Copiare dati da un database di SQL Server all'archiviazione BLOB di Azure
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
In questa esercitazione si usa l'interfaccia utente di Azure Data Factory per creare una pipeline di data factory che copia i dati da un database di SQL Server all'archiviazione BLOB di Azure. Si crea e si usa un runtime di integrazione self-hosted, che sposta i dati tra gli archivi dati locali e cloud.
Nota
Questo articolo non offre una presentazione dettagliata di Data Factory. Per altre informazioni, vedere Introduzione ad Azure Data Factory.
In questa esercitazione si segue questa procedura:
- Creare una data factory.
- Creare un runtime di integrazione self-hosted.
- Creare servizi collegati per SQL Server e Archiviazione di Azure.
- Creare set di dati per SQL Server e BLOB di Azure.
- Creare una pipeline con attività di copia per trasferire i dati.
- Avviare un'esecuzione della pipeline.
- Monitorare l'esecuzione della pipeline.
Prerequisiti
La sottoscrizione di Azure
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Ruoli di Azure
Per creare istanze di Data Factory, all'account utente usato per accedere ad Azure deve essere assegnato un ruolo collaboratore o proprietario oppure l'account utente deve essere un amministratore della sottoscrizione di Azure.
Per visualizzare le autorizzazioni disponibili nella sottoscrizione, passare al portale di Azure. Nell'angolo superiore destro selezionare il nome utente e quindi Autorizzazioni. Se si accede a più sottoscrizioni, selezionare quella appropriata. Per istruzioni di esempio su come aggiungere un utente a un ruolo, vedere Assegnare ruoli di Azure usando il portale di Azure.
SQL Server 2014, 2016 e 2017
In questa esercitazione si usa un database di SQL Server come archivio dati di origine. La pipeline nella data factory creata in questa esercitazione copia i dati da questo database di SQL Server (origine) all'archiviazione BLOB (sink). Si crea quindi una tabella denominata emp nel database di SQL Server e si inseriscono alcune voci di esempio nella tabella.
Avvia SQL Server Management Studio. Se non è già installato nel computer, passare a Scaricare SQL Server Management Studio.
Connettersi all'istanza di SQL Server usando le credenziali.
Creare un database di esempio. Nella visualizzazione struttura ad albero fare clic con il pulsante destro del mouse su Database e scegliere Nuovo database.
Nella finestra Nuovo database immettere un nome per il database e fare clic su OK.
Per creare la tabella emp e inserirvi alcuni dati di esempio, eseguire questo script di query sul database. Nella visualizzazione struttura ad albero fare clic con il pulsante destro del mouse sul database creato e scegliere Nuova query.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Account di archiviazione di Azure
In questa esercitazione, come archivio dati di destinazione/sink si usa un account di archiviazione di Azure per utilizzo generico (specificamente, un archivio BLOB). Se non si ha un account di archiviazione di Azure per utilizzo generico, vedere Creare un account di archiviazione. La pipeline nella data factory creata in questa esercitazione copia i dati dal database di SQL Server (origine) all'archiviazione BLOB (sink).
Recuperare il nome e la chiave dell'account di archiviazione
In questa esercitazione si usano il nome e la chiave dell'account di archiviazione. Per recuperare il nome e la chiave dell'account di archiviazione, seguire questa procedura:
Accedere al portale di Azure con nome utente e password di Azure.
Nel riquadro sinistro selezionare Tutti i servizi. Usare la parola chiave Archiviazione come filtro e quindi selezionare Account di archiviazione.
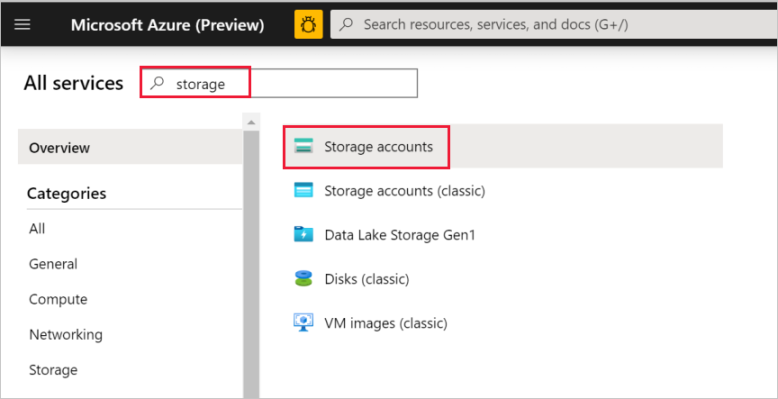
Nell'elenco degli account di archiviazione filtrare, se necessario, il proprio account di archiviazione. Selezionare quindi l'account di archiviazione.
Nella finestra Account di archiviazione selezionare Chiavi di accesso.
Nelle caselle Nome account di archiviazione e key1 copiare i valori e incollarli nel Blocco note o in un altro editor per usarli in seguito nell'esercitazione.
