Visualizzare le metriche di calcolo
Questo articolo illustra come usare lo strumento di metriche di calcolo nativo nell'interfaccia utente di Azure Databricks per raccogliere le metriche chiave hardware e Spark. Qualsiasi calcolo che usa Databricks Runtime 13.3 LTS e versioni successive ha accesso a queste metriche per impostazione predefinita.
Le metriche sono disponibili in tempo quasi reale con un normale ritardo inferiore a un minuto. Le metriche vengono archiviate nell'archiviazione gestita da Azure Databricks, non nella risorsa di archiviazione del cliente.
In che modo queste nuove metriche sono diverse da Ganglia?
La nuova interfaccia utente delle metriche di calcolo offre una visualizzazione più completa dell'utilizzo delle risorse del cluster, inclusi l'utilizzo di Spark e i processi interni di Databricks. Al contrario, l'interfaccia utente ganglia misura solo il consumo di contenitori Spark. Questa differenza può comportare discrepanze nei valori delle metriche tra le due interfacce.
Accedere all'interfaccia utente delle metriche di calcolo
Per visualizzare l'interfaccia utente delle metriche di calcolo:
- Fare clic su Calcolo nella barra laterale.
- Fare clic sulla risorsa di calcolo per cui si vogliono visualizzare le metriche.
- Fare clic sulla scheda Metriche .
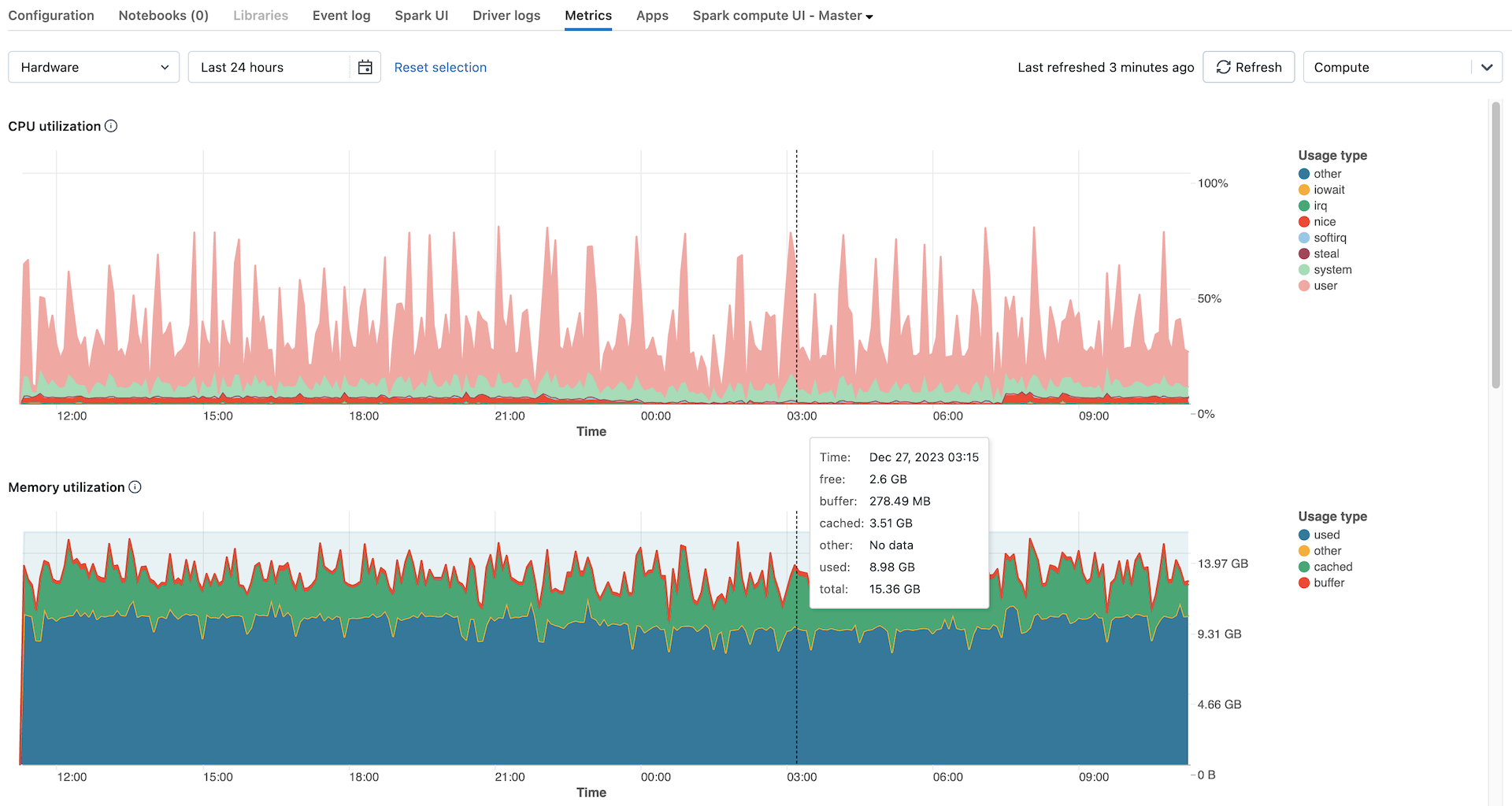
Le metriche hardware vengono visualizzate per impostazione predefinita. Per visualizzare le metriche spark, fare clic sul menu a discesa Hardware con etichetta Hardware e selezionare Spark. È anche possibile selezionare GPU se l'istanza è abilitata per la GPU.
Filtrare le metriche in base al periodo di tempo
È possibile visualizzare le metriche cronologiche selezionando un intervallo di tempo usando il filtro selezione data. Le metriche vengono raccolte ogni minuto, in modo da poter filtrare in base a qualsiasi intervallo di giorno, ora o minuto degli ultimi 30 giorni. Fare clic sull'icona del calendario per selezionare gli intervalli di dati predefiniti oppure fare clic all'interno della casella di testo per definire valori personalizzati.
Nota
Gli intervalli di tempo visualizzati nei grafici si regolano in base al periodo di tempo visualizzato. La maggior parte delle metriche sono medie in base all'intervallo di tempo attualmente visualizzato.
