Trasformazione tramite join nel flusso di dati per mapping
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
I flussi di dati sono disponibili sia in Azure Data Factory che in Azure Synapse Pipelines. Questo articolo si applica ai flussi di dati di mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati usando un flusso di dati di mapping.
Usare la trasformazione tramite join per combinare i dati di due origini o flussi in un flusso di dati di mapping. Nel flusso di output saranno contenute tutte le colonne di entrambe le origini, associate in base a una condizione di join.
Tipi di join
I flussi di dati di mapping supportano attualmente cinque tipi di join.
Inner join
L'operazione inner join restituisce solo le righe con valori corrispondenti in entrambe le tabelle.
Left outer join
L'operazione left outer join restituisce tutte le righe del flusso di sinistra e i record corrispondenti del flusso di destra. Se una riga del flusso di sinistra non ha corrispondenze, le colonne di output del flusso di destra vengono impostate su NULL. L'output sarà quindi costituito dalle righe restituite da un inner join, più le righe senza corrispondenza del flusso di sinistra.
Nota
In alcuni casi, è possibile che il motore Spark usato dai flussi di dati abbia esito negativo a causa di possibili prodotti cartesiani nelle condizioni di join. In questo caso, è possibile passare a un cross join personalizzato e inserire manualmente la condizione di join. Questo può determinare un rallentamento delle prestazioni nei flussi di dati, poiché è possibile che il motore di esecuzione debba calcolare e filtrare tutte le righe di entrambi i lati della relazione.
Right outer join
L'operazione right outer join restituisce tutte le righe del flusso di destra e i record corrispondenti del flusso di sinistra. Se una riga del flusso di destra non ha corrispondenze, le colonne di output del flusso di sinistra vengono impostate su NULL. L'output sarà quindi costituito dalle righe restituite da un inner join, più le righe senza corrispondenza del flusso di destra.
Full outer join
L'operazione full outer join restituisce tutte le colonne e le righe di entrambi i lati con valori NULL relativi alle colonne che non hanno corrispondenze.
Cross join personalizzato
L'operazione cross join restituisce il prodotto incrociato dei due flussi in base a una condizione. Se si usa una condizione diversa dall'uguaglianza, specificare un'espressione personalizzata come condizione di cross join. Il flusso di output sarà costituito da tutte le righe che soddisfano la condizione di join.
È possibile usare questo tipo di join per i join non uguali e le condizioni OR.
Se si vuole produrre esplicitamente un prodotto cartesiano completo, usare la trasformazione Colonna derivata in ognuno dei due flussi indipendenti prima del join, in modo da creare una chiave sintetica per la corrispondenza. Creare, ad esempio, una nuova colonna in Colonna derivata nell'ambito di ogni flusso denominato SyntheticKey e impostarla uguale a 1. Usare quindi a.SyntheticKey == b.SyntheticKey come espressione di join personalizzata.
Nota
Assicurarsi di includere nel cross join personalizzato almeno una colonna di ogni lato della relazione sinistra e di quella destra. L'esecuzione di cross join con valori statici anziché con colonne di entrambi i lati produce analisi complete dell'intero set di dati, con una conseguente riduzione delle prestazioni del flusso di dati.
Join fuzzy
È possibile scegliere di eseguire il join in base alla logica di join fuzzy anziché alla corrispondenza esatta dei valori di colonna attivando l'opzione di controllo "Usa corrispondenza fuzzy".
- Combina parti di testo: usare questa opzione per trovare corrispondenze rimuovendo lo spazio tra le parole. Ad esempio, Data Factory viene confrontato con DataFactory se questa opzione è abilitata.
- Colonna punteggio di somiglianza: è possibile scegliere facoltativamente di archiviare il punteggio di corrispondenza per ogni riga in una colonna immettendo qui un nuovo nome di colonna per archiviare tale valore.
- Soglia di somiglianza: scegliere un valore compreso tra 60 e 100 come corrispondenza percentuale tra i valori nelle colonne selezionate.