Creare il contenitore adftutorial
In questa sezione si crea un contenitore BLOB denominato adftutorial nell'archivio BLOB.
Nella finestra Account di archiviazione passare a Panoramica e quindi selezionare Contenitori.
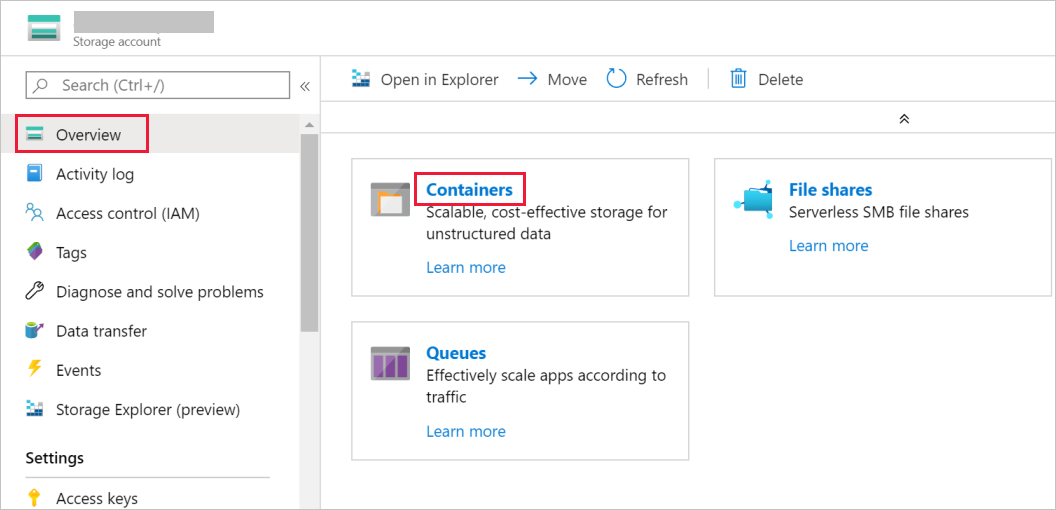
Nella finestra Contenitori selezionare + Contenitore per creare un nuovo contenitore.
Nella finestra Nuovo contenitore immettere adftutorial in Nome. Selezionare Crea.
Selezionare il contenitore adftutorial appena creato nell'elenco di contenitori.
Tenere aperta la finestra Contenitore per adftutorial Verrà usata per verificare l'output alla fine di questa esercitazione. Data Factory crea automaticamente la cartella di output in questo contenitore, quindi non è necessario crearne uno.
Creare una data factory
In questo passaggio si crea una data factory e si avvia l'interfaccia utente di Data Factory per creare una pipeline nella data factory.
Aprire il Web browser Microsoft Edge o Google Chrome. L'interfaccia utente di Data Factory è attualmente supportata solo nei Web browser Microsoft Edge e Google Chrome.
Nel menu sinistro selezionare Crea una risorsa>Integrazione>Data factory:
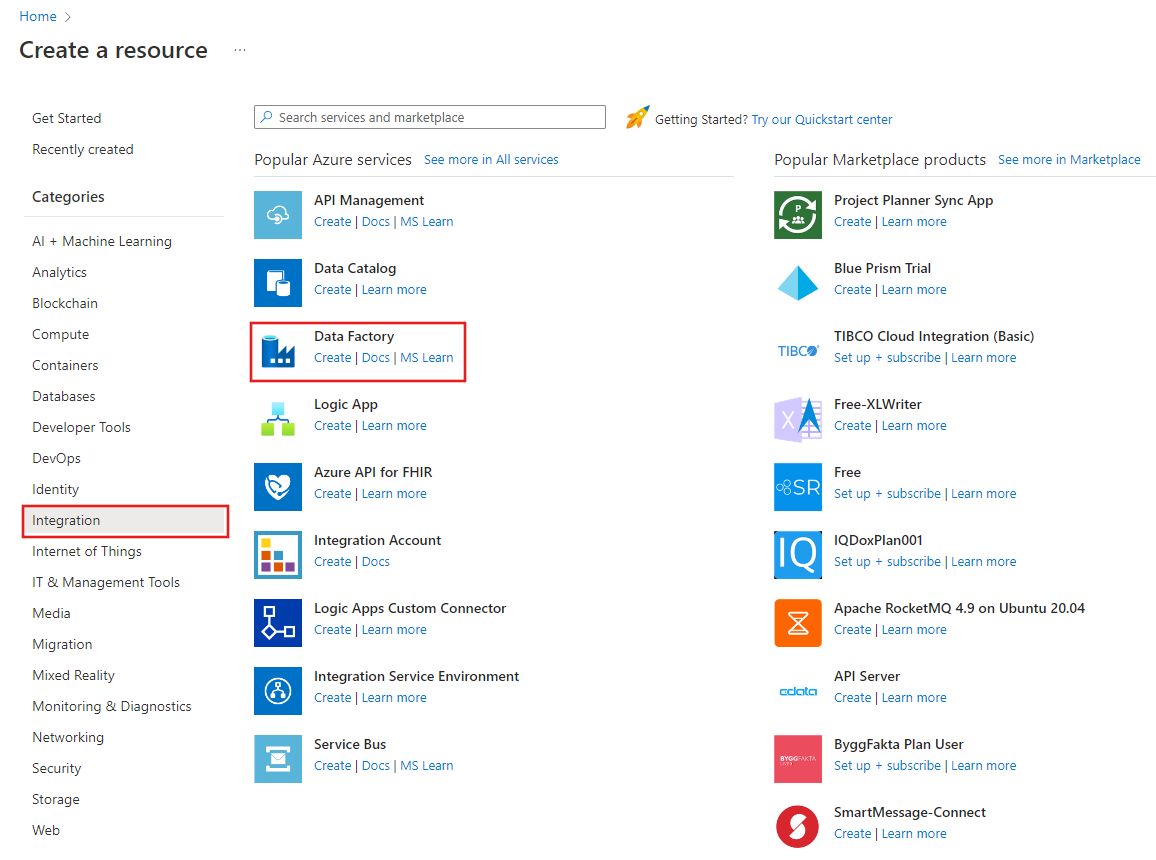
