Copiare in modo incrementale nuovi file in base al nome file partizionato in base al tempo usando lo strumento Copia dati
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
In questa esercitazione si usa il portale di Azure per creare una data factory. Usare quindi lo strumento Copia dati per creare una pipeline che copia in modo incrementale nuovi file in base al nome di file partizionato in tempo dall'archivio BLOB di Azure all'archivio BLOB di Azure.
Nota
Se non si ha familiarità con Azure Data Factory, vedere Introduzione ad Azure Data Factory.
In questa esercitazione si segue questa procedura:
- Creare una data factory.
- Usare lo strumento Copia dati per creare una pipeline.
- Monitorare le esecuzioni di pipeline e attività.
Prerequisiti
- Sottoscrizione di Azure: se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Account di archiviazione di Azure: usare l'archiviazione BLOB come archivio dati di origine e sink . Se non è disponibile un account di archiviazione di Azure, vedere le istruzioni fornite in Creare un account di archiviazione.
Creare due contenitori nell'archivio BLOB
Preparare l'archiviazione BLOB per l'esercitazione eseguendo questi passaggi.
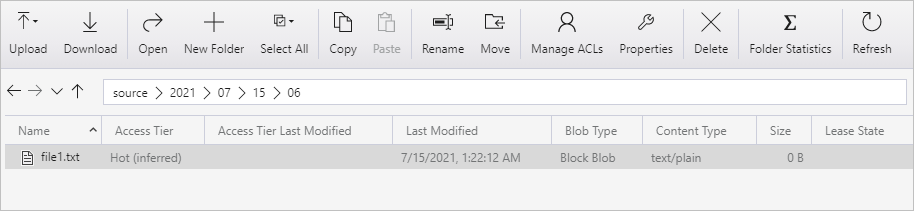
Creare un contenitore denominato source. Creare un percorso di cartella come 15/07/2021/2021 nel contenitore. Creare un file di testo vuoto e denominarlo come file1.txt. Caricare il file1.txt nell'origine percorso cartella/2021/07/15/06 nell'account di archiviazione. Per eseguire queste attività è possibile usare vari strumenti, ad esempio Azure Storage Explorer.
Nota
