Eseguire la copia bulk da un database con una tabella di controllo
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
Per copiare dati da un data warehouse in Oracle Server, Netezza, Teradata o SQL Server in Azure Synapse Analytics, è necessario caricare grandi quantità di dati da più tabelle. I dati in genere devono essere partizionati in ogni tabella, in modo che sia possibile caricare righe con più thread in parallelo da una singola tabella. Questo articolo descrive un modello da usare in questi scenari.
Nota
Per copiare dati da un numero ridotto di tabelle con un volume di dati relativamente ridotto ad Azure Synapse Analytics, è più efficiente usare lo strumento Copia dati di Azure Data Factory. Il modello descritto in questo articolo è più avanzato di quello effettivamente necessario per questo scenario.
Informazioni sul modello di soluzione
Questo modello recupera un elenco di partizioni del database di origine da copiare da una tabella di controllo esterna. Esegue quindi l'iterazione su ogni partizione nel database di origine e copia i dati nella destinazione.
Il modello contiene tre attività:
- Ricerca recupera l'elenco delle partizioni del database di origine da una tabella di controllo esterna.
- ForEach ottiene l'elenco di partizioni dall'attività di ricerca ed esegue l'iterazione di ogni partizione nell'attività di copia.
- Copia esegue la copia di ciascuna partizione dall'archivio del database di origine all'archivio di destinazione.
Il modello definisce i parametri seguenti:
- Control_Table_Name è la tabella di controllo esterna, in cui è archiviato l'elenco delle partizioni per il database di origine.
- Control_Table_Schema_PartitionID è il nome della colonna nella tabella di controllo esterna in cui è archiviato ogni ID partizione. Assicurarsi che l'ID partizione sia univoco per ogni partizione nel database di origine.
- Control_Table_Schema_SourceTableName è il nome della tabella di controllo esterna in cui è archiviato ogni nome di tabella del database di origine.
- Control_Table_Schema_FilterQuery è il nome della colonna nella tabella di controllo esterna in cui è archiviata la query di filtro con cui ottenere i dati da ogni partizione nel database di origine. Ad esempio, se i dati sono stati partizionati per anno, la query archiviata in ogni riga potrebbe essere simile a 'select * from datasource where LastModifytime >= ''2015-01-01 00:00:00'' e LastModifytime <= ''2015-12-31 23:59:59.999'''' .
- Data_Destination_Folder_Path è il percorso in cui i dati vengono copiati nell'archivio di destinazione (applicabile quando la destinazione scelta è "File system" o "Azure Data Lake Storage Gen1").
- Data_Destination_Container è il percorso della cartella radice in cui i dati vengono copiati nell'archivio di destinazione.
- Data_Destination_Directory è il percorso di directory sotto la radice in cui i dati vengono copiati nell'archivio di destinazione.
Gli ultimi tre parametri, che definiscono il percorso nell'archivio di destinazione, sono visibili solo se la destinazione scelta è l'archiviazione basata su file. Se si sceglie "Azure Synapse Analytics" come archivio di destinazione, questi parametri non sono necessari. I nomi delle tabelle e lo schema in Azure Synapse Analytics devono tuttavia corrispondere a quelli nel database di origine.
Come usare questo modello di soluzione
Creare una tabella di controllo in SQL Server o database SQL di Azure per archiviare l'elenco di partizioni del database di origine per la copia bulk. Nell'esempio seguente sono presenti cinque partizioni nel database di origine. Tre partizioni sono per la tabella datasource_table e due per project_table. La colonna LastModifytime viene usata per partizionare i dati nella tabella datasource_table dal database di origine. La query usata per leggere la prima partizione è 'select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' e LastModifytime <= ''2015-12-31 23:59:59.999''''. È possibile usare una query simile per la lettura dei dati da altre partizioni.
Create table ControlTableForTemplate ( PartitionID int, SourceTableName varchar(255), FilterQuery varchar(255) ); INSERT INTO ControlTableForTemplate (PartitionID, SourceTableName, FilterQuery) VALUES (1, 'datasource_table','select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''), (2, 'datasource_table','select * from datasource_table where LastModifytime >= ''2016-01-01 00:00:00'' and LastModifytime <= ''2016-12-31 23:59:59.999'''), (3, 'datasource_table','select * from datasource_table where LastModifytime >= ''2017-01-01 00:00:00'' and LastModifytime <= ''2017-12-31 23:59:59.999'''), (4, 'project_table','select * from project_table where ID >= 0 and ID < 1000'), (5, 'project_table','select * from project_table where ID >= 1000 and ID < 2000');Passare al modello Copia bulk dal database. Creare una nuova connessione alla tabella di controllo esterna creata nel passaggio 1.

Creare una nuova connessione al database di origine da cui si stanno copiando i dati.
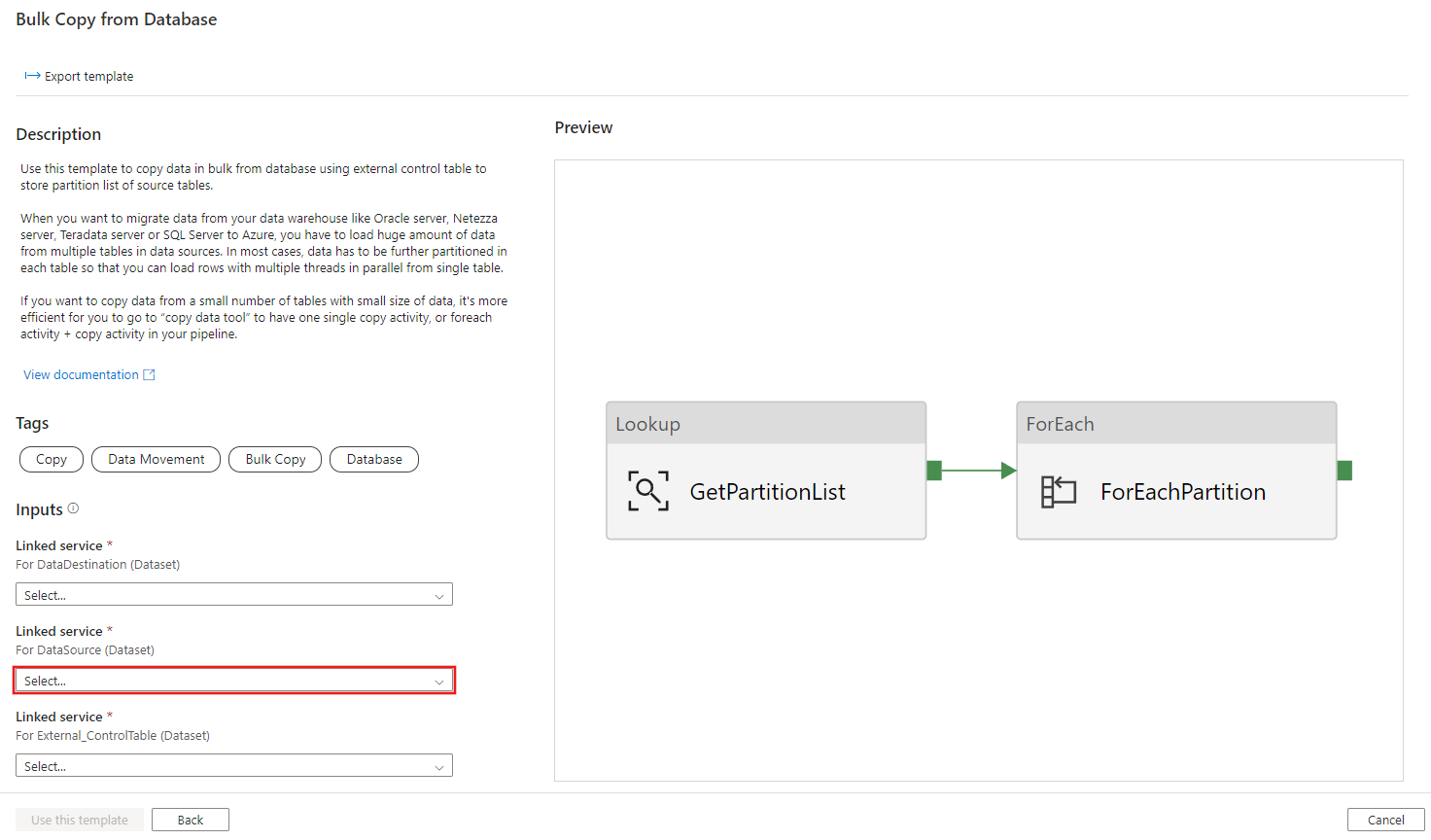
Creare una nuova connessione all'archivio dati di destinazione in cui si stanno copiando i dati.
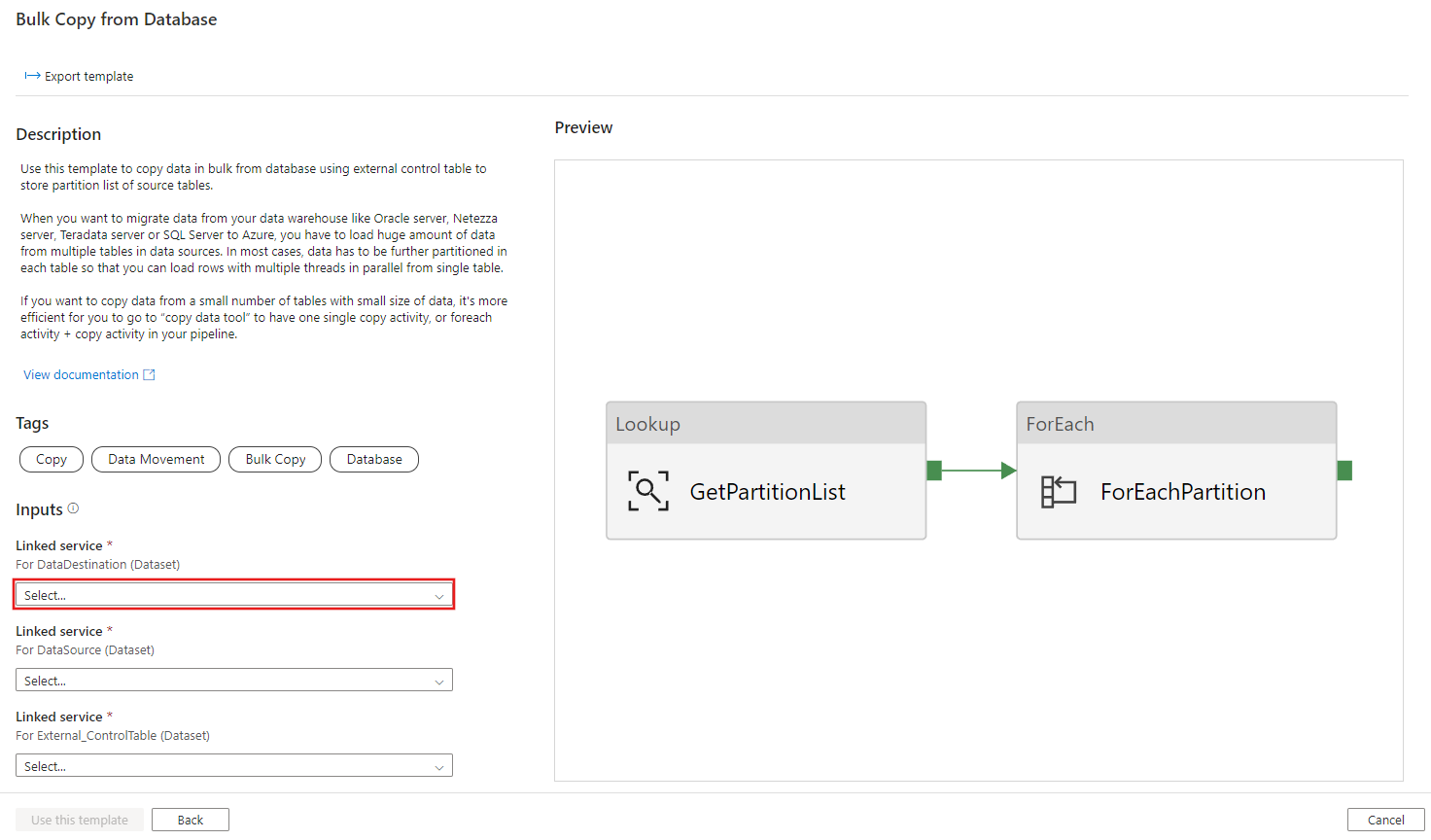
Selezionare Usa questo modello.
Verrà visualizzata la pipeline, come illustrato nell'esempio seguente:
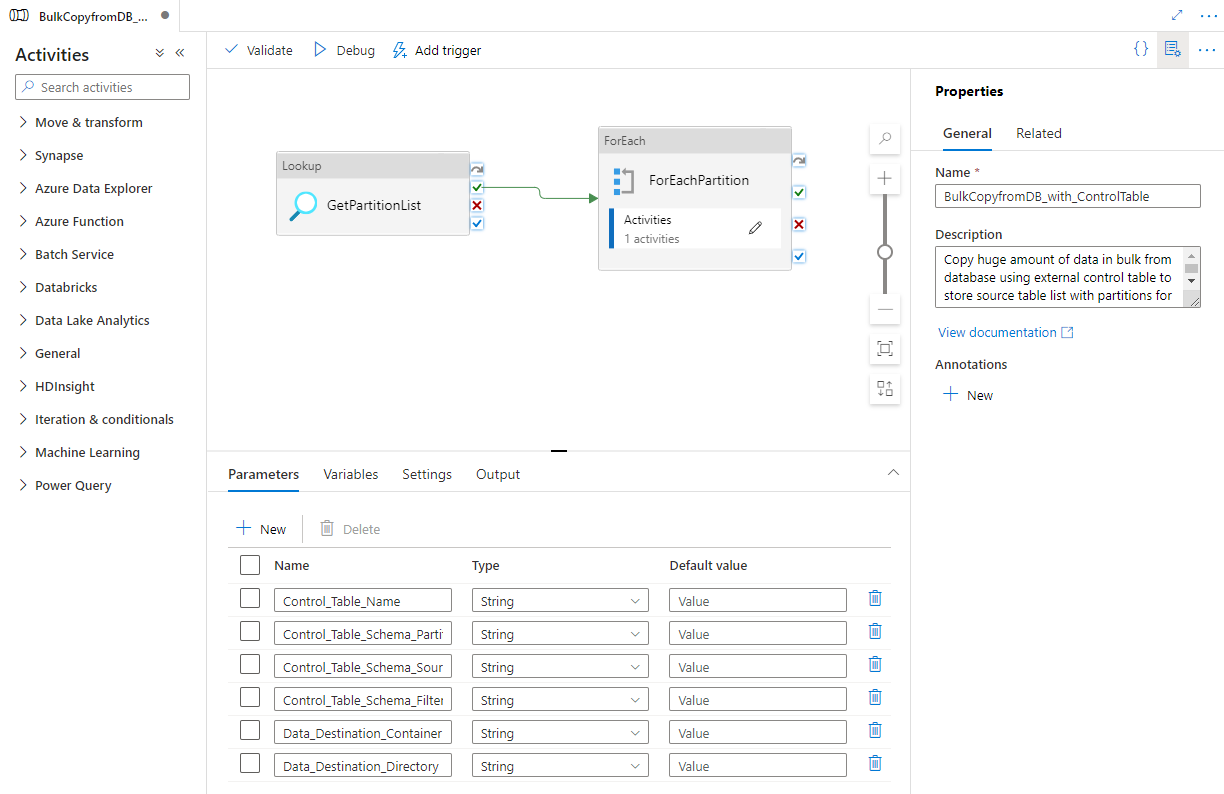
Selezionare Debug, immettere i valori in Parametri e quindi selezionare Fine.
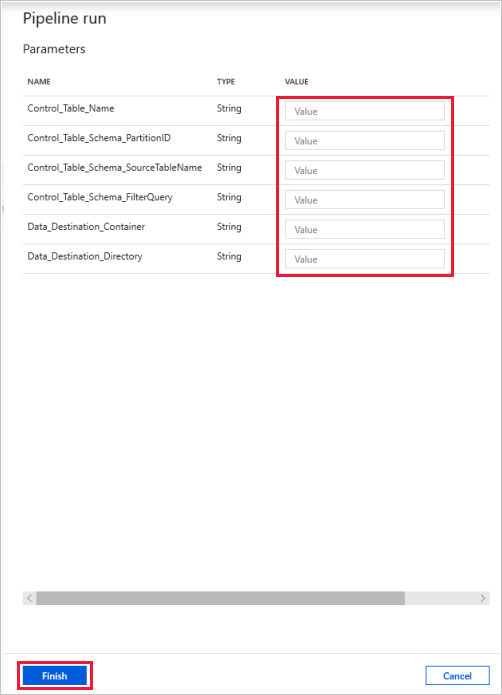
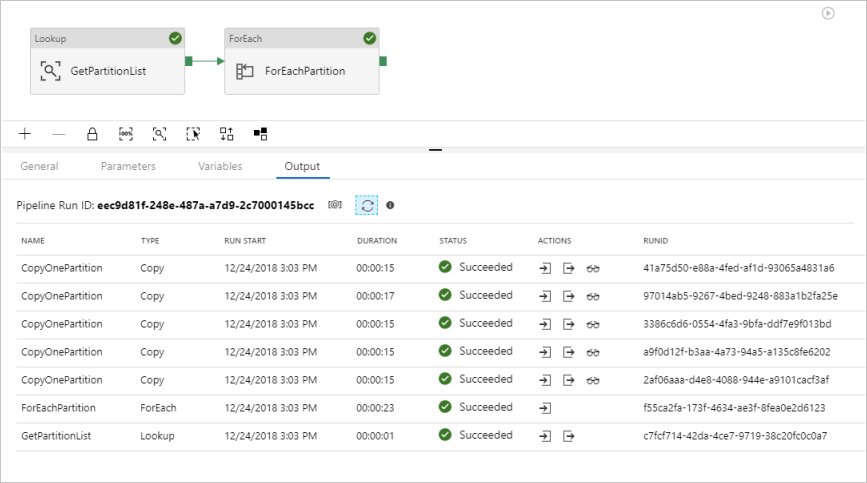
I risultati visualizzati sono simili all'esempio seguente:
(Facoltativo) Se si sceglie "Azure Synapse Analytics" come destinazione dati, è necessario immettere una connessione all'archivio BLOB di Azure per la gestione temporanea, come richiesto da Polybase di Azure Synapse Analytics. Il modello genererà automaticamente un percorso del contenitore per l'archiviazione BLOB. Controllare che il contenitore sia stato creato dopo l'esecuzione della pipeline.