Nella pagina Nuova data factory immettere ADFTutorialDataFactory in Nome.
Il nome della data factory deve essere univoco a livello globale. Se viene visualizzato il messaggio di errore seguente per il campo Nome, modificare il nome della data factory, ad esempio usando nomeutenteADFTutorialDataFactory. Per informazioni sulle regole di denominazione per gli elementi di Data factory, vedere Azure Data factory - Regole di denominazione.
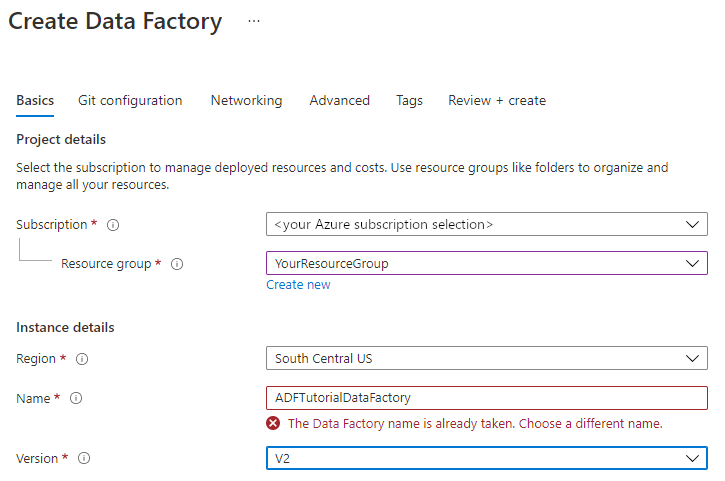
Selezionare la sottoscrizione di Azure in cui creare la data factory.
In Gruppo di risorse eseguire una di queste operazioni:
Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
Selezionare Crea nuovoe immettere un nome per il gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere l'articolo su come usare gruppi di risorse per gestire le risorse di Azure.
In Versione selezionare V2.
In Località selezionare la località per la data factory. Nell'elenco a discesa vengono mostrate solo le località supportate. Gli archivi dati (ad esempio, Archiviazione e il database SQL) e le risorse di calcolo (ad esempio, Azure HDInsight) usati da Data Factory possono trovarsi in altre aree.
Seleziona Crea.
