Distribuzione globale dei dati con Azure Cosmos DB - informazioni sul funzionamento
SI APPLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabella
Tabella
Azure Cosmos DB è un servizio fondamentale di Azure, tale da essere distribuito in tutte le aree di Azure di tutto il mondo, inclusi il settore pubblico, sovrano, il Dipartimento della difesa (DoD) e i cloud per enti pubblici.
A livello generale, i dati del contenitore di Azure Cosmos DB vengono partizionati orizzontalmente in molti set di repliche, che replicano le scritture, in ogni area. I set di repliche eseguono operazioni di commit in modo permanente usando un quorum di maggioranza.
Ogni area contiene tutte le partizioni di dati di un contenitore di Azure Cosmos DB e può gestire le letture e le scritture quando è abilitata la scrittura in più aree. Se l'account Azure Cosmos DB viene distribuito tra N aree di Azure, saranno presenti almeno N x 4 copie di tutti i dati.
All'interno di un data center, distribuiamo e gestiamo Azure Cosmos DB su moltissimi tipi di computer, ognuno con risorse di archiviazione locali dedicate. All'interno di un data center, Azure Cosmos DB viene distribuito tra vari cluster, ognuno dei quali esegue potenzialmente più generazioni di hardware. I computer all'interno di un cluster vengono in genere distribuiti in 10-20 domini di errore per la disponibilità elevata all'interno di un'area. L'immagine seguente mostra la topologia del sistema di distribuzione globale di Azure Cosmos DB:
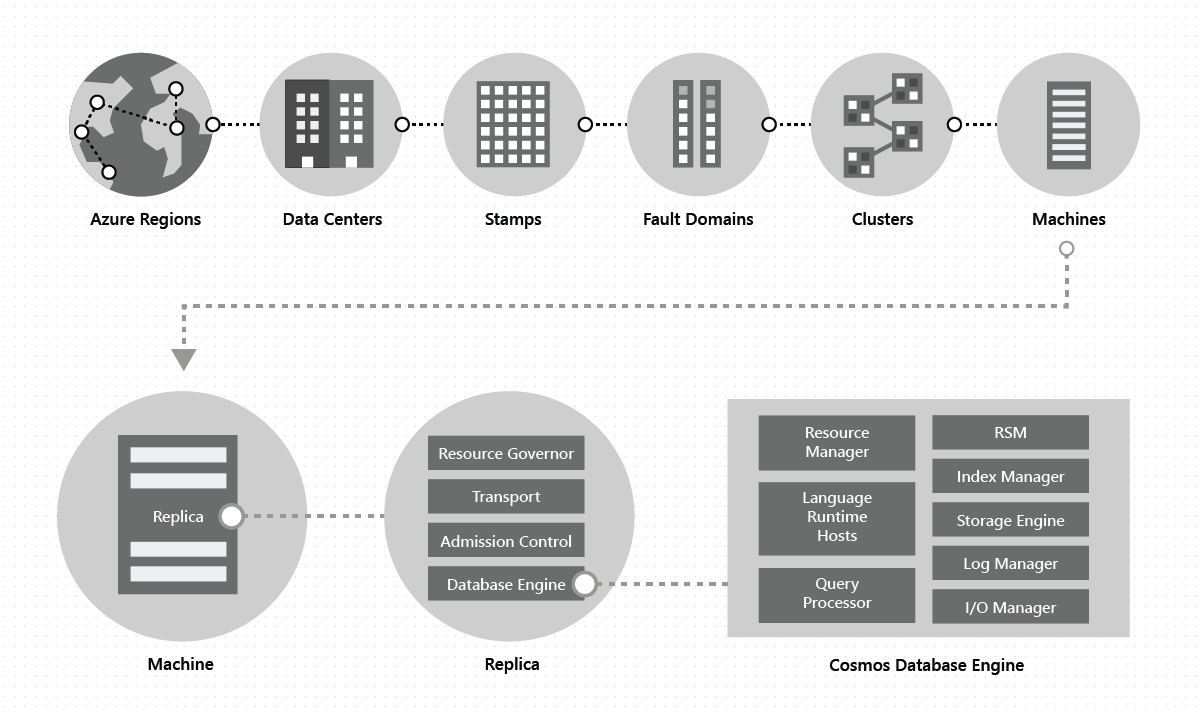
La distribuzione globale in Azure Cosmos DB è un fattore chiave: in qualsiasi momento, con pochi clic o con una singola chiamata di API a livello di programmazione, è possibile aggiungere o rimuovere le aree geografiche associate al relativo database Azure Cosmos DB. Un database di Azure Cosmos DB, a sua volta, è costituito da un set di contenitori di Azure Cosmos DB. In Azure Cosmos DB, i contenitori fungono da unità logiche di distribuzione e scalabilità. Le raccolte, le tabelle e i grafici che vengono creati sono (internamente) solo contenitori Azure Cosmos DB. I contenitori sono completamente indipendenti dallo schema e forniscono un ambito per una query. I dati in un contenitore Azure Cosmos DB vengono indicizzati automaticamente al momento dell'inserimento. L'indicizzazione automatica consente agli utenti di eseguire query sui dati senza problemi di gestione dello schema o dell'indice, soprattutto in una configurazione distribuita a livello globale.
In una determinata area, i dati all'interno di un contenitore vengono distribuiti usando una chiave di partizione, che viene fornita e gestita in modo trasparente dalle partizioni fisiche sottostanti (distribuzione locale).
Ogni partizione fisica viene inoltre replicata in più aree geografiche (distribuzione globale).
Quando un'app che usa Azure Cosmos DB ridimensiona in modo elastico la velocità effettiva in un contenitore di Azure Cosmos DB o usa più spazio di archiviazione, Azure Cosmos DB gestisce in modo trasparente le operazioni di gestione delle partizioni (divisione, clonazione, eliminazione) in tutte le aree. Indipendente da scalabilità, distribuzione o errori, Azure Cosmos DB continua a fornire una singola immagine del sistema dei dati all'interno dei contenitori, che vengono distribuiti globalmente in un grande numero di aree.
Come illustrato nell'immagine seguente, i dati all'interno di un contenitore vengono distribuiti lungo due dimensioni, all'interno di un'area e tra aree, in tutto il mondo:
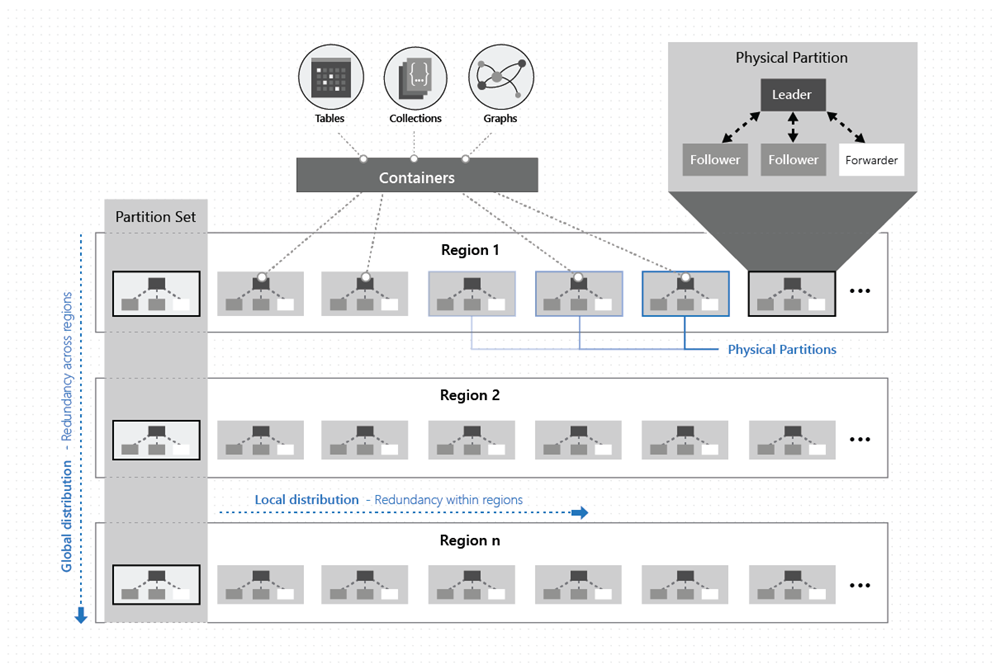
Una partizione fisica viene implementata da un gruppo di repliche, denominato set di repliche. Ogni computer ospita centinaia di repliche che corrispondono a diverse partizioni fisiche all'interno di un set fisso di processi, come illustrato nell'immagine precedente. Le repliche corrispondenti alle partizioni fisiche vengono posizionate in modo dinamico e con carico bilanciato nei computer all'interno di un cluster e nei data center all'interno di un'area.