È anche possibile ottenere le metriche più recenti facendo clic sul pulsante Aggiorna .
Visualizzare le metriche a livello di nodo
È possibile visualizzare le metriche per i singoli nodi facendo clic sul menu a discesa Calcolo e selezionando il nodo per cui si vogliono visualizzare le metriche. Le metriche GPU sono disponibili solo a livello di singolo nodo. Le metriche spark non sono disponibili per i singoli nodi.
Nota
Se non si seleziona un nodo specifico, il risultato verrà mediato su tutti i nodi all'interno di un cluster (incluso il driver).
Grafici delle metriche hardware
I grafici delle metriche hardware seguenti sono disponibili per la visualizzazione nell'interfaccia utente delle metriche di calcolo:
- Distribuzione del carico del server: questo grafico mostra l'utilizzo della CPU negli ultimi minuti per ogni nodo.
- Utilizzo CPU: percentuale di tempo impiegato dalla CPU in ogni modalità, in base al costo totale della CPU secondi. La metrica viene calcolata in base all'intervallo di tempo visualizzato nel grafico. Di seguito sono riportate le modalità rilevate:
- guest: se si eseguono macchine virtuali, la CPU usata dalle macchine virtuali
- iowait: tempo trascorso in attesa di I/O
- inattivo: ora in cui la CPU non aveva nulla da fare
- irq: Tempo impiegato per le richieste di interrupt
- bello: tempo usato dai processi che hanno una simpatia positiva, vale a dire una priorità inferiore rispetto ad altre attività
- softirq: tempo dedicato alle richieste di interrupt software
- steal: se si è una macchina virtuale, ora che altre macchine virtuali "rubate" dalle CPU
- system: il tempo impiegato nel kernel
- user: il tempo trascorso nell'ambito dell'utente
- Utilizzo della memoria: utilizzo totale della memoria per ogni modalità, misurato in byte e mediato in base all'intervallo di tempo visualizzato nel grafico. Vengono rilevati i tipi di utilizzo seguenti:
- used: memoria usata (inclusa la memoria usata dai processi in background in esecuzione in un ambiente di calcolo)
- free: memoria inutilizzata
- buffer: memoria usata dai buffer del kernel
- cache: memoria usata dalla cache del file system a livello di sistema operativo
- Utilizzo dello scambio di memoria: utilizzo totale dello scambio di memoria per ogni modalità, misurato in byte e mediato in base all'intervallo di tempo visualizzato nel grafico.