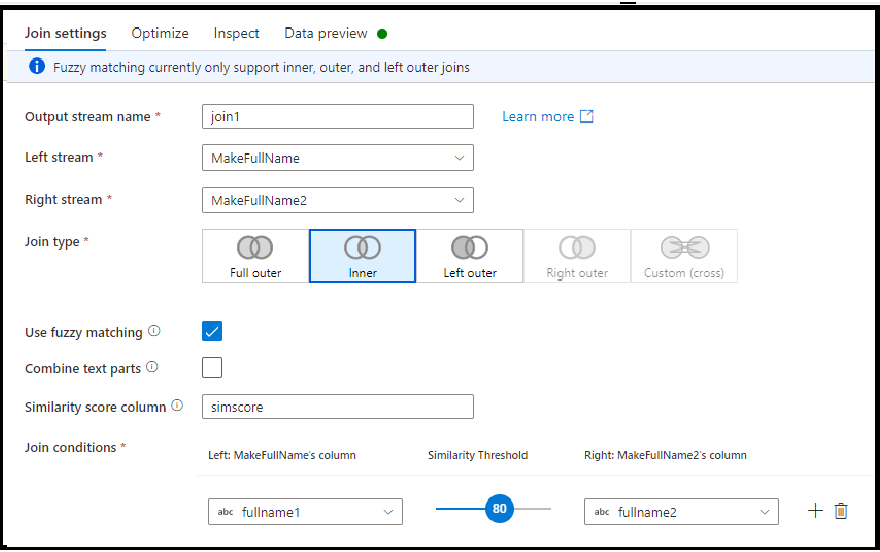
Nota
La corrispondenza fuzzy attualmente funziona solo con i tipi di colonna stringa e con tipi inner, left outer e full outer join. È necessario disattivare l'ottimizzazione della trasmissione quando si usano join corrispondenti fuzzing.
Configurazione
- Nell'elenco a discesa Right stream (Flusso destro) scegliere il flusso di dati di cui si vuole eseguire il join.
- Selezionare il Tipo di join
- Scegliere le colonne chiave su cui si desidera trovare la corrispondenza per la condizione di join. Per impostazione predefinita, il flusso di dati cerca l'uguaglianza tra una colonna per ogni flusso. Per eseguire il confronto tramite un valore calcolato, passare il puntatore del mouse sull'elenco a discesa della colonna e selezionare Colonna calcolata.
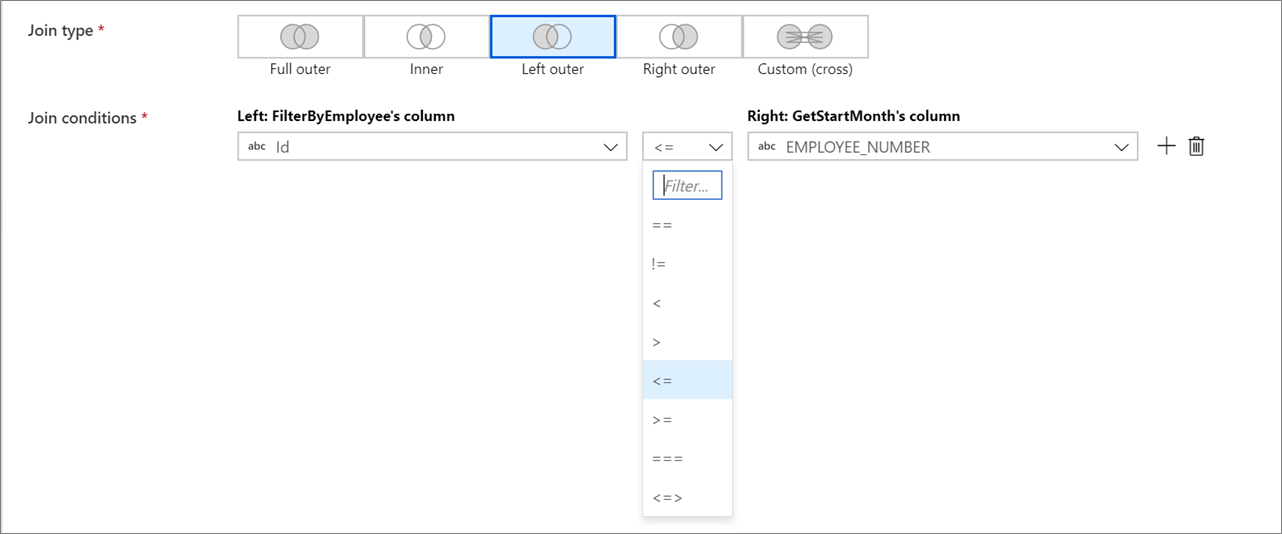
Join non uguali
Per usare un operatore condizionale, ad esempio diverso da (!=) o maggiore di (>) nelle condizioni di join, modificare l'elenco a discesa dell'operatore tra le due colonne. Per i join non uguali è necessario che almeno uno dei due flussi venga trasmesso usando la broadcast fissa nella scheda Ottimizza.
