Gestire l'indicizzazione in Azure Cosmos DB for MongoDB
SI APPLICA A: ![]() MongoDB
MongoDB
Azure Cosmos DB for MongoDB sfrutta le funzionalità di gestione degli indici di base di Azure Cosmos DB. Questo articolo è incentrato su come aggiungere indici usando Azure Cosmos DB per MongoDB. Gli indici sono strutture di dati specializzate che rendono più veloce l'esecuzione di query sui dati.
Indicizzazione per il server MongoDB versione 3.6 e successive
Azure Cosmos DB per il server MongoDB versione 3.6+ indicizza automaticamente il _id campo e la chiave di partizione (solo nelle raccolte partizionate). L'API applica automaticamente l'univocità del _idcampo per ogni chiave di partizione.
L'API per MongoDB si comporta in modo diverso rispetto ad Azure Cosmos DB per NoSQL, che indicizza tutti i campi per impostazione predefinita.
Modifica dei criteri di indicizzazione
Si consiglia di modificare i criteri di indicizzazione in Esplora Dati nel portale di Azure. È possibile aggiungere singoli campi e indici jolly dall'editor dei criteri di indicizzazione in Esplora Dati:
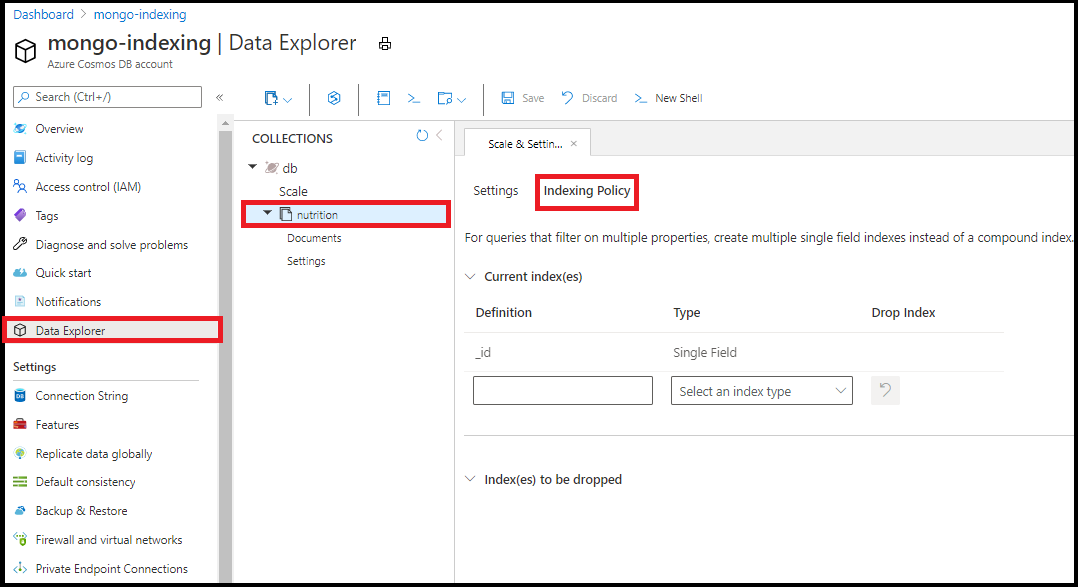
Nota
Non è possibile creare indici composti usando l'editor dei criteri di indicizzazione in Esplora Dati.