Modificare il nome della cartella con l'ora UTC. Ad esempio, se l'ora UTC corrente è 06:10 il 15 luglio 2021, è possibile creare il percorso della cartella come origine/2021/07/15/06/ dalla regola di origine/{Anno}/{Mese}/{Giorno}/{Ora}/.
Creare un contenitore denominato destination. Per eseguire queste attività è possibile usare vari strumenti, ad esempio Azure Storage Explorer.
Creare una data factory
Nel menu sinistro selezionare Crea una risorsa>Integrazione>Data factory:
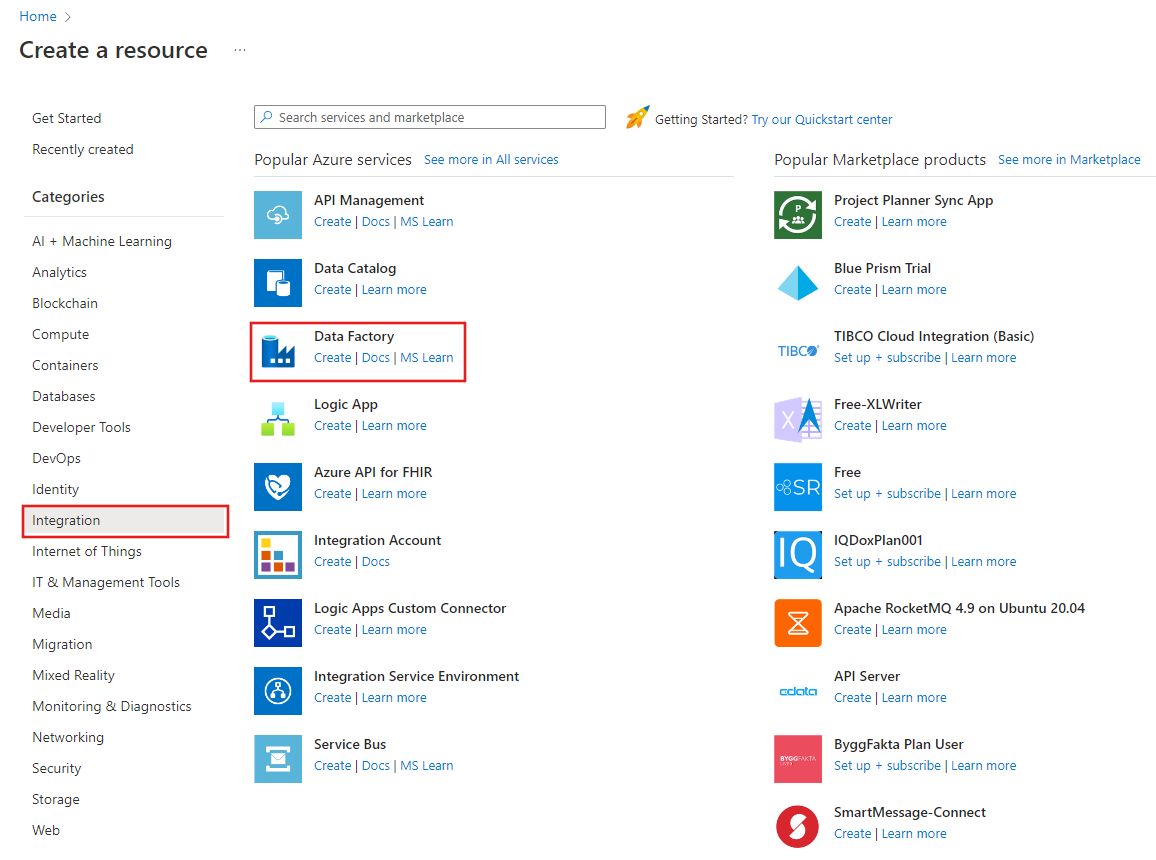
Nella pagina Nuova data factory immettere ADFTutorialDataFactory in Nome.
Il nome della data factory deve essere univoco a livello globale. Potrebbe essere visualizzato il messaggio di errore seguente:
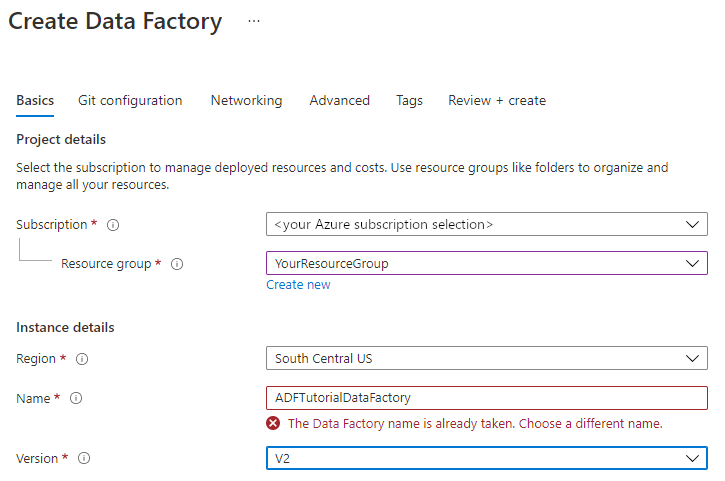
Se viene visualizzato un messaggio di errore relativo al valore del nome, immettere un nome diverso per la data factory. Ad esempio, usare il nome nomeutenteADFTutorialDataFactory. Per informazioni sulle regole di denominazione per gli elementi di Data Factory, vedere Azure Data Factory - Regole di denominazione.
Selezionare la sottoscrizione di Azure in cui creare la nuova data factory.
In Gruppo di risorse eseguire una di queste operazioni:
a. Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
b. Selezionare Crea nuovoe immettere un nome per il gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere l'articolo su come usare gruppi di risorse per gestire le risorse di Azure.
In Versione selezionare la versione V2.
In Località selezionare la località per la data factory. Nell'elenco a discesa vengono visualizzate solo le località supportate. Gli archivi dati (ad esempio, Archiviazione di Azure e il database SQL) e le risorse di calcolo (ad esempio, Azure HDInsight) usati dalla data factory possono trovarsi in altre località e aree.
Seleziona Crea.