Ottimizzazione delle prestazioni di join
A differenza di Merge join in strumenti come SSIS, la trasformazione tramite join non rappresenta un'operazione di merge obbligatoria. Le chiavi di join non richiedono l'ordinamento. L'operazione di join viene eseguita in base all'operazione di join ottimale in Spark, ovvero join Broadcast o lato mappa.
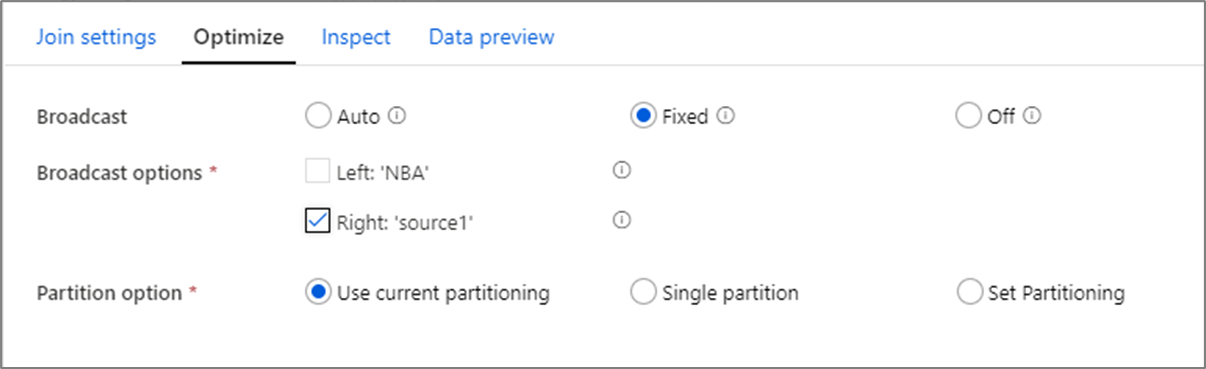
Nella trasformazione di join, ricerche ed exists, se uno o entrambi i flussi di dati rientrano nella memoria del nodo di lavoro, è possibile ottimizzare le prestazioni abilitando la trasmissione. Per impostazione predefinita, il motore Spark deciderà automaticamente se trasmettere o meno un lato. Per scegliere manualmente il lato da trasmettere, selezionare Fisso.
Non è consigliabile disabilitare la trasmissione tramite l'opzione Off a meno che i join non siano in errore di timeout.
Self-join
Per eseguire il self-join di un flusso di dati con se stesso, creare un alias di un flusso esistente con una trasformazione Select. Creare un nuovo ramo facendo clic sull'icona a forma di più accanto a una trasformazione e selezionando Nuovo ramo. Aggiungere una trasformazione SELECT per creare un alias del flusso originale. Aggiungere una trasformazione join e scegliere il flusso originale come flusso di sinistra e "trasformazione" come flusso di destra.
