Trasformare i dati usando l'attività MapReduce di Hadoop in Azure Data Factory o Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
L'attività MapReduce di HDInsight in una pipeline di Azure Data Factory o Synapse Analytics richiama il programma MapReduce nel proprio cluster HDInsight o su richiesta. Questo articolo si basa sull'articolo relativo alle attività di trasformazione dei dati che presenta una panoramica generale della trasformazione dei dati e le attività di trasformazione supportate.
Per altre informazioni, leggere gli articoli introduttivi per Azure Data Factory e Synapse Analytics ed eseguire l'esercitazione Esercitazione: Trasformare i dati prima di leggere questo articolo.
Vedere Pig e Hive per informazioni dettagliate sull'esecuzione di script Pig/Hive in un cluster HDInsight da una pipeline tramite le attività HDInsight Pig e Hive.
Aggiungere un'attività MapReduce di HDInsight a una pipeline con l'interfaccia utente
Per usare un'attività MapReduce di HDInsight in una pipeline, completare la procedura seguente:
Cercare MapReduce nel riquadro Attività pipeline e trascinare un'attività MapReduce nell'area di disegno della pipeline.
Selezionare la nuova attività MapReduce nell'area di disegno, se non è già selezionata.
Selezionare la scheda Cluster HDI per selezionare o creare un nuovo servizio collegato in un cluster HDInsight che verrà usato per eseguire l'attività MapReduce.
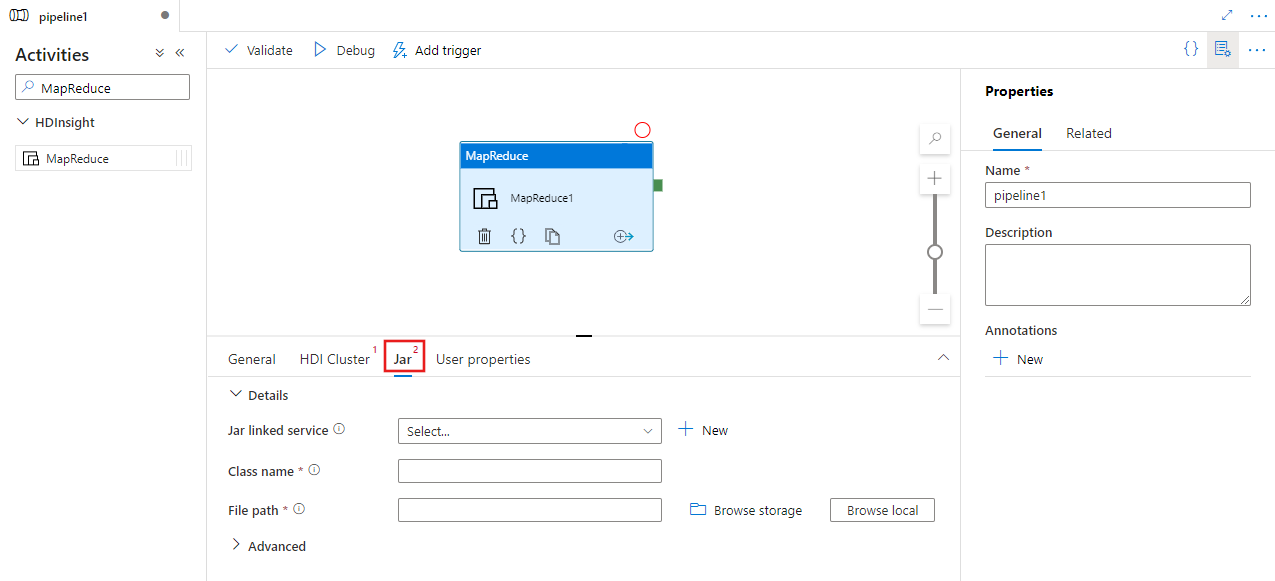
Selezionare la scheda Jar per selezionare o creare un nuovo servizio collegato Jar a un account Archiviazione di Azure che ospiterà lo script. Specificare un nome di classe da eseguire e un percorso di file all'interno del percorso di archiviazione. È anche possibile configurare dettagli avanzati, tra cui un percorso delle librerie Jar, la configurazione di debug e gli argomenti e i parametri da passare allo script.
Sintassi
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Dettagli sintassi
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| name | Nome dell'attività | Sì |
| description | Testo descrittivo per lo scopo dell'attività | No |
| Tipo | Per l'attività MapReduce, il tipo di attività è HDinsightMapReduce | Sì |
| linkedServiceName | Riferimento al cluster HDInsight registrato come servizio collegato. Per informazioni su questo servizio collegato, vedere l'articolo Servizi collegati di calcolo. | Sì |
| className | Nome della classe da eseguire | Sì |
| jarLinkedService | Riferimento a un servizio collegato di Archiviazione di Azure usato per archiviare i file Jar. Qui sono supportati solo i servizi collegati Archiviazione BLOB di Azure e ADLS Gen2. Se non si specifica questo servizio collegato, viene usato il servizio collegato Archiviazione di Azure definito nel servizio collegato HDInsight. | No |
| jarFilePath | Specificare il percorso dei file Jar archiviati nel servizio Archiviazione di Azure indicato da jarLinkedService. Il nome del file distingue tra maiuscole e minuscole. | Sì |
| jarlibs | Percorso dei file di libreria Jar indicati dal processo archiviato nel servizio Archiviazione di Azure indicato da jarLinkedService. Il nome del file distingue tra maiuscole e minuscole. | No |
| getDebugInfo | Specifica quando i file di log vengono copiati nel servizio Archiviazione di Azure usato dal cluster HDInsight o specificato da jarLinkedService. Valori consentiti: None, Always o Failure. Valore predefinito: None. | No |
| arguments | Specifica una matrice di argomenti per un processo Hadoop. Gli argomenti vengono passati a ogni attività come argomenti della riga di comando. | No |
| defines | Specificare i parametri come coppie chiave/valore per fare riferimento a essi nello script Hive. | No |
Esempio
È possibile usare l’attività MapReduce di HDInsight per l'esecuzione di file JAR di MapReduce in un cluster HDInsight. Nella definizione JSON seguente di una pipeline di esempio l'attività HDInsight è configurata per eseguire un file JAR di Mahout.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
È possibile specificare eventuali argomenti per il programma MapReduce nella sezione arguments. In fase di esecuzione, vengono visualizzati alcuni argomenti aggiuntivi (ad esempio: mapreduce.job.tags) dal framework di MapReduce. Per differenziare gli argomenti con gli argomenti di MapReduce, è consigliabile usare sia l'opzione che il valore come argomenti, come illustrato nell'esempio seguente (-s,--input,--output e così via sono opzioni immediatamente seguite dai valori).
Contenuto correlato
Vedere gli articoli seguenti, che illustrano altre modalità di trasformazione dei dati: