Contenitori riconoscimento vocale personalizzato con Docker
Il contenitore di riconoscimento vocale personalizzato trascrive il parlato in tempo reale o le registrazioni audio in batch con risultati intermedi. È possibile usare un modello personalizzato creato nel portale Voce personalizzato. Questo articolo illustra come scaricare, installare ed eseguire un contenitore di riconoscimento vocale personalizzato.
Per altre informazioni sui prerequisiti, verificare che un contenitore sia in esecuzione, che esegua più contenitori nello stesso host e che esegua contenitori disconnessi, vedere Installare ed eseguire contenitori di Voce con Docker.
Immagini del contenitore
L'immagine del contenitore di riconoscimento vocale personalizzato per tutte le versioni e le impostazioni locali supportate è disponibile nel syndicate Registro Container di Microsoft. Si trova all'interno del repository azure-cognitive-services/speechservices/ ed è denominata custom-speech-to-text.

Il nome completo dell'immagine del contenitore è mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Aggiungere una versione specifica o accodare :latest per ottenere la versione più recente.
| Versione | Percorso |
|---|---|
| Più recente | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.6.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.6.0-amd64 |
Tutti i tag, ad eccezione di latest, sono nel formato seguente e fanno distinzione tra maiuscole e minuscole:
<major>.<minor>.<patch>-<platform>-<prerelease>
Nota
locale e voice per i contenitori di riconoscimento vocale personalizzato sono determinati dal modello personalizzato inserito dal contenitore.
I tag sono disponibili anche in formato JSON per praticità. Il corpo include il percorso del contenitore e l'elenco di tag. I tag non vengono ordinati in base alla versione, ma "latest" viene sempre incluso alla fine dell'elenco, come illustrato in questo frammento di codice:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
"2.10.0-amd64",
"2.11.0-amd64",
"2.12.0-amd64",
"2.12.1-amd64",
<--redacted for brevity-->
"latest"
]
}
Ottenere l'immagine del contenitore con docker pull
Sono necessari i prerequisiti incluso l'hardware necessario. Vedere anche l'allocazione consigliata delle risorse per ogni contenitore di Voce.
Usare il comando docker pull per scaricare un'immagine del contenitore da Registro Container di Microsoft:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Nota
locale e voice per i contenitori Voce personalizzati sono determinati dal modello personalizzato inserito dal contenitore.
Ottenere l'ID modello
Prima di poter eseguire il contenitore, è necessario conoscere l'ID modello del modello personalizzato o l’ID di un modello di base. Quando si esegue il contenitore, specificare uno degli ID modello da scaricare e usare.
Il training del modello personalizzato deve essere eseguito tramite Speech Studio. Per informazioni su come ottenere l'ID modello, vedere Ciclo di vita del modello conversione voce/testo personalizzato.
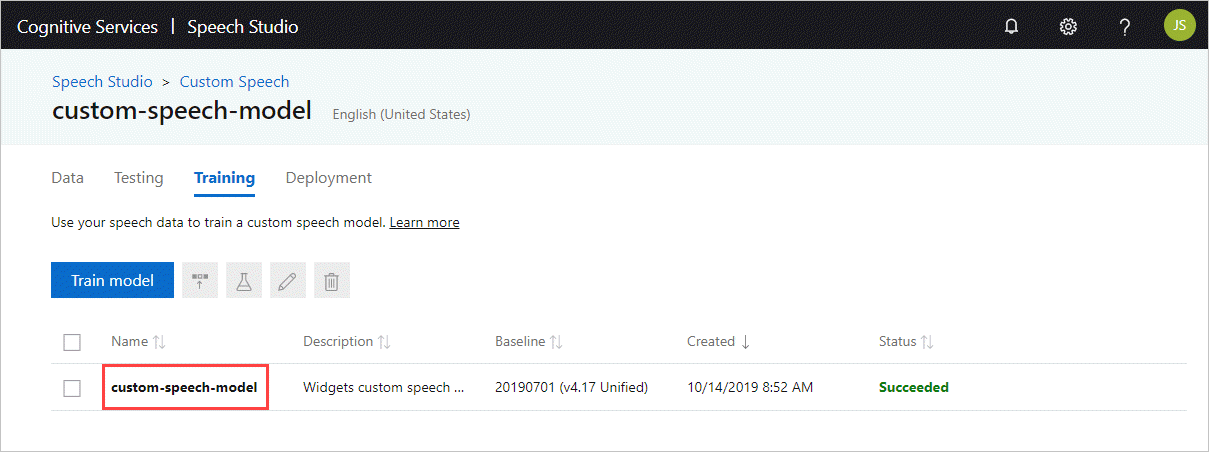
Ottenere l'ID modello da usare come argomento per il parametro ModelId del comando docker run.