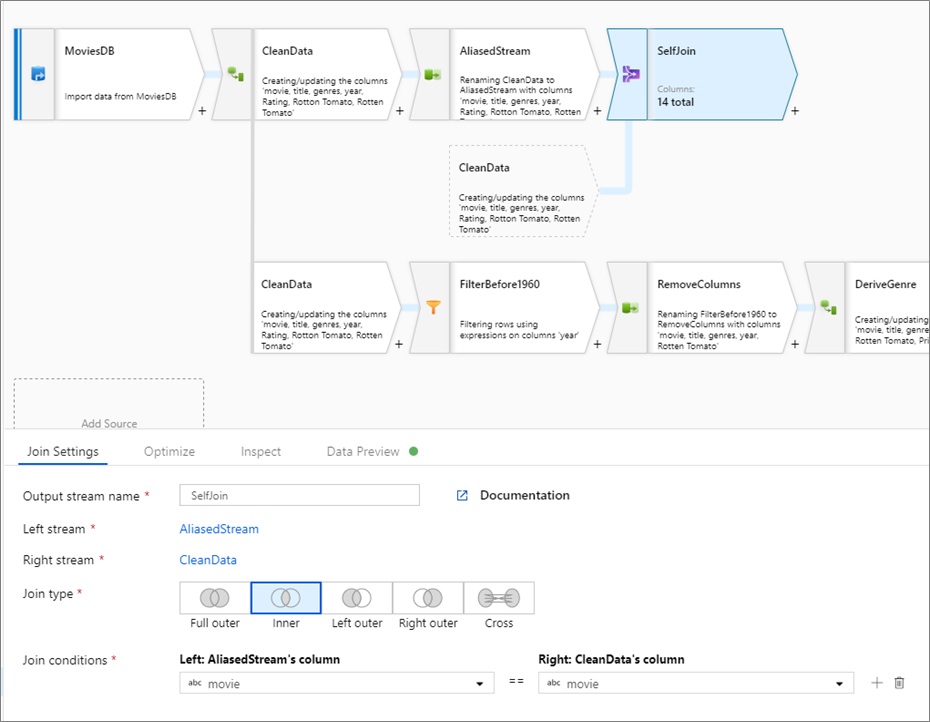
Test delle condizioni di join
Quando si testa una trasformazione tramite join con anteprima dati in modalità di debug, usare un piccolo set di dati noti. Quando si campionano righe da un set di dati di grandi dimensioni, non è possibile prevedere quali righe e chiavi verranno lette per il test. Il risultato è non deterministico, vale a dire che le condizioni di join potrebbero non restituire corrispondenze.
Script del flusso di dati
Sintassi
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
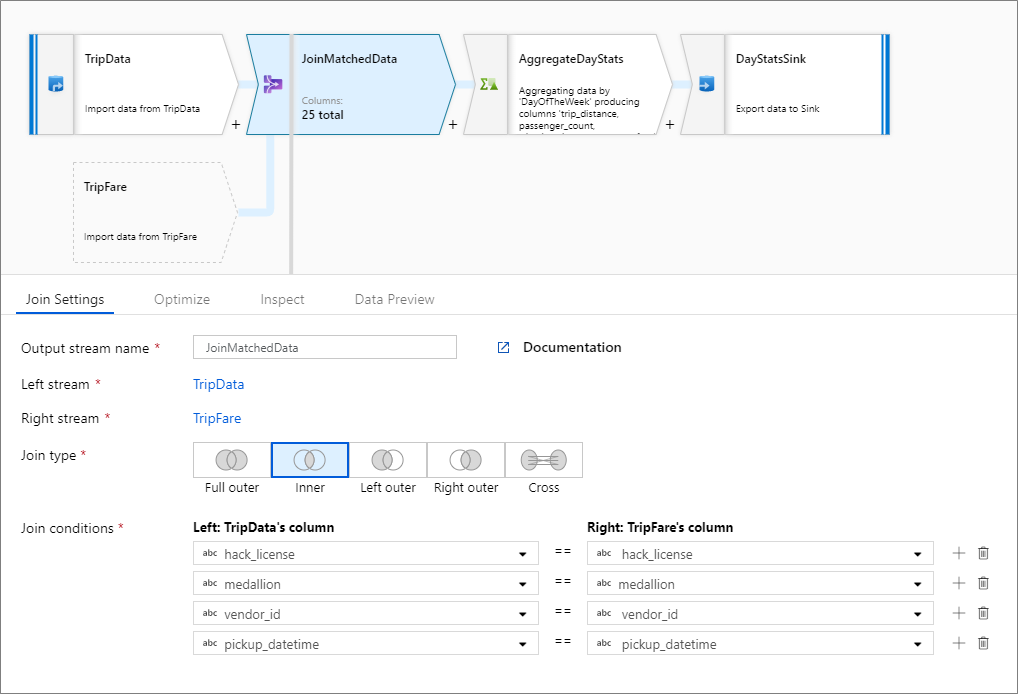
Esempio di Inner join
Nell'esempio seguente viene illustrata una trasformazione join denominata JoinMatchedData che accetta il flusso sinistro TripData e il flusso destro TripFare. La condizione di join è l'espressione hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime} che restituisce true se esiste una corrispondenza tra le colonne hack_license, medallion, vendor_id e pickup_datetime di ogni flusso. Il joinType è 'inner'. La trasmissione verrà abilitata solo nel flusso sinistro e broadcast avrà quindi il valore 'left'.
Nell'interfaccia utente questa trasformazione è simile all'immagine seguente:

Lo script del flusso di dati per questa trasformazione si trova nel frammento di codice seguente:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
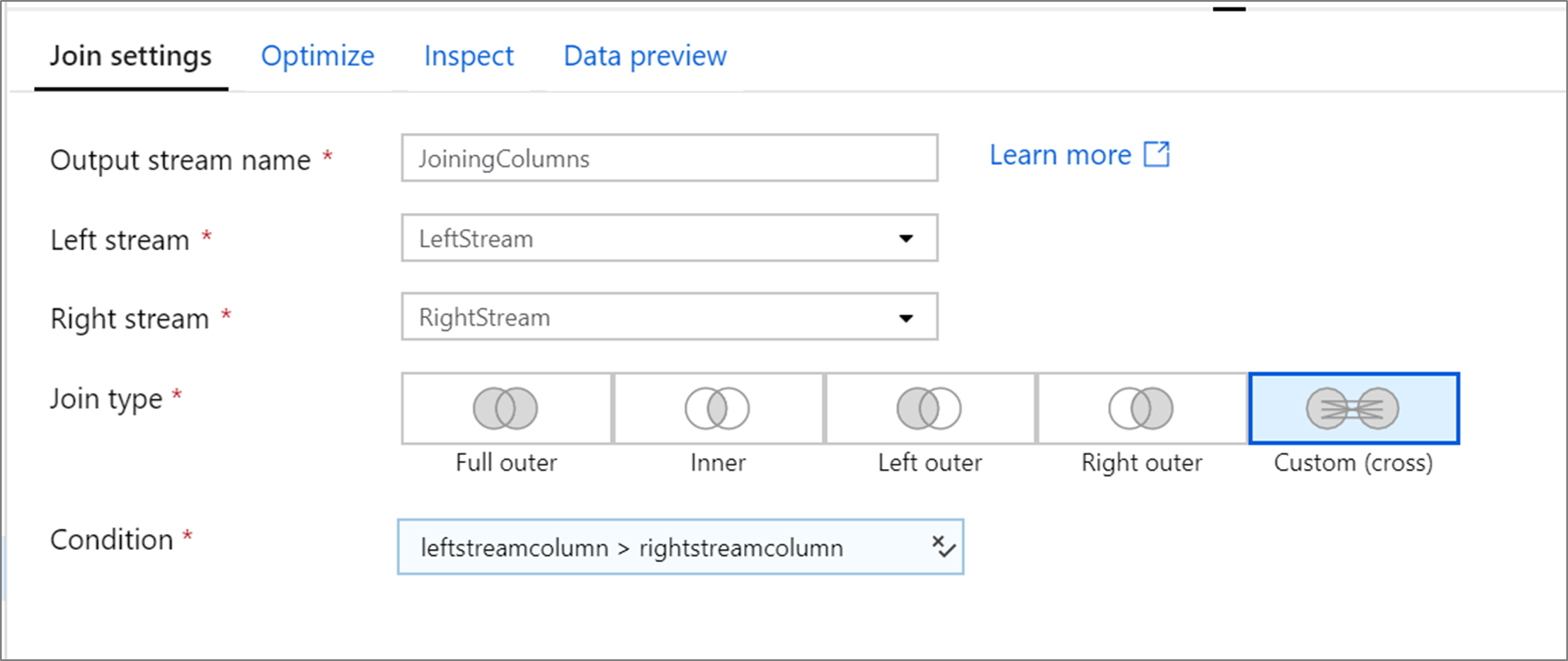
Esempio di cross join personalizzato
Nell'esempio seguente viene illustrata una trasformazione join denominata JoiningColumns che accetta il flusso sinistro LeftStream e il flusso destro RightStream. Questa trasformazione accetta due flussi e unisce tutte le righe in cui la colonna leftstreamcolumn è maggiore della colonna rightstreamcolumn. Il joinType è cross. La trasmissione non è abilitata e broadcast avrà quindi il valore 'none'.
Nell'interfaccia utente questa trasformazione è simile all'immagine seguente:
Lo script del flusso di dati per questa trasformazione si trova nel frammento di codice seguente:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Contenuto correlato
Dopo aver unito i dati, creare un colonna derivata ed effettuare il sink dei dati a un archivio dati di destinazione.