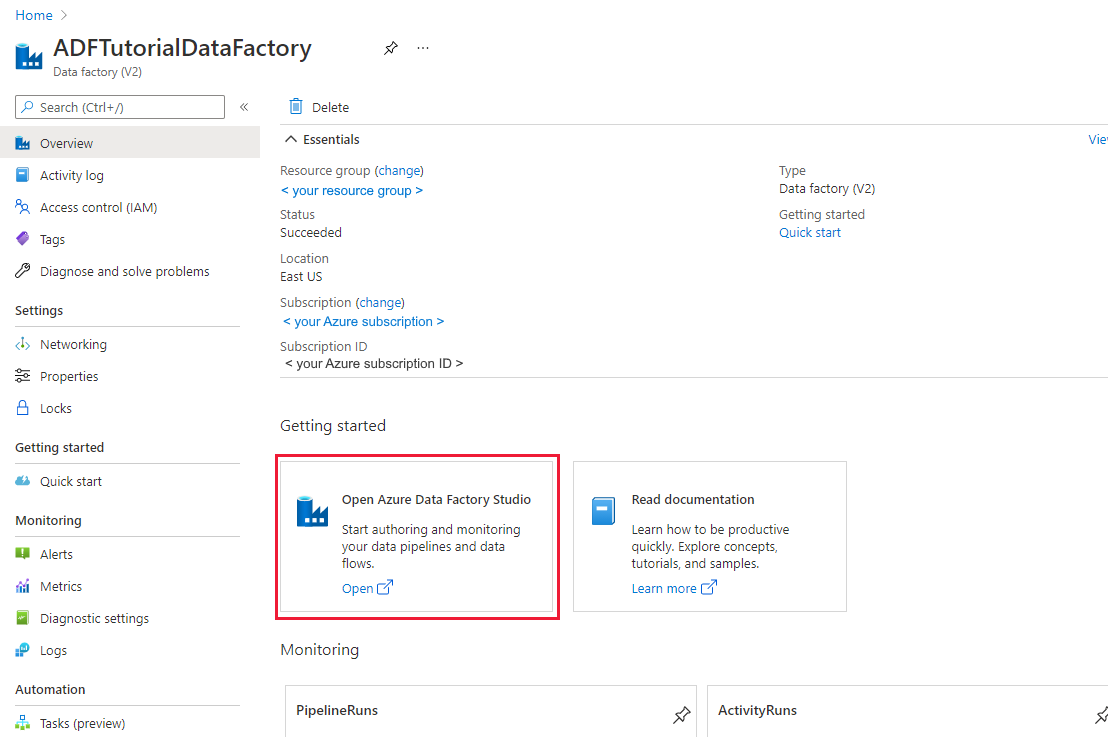
Al termine della creazione verrà visualizzata la home page Data factory.
Per avviare l'interfaccia utente di Azure Data Factory in una scheda separata, selezionare Apri nel riquadro Apri Azure Data Factory Studio.
Usare lo strumento Copia dati per creare una pipeline
Nella home page di Azure Data Factory selezionare il titolo Inserimento per avviare lo strumento Copia dati.
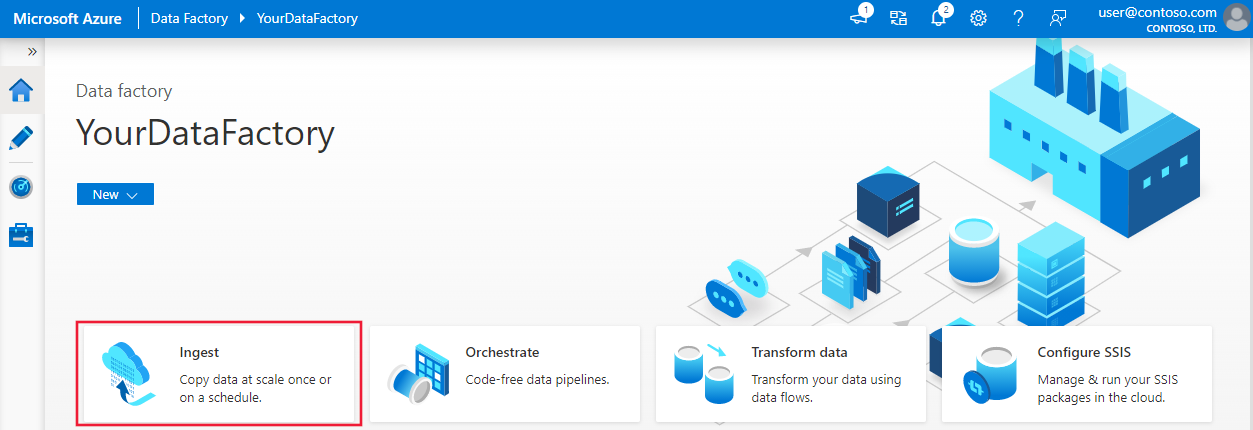
Nella pagina Proprietà seguire questa procedura:
In Tipo di attività scegliere Attività di copia predefinita.
