Integrazione e recapito continui in Azure Data Factory
SI APPLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
L'integrazione continua è la procedura che consente di testare ogni modifica apportata alla base di codici automaticamente e quanto prima possibile. Il recapito continuo segue i test eseguiti durante l'integrazione continua ed esegue il push delle modifiche in un sistema di gestione temporanea o di produzione.
In Azure Data Factory per integrazione e recapito continui (CI/CD) si intende lo spostamento delle pipeline di Data Factory da un ambiente (sviluppo, test, produzione) a un altro. Azure Data Factory usa modelli di Azure Resource Manager per archiviare la configurazione di varie entità ADF (pipeline, set di dati, flussi di dati e così via). Per alzare di livello una data factory a un altro ambiente, esistono due metodi consigliati:
- Distribuzione automatizzata tramite l'integrazione di Data Factory con Azure Pipelines
- Caricamento manuale di un modello di Resource Manager usando l'integrazione di Data Factory UX con Azure Resource Manager.
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Ciclo di vita CI/CD
Nota
Per altre informazioni, vedere Miglioramenti della distribuzione continua.
Di seguito è riportata una panoramica di esempio del ciclo di vita CI/CD in una data factory di Azure configurata con Azure Repos Git. Per altre informazioni su come configurare un repository Git, vedere Controllo del codice sorgente in Azure Data Factory.
Una data factory di sviluppo viene creata e configurata con Azure Repos Git. Tutti gli sviluppatori devono disporre dell'autorizzazione per creare risorse di Data Factory come pipeline e set di dati.
Uno sviluppatore crea un ramo di funzionalità per apportare una modifica. Viene eseguito il debug delle esecuzioni della pipeline con le modifiche più recenti. Per altre informazioni su come eseguire il debug di un'esecuzione di pipeline, vedere Sviluppo e debug iterativi con Azure Data Factory.
Dopo che uno sviluppatore è soddisfatto delle modifiche, crea una richiesta pull dal ramo di funzionalità al ramo principale o di collaborazione per ottenere le modifiche esaminate dai peer.
Dopo l'approvazione di una richiesta pull e le modifiche vengono unite nel ramo principale, le modifiche vengono pubblicate nella factory di sviluppo.
Quando il team è pronto a distribuire le modifiche in una factory di test o di test di accettazione utente, passa alla propria versione di Azure Pipelines e distribuisce la versione desiderata della factory di sviluppo nell'ambiente di test di accettazione utente. Questa distribuzione viene eseguita come parte di un'attività di Azure Pipelines e usa i parametri di modello di Resource Manager per applicare la configurazione appropriata.
Una volta verificate le modifiche nella factory di test, eseguire la distribuzione nella factory di produzione usando l'attività successiva della versione delle pipeline.
Nota
Solo la factory di sviluppo è associata a un repository Git. Le factory di test e di produzione non devono essere associate a un repository Git e devono essere aggiornate solo tramite una pipeline di Azure DevOps o tramite un modello di Resource Management.
Nell'immagine seguente vengono evidenziati i diversi passaggi di questo ciclo di vita.
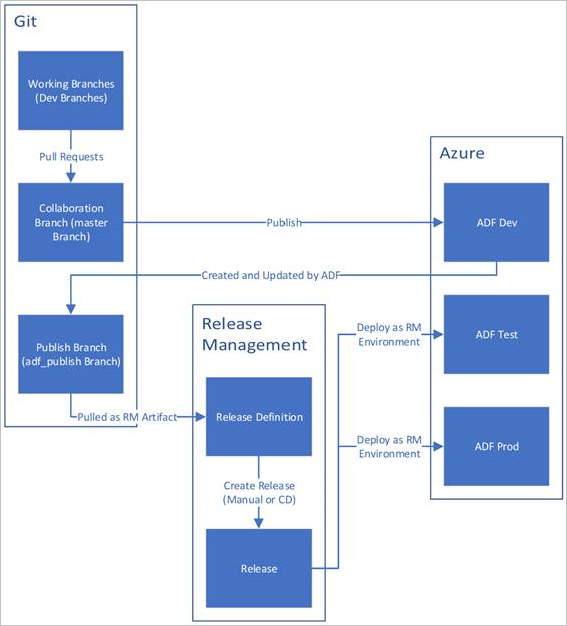
Procedure consigliate per la pipeline CI/CD
Se si usa l'integrazione di Git con la data factory e si dispone di una pipeline CI/CD che sposta le modifiche apportate dall'ambiente di sviluppo all'ambiente di test e successivamente all'ambiente di produzione, è consigliabile osservare le procedure consigliate seguenti:
Integrazione di Git. Configurare solo la data factory di sviluppo con l'integrazione di Git. Le modifiche all'ambiente di test e produzione vengono distribuite tramite CI/CD e non necessitano dell'integrazione di Git.
Script pre-distribuzione e post-distribuzione. Prima del passaggio di distribuzione di Resource Manager in CI/CD, è necessario completare determinate attività, ad esempio l'arresto e il riavvio dei trigger e l'esecuzione della pulizia. È consigliabile usare gli script di PowerShell prima e dopo l'attività di distribuzione. Per altre informazioni, vedere Aggiornamento di trigger attivi. Il team della data factory ha fornito uno script da usare alla fine di questa pagina.
Nota
Usare PrePostDeploymentScript.Ver2.ps1 se si vuole disattivare/ solo i trigger modificati anziché disattivare tutti i trigger durante CI/CD.
Avviso
Assicurarsi di usare PowerShell Core nell'attività ADO per eseguire lo script.
Avviso
Se non si usano le versioni più recenti del modulo PowerShell e Data Factory, è possibile che si verifichino errori di deserializzazione durante l'esecuzione dei comandi.
Runtime di integrazione e condivisione. I runtime di integrazione non cambiano spesso e sono simili in tutte le fasi di CI/CD. Data Factory prevede quindi di avere lo stesso nome, tipo e sottotipo del runtime di integrazione in tutte le fasi di CI/CD. Se si desidera condividere runtime di integrazione in tutte le fasi, è consigliabile usare una factory ternaria per contenere solo i runtime di integrazione condivisi. È possibile usare questa factory condivisa in tutti gli ambienti come tipo di runtime di integrazione collegato.
Nota
La condivisione del runtime di integrazione è disponibile solo per i runtime di integrazione self-hosted. I runtime di integrazione SSIS di Azure non supportano la condivisione.
Distribuzione gestita di endpoint privati. Se in una factory esiste già un endpoint privato e si tenta di distribuire un modello di Azure Resource Manager che contiene un endpoint privato con lo stesso nome ma con proprietà modificate, la distribuzione non riesce. In altre parole, è possibile distribuire correttamente un endpoint privato purché abbia le stesse proprietà di quello già esistente nella factory. Se una proprietà qualsiasi è diversa tra gli ambienti, è possibile eseguirne l'override parametrizzandola e fornendo il relativo valore durante la distribuzione.
Insieme di credenziali delle chiavi. Quando si usano servizi collegati le cui informazioni di connessione vengono archiviate in Azure Key Vault, è consigliabile conservare insiemi di credenziali delle chiavi separati per ambienti diversi. È anche possibile configurare i livelli di autorizzazione separati per ogni insieme di credenziali delle chiavi. Ad esempio, è possibile che non si voglia che i membri del team siano autorizzati ad accedere ai segreti di produzione. Se si segue questo approccio, è consigliabile mantenere gli stessi nomi dei segreti in tutte le fasi. Se si mantengono gli stessi nomi dei segreti, non è necessario parametrizzare ogni stringa di connessione negli ambienti CI/CD, perché l'unica cosa che cambia è il nome dell'insieme di credenziali delle chiavi, che è un parametro separato.