Tipi di indice
Campo singolo
È possibile creare indici in qualsiasi campo singolo. L'ordine dell'indice di campo singolo non è rilevante. Il comando seguente crea un indice nel campo name:
db.coll.createIndex({name:1})
È possibile creare lo stesso indice di campo singolo in name nel portale di Azure:
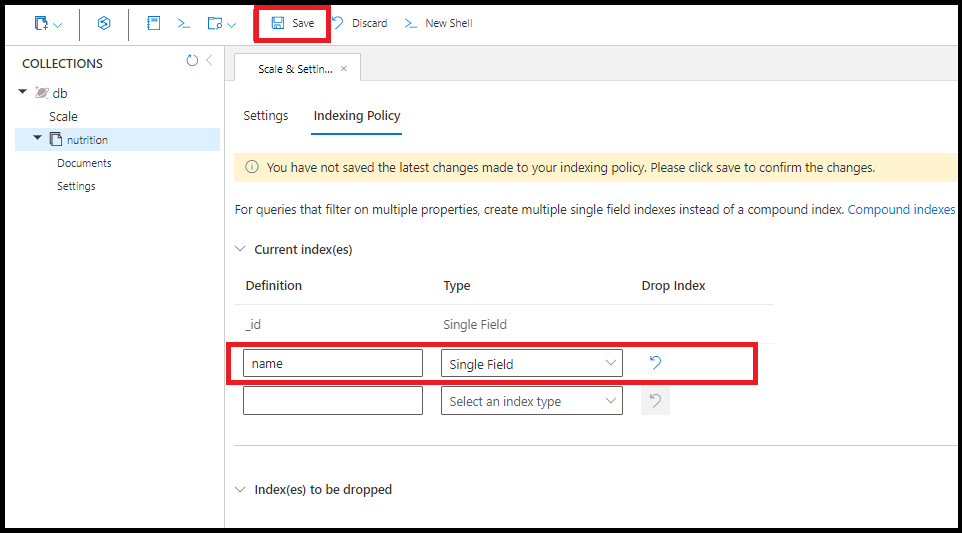
Una query usa più indici di campo singolo, se disponibili. È possibile creare fino a 500 indici di campo singolo per raccolta.
Indici composti (server MongoDB versione 3.6+)
Nell'API per MongoDB, gli indici composti sono necessari se la query deve ordinare più campi contemporaneamente. Per le query con più filtri che non devono essere ordinati, creare più indici di campo singolo anziché un indice composto per risparmiare sui costi di indicizzazione.
Un indice composto o un indice di campo singolo per ogni campo nell'indice composto fornisce le stesse prestazioni di filtro nelle query.
Gli indici composti nei campi annidati non sono supportati per impostazione predefinita a causa delle limitazioni con le matrici. Se il campo annidato non contiene una matrice, l'indice funziona come previsto. Se il campo annidato contiene una matrice (in qualsiasi punto del percorso), quel valore viene ignorato nell'indice.
Ad esempio, un indice composto contenente people.dylan.age, funziona in questo caso perché non c’è nessuna matrice nel percorso:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Questo stesso indice composto non funziona in questo caso perché c’è una matrice nel percorso:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Questa funzionalità può essere abilitata per l'account del database abilitando la funzionalità 'EnableUniqueCompoundNestedDocs'.
Nota
Non è possibile creare indici composti su matrici.
Il comando seguente crea un indice composto nei campi name e age:
db.coll.createIndex({name:1,age:1})
È possibile usare indici composti per ordinare in modo efficiente più campi contemporaneamente, come illustrato nell'esempio seguente:
db.coll.find().sort({name:1,age:1})
È anche possibile usare l'indice composto precedente per ordinare in modo efficiente una query con l'organizzazione opposta in tutti i campi. Ecco un esempio:
db.coll.find().sort({name:-1,age:-1})
Tuttavia, la sequenza dei percorsi nell'indice composto deve corrispondere esattamente alla query. Di seguito è riportato un esempio di query che richiede un indice composto aggiuntivo:
db.coll.find().sort({age:1,name:1})
Indici multichiave
Azure Cosmos DB crea indici multichiave per indicizzare il contenuto archiviato in matrici. Se si indicizza un campo con un valore di matrice, Azure Cosmos DB indicizza automaticamente ogni elemento nella matrice.
Indici geospaziali
Molti gestori geospaziali trarranno vantaggio dagli indici geospaziali. Attualmente, Azure Cosmos DB per MongoDB supporta gli indici 2dsphere. L'API non supporta ancora gli indici 2d.