In Frequenza attività o pianificazione attività selezionare la finestra a cascata.
In Ricorrenza immettere 1 ora.
Seleziona Avanti.
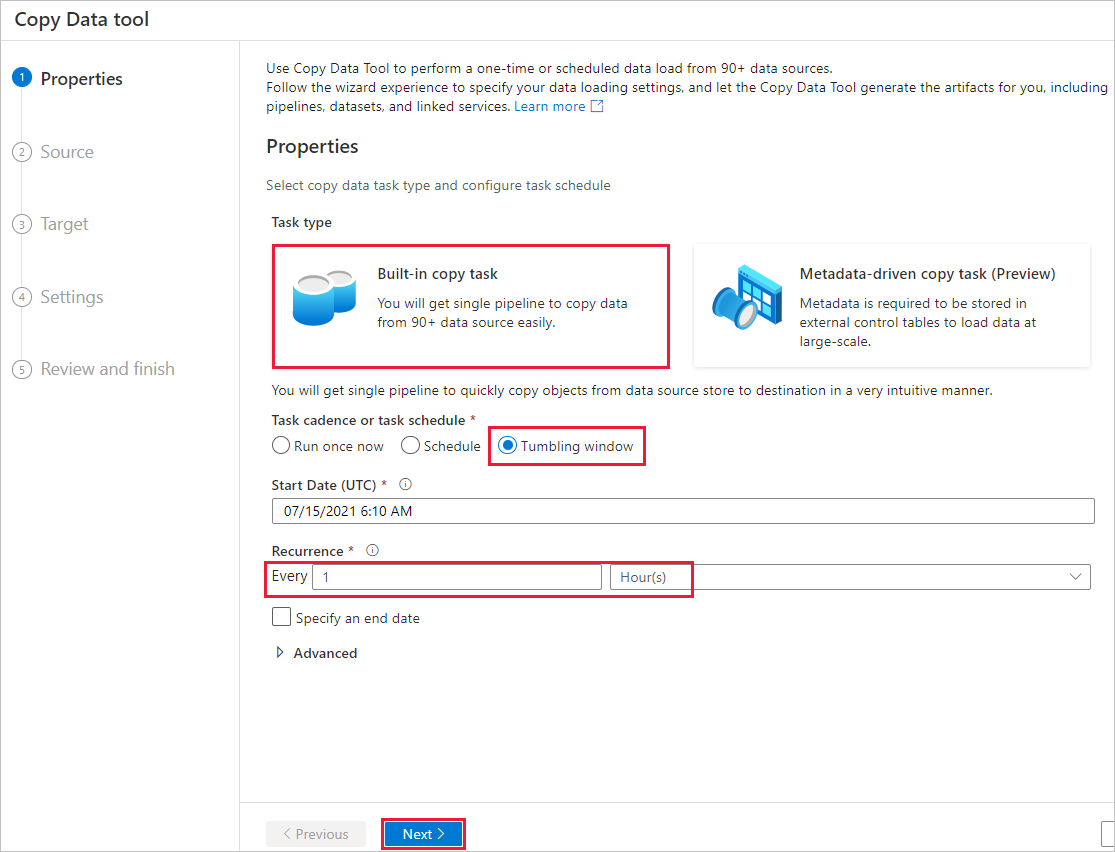
Nella pagina Archivio dati di origine completare la procedura seguente:
a. Selezionare + Nuova connessione per aggiungere una connessione.
b. Selezionare Archiviazione BLOB di Azure nella raccolta e quindi Continua.
c. Nella pagina Nuova connessione (Archiviazione BLOB di Azure) immettere un nome per la connessione. Selezionare la sottoscrizione di Azure e selezionare l'account di archiviazione dall'elenco Archiviazione nome dell'account. Testare la connessione e quindi selezionare Crea.