- Spazio libero del file system: utilizzo totale del file system per ogni punto di montaggio, misurato in byte e mediato in base all'intervallo di tempo visualizzato nel grafico.
- Ricevuta tramite rete: numero di byte ricevuti attraverso la rete da ogni dispositivo, in base all'intervallo di tempo visualizzato nel grafico.
- Trasmesso tramite rete: numero di byte trasmessi tramite rete da ogni dispositivo, mediato in base all'intervallo di tempo visualizzato nel grafico.
- Numero di nodi attivi: indica il numero di nodi attivi a ogni timestamp per il calcolo specificato.
Grafici delle metriche Spark
I grafici delle metriche Spark seguenti sono disponibili per la visualizzazione nell'interfaccia utente delle metriche di calcolo:
- Distribuzione del carico del server: questo grafico mostra l'utilizzo della CPU negli ultimi minuti per ogni nodo.
- Attività attive: numero totale di attività in esecuzione in un determinato momento, in base all'intervallo di tempo visualizzato nel grafico.
- Totale attività non riuscite: numero totale di attività non riuscite negli executor, calcolata in base all'intervallo di tempo visualizzato nel grafico.
- Totale attività completate: numero totale di attività completate negli executor, in media in base all'intervallo di tempo visualizzato nel grafico.
- Numero totale di attività: numero totale di tutte le attività (in esecuzione, non riuscite e completate) in executor, calcolate in base all'intervallo di tempo visualizzato nel grafico.
- Lettura casuale totale: dimensioni totali dei dati di lettura casuale, misurate in byte e calcolate in base all'intervallo di tempo visualizzato nel grafico.
Shuffle readindica la somma dei dati di lettura serializzati in tutti gli executor all'inizio di una fase. - Scrittura casuale totale: dimensioni totali dei dati di scrittura casuale, misurate in byte e calcolate in base all'intervallo di tempo visualizzato nel grafico.
Shuffle Writeè la somma di tutti i dati serializzati scritti su tutti gli executor prima della trasmissione (normalmente alla fine di una fase). - Durata totale dell'attività: tempo totale trascorso dalla JVM impiegato per l'esecuzione di attività sugli executor, misurato in secondi e mediato in base all'intervallo di tempo visualizzato nel grafico.
Grafici delle metriche GPU
I grafici delle metriche GPU seguenti sono disponibili per la visualizzazione nell'interfaccia utente delle metriche di calcolo:
- Distribuzione del carico del server: questo grafico mostra l'utilizzo della CPU negli ultimi minuti per ogni nodo.
- Utilizzo del decodificatore per GPU: percentuale di utilizzo del decodificatore GPU, mediata in base all'intervallo di tempo visualizzato nel grafico.
- Utilizzo del codificatore per GPU: percentuale di utilizzo del codificatore GPU, mediata in base all'intervallo di tempo visualizzato nel grafico.
- Byte di memoria del buffer dei frame per GPU: utilizzo della memoria del buffer dei fotogrammi, misurato in byte e mediato in base all'intervallo di tempo visualizzato nel grafico.
- Utilizzo della memoria per GPU: percentuale di utilizzo della memoria GPU, mediata in base all'intervallo di tempo visualizzato nel grafico.
- Utilizzo per GPU: percentuale di utilizzo della GPU, mediata in base all'intervallo di tempo visualizzato nel grafico.
Risoluzione dei problemi
Se vengono visualizzate metriche incomplete o mancanti per un periodo, potrebbe trattarsi di uno dei problemi seguenti:
- Interruzione nel servizio Databricks responsabile dell'esecuzione di query e archiviazione delle metriche.
- Problemi di rete sul lato del cliente.
- Il calcolo è o è in uno stato non integro.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per