Di seguito è riportato un esempio di creazione di un indice geospaziale nel campo location:
db.coll.createIndex({ location : "2dsphere" })
Indici di testo
Azure Cosmos DB per MongoDB attualmente non supporta gli indici di testo. Per le query di ricerca di testo sulle stringhe, si consiglia di usare l'integrazione di Ricerca con l’intelligenza artificiale di Azure con Azure Cosmos DB.
Indici con caratteri jolly
È possibile usare gli indici jolly per supportare query su campi sconosciuti. Supponiamo di avere una raccolta che contiene dati sulle famiglie.
Di seguito è riportato parte di un documento di esempio in quella raccolta:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
Ecco un altro esempio, questa volta con un set leggermente diverso di proprietà in children:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
In questa raccolta, i documenti possono avere molte proprietà. Se si desidera indicizzare tutti i dati nella matrice children, sono disponibili due opzioni: creare indici separati per ogni singola proprietà o creare un indice jolly per l'intera matricechildren.
Creare un indice jolly
Il comando seguente crea un indice jolly in qualsiasi proprietà all'interno di children:
db.coll.createIndex({"children.$**" : 1})
A differenza di MongoDB, gli indici jolly possono supportare più campi nei predicati di query. Non ci sarà alcuna differenza nelle prestazioni delle query se si usa un singolo indice jolly anziché creare un indice separato per ogni proprietà.
È possibile creare i tipi di indice seguenti usando la sintassi con caratteri jolly:
- Campo singolo
- GeoSpatial
Indicizzazione di tutte le proprietà
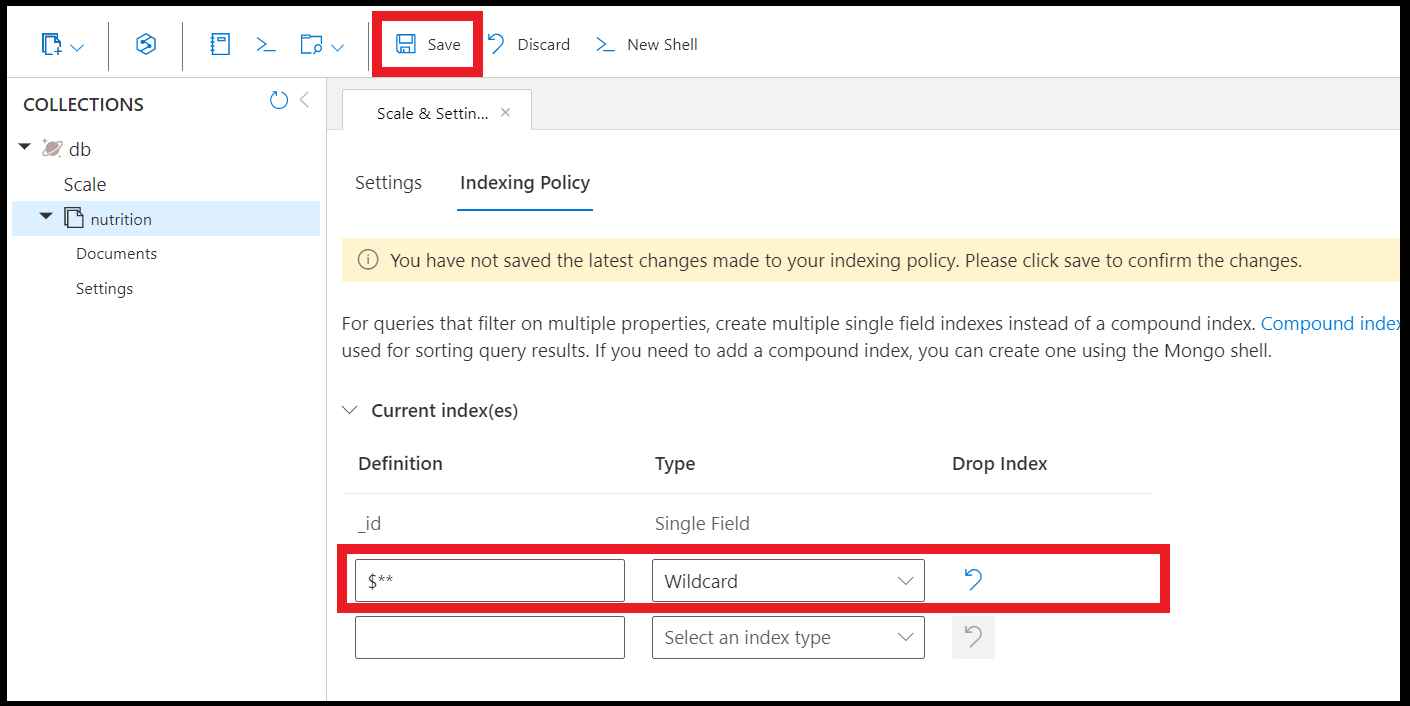
Ecco come creare un indice jolly in tutti i campi:
db.coll.createIndex( { "$**" : 1 } )
È anche possibile creare indici jolly usando Esplora Dati nel portale di Azure:
Nota
Se si è cominciato a sviluppare da poco, si consiglia vivamente di iniziare con un indice jolly in tutti i campi. In questo modo è possibile semplificare lo sviluppo e semplificare l'ottimizzazione delle query.