Denominazione delle risorse. A causa dei vincoli del modello di Resource Manager, possono verificarsi problemi nella distribuzione se le risorse contengono spazi nel nome. Il team di Azure Data Factory consiglia di usare il carattere "_" o "-" anziché gli spazi per le risorse. Ad esempio, "Pipeline_1" è un nome preferibile a "Pipeline 1".
Modifica del repository. ADF gestisce automaticamente il contenuto del repository GIT. La modifica o l'aggiunta manuale di file o cartelle non correlati in qualsiasi posizione nella cartella dei dati del repository Git di Azure Data Factory potrebbero causare errori di caricamento delle risorse. Ad esempio, la presenza di file con estensione bak può causare l'errore CI/CD di ADF, quindi devono essere rimossi per il caricamento di ADF.
Controllo dell'esposizione e flag di funzionalità. Quando si lavora in un team, esistono istanze in cui è possibile unire le modifiche, ma non si vuole che vengano eseguite in ambienti con privilegi elevati, ad esempio PROD e QA. Per gestire questo scenario, il team di Azure Data Factory consiglia il concetto DevOps di usare i flag di funzionalità. In Azure Data Factory è possibile combinare parametri globali e l'attività condizione if per nascondere i set di logica in base a questi flag di ambiente.
Per informazioni su come configurare un flag di funzionalità, vedere l'esercitazione video seguente:
Funzionalità non supportate
Per progettazione, Data Factory non consente il cherry-pick di commit o la pubblicazione selettiva delle risorse. Le pubblicazioni includeranno tutte le modifiche apportate nella data factory.
- Le entità della data factory dipendono l'una dall'altra. Ad esempio, i trigger dipendono dalle pipeline, le pipeline dipendono dai set di dati e da altre pipeline. La pubblicazione selettiva di un subset di risorse può causare comportamenti imprevisti ed errori.
- Nei rari casi in cui è necessaria la pubblicazione selettiva, provare a usare un hotfix. Per altre informazioni, vedere Ambiente di produzione degli hotfix.
Il team di Azure Data Factory non consiglia di assegnare controlli controllo degli accessi in base al ruolo di Azure a singole entità (pipeline, set di dati e così via) in una data factory. Se, ad esempio, uno sviluppatore ha accesso a una pipeline o a un set di dati, deve poter accedere a tutte le pipeline o ai set di dati nella data factory. Se si ritiene di dover implementare molti ruoli di Azure all'interno di una data factory, esaminare la distribuzione di una seconda data factory.
Non è possibile pubblicare da rami privati.
Non è attualmente possibile ospitare progetti in Bitbucket.
Non è attualmente possibile esportare e importare avvisi e matrici come parametri.
Nel repository di codice nel ramo adf_publish una cartella denominata 'PartialArmTemplates' viene attualmente aggiunta accanto alla cartella 'linkedTemplates', 'ARMTemplateForFactory.json' e 'ARMTemplateParametersForFactory.json' come parte della pubblicazione con il controllo del codice sorgente.
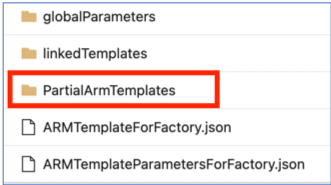
Il ramo "PartialArmTemplates" non verrà più pubblicato nel ramo adf_publish a partire dal 1° novembre 2021.
Non è necessaria alcuna azione a meno che non si usi 'PartialArmTemplates'. In caso contrario, passare a qualsiasi meccanismo supportato per le distribuzioni usando i file 'ARMTemplateForFactory.json' o 'linkedTemplates'.
Contenuto correlato
- Miglioramenti della distribuzione continua
- Automatizzare l'integrazione continua con le versioni di Azure Pipelines
- Alzare di livello manualmente un modello di Resource Manager a ogni ambiente
- Usare parametri personalizzati con un modello di Resource Manager
- Modelli di Resource Manager collegati
- Uso di un ambiente di produzione hotfix
- Script di pre-distribuzione di esempio e post-distribuzione