Trasformazione Aggregazione nel flusso di dati di mapping
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
I flussi di dati sono disponibili sia in Azure Data Factory che in Azure Synapse Pipelines. Questo articolo si applica ai flussi di dati di mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati usando un flusso di dati di mapping.
La trasformazione Aggregazione definisce le aggregazioni delle colonne nei flussi di dati. Usando il generatore di espressioni, è possibile definire tipi diversi di aggregazioni, ad esempio SUM, MIN, MAX e COUNT raggruppate in base a colonne esistenti o calcolate.
Raggruppa per
Selezionare una colonna esistente o creare una nuova colonna calcolata da usare come clausola group by per l'aggregazione. Per usare una colonna esistente, selezionarla nell'elenco a discesa. Per creare una nuova colonna calcolata, passare il puntatore del mouse sulla clausola e fare clic su Colonna calcolata. Verrà aperto il generatore di espressioni del flusso di dati. Dopo aver creato la colonna calcolata, immettere il nome della colonna di output nel campo Nome come . Se si desidera aggiungere un ulteriore gruppo per clausola, passare il puntatore del mouse su una clausola esistente e fare clic sull'icona con il segno più.
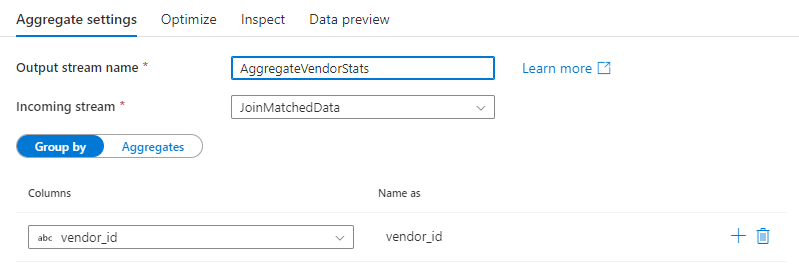
Una clausola group by è facoltativa in una trasformazione Aggregate.
Colonne di aggregazione
Passare alla scheda Aggregazioni per compilare espressioni di aggregazione. È possibile sovrascrivere una colonna esistente con un'aggregazione oppure creare un nuovo campo con un nuovo nome. L'espressione di aggregazione viene immessa nella casella di destra accanto al selettore del nome di colonna. Per modificare l'espressione, fare clic sulla casella di testo e aprire il generatore di espressioni. Per aggiungere altre colonne di aggregazione, fare clic su Aggiungi sopra l'elenco di colonne o sull'icona con il segno più accanto a una colonna di aggregazione esistente. Scegliere Aggiungi colonna o Aggiungi criteri di ricerca colonna. Ogni espressione di aggregazione deve contenere almeno una funzione di aggregazione.
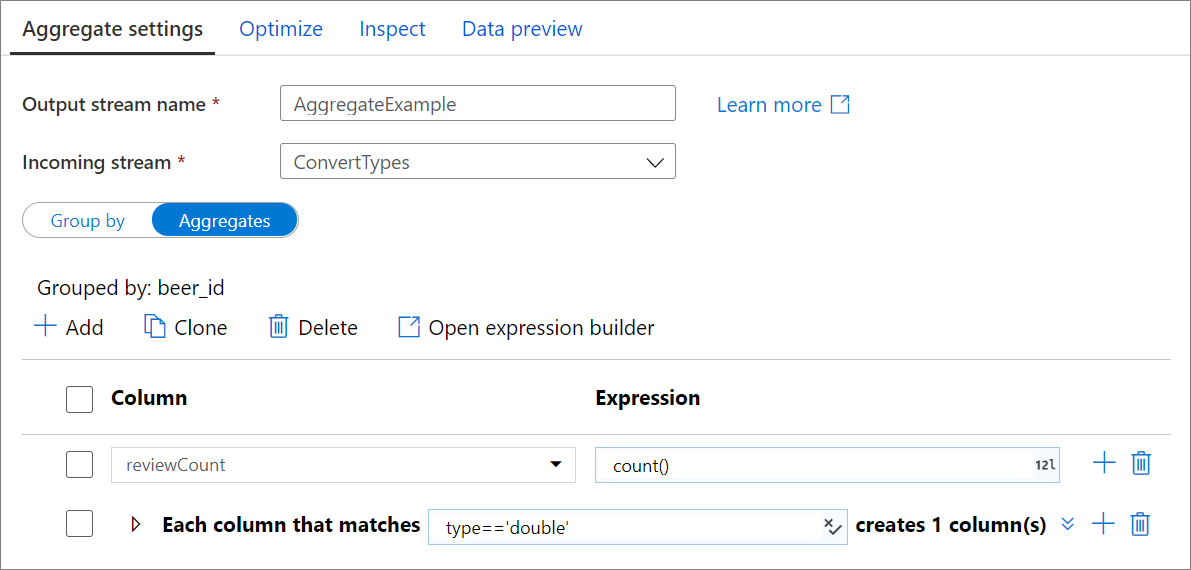
Nota
In modalità debug, il generatore di espressioni non può produrre anteprime dei dati con funzioni di aggregazione. Per visualizzare le anteprime dei dati per le trasformazioni di aggregazione, chiudere il generatore di espressioni e visualizzare i dati tramite la scheda 'Anteprima dati'.