d. Nella pagina Archivio dati di origine selezionare la connessione appena creata nella sezione Connessione ion.
e. Nella sezione File o cartella individuare e selezionare il contenitore di origine, quindi selezionare OK.
f. In Comportamento di caricamento file selezionare Caricamento incrementale : nomi di file/cartelle partizionate in tempo.
g. Scrivere il percorso della cartella dinamica come source/{year}/{month}/{day}/{hour}/e modificare il formato come illustrato nello screenshot seguente.
h. Selezionare Copia binaria e selezionare Avanti.
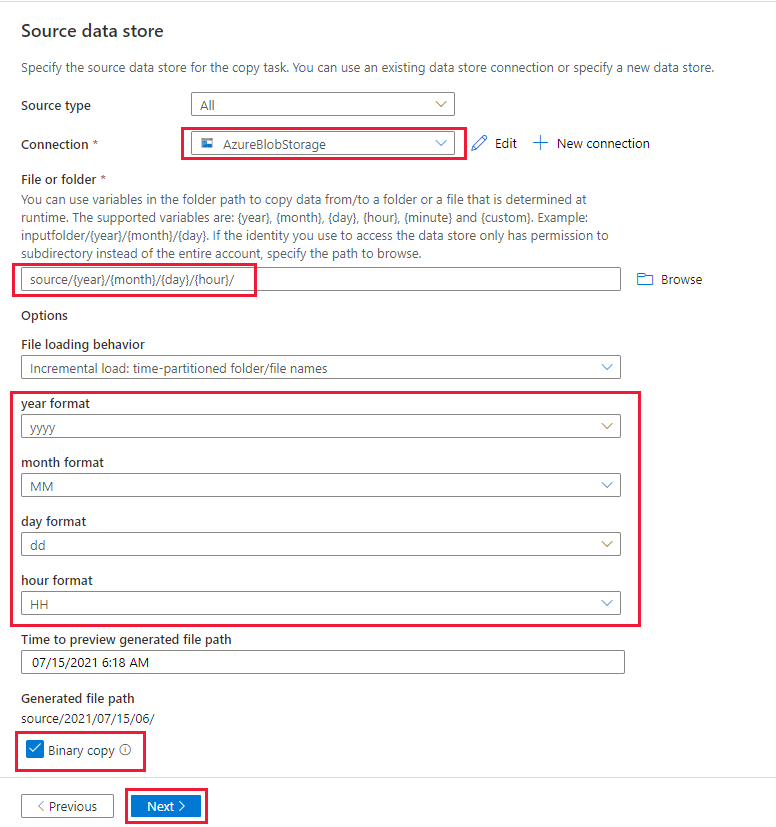
Nella pagina Archivio dati di destinazione completare la procedura seguente:
Selezionare AzureBlob Archiviazione, che corrisponde allo stesso account di archiviazione dell'archivio origine dati.
Sfogliare e selezionare la cartella di destinazione , quindi selezionare OK.
Scrivere il percorso della cartella dinamica come destinazione/{anno}/{mese}/{day}/{hour}/e modificare il formato come illustrato nello screenshot seguente.
Seleziona Avanti.
Nella pagina Impostazioni, in Nome attività immettere DeltaCopyFromBlobPipeline e quindi selezionare Avanti. L'interfaccia utente di Data Factory crea una pipeline con il nome di attività specificato.
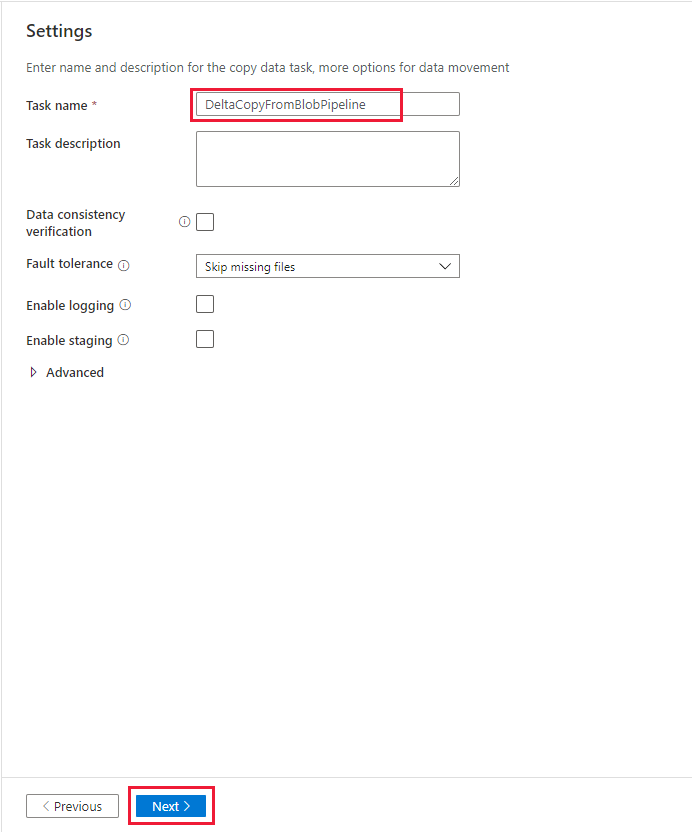
Nella pagina Riepilogo esaminare le impostazioni e quindi selezionare Avanti.
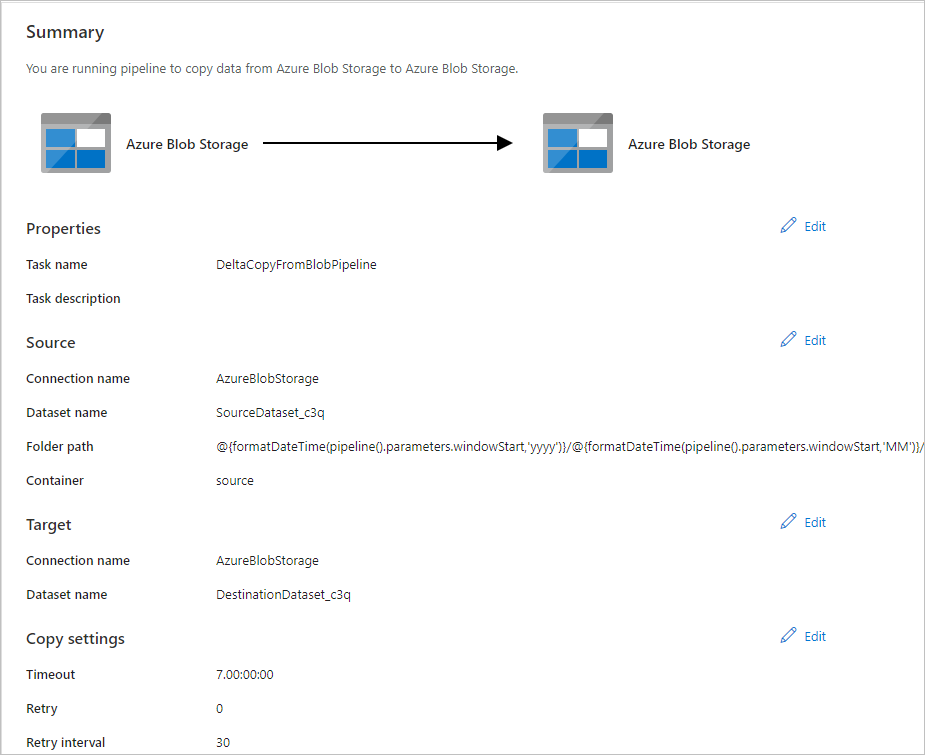
Nella pagina Distribuzione selezionare Monitoraggio per monitorare la pipeline (attività).