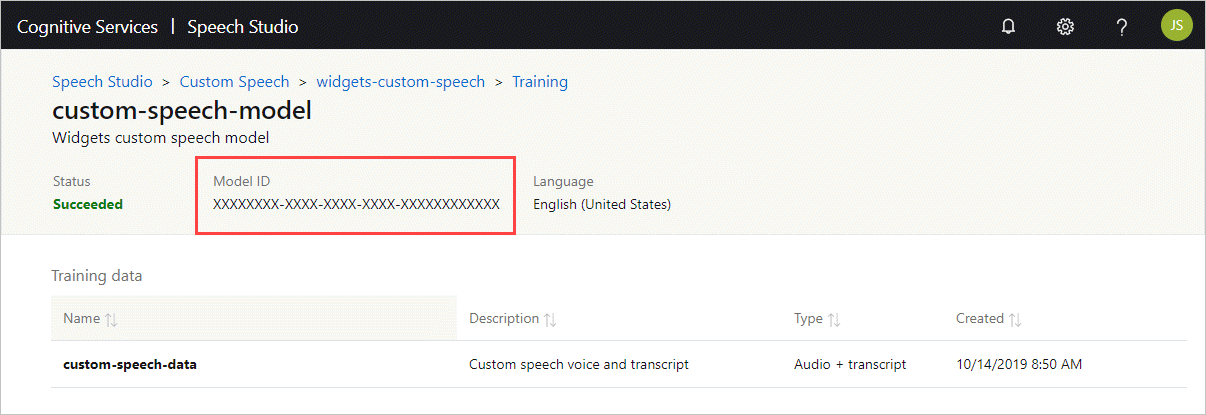
Download del modello di visualizzazione
Prima di eseguire il contenitore, è possibile ottenere facoltativamente le informazioni sui modelli di visualizzazione disponibili e scegliere se scaricare tali modelli nel contenitore di riconoscimento vocale per ottenere un output finale di visualizzazione estremamente migliorato. Il download del modello di visualizzazione è disponibile con il contenitore personalizzato di riconoscimento vocale versione 3.1.0 e successive.
Nota
Anche se si usa il comando docker run, il contenitore non viene avviato per il servizio.
È possibile eseguire query o scaricare uno o tutti questi tipi di modello di visualizzazione: Rescoring (Rescore), Punctuation (Punct), resegmentation (Resegment) e wfstitn (Wfstitn). In caso contrario, è possibile usare l'opzione FullDisplay (con o senza altri tipi) per eseguire query o scaricare tutti i tipi di modelli di visualizzazione.
Impostare BaseModelLocale per eseguire una query sul modello di visualizzazione più recente disponibile nelle impostazioni locali di destinazione. Se si includono più tipi di modello di visualizzazione, il comando restituisce i modelli di visualizzazione disponibili più recenti per ogni tipo. Ad esempio:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Impostare DisplayLocale per scaricare il modello di visualizzazione più recente disponibile nelle impostazioni locali di destinazione. Quando si imposta DisplayLocale, è necessario specificare anche FullDisplay o un subset separato da spazi di modelli di visualizzazione. Il comando scarica il modello di visualizzazione disponibile più recente per ogni tipo specificato. Ad esempio:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Impostare un parametro ID modello per scaricare un modello di visualizzazione specifico: Rescoring (RescoreId), Punctuation (PunctId), resegmentation (ResegmentId), or wfstitn (WfstitnId). Questa procedura è simile a quella con cui si scarica un modello di base tramite il parametro ModelId. Ad esempio, per scaricare un modello di visualizzazione di registrazione, è possibile usare il comando seguente con il parametro RescoreId:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Nota
Se si impostano più query o parametri di download, il comando assegna le priorità in questo ordine: BaseModelLocale, ID modello e infine DisplayLocale (applicabile solo per i modelli di visualizzazione).
Eseguire il contenitore con il comando docker run
Usare il comando docker run per eseguire il contenitore per il servizio.