Criteri delle colonne
Usare i criteri di colonna per applicare la stessa aggregazione a un set di colonne. Ciò è utile se si desidera rendere persistenti molte colonne dello schema di input man mano che vengono eliminate per impostazione predefinita. Usare un'euristica, first() ad esempio per rendere persistenti le colonne di input tramite l'aggregazione.
Riconnettere righe e colonne
Le trasformazioni di aggregazione sono simili alle query di selezione dell'aggregazione SQL. Le colonne non incluse nel gruppo per clausola o le funzioni di aggregazione non passano attraverso l'output della trasformazione di aggregazione. Se si desidera includere altre colonne nell'output aggregato, eseguire uno dei metodi seguenti:
- Usare una funzione di aggregazione,
last()ad esempio ofirst()per includere tale colonna aggiuntiva. - Ricongiunire le colonne al flusso di output usando il modello di self join.
Rimozione di righe duplicate
Un uso comune della trasformazione di aggregazione consiste nel rimuovere o identificare voci duplicate nei dati di origine. Questo processo è noto come deduplicazione. In base a un set di gruppi per chiavi, usare un'euristica della scelta per determinare quale riga duplicata conservare. L'euristica comune è first(), last(), max()e min(). Usare i criteri di colonna per applicare la regola a ogni colonna, ad eccezione del gruppo per colonne.

Nell'esempio precedente le colonne ProductID e Name vengono usate per il raggruppamento. Se due righe hanno gli stessi valori per queste due colonne, vengono considerati duplicati. In questa trasformazione di aggregazione, i valori della prima riga corrispondente verranno mantenuti e tutti gli altri verranno eliminati. Usando la sintassi dei criteri di colonna, tutte le colonne i cui nomi non ProductID sono e Name vengono mappati al nome della colonna esistente e dato il valore delle prime righe corrispondenti. Lo schema di output è uguale allo schema di input.
Per gli scenari di convalida dei dati, la count() funzione può essere usata per contare il numero di duplicati presenti.
Script del flusso di dati
Sintassi
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Esempio
L'esempio seguente accetta un flusso MoviesYear in ingresso e raggruppa le righe in base alla colonna year. La trasformazione crea una colonna avgrating di aggregazione che restituisce la media della colonna Rating. Questa trasformazione di aggregazione è denominata AvgComedyRatingsByYear.
Nell'interfaccia utente questa trasformazione è simile all'immagine seguente:
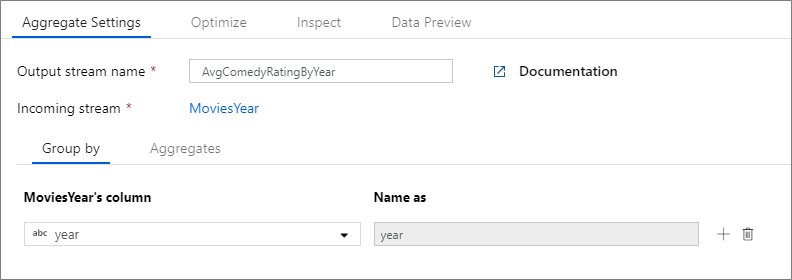

Lo script del flusso di dati per questa trasformazione è nel frammento di codice seguente.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
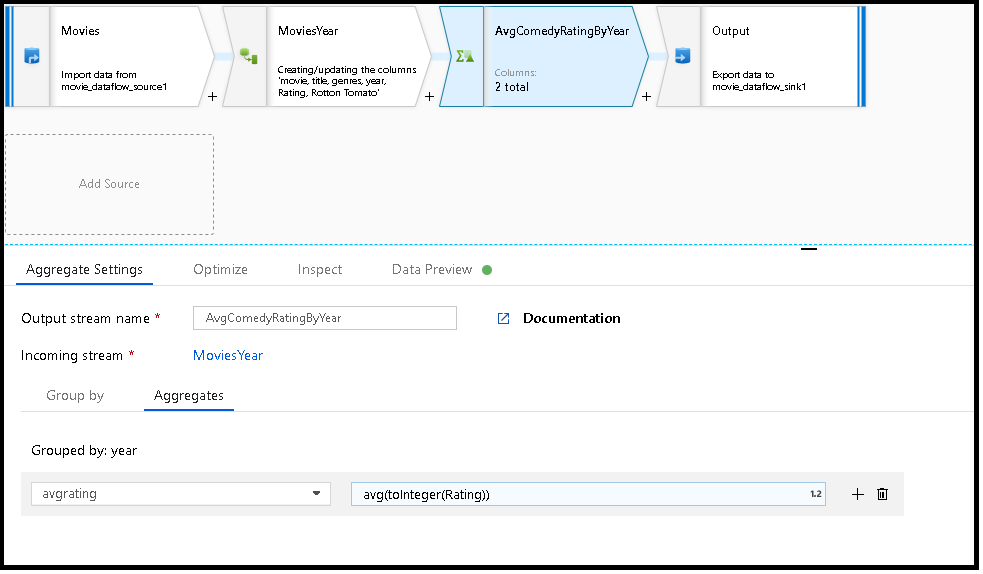
MoviesYear: colonna derivata che definisce le colonne AvgComedyRatingByYearanno e titolo: trasformazione Aggregazione per la classificazione media delle comede raggruppate per anno avgrating: nome della nuova colonna creata per contenere il valore aggregato
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Contenuto correlato
- Definire un'aggregazione basata su finestra usando la trasformazione Finestra