Una replica appartiene in modo univoco a un tenant di Azure Cosmos DB. Ogni replica ospita un'istanza del motore di database di Azure Cosmos DB, che gestisce le risorse, nonché gli indici associati. Il motore di database Azure Cosmos DB funziona su un tipo di sistema basato su una sequenza di record ATOM (ARS,atom-record-sequence). Il motore è indipendente dal concetto di uno schema e il confine tra i valori di struttura e di istanza del record è sfocato. Azure Cosmos DB consente di ottenere la completa indipendenza dallo schema attraverso un'efficiente indicizzazione automatica di tutti gli elementi dopo all'inserimento, consentendo agli utenti di eseguire una query dei dati distribuiti a livello globale senza dover gestire schemi o indici.
Il motore di database di Azure Cosmos DB è costituito da componenti, tra cui l'implementazione di diverse primitive di coordinamento, runtime di linguaggio, processore di query e sottosistemi di archiviazione e indicizzazione responsabili dell'archiviazione transazionale e, rispettivamente, dell'indicizzazione dei dati. Per garantire durabilità e disponibilità elevata, il motore di database conserva i dati e l'indice nelle unità SSD e ne esegue la replica, rispettivamente tra le istanze del motore di database all'interno dei set di repliche. I tenant di dimensioni maggiori corrispondono a una scalabilità superiore di velocità effettiva e archiviazione e dispongono di repliche più grandi o in numero maggiore o di entrambi. Ogni componente del sistema è completamente asincrono: nessun thread si blocca mai e ognuno esegue operazioni di breve durata senza incorrere in eventuali opzioni di thread non necessarie. Limitazione di frequenza e congestione sono sottoposte a plumbing nell'intero stack dal controllo di ammissione a tutti i percorsi I/O. Il motore di database di Azure Cosmos DB è progettato per sfruttare la concorrenza con granularità fine, per offrire elevata velocità effettiva mentre opera all'interno di quantità frugali di risorse di sistema.
La distribuzione globale di Azure Cosmos DB si basa su due chiavi di astrazioni: set di repliche e set di partizioni. Un set di repliche è un "mattoncino" modulare per il coordinamento e un set di partizioni è una sovrapposizione dinamica di una o più partizioni fisiche distribuite geograficamente. Per comprendere il funzionamento della distribuzione globale, è necessario comprendere queste due chiavi di astrazioni.
Set di repliche
Una partizione fisica viene materializzata come un gruppo di repliche con bilanciamento del carico autogestito e dinamico su più domini di errore, denominato set di repliche. Questo set implementa collettivamente il protocollo replicato dello stato del computer per rendere i dati all'interno della partizione fisica altamente disponibili, durevoli e coerenti. L'appartenenza al set di repliche N è dinamico: fluttua tra NMin e NMax in base agli errori, alle operazioni amministrative e al tempo necessario per rigenerare/ripristinare le repliche non riuscite. In base alle modifiche dell'appartenenza, anche il protocollo della replica riconfigura anche le dimensioni del quorum di lettura e scrittura. Per distribuire in modo uniforme la velocità effettiva assegnata a una determinata partizione fisica, si usano due idee:
In primo luogo, il costo di elaborazione delle richieste di scrittura sul leader è superiore al costo di applicazione degli aggiornamenti al follower. Di conseguenza, il leader ha in bilancio più risorse di sistema rispetto ai follower.
In secondo luogo, per quanto possibile, il quorum di lettura per un livello di coerenza specifico è costituito esclusivamente dalle repliche dei follower. A meno che non necessario, sarà possibile evitare di contattare il leader per la gestione delle operazioni di lettura. Vengono impiegate svariate idee dalla ricerca effettuata sulla relazione tra il carico e la capacità nei sistemi basati su quorum per i cinque modelli di coerenza che Azure Cosmos DB supporta.