Al termine della creazione verrà visualizzata la pagina Data factory, come illustrato nell'immagine:
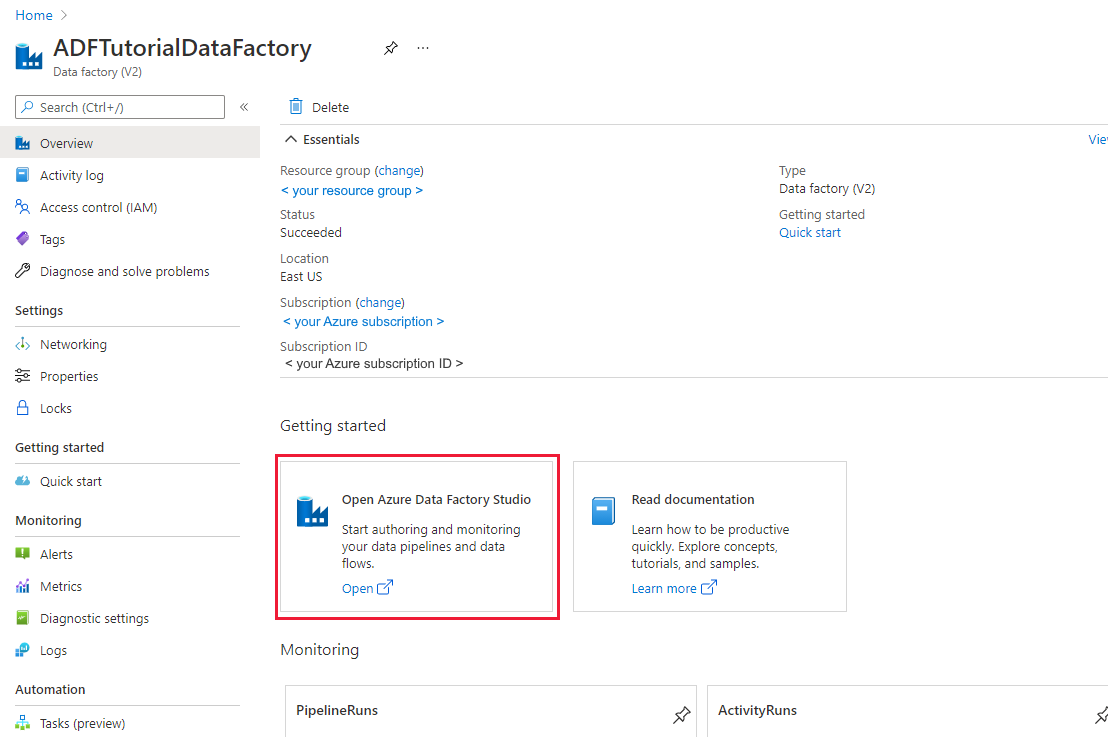
Selezionare Apri nel riquadro Apri Azure Data Factory Studio per avviare l'interfaccia utente di Data Factory in una scheda separata.
Creare una pipeline
Nella home page di Azure Data Factory selezionare Orchestrate .On the Azure Data Factory home page, select Orchestrate. Verrà creata automaticamente una pipeline. La pipeline sarà visibile nella visualizzazione albero e verrà aperto il relativo editor.
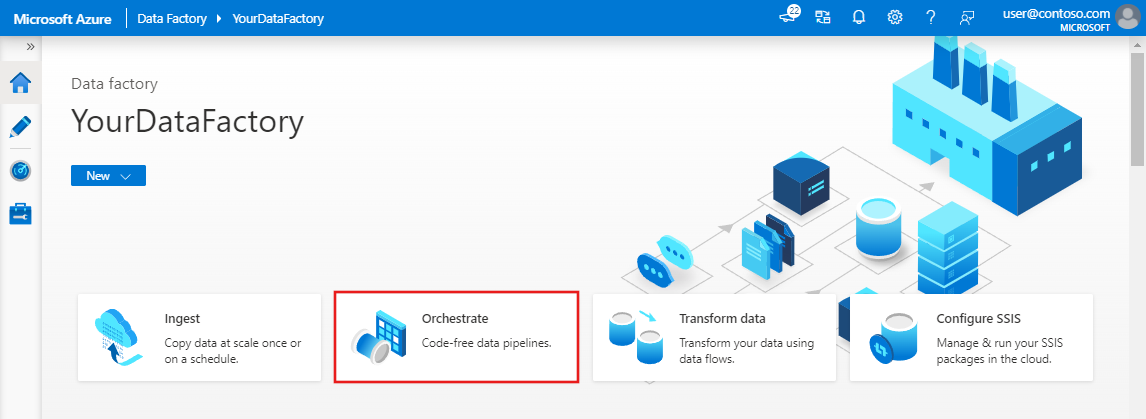
Nel pannello Generale, in Proprietà, specificare SQLServerToBlobPipeline per Nome. Comprimere quindi il pannello facendo clic sull'icona Proprietà nell'angolo in alto a destra.
Nella casella degli strumenti Attività espandere Move & Transform (Sposta e trasforma). Trascinare l'attività Copia nell'area di progettazione della pipeline. Impostare il nome dell'attività su CopySqlServerToAzureBlobActivity.
Nella finestra Proprietà passare alla scheda Origine e selezionare + Nuovo.
Nella finestra di dialogo Nuovo set di dati cercare SQL Server. Selezionare SQL Server e quindi Continua.