La tabella seguente rappresenta i vari parametri docker run e le descrizioni corrispondenti:
| Parametro | Descrizione |
|---|---|
{VOLUME_MOUNT} |
Montaggio del volume del computer host, usato da Docker per rendere persistente il modello personalizzato. Ne è un esempio c:\CustomSpeech, dove l'unità c:\ si trova nel computer host. |
{MODEL_ID} |
ID modello di base o voce personalizzato. Per altre informazioni, vedere Ottenere l'ID modello. |
{ENDPOINT_URI} |
L'endpoint è necessario per misurazione e fatturazione. Per altre informazioni, vedere argomenti di fatturazione. |
{API_KEY} |
La chiave API è obbligatoria. Per altre informazioni, vedere argomenti di fatturazione. |
Quando si esegue il contenitore di riconoscimento vocale personalizzato, configurare la porta, la memoria e la CPU in base ai requisiti e alle raccomandazioni per il contenitore di riconoscimento vocale personalizzato.
Ecco un esempio del comando docker run con valori segnaposto. È necessario specificare i valori VOLUME_MOUNT, MODEL_ID, ENDPOINT_URI e API_KEY:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Questo comando:
- Esegue un contenitore di riconoscimento vocale personalizzato dall'immagine del contenitore.
- Alloca 4 core della CPU e 8 GB di memoria.
- Carica il modello di riconoscimento vocale personalizzato dal montaggio di input del volume, ad esempio C:\CustomSpeech.
- Espone la porta TCP 5000 e alloca un pseudo terminale TTY per il contenitore.
- Scarica il modello dato
ModelId(se non trovato nel montaggio del volume). - Se il modello personalizzato è stato scaricato in precedenza,
ModelIdviene ignorato. - Rimuove automaticamente il contenitore dopo la chiusura. L'immagine del contenitore rimane disponibile nel computer host.
Per altre informazioni su docker run con i contenitori di Voce, vedere Installare ed eseguire contenitori di Voce con Docker.
Usare il contenitore
I contenitori voce forniscono API endpoint di query basate su websocket a cui si accede tramite Speech SDK e interfaccia della riga di comando di Voce. Per impostazione predefinita, il Software Development Kit e l'interfaccia della riga di comando di Voce usano il servizio Voce pubblico. Per usare il contenitore, è necessario modificare il metodo di inizializzazione.
Importante
Quando si usa il servizio Voce con contenitori, assicurarsi di usare l’autenticazione host. Se si configura la chiave e l'area, le richieste verranno inviate al servizio Voce pubblico. I risultati del servizio Voce potrebbero non essere quelli previsti. Le richieste provenienti da contenitori disconnessi avranno esito negativo.
Anziché usare questa configurazione di inizializzazione cloud di Azure:
var config = SpeechConfig.FromSubscription(...);
Usare questa configurazione con l’host del contenitore:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
Anziché usare questa configurazione di inizializzazione cloud di Azure:
auto speechConfig = SpeechConfig::FromSubscription(...);
Usare questa configurazione con l’host del contenitore:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
Anziché usare questa configurazione di inizializzazione cloud di Azure:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Usare questa configurazione con l’host del contenitore:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
Anziché usare questa configurazione di inizializzazione cloud di Azure:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Usare questa configurazione con l’host del contenitore:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
Anziché usare questa configurazione di inizializzazione cloud di Azure:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Usare questa configurazione con l’host del contenitore:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
Anziché usare questa configurazione di inizializzazione cloud di Azure:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Usare questa configurazione con l’host del contenitore:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
Anziché usare questa configurazione di inizializzazione cloud di Azure:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Usare questa configurazione con l’host del contenitore:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
Anziché usare questa configurazione di inizializzazione cloud di Azure:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Usare questa configurazione con l’endpoint del contenitore:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
Quando si usa l'interfaccia della riga di comando di Voce in un contenitore, includere l'opzione --host wss://localhost:5000/. È inoltre necessario specificare --key none per assicurarsi che l'interfaccia della riga di comando non tenti di usare una chiave di Voce per l'autenticazione. Per informazioni su come configurare l'interfaccia della riga di comando di Voce, vedere Introduzione all'interfaccia della riga di comando di Voce di Azure AI.
Provare la guida di avvio rapido al riconoscimento vocale usando l'autenticazione host anziché la chiave e l'area.
Passaggi successivi
- Vedere la panoramica dei contenitori Voce
- Vedere configurare i contenitori per informazioni sulle impostazioni di configurazione
- Usare altri contenitori Azure per intelligenza artificiale