Set di partizioni
Un gruppo di partizioni fisiche, uno per ognuna delle aree di database Azure Cosmos DB configurate, è costruito per gestire lo stesso set di chiavi replicate in tutte le aree configurate. Questa primitiva di coordinamento superiore è denominata set di partizioni, ovvero una sovrapposizione dinamica di partizioni fisiche distribuita geograficamente per la gestione di un determinato set di chiavi. Mentre una determinata partizione fisica (un set di repliche) è presente all'interno di un cluster, un set di partizioni può estendersi su cluster, data center e aree geografiche come mostrato nell'immagine seguente:
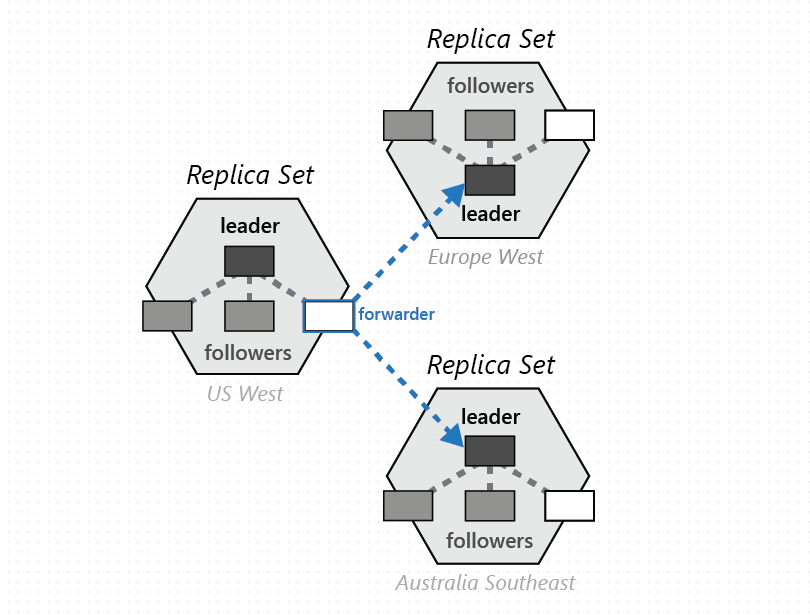
È possibile considerare un set di partizioni come un "super set di repliche" geograficamente disperso, composto da più set di repliche che dispongono dello stesso numero di chiavi. Analogamente a un set di repliche, anche l'appartenenza a un set di repliche è dinamica: fluttua in base alle operazioni implicite di gestione delle partizioni fisiche per aggiungere/rimuovere nuove partizioni in/da un determinato set di partizioni (ad esempio, quando si aumenta la velocità effettiva in un contenitore, si aggiunge/rimuove una regione nel database Azure Cosmos DB, oppure quando si verifica un errore). Grazie al fatto che ogni partizione (di un set) gestisce l'appartenenza al set di partizioni all'interno del proprio set di repliche, l'appartenenza è completamente decentralizzata e a disponibilità elevata. Durante la riconfigurazione di un set di partizioni, viene specificata anche la topologia della sovrapposizione tra le partizioni fisiche. La topologia viene selezionata in modo dinamico in base al livello di coerenza, la distanza geografica e la larghezza di banda della rete disponibile tra le partizioni fisiche di origine e di destinazione.
Il servizio consente di configurare i database Azure Cosmos DB con una singola area di scrittura o con più aree di scrittura e, a seconda della selezione, i set di partizioni sono configurati per accettare le scritture esattamente in una o tutte le aree. Il sistema usa un protocollo di consenso annidato e a due livelli: un livello opera all'interno delle repliche di un set di repliche di una partizione fisica accettando le scritture; l'altro opera a livello di un set di partizioni per fornire garanzie di ordinamento complete per tutte scritture sulle quali è stato eseguito il commit all'interno del set di partizioni. Questo consenso, annidato e a più livelli, è fondamentale per l'implementazione dei rigorosi contratti di servizio per la disponibilità elevata, nonché per l'implementazione di modelli di coerenza offerti ai client da Azure Cosmos DB.
Risoluzione dei conflitti
La progettazione per la propagazione degli aggiornamenti, la risoluzione dei conflitti e il rilevamento della causalità sono ispirate al lavoro preliminare sugli algoritmi epidemici e il sistema Bayou. Mentre i kernel delle idee rimasti forniscono un pratico riferimento per la comunicazione relativa alla progettazione di sistema di Azure Cosmos DB, sono stati anche sottoposti a una significativa trasformazione una volta applicati al sistema di Azure Cosmos DB. Ciò è stato necessario, in quanto i precedenti sistemi erano progettati privi della governance delle risorse e della scalabilità necessarie ad Azure Cosmos DB per operare e fornire le funzionalità (ad esempio, la coerenza di decadimento ristretto) e i rigorosi e completi contratti di servizio che Azure Cosmos DB offre ai client.