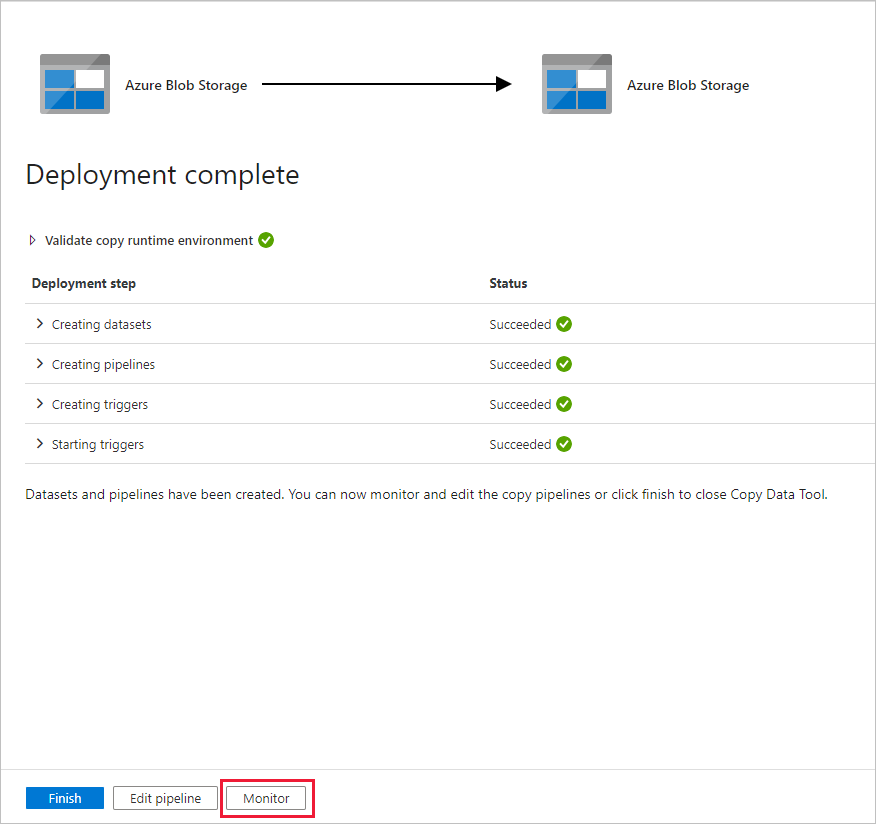
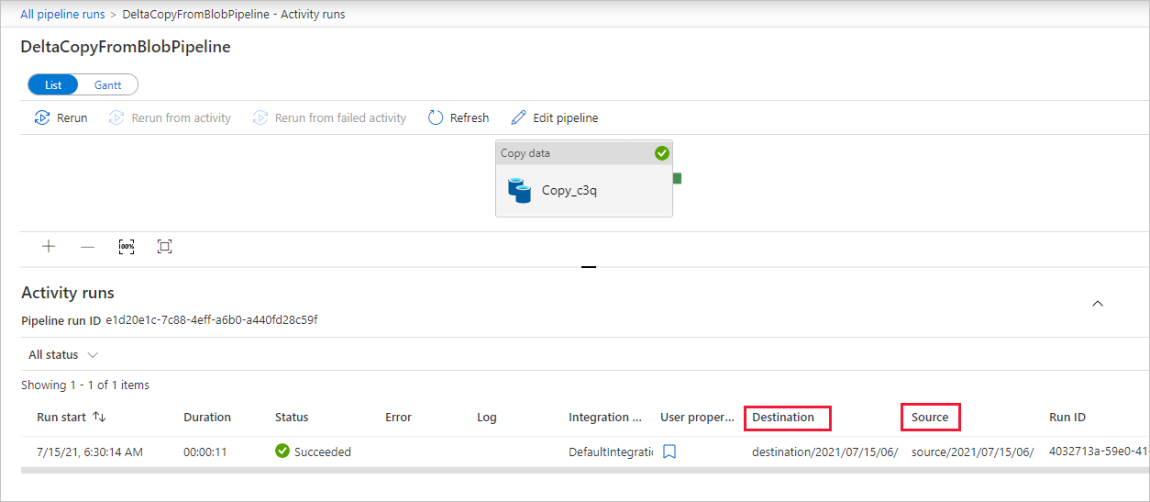
Si noti che la scheda Monitoraggio a sinistra è selezionata automaticamente. È necessario attendere l'esecuzione della pipeline quando viene attivata automaticamente (circa dopo un'ora). Quando viene eseguita, selezionare il collegamento deltaCopyFromBlobPipeline del nome della pipeline per visualizzare i dettagli dell'esecuzione dell'attività o rieseguire la pipeline. Selezionare Aggiorna per aggiornare l'elenco.
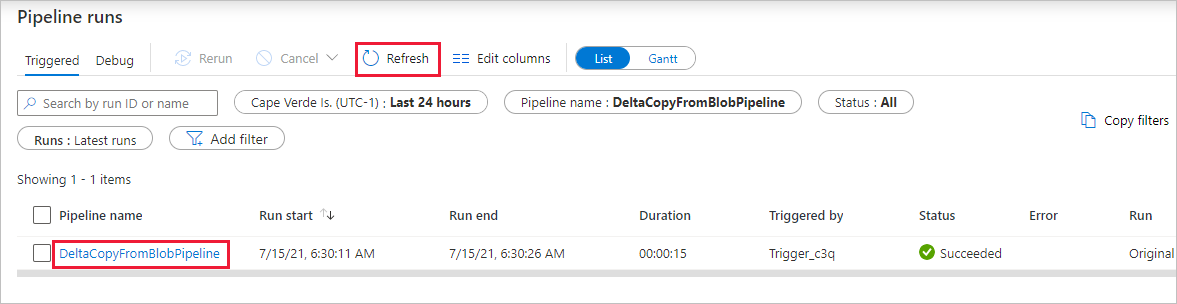
Dato che la pipeline contiene una sola attività (attività di copia), viene visualizzata una sola voce. Modificare la larghezza delle colonne Origine e Destinazione (se necessario) per visualizzare altri dettagli, è possibile vedere che il file di origine (file1.txt) è stato copiato dall'origine /2021/07/07/15/06/ alla destinazione/2021/07/15/06/ con lo stesso nome file.
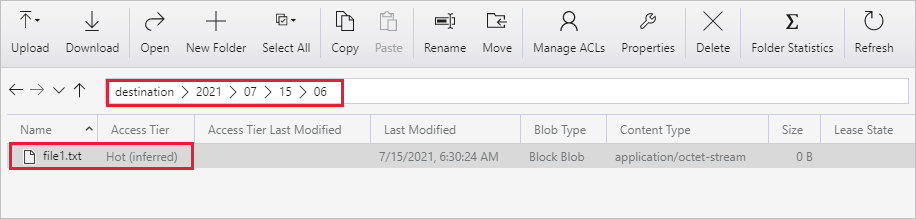
È anche possibile verificare lo stesso usando Archiviazione di Azure Explorer (https://storageexplorer.com/) per analizzare i file.
Creare un altro file di testo vuoto con il nuovo nome file2.txt. Caricare il file file2.txt nell'origine percorso cartella /2021/07/15/07 nell'account di archiviazione. Per eseguire queste attività è possibile usare vari strumenti, ad esempio Azure Storage Explorer.
Nota
È possibile tenere presente che è necessario creare un nuovo percorso di cartella. Modificare il nome della cartella con l'ora UTC. Ad esempio, se l'ora UTC corrente è 7:30 del mese di luglio. 15th, 2021, you can create the folder path as source/2021/07/15/07/ by the rule of {Year}/{Month}/{Day}/{Hour}/.
Per tornare alla visualizzazione Esecuzioni pipeline, selezionare Tutte le esecuzioni di pipeline e attendere che la stessa pipeline venga attivata di nuovo automaticamente dopo un'altra ora.

Selezionare il nuovo collegamento DeltaCopyFromBlobPipeline per la seconda esecuzione della pipeline quando arriva e fare lo stesso per esaminare i dettagli. Si noterà che il file di origine (file2.txt) è stato copiato da source/2021/07/15/07/ a destination/2021/07/15/07/ con lo stesso nome file. È anche possibile verificare lo stesso usando Archiviazione di Azure Explorer (https://storageexplorer.com/) per analizzare i file nel contenitore di destinazione.
Contenuto correlato
Passare all'esercitazione successiva per informazioni sulla trasformazione dei dati usando un cluster Spark in Azure: