent recognition, and returns after a single utterance is recognized. The end of a // single utterance is determined by listening for silence at the end or until a maximum of 15 // seconds of audio is processed. The task returns the recognition text as result. // Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single // shot recognition like command or query. // For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead. var result = await recognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (result.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={result.Text}"); Console.WriteLine($" Intent Id: {result.IntentId}."); Console.WriteLine($" Language Understanding JSON: {result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (result.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={result.Text}"); Console.WriteLine($" Intent not recognized."); } else if (result.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (result.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(result); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } }Sostituire i segnaposto in questo metodo con la chiave della risorsa LUIS, l'area e l'ID app come indicato di seguito.
Segnaposto Replace with YourLanguageUnderstandingSubscriptionKeyChiave di risorsa LUIS. Anche in questo caso, è necessario ottenere questo elemento dal dashboard di Azure. È possibile trovarla nella pagina Risorse di Azure dell'app (in Gestisci) nel portale LUIS. YourLanguageUnderstandingServiceRegionL'identificatore breve per l'area in cui si trova la risorsa LUIS, ad esempio westusper gli Stati Uniti occidentali. Vedere Tutte le aree.YourLanguageUnderstandingAppIdL'ID dell'app LUIS. È possibile trovarlo nella pagina Impostazioni dell'app nel portale LUIS.
Con queste modifiche apportate, è possibile compilare (Ctrl+MAIUSC+B) ed eseguire (F5) l'applicazione. Quando richiesto, provare a dire "Spegni le luci" nel microfono del PC. L'applicazione visualizza il risultato nella finestra della console.
Le sezioni seguenti includono una discussione del codice.
Creare un sistema di riconoscimento delle finalità
Prima di tutto, è necessario creare una configurazione vocale dalla chiave e dall'area di stima LUIS. È possibile usare le configurazioni del riconoscimento vocale per creare sistemi di riconoscimento per le diverse funzionalità di Speech SDK. La configurazione vocale offre diversi modi per specificare la risorsa che si vuole usare; in questo caso si usa FromSubscription, che accetta la chiave della risorsa e l'area.
Nota
Usare la chiave e l'area della risorsa LUIS, non una risorsa Voce.
Creare un sistema di riconoscimento delle finalità tramite new IntentRecognizer(config). Poiché la configurazione conosce già la risorsa da usare, non è necessario specificare di nuovo la chiave durante la creazione del sistema di riconoscimento.
Importare un modello LUIS e aggiungere le finalità
Ora importare il modello dalla app LUIS tramite LanguageUnderstandingModel.FromAppId() e aggiungere le finalità di LUIS che si desidera riconoscere tramite il metodo del sistema di riconoscimento AddIntent(). Questi due passaggi migliorano l'accuratezza del riconoscimento vocale, indicando le parole che l'utente, con probabilità, usa nelle richieste. Non è necessario aggiungere tutte le finalità dell'app se non è necessario riconoscerle tutte nella propria applicazione.
Per aggiungere finalità, è necessario fornire tre argomenti: il modello LUIS (denominato model), il nome della finalità e un ID finalità. La differenza tra l'ID e il nome è come indicato di seguito.
AddIntent() argomento |
Scopo |
|---|---|
intentName |
Il nome delle finalità va in base a quanto definito nell'app LUIS. Questo valore deve corrispondere esattamente al nome finalità LUIS. |
intentID |
ID assegnato a una finalità riconosciuta da Speech SDK. Questo valore può essere un qualsiasi valore; non è necessario che corrisponda al nome finalità come definito nell'app LUIS. Se più finalità vengono gestite tramite lo stesso codice, ad esempio, è possibile usare per queste lo stesso ID. |
La app LUIS di domotica presenta due finalità: una per accendere il dispositivo e l'altra per spegnerlo. Le righe in basso aggiungono queste finalità al sistema di riconoscimento; sostituire le tre linee AddIntent nel metodo RecognizeIntentAsync() con questo codice.
recognizer.AddIntent(model, "HomeAutomation.TurnOff", "off");
recognizer.AddIntent(model, "HomeAutomation.TurnOn", "on");
Anziché aggiungere singole finalità, è anche possibile usare il metodo AddAllIntents per aggiungere tutte le finalità in un modello al sistema di riconoscimento.
Avviare il riconoscimento
Con il riconoscimento creato e le finalità aggiunte, è possibile iniziare il riconoscimento. Speech SDK supporta sia il riconoscimento singolo che quello continuo.
| Modalità di riconoscimento | Metodi di chiamata | Risultato |
|---|---|---|
| Singolo | RecognizeOnceAsync() |
Restituisce la finalità riconosciuta, se presente, dopo una singola espressione. |
| Continuo | StartContinuousRecognitionAsync()StopContinuousRecognitionAsync() |
Riconosce più espressioni; genera eventi (ad esempio, IntermediateResultReceived) quando i risultati sono disponibili. |
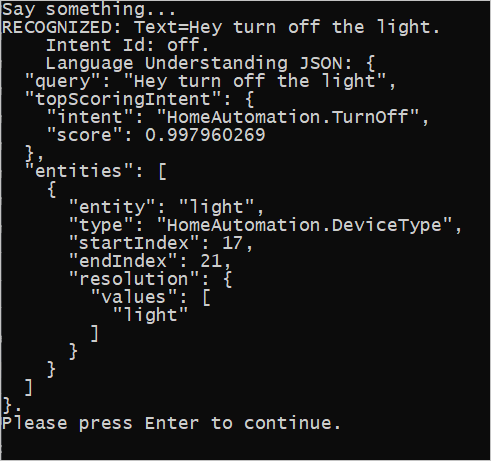
L'applicazione usa la modalità single-shot e quindi chiama RecognizeOnceAsync() per iniziare il riconoscimento. Il risultato è un oggetto IntentRecognitionResult contenente le informazioni sulla finalità riconosciuta. La risposta LUIS JSON viene estratta mediante l'espressione seguente:
result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)
L'applicazione non analizza il risultato JSON. Viene visualizzato solo il testo JSON nella finestra della console.
Specificare lingua di riconoscimento
Per impostazione predefinita, LUIS riconosce le finalità in inglese Americano (en-us). Tramite l'assegnazione di un codice impostazioni locali alla proprietà SpeechRecognitionLanguage della configurazione del riconoscimento vocale, questa è in grado di riconoscere le finalità in altre lingue. Ad esempio, aggiungere config.SpeechRecognitionLanguage = "de-de"; nell'applicazione prima di creare il riconoscitore per riconoscere le finalità in tedesco. Per altre informazioni, vedere Supporto per il linguaggio LUIS.
Riconoscimento vocale continuo da un file
Il codice seguente illustra altre due funzionalità di riconoscimento delle finalità con Speech SDK. Il primo, menzionato in precedenza, è il riconoscimento continuo, in cui il sistema di riconoscimento genera eventi quando sono disponibili i risultati. Questi eventi vengono elaborati dai gestori eventi forniti. Con il riconoscimento continuo, si effettua una chiamata al metodoStartContinuousRecognitionAsync() del sistema di riconoscimento per avviare il riconoscimento anziché chiamare RecognizeOnceAsync().
L'altra funzionalità legge l'audio che contiene il riconoscimento vocale per essere elaborato da un file WAV. L'implementazione comporta la creazione di una configurazione audio che può essere usata quando si crea il riconoscimento finalità. Il file deve essere singolo canale (mono) con una frequenza di campionamento di 16 kHz.
Per provare queste funzionalità, eliminare o impostare come commento il corpo del metodo RecognizeIntentAsync() e sostituirlo con il codice seguente.
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
var config = SpeechConfig.FromSubscription("YourLanguageUnderstandingSubscriptionKey", "YourLanguageUnderstandingServiceRegion");
// Creates an intent recognizer using file as audio input.
// Replace with your own audio file name.
using (var audioInput = AudioConfig.FromWavFileInput("YourAudioFile.wav"))
{
using (var recognizer = new IntentRecognizer(config, audioInput))
{
// The TaskCompletionSource to stop recognition.
var stopRecognition = new TaskCompletionSource<int>(TaskCreationOptions.RunContinuationsAsynchronously);
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// Subscribes to events.
recognizer.Recognizing += (s, e) =>
{
Console.WriteLine($"RECOGNIZING: Text={e.Result.Text}");
};
recognizer.Recognized += (s, e) =>
{
if (e.Result.Reason == ResultReason.RecognizedIntent)
{
Console.WriteLine($"RECOGNIZED: Text={e.Result.Text}");
Console.WriteLine($" Intent Id: {e.Result.IntentId}.");
Console.WriteLine($" Language Understanding JSON: {e.Result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}.");
}
else if (e.Result.Reason == ResultReason.RecognizedSpeech)
{
Console.WriteLine($"RECOGNIZED: Text={e.Result.Text}");
Console.WriteLine($" Intent not recognized.");
}
else if (e.Result.Reason == ResultReason.NoMatch)
{
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
}
};
recognizer.Canceled += (s, e) =>
{
Console.WriteLine($"CANCELED: Reason={e.Reason}");
if (e.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={e.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={e.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
stopRecognition.TrySetResult(0);
};
recognizer.SessionStarted += (s, e) =>
{
Console.WriteLine("\n Session started event.");
};
recognizer.SessionStopped += (s, e) =>
{
Console.WriteLine("\n Session stopped event.");
Console.WriteLine("\nStop recognition.");
stopRecognition.TrySetResult(0);
};
// Starts continuous recognition. Uses StopContinuousRecognitionAsync() to stop recognition.
await recognizer.StartContinuousRecognitionAsync().ConfigureAwait(false);
// Waits for completion.
// Use Task.WaitAny to keep the task rooted.
Task.WaitAny(new[] { stopRecognition.Task });
// Stops recognition.
await recognizer.StopContinuousRecognitionAsync().ConfigureAwait(false);
}
}
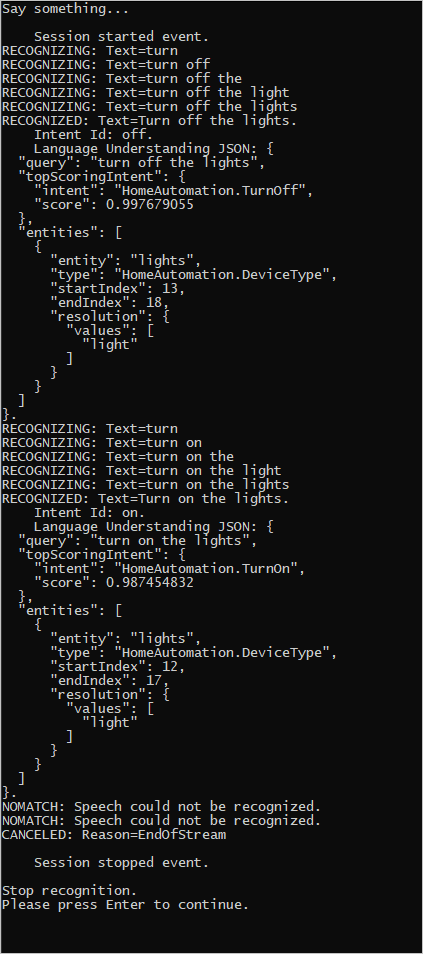
Rivedere il codice in modo da includere la chiave di stima, l'area e l'ID dell'app LUIS e aggiungere le finalità di Automazione home come in precedenza. Modificare whatstheweatherlike.wav nel nome del proprio file audio registrato. Quindi compilare, copiare il file audio nella directory di compilazione ed eseguire l'applicazione.
Ad esempio, se si dice "Spegni le luci", mettere in pausa e quindi pronunciare "Accendere le luci" nel file audio registrato, l'output della console simile al seguente potrebbe apparire:
Il team di Speech SDK gestisce attivamente un ampio set di esempi in un repository open source. Per il repository di codice sorgente di esempio, vedere Azure AI Speech SDK in GitHub. Sono disponibili esempi per C#, C++, Java, Python, Objective-C, Swift, JavaScript, UWP, Unity e Xamarin. Cercare il codice usato in questo articolo nella cartella samples/csharp/sharedcontent/console.