È importante ricordare che un set di partizioni viene distribuito tra più aree e segue il protocollo di replica Azure Cosmos DB (scritture in più aree) per replicare i dati tra le partizioni fisiche che comprendono uno specifico set di partizioni. Ogni partizione fisica (di un set di partizioni) in genere accetta le scritture e gestisce le letture dei client locali di una determinata area. Le scritture accettate da una partizione fisica all'interno di un'area vengono memorizzate in modo duraturo e rese altamente disponibili all'interno della partizione fisica prima di essere confermate al client. Si tratta di operazioni di scrittura provvisorie e vengono propagate alle altre partizioni fisiche all'interno del set di partizioni usando un canale antientropia. I client possono richiedere operazioni di scrittura provvisori o sulle quali è stato eseguito il commit, passando un'intestazione di richiesta. La propagazione antientropia (inclusa la frequenza della propagazione) è dinamica e basata sulla topologia del set di partizioni, la prossimità dell'area delle partizioni fisiche e il livello di coerenza configurato. All'interno di un set di partizioni, Azure Cosmos DB segue uno schema di commit primario con una partizione arbiter selezionata dinamicamente. La selezione arbiter è dinamica ed è parte integrante della riconfigurazione del set di partizioni basata sulla topologia della sovrimpressione. Le operazioni di scrittura (inclusi multi-row/in batch gli aggiornamenti) in cui è stato eseguito il commit sono garantite per essere ordinate.
Vengono usati orologi con vettori codificati (contenenti l'ID dell'area e la logica dell'orologio corrispondente a ogni livello di consenso rispettivamente, al set di repliche e al set di partizioni) per il rilevamento della causalità e della versione vettori per identificare e risolvere conflitti di aggiornamento. La topologia e l'algoritmo di selezione peer sono progettati per garantire risorse di archiviazione predefinite e minime e un sovraccarico di rete minimo dei vettori della versione. L'algoritmo garantisce la rigida proprietà di convergenza.
Per i database Azure Cosmos DB configurati con più aree di scrittura, il sistema offre agli sviluppatori una serie di criteri di risoluzione dei conflitti automatica e flessibile, che include:
- Last-Write-Wins (LWW) che, per impostazione predefinita, utilizza una proprietà timestamp definita dal sistema (che si basa sul protocollo dell'orologio di sincronizzazione dell'ora). Azure Cosmos DB consente anche di specificare qualsiasi altra proprietà numerica personalizzata da usare per la risoluzione dei conflitti.
- Il criterio personalizzato di risoluzione dei conflitti definito dall'applicazione (espresso tramite procedure di tipo merge) progettato per la risoluzione a livello semantico dei conflitti basati sull'applicazione. Queste procedure vengono richiamate quando viene rilevato un conflitto tra scrittura e scrittura a cura di una transazione di database, sul lato server. Il sistema fornisce esattamente una volta la garanzia per l'esecuzione di una routine di tipo merge come parte del protocollo di impegno. Esistono diversi esempi di risoluzione dei conflitti disponibili.
Modelli di coerenza
Se si configura il database Azure Cosmos DB con una o più aree di scrittura, è possibile scegliere tra cinque modelli di coerenza ben definiti. Con le diverse aree di scrittura, ecco alcuni aspetti più interessanti riguardo ai livelli di coerenza:
La coerenza a decadimento ristretto garantisce che tutte le letture siano all'interno di prefissi K o secondi T dalla scrittura più recente in una qualsiasi delle aree. Inoltre, con la coerenza a decadimento ristretto le letture sono garantite come monotone e con garanzie di prefisso costante. Il protocollo antientropia è soggetto a limitazioni di frequenza e assicura che i prefissi non vengono accumulati e che non venga applicata la congestione nelle operazioni di scrittura. La coerenza delle sessioni garantisce una lettura monotona, una scrittura monotona, lettura della propria scrittura, scrittura-segue-lettura e garanzie di prefisso coerente in tutto il mondo. Per i database configurati con coerenza assoluta, i vantaggi delle diverse aree di scrittura (bassa latenza di scrittura, disponibilità elevata di scrittura) non sono applicabili a causa della replica sincrona tra le aree.
La semantica dei cinque modelli di coerenza in Azure Cosmos DB è descritta qui e viene descritta matematicamente qui usando un alto livello TLA + specifiche.
Passaggi successivi
Scoprire come configurare la distribuzione globale utilizzando i seguenti articoli:
- Aggiungere o rimuovere aree dall'account di database
- Come creare un criterio di risoluzione dei conflitti personalizzato
- Si sta tentando di pianificare la capacità per una migrazione ad Azure Cosmos DB? È possibile usare le informazioni del cluster di database esistente per la pianificazione della capacità.
- Se si conosce solo il numero di vcore e server nel cluster di database esistente, leggere le informazioni sulla stima delle unità richieste usando vCore o vCPU
- Se si conosce la frequenza delle richieste tipiche per il carico di lavoro corrente del database, leggere le informazioni sulla stima delle unità richieste con lo strumento di pianificazione della capacità di Azure Cosmos DB