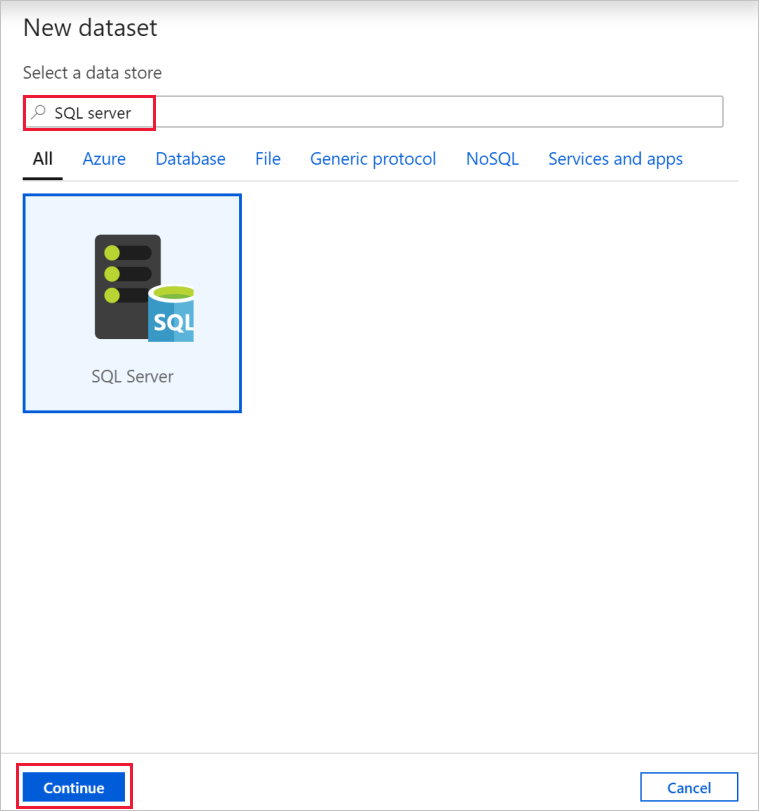
Nella finestra di dialogo Imposta proprietà, in Nome, immettere SqlServerDataset. In Servizio collegato selezionare + Nuovo. In questo passaggio si crea una connessione all'archivio dati di origine (database SQL Server).
Nella finestra di dialogo New Linked Service (Nuovo servizio collegato) aggiungere Nome come SqlServerLinkedService. In Connect via integration runtime (Connetti tramite runtime di integrazione) selezionare + Nuovo. In questa sezione si crea un runtime di integrazione self-hosted e lo si associa a un computer locale con il database di SQL Server. Il runtime di integrazione self-hosted è il componente che copia i dati dal database di SQL Server presente nel computer all'archivio BLOB.