I documenti con molti campi avranno un addebito elevato di unità richiesta (UR) per operazioni di scrittura e aggiornamenti. Quindi, se il carico di lavoro comporta un’intensa attività di scrittura, si consiglia di scegliere percorsi di indice individuali anziché usare indici jolly.
Nota
Il supporto per l'indice univoco nelle raccolte esistenti con dei dati è disponibile nell’anteprima. Questa funzionalità può essere abilitata per l'account del database tramite la funzionalità 'EnableUniqueIndexReIndex'.
Limiti
Gli indici jolly non supportano nessun tipo di indice o di proprietà seguenti:
- Composto
- TTL
- Univoco
A differenza di MongoDB, in Azure Cosmos DB per MongoDB non è possibile usare indici jolly per:
Creare un indice con carattere jolly che includa più campi specifici
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )Creare un indice con carattere jolly che escluda più campi specifici
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
In alternativa, è possibile creare più indici con carattere jolly.
Proprietà degli indici
Le operazioni seguenti sono comuni per gli account che sono compatibili con il protocollo wire versione 4.0 e gli account compatibili con le versioni precedenti. Sono disponibili anche altre informazioni sugli indici supportati e proprietà indicizzate.
Indici univoci
Gli indici univoci sono utili per impedire che due o più documenti contengano lo stesso valore per i campi indicizzati.
Il comando seguente crea un indice univoco nel campo student_id:
globaldb:PRIMARY> db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
Per le raccolte partizionate, è necessario specificare la chiave di partizione (partizione) per creare un indice univoco. In altre parole, tutti gli indici univoci di una raccolta partizionata sono indici composti in cui uno dei campi è la chiave di partizione. Il primo campo nell'ordine deve essere la chiave di partizione.
I comandi seguenti servono a creare una raccolta partizionata coll (la chiave di partizione è university) con un indice univoco nei campi student_id e university:
globaldb:PRIMARY> db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
globaldb:PRIMARY> db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
Nell'esempio precedente, omettendo la clausola "university":1 si ottiene un errore con il messaggio seguente:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Limiti
È necessario creare indici univoci mentre la raccolta è vuota.
Gli indici univoci nei campi annidati non sono supportati per impostazione predefinita a causa delle limitazioni con le matrici. Se il campo annidato non contiene una matrice, l'indice funzionerà come previsto. Se il campo annidato contiene una matrice (in qualsiasi punto del percorso), quel valore verrà ignorato nell'indice univoco e l'univocità non verrà mantenuta per quel valore.
Ad esempio, un indice univoco in people.tom.age funzionerà in questo caso perché non c’è una matrice nel percorso:
{ "people": { "tom": { "age": "25" }, "mark": { "age": "30" } } }
ma non funzionerà in questo caso perché nel percorso c’è una matrice:
{ "people": { "tom": [ { "age": "25" } ], "mark": [ { "age": "30" } ] } }
Questa funzionalità può essere abilitata per l'account del database abilitando la funzionalità 'EnableUniqueCompoundNestedDocs'.
Indici TTL
Per abilitare la scadenza dei documenti in una raccolta specifica, è necessario creare un indiceTTL (Time-to-Live). Un indice TTL è un indice nel campo _ts con un valore expireAfterSeconds.
Esempio:
globaldb:PRIMARY> db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
Il comando precedente elimina tutti i documenti nella raccolta db.coll che non sono stati modificati negli ultimi 10 secondi.
Nota
Il campo _ts è dedicato unicamente ad Azure Cosmos DB e non è accessibile dai client MongoDB. Si tratta di una proprietà di sistema riservata che contiene il timestamp dell'ultima modifica del documento.
Monitorare lo stato dell'indice
La versione 3.6+ di Azure Cosmos DB per MongoDB supporta il comando currentOp() per monitorare lo stato di avanzamento dell'indice su un'istanza del database. Con questo comando si ottiene un documento contenente informazioni sulle operazioni in corso su un'istanza del database. Usare il comando currentOp per monitorare tutte le operazioni in corso in MongoDB nativo. In Azure Cosmos DB per MongoDB questo comando supporta solo il monitoraggio dell'operazione sull'indice.
Ecco alcuni esempi che mostrano come usare il comando currentOp per monitorare l'avanzamento dell'indice:
Ottenere lo stato di avanzamento dell'indice per una raccolta:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})Ottenere lo stato di avanzamento dell'indice per tutte le raccolte in un database:
db.currentOp({"command.$db": <databaseName>})Ottenere lo stato di avanzamento dell'indice per tutti i database e le raccolte in un account Azure Cosmos DB:
db.currentOp({"command.createIndexes": { $exists : true } })
Esempi di output dello stato di avanzamento dell'indice
Le informazioni sullo stato di avanzamento dell'indice mostrano la percentuale di avanzamento dell'operazione sull'indice corrente. Di seguito è riportato un esempio che mostra il formato del documento di output per diverse fasi dell'avanzamento dell'indice:
Un'operazione sull'indice su una raccolta "foo" e un database "bar" completo al 60% avrà il documento di output seguente. Il campo
Inprog[0].progress.totalmostra 100 come percentuale di completamento finale.{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 60 %", "progress" : { "done" : 60, "total" : 100 }, …………..….. } ], "ok" : 1 }Se un'operazione sull'indice è stata appena avviata in una raccolta "foo" e in un database "bar", il documento di output potrebbe mostrare lo stato di avanzamento dello 0% fino a quando non raggiunge un livello misurabile.
{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 0 %", "progress" : { "done" : 0, "total" : 100 }, …………..….. } ], "ok" : 1 }Al termine dell'operazione sull'indice in corso, il documento di output mostra le operazioni
inprogvuote.{ "inprog" : [], "ok" : 1 }
Aggiornamenti degli indici in background
Indipendentemente dal valore specificato per la proprietà Indice in background, gli aggiornamenti dell'indice vengono sempre eseguiti in background. Poiché gli aggiornamenti degli indici utilizzano unità richiesta (UR) con una priorità inferiore rispetto ad altre operazioni di database, le modifiche all'indice non comportano tempi di inattività per scritture, aggiornamenti o eliminazioni.
L’aggiunta di un nuovo indice non ha alcun impatto sulla disponibilità di lettura. Le query utilizzeranno nuovi indici una volta completata la trasformazione dell'indice. Durante la trasformazione dell'indice, il motore di query continuerà a usare gli indici esistenti. Pertanto, durante la trasformazione dell'indicizzazione, si avranno prestazioni di lettura simili a quelle che si avevano prima di modificare l'indicizzazione. Quando si aggiungono nuovi indici, non esiste alcun rischio di risultati di query incompleti o incoerenti.
Quando si rimuovono gli indici e si eseguono immediatamente query con filtri sugli indici eliminati, i risultati potrebbero essere incoerenti e incompleti fino al termine della trasformazione dell'indice. Se si rimuovono gli indici, il motore di query non fornisce risultati coerenti o completi quando le query filtrano in base a questi indici appena rimossi. La maggior parte degli sviluppatori non elimina gli indici e prova immediatamente a eseguire query su di essi. Quindi, questa situazione è praticamente improbabile.
Nota
È possibile monitorare lo stato dell'indice.
Comando ReIndex
Il comando reIndex ricrea tutti gli indici di una raccolta. In alcuni rari casi, le prestazioni delle query o altri problemi di indice nella raccolta possono essere risolti eseguendo il comando reIndex. Se si verificano problemi con l'indicizzazione, si consiglia di ricreare gli indici con il comando reIndex.
È possibile eseguire il comando reIndex usando la sintassi seguente:
db.runCommand({ reIndex: <collection> })
È possibile usare la sintassi seguente per verificare se l'esecuzione del comando reIndex migliorerebbe le prestazioni delle query nella raccolta:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Output di esempio:
{
"database" : "myDB",
"collection" : "myCollection",
"provisionedThroughput" : 400,
"indexes" : [
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
},
{
"v" : 1,
"key" : {
"b.$**" : 1
},
"name" : "b.$**_1",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
}
],
"ok" : 1
}
Se reIndex migliorerà le prestazioni delle query, requiresReIndex sarà esatto. Se reIndex non migliorerà le prestazioni delle query, questa proprietà verrà omessa.
Eseguire la migrazione di raccolte con indici
Attualmente, è possibile creare indici univoci solo quando la raccolta non contiene documenti. Gli strumenti di migrazione di MongoDB più diffusi cercano di creare gli indici univoci dopo l'importazione dei dati. Per aggirare questo problema, è possibile creare manualmente le raccolte e gli indici univoci corrispondenti anziché usare lo strumento di migrazione. (È possibile ottenere questo comportamento per mongorestore usando il flag --noIndexRestore nella riga di comando).
Indicizzazione per MongoDB versione 3.2
Le funzionalità di indicizzazione disponibili e le impostazioni predefinite sono diverse per gli account Azure Cosmos DB compatibili con la versione 3.2 del protocollo di collegamento MongoDB. È possibile controllare la versione dell'account e eseguire l'aggiornamento per passare alla versione 3.6.
Se si usa la versione 3.2, questa sezione descrive le differenze principali con le versioni 3.6+.
Eliminazione degli indici predefiniti (versione 3.2)
A differenza delle versioni 3.6+ di Azure Cosmos DB per MongoDB, la versione 3.2 indicizza ogni proprietà per impostazione predefinita. È possibile usare il comando seguente per eliminare questi indici predefiniti per una raccolta (coll):
> db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
Dopo l'eliminazione degli indici predefiniti, è possibile aggiungere altri indici come nella versione 3.6+.
Indici composti (versione 3.2)
Gli indici composti contengono riferimenti a più campi di un documento. Per creare un indice composto, eseguire l'aggiornamento per passare alla versione 3.6 o 4.0.
Indici jolly (versione 3.2)
Per creare un indice jolly, eseguire l'aggiornamento per passare alla versione 4.0 o 3.6.
Passaggi successivi
- Indicizzazione in Azure Cosmos DB
- Impostare la scadenza automatica dei dati in Azure Cosmos DB con la durata (TTL)
- Per informazioni sulla relazione tra il partizionamento e l'indicizzazione, vedere l'articolo su come Eseguire query su un contenitore di Azure Cosmos DB.
- Si sta tentando di pianificare la capacità per una migrazione ad Azure Cosmos DB? È possibile usare le informazioni del cluster di database esistente per la pianificazione della capacità.
- Se si conosce solo il numero di vCore e server nel cluster di database esistente, leggere le informazioni sulla stima delle unità richieste con vCore o vCPU
- Se si conosce la frequenza delle richieste tipiche per il carico di lavoro corrente del database, leggere le informazioni sulla stima delle unità richieste con lo strumento di pianificazione della capacità di Azure Cosmos DB