Nella finestra Installazione di Integration Runtime selezionare Self-Hosted e quindi Continua.
In Nome immettere TutorialIntegrationRuntime. Selezionare Crea.
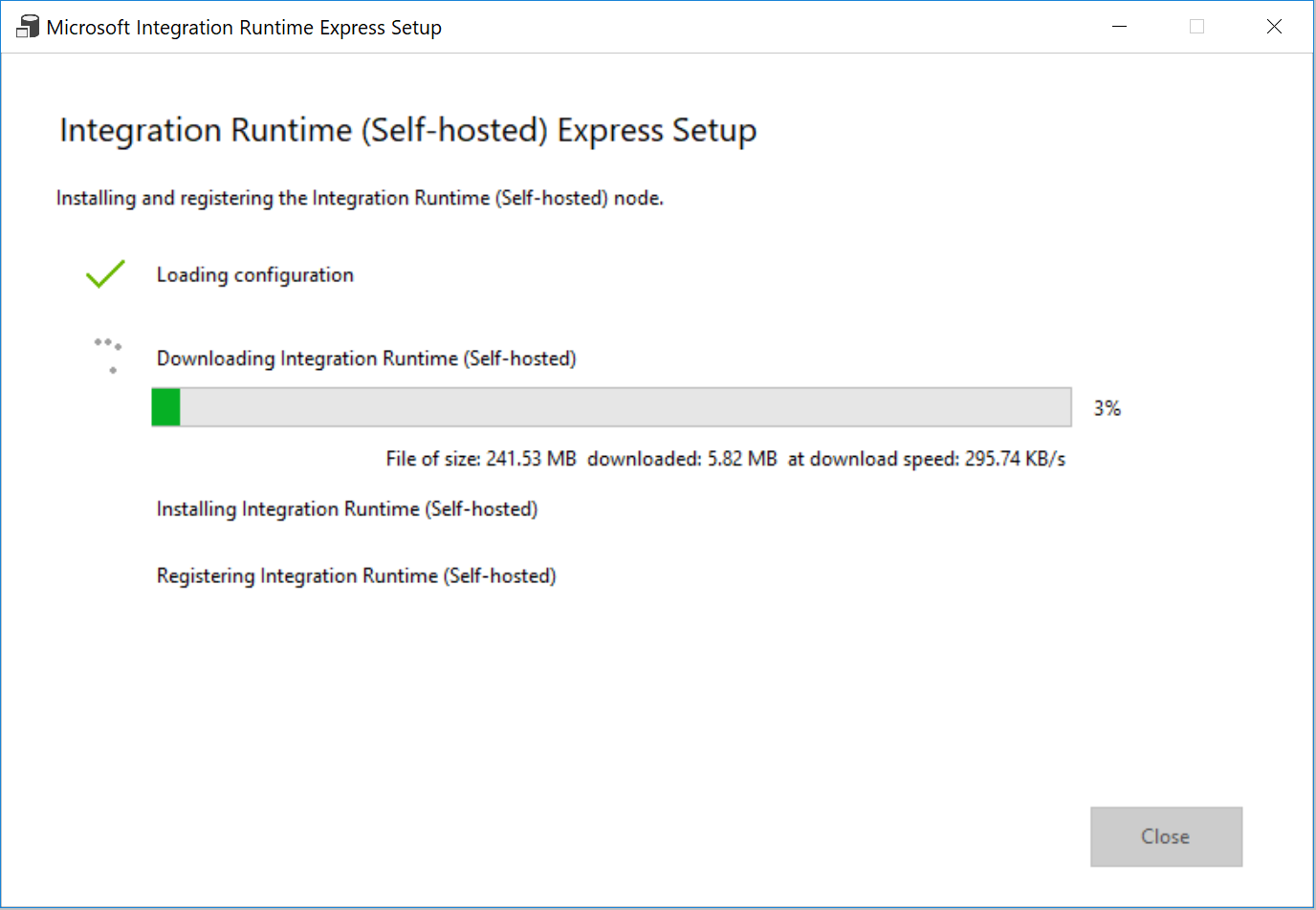
In Impostazioni selezionare Fare clic qui per avviare l'installazione rapida per questo computer. Questa azione installa il runtime di integrazione nel computer e lo registra in Data Factory. In alternativa è possibile usare l'opzione di installazione manuale per scaricare il file di installazione, eseguirlo e usare la chiave per registrare il runtime di integrazione.
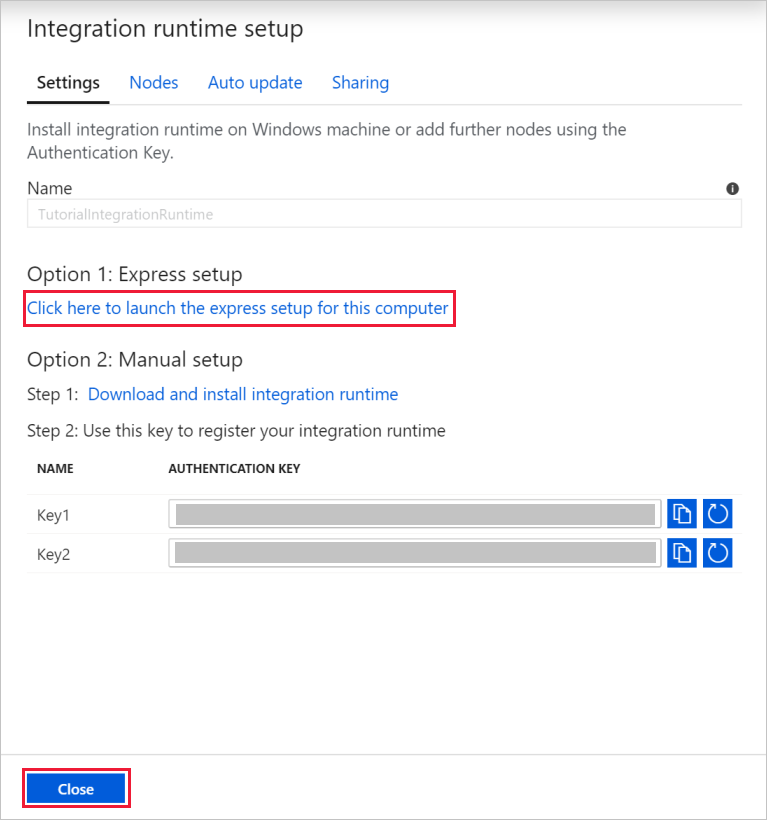
Nella finestra Installazione rapida di Integration Runtime (self-hosted) selezionare Chiudi al termine del processo.
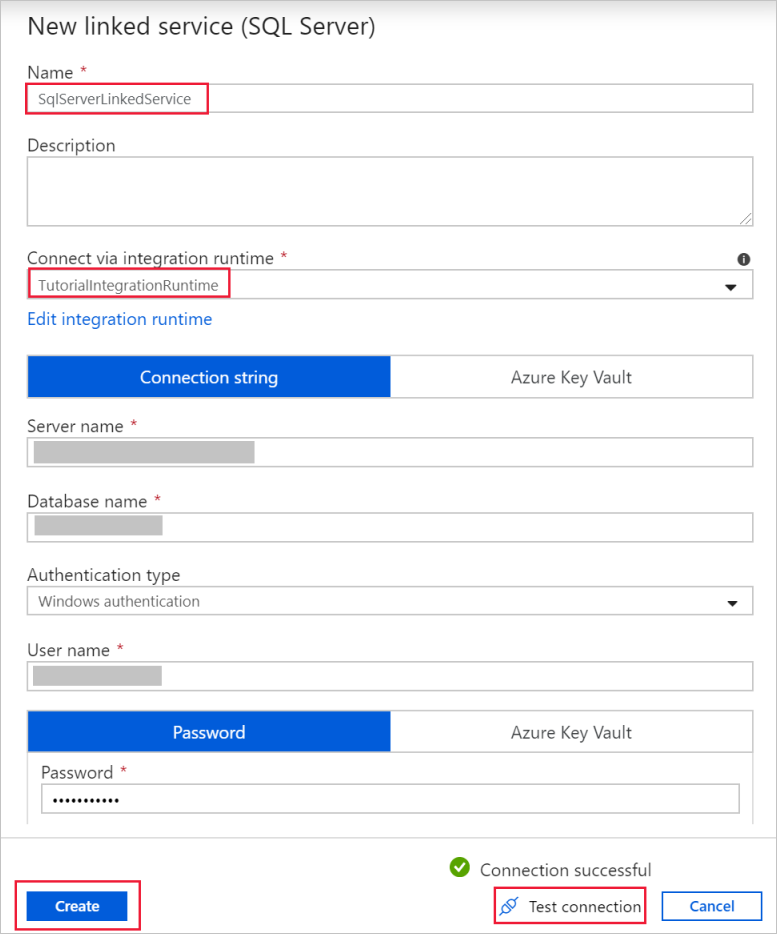
Nella finestra di dialogo Nuovo servizio collegato (SQL Server) verificare che nel campo Connetti tramite il runtime di integrazione sia selezionato TutorialIntegrationRuntime. Seguire quindi questa procedura:
a. In Nome immettere SqlServerLinkedService.
b. In Nome server immettere il nome dell'istanza di SQL Server.
c. In Nome database immettere il nome del database con la tabella emp.
d. In Tipo di autenticazione selezionare il tipo di autenticazione appropriato che dovrà essere usato da Data Factory per la connessione al database di SQL Server.
e. In Nome utente e Password immettere il nome utente e la password. Usare mydomain\myuser come nome utente, se necessario.
f. Selezionare Test connessione. Eseguire questo passaggio per verificare che Data Factory possa connettersi al database SQL Server usando il runtime di integrazione self-hosted creato.
g. Selezionare Crea per salvare il servizio collegato.
Al termine della creazione del servizio collegato verrà visualizzata di nuovo la pagina Imposta proprietà per il set di dati di SQL Server. Seguire questa procedura:
a. In Servizio collegato verificare che venga visualizzato SqlServerLinkedService.
b. In Nome tabella selezionare [dbo].[emp].
c. Seleziona OK.
Passare alla scheda con SQLServerToBlobPipeline oppure selezionare SQLServerToBlobPipeline nella visualizzazione albero.
Passare alla scheda Sink nella parte inferiore della finestra Proprietà e selezionare + Nuovo.
Nella finestra di dialogo Nuovo set di dati selezionare Archiviazione BLOB di Azure. Selezionare Continua.
Nella finestra di dialogo Select Format (Seleziona formato) scegliere il tipo di formato dei dati. Selezionare Continua.

Nella finestra di dialogo Imposta proprietà immettere AzureBlobDataset come nome. Selezionare + Nuovo accanto alla casella di testo Servizio collegato.
Nella finestra New Linked Service (Azure Blob Storage) (Nuovo servizio collegato - Archiviazione BLOB di Azure) immettere AzureStorageLinkedService come nome e selezionare l'account di archiviazione nell'elenco Nome account di archiviazione. Testare la connessione e quindi selezionare Crea per distribuire il servizio collegato.
Al termine della creazione del servizio collegato verrà visualizzata di nuovo la pagina Imposta proprietà. Seleziona OK.
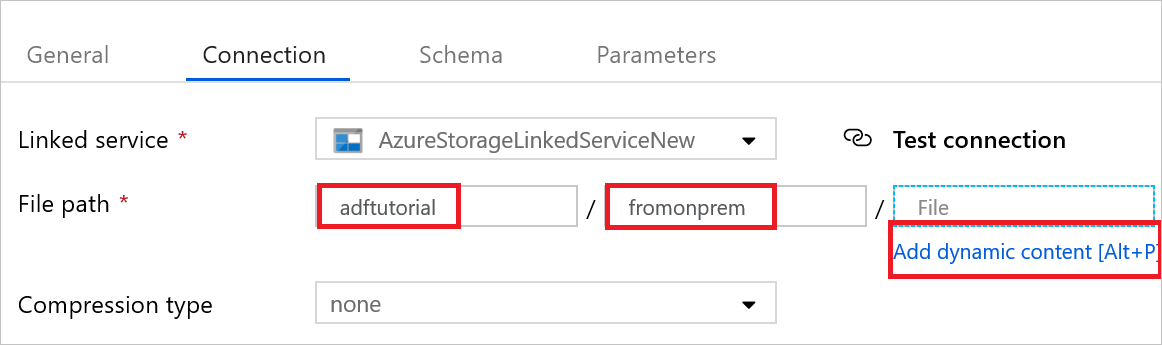
Aprire il set di dati sink. Nella scheda Connessione seguire questa procedura:
a. In Servizio collegato verificare che sia selezionato AzureStorageLinkedService.
b. Nella parte Contenitore/directory di Percorso file immettere adftutorial/fromonprem. Se la cartella di output non esiste nel contenitore adftutorial, verrà creata automaticamente da Data Factory.
c. Nella parte File selezionare Aggiungi contenuto dinamico.
d. Aggiungere
@CONCAT(pipeline().RunId, '.txt'), quindi selezionare Fine. Questa azione rinomina il file in PipelineRunID.txt.Passare alla scheda con la pipeline aperta oppure selezionare la pipeline nella visualizzazione albero. In Sink Dataset (Set di dati sink) verificare che sia selezionato AzureBlobDataset.
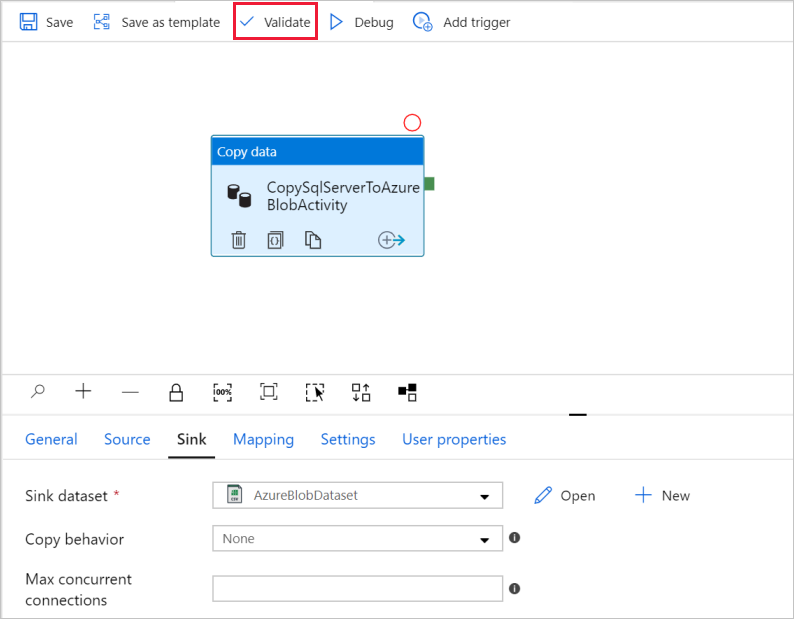
Per convalidare le impostazioni della pipeline, selezionare Convalida sulla barra degli strumenti della pipeline. Per chiudere l'output della convalida della pipe, selezionare l'icona >>.
Per pubblicare le entità create in Data Factory, selezionare Pubblica tutti.
Attendere fino alla visualizzazione del messaggio popup La pubblicazione è stata completata. Per verificare lo stato della pubblicazione, selezionare il collegamento Mostra notifiche nella parte superiore della finestra. Per chiudere la finestra delle notifiche, selezionare Chiudi.
Attivare un'esecuzione della pipeline
Selezionare Add Trigger (Aggiungi trigger) sulla barra degli strumenti della pipeline e quindi Trigger Now (Attiva adesso).
Monitorare l'esecuzione della pipeline
Passare alla scheda Monitoraggio . Nel passaggio precedente viene visualizzata la pipeline attivata manualmente.
Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, selezionare il collegamento SQLServerToBlobPipeline in NOME DELLA PIPELINE.

Per visualizzare informazioni dettagliate sull'operazione di copia, selezionare il collegamento Dettagli (icona a forma di occhiali) nella pagina Esecuzioni attività. Per tornare alla visualizzazione Esecuzioni della pipeline, selezionare Esecuzioni della pipeline in alto.
Verificare l'output
La pipeline crea automaticamente la cartella di output denominata fromonprem nel contenitore BLOB adftutorial. Assicurarsi che nella cartella di output sia presente il file [pipeline().RunId].txt.
Contenuto correlato
La pipeline di questo esempio copia i dati da una posizione a un'altra in un archivio BLOB. Contenuto del modulo:
- Creare una data factory.
- Creare un runtime di integrazione self-hosted.
- Creare servizi collegati per SQL Server e Archiviazione.
- Creare i set di dati per SQL Server e l'archivio BLOB.
- Creare una pipeline con attività di copia per trasferire i dati.
- Avviare un'esecuzione della pipeline.
- Monitorare l'esecuzione della pipeline.
Per un elenco degli archivi dati supportati da Data Factory, vedere la tabella degli archivi dati supportati.
Per informazioni sulla copia di dati in blocco da un'origine a una destinazione, passare all'esercitazione successiva: