Creazione e gestione dei cataloghi
Questo articolo illustra come creare e gestire cataloghi in Unity Catalog. Un catalogo contiene schemi (database) e uno schema contiene tabelle, viste, volumi, modelli e funzioni.
Nota
Nelle aree di lavoro abilitate automaticamente per Unity Catalog è stato creato automaticamente un catalogo di aree di lavoro per impostazione predefinita. Per impostazione predefinita, tutti gli utenti dell'area di lavoro (e solo l'area di lavoro) possono accedervi. Vedere Passaggio 1: Verificare che l'area di lavoro sia abilitata per il catalogo unity.
Nota
Per informazioni su come creare un catalogo esterno, un oggetto Catalogo Unity che esegue il mirroring di un database in un sistema dati esterno, vedere Creare un catalogo esterno. Vedere anche Gestire e usare cataloghi stranieri.
Requisiti
Per creare un catalogo:
È necessario essere un amministratore del metastore di Azure Databricks o avere il privilegio per
CREATE CATALOGil metastore.È necessario disporre di un metastore del catalogo Unity collegato all'area di lavoro in cui si esegue la creazione del catalogo.
Il cluster usato per eseguire un notebook per creare un catalogo deve usare una modalità di accesso conforme a Unity Catalog. Vedere Modalità di accesso.
I warehouse SQL supportano sempre il catalogo Unity.
Creare un catalogo
Per creare un catalogo, è possibile usare Esplora cataloghi o un comando SQL.
Esplora cataloghi
Accedere a un'area di lavoro collegata al metastore.
Fare clic su
 Catalogo.
Catalogo.Fare clic sul pulsante Crea catalogo .
Selezionare il tipo di catalogo da creare:
- Catalogo standard : un oggetto a protezione diretta che organizza gli asset di dati gestiti da Unity Catalog. Per tutti i casi d'uso ad eccezione della federazione lakehouse.
- Catalogo esterno : un oggetto a protezione diretta in Unity Catalog che esegue il mirroring di un database in un sistema di dati esterno tramite Lakehouse Federation. Vedere Panoramica della configurazione di Lakehouse Federation.
(Facoltativo ma fortemente consigliato) Specificare un percorso di archiviazione gestito. Richiede il
CREATE MANAGED STORAGEprivilegio per la posizione esterna di destinazione. Vedere Specificare un percorso di archiviazione gestito nel catalogo unity.Importante
Se l'area di lavoro non dispone di una posizione di archiviazione a livello di metastore, è necessario specificare un percorso di archiviazione gestito quando si crea un catalogo.
Fai clic su Crea.
(Facoltativo) Specificare l'area di lavoro a cui è associato il catalogo.
Per impostazione predefinita, il catalogo viene condiviso con tutte le aree di lavoro collegate al metastore corrente. Se il catalogo conterrà dati che devono essere limitati a aree di lavoro specifiche, passare alla scheda Aree di lavoro e aggiungere tali aree di lavoro.
Per altre informazioni, vedere (Facoltativo) Assegnare un catalogo a aree di lavoro specifiche.
Assegnare le autorizzazioni per il catalogo. Vedere Privilegi del catalogo Unity e oggetti a protezione diretta.
Sql
Eseguire il comando SQL seguente in un notebook o in un editor SQL di Databricks. Gli elementi tra parentesi quadre sono facoltativi. Sostituire i valori segnaposto:
<catalog-name>: nome del catalogo.<location-path>: facoltativo ma fortemente consigliato. Specificare un percorso di archiviazione se si desidera che le tabelle gestite in questo catalogo vengano archiviate in un percorso diverso rispetto all'archiviazione radice predefinita configurata per il metastore.Importante
Se l'area di lavoro non dispone di una posizione di archiviazione a livello di metastore, è necessario specificare un percorso di archiviazione gestito quando si crea un catalogo.
Questo percorso deve essere definito in una configurazione del percorso esterno ed è necessario avere il
CREATE MANAGED STORAGEprivilegio per la configurazione della posizione esterna. È possibile usare il percorso definito nella configurazione del percorso esterno o un sottopercorso (in altre parole,'abfss://my-container-name@storage-account-name.dfs.core.windows.net/finance'o'abfss://my-container-name@storage-account-name.dfs.core.windows.net/finance/product'). Richiede Databricks Runtime 11.3 e versioni successive.<comment>: Descrizione facoltativa o altro commento.
Nota
Se si sta creando un catalogo esterno (un oggetto a protezione diretta in Unity Catalog che esegue il mirroring di un database in un sistema dati esterno, usato per la federazione lakehouse), il comando SQL è
CREATE FOREIGN CATALOGe le opzioni sono diverse. Vedere Creare un catalogo esterno.CREATE CATALOG [ IF NOT EXISTS ] <catalog-name> [ MANAGED LOCATION '<location-path>' ] [ COMMENT <comment> ];Ad esempio, per creare un catalogo denominato
example:CREATE CATALOG IF NOT EXISTS example;Per limitare l'accesso al catalogo a aree di lavoro specifiche nell'account, noto anche come associazione del catalogo dell'area di lavoro, vedere Associare un catalogo a una o più aree di lavoro.
Per le descrizioni dei parametri, vedere CREATE CATALOG.
Assegnare privilegi al catalogo. Vedere Privilegi del catalogo Unity e oggetti a protezione diretta.
Quando si crea un catalogo, vengono creati default automaticamente due schemi (database): e information_schema.
È anche possibile creare un catalogo usando il provider Databricks Terraform e databricks_catalog. È possibile recuperare informazioni sui cataloghi usando databricks_catalogs.
(Facoltativo) Assegnare un catalogo a aree di lavoro specifiche
Se si usano aree di lavoro per isolare l'accesso ai dati utente, è possibile limitare l'accesso al catalogo a aree di lavoro specifiche nell'account, noto anche come associazione del catalogo dell'area di lavoro. L'impostazione predefinita consiste nel condividere il catalogo con tutte le aree di lavoro collegate al metastore corrente.
È possibile consentire l'accesso in lettura e scrittura al catalogo da un'area di lavoro (impostazione predefinita) oppure è possibile specificare l'accesso in sola lettura. Se si specifica di sola lettura, tutte le operazioni di scrittura vengono bloccate da tale area di lavoro a tale catalogo.
I casi d'uso tipici per l'associazione di un catalogo a aree di lavoro specifiche includono:
- Garantire che gli utenti possano accedere solo ai dati di produzione da un ambiente dell'area di lavoro di produzione.
- Garantire che gli utenti possano elaborare solo i dati sensibili da un'area di lavoro dedicata.
- Concedere agli utenti l'accesso in sola lettura ai dati di produzione da un'area di lavoro per sviluppatori per abilitare lo sviluppo e il test.
Esempio di associazione del catalogo dell'area di lavoro
Si prenda l'esempio di isolamento di produzione e sviluppo. Se si specifica che i cataloghi dati di produzione possono essere accessibili solo dalle aree di lavoro di produzione, vengono sostituite tutte le singole concessioni rilasciate agli utenti.
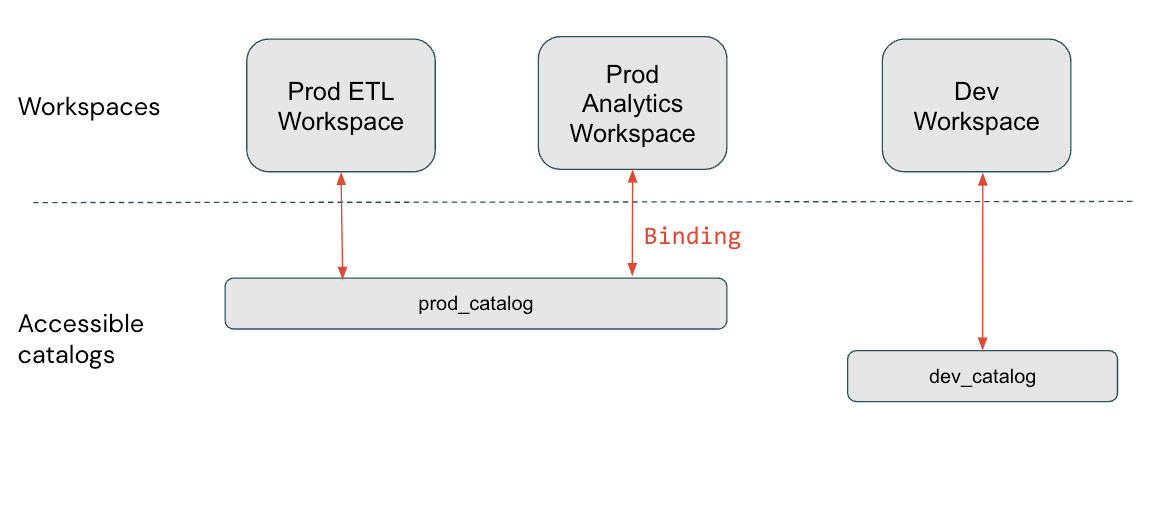
In questo diagramma è prod_catalog associato a due aree di lavoro di produzione. Si supponga che a un utente sia stato concesso l'accesso a una tabella in prod_catalog chiamata my_table (usando GRANT SELECT ON my_table TO <user>). Se l'utente tenta di accedere my_table all'area di lavoro Sviluppo, viene visualizzato un messaggio di errore. L'utente può accedere my_table solo dalle aree di lavoro Prod ETL e Prod Analytics.
Le associazioni del catalogo dell'area di lavoro vengono rispettate in tutte le aree della piattaforma. Ad esempio, se si esegue una query sullo schema delle informazioni, vengono visualizzati solo i cataloghi accessibili nell'area di lavoro in cui si esegue la query. La derivazione dei dati e le interfacce utente di ricerca mostrano in modo analogo solo i cataloghi assegnati all'area di lavoro (se si usano associazioni o per impostazione predefinita).
Associare un catalogo a una o più aree di lavoro
Per assegnare un catalogo a aree di lavoro specifiche, è possibile usare Esplora cataloghi o l'API REST del catalogo Unity.
Autorizzazioni necessarie: amministratore metastore o proprietario del catalogo.
Nota
Gli amministratori metastore possono visualizzare tutti i cataloghi in un metastore usando Esplora cataloghi e i proprietari del catalogo possono visualizzare tutti i cataloghi di cui sono proprietari in un metastore, indipendentemente dal fatto che il catalogo sia assegnato all'area di lavoro corrente. I cataloghi non assegnati all'area di lavoro vengono visualizzati in grigio e nessun oggetto figlio è visibile o su cui è possibile eseguire query.
Esplora cataloghi
Accedere a un'area di lavoro collegata al metastore.
Fare clic su
Catalogo.Nel riquadro Catalogo, a sinistra, fare clic sul nome del catalogo.
Per impostazione predefinita, il riquadro principale esplora cataloghi è l'elenco Cataloghi . È anche possibile selezionare il catalogo.
Nella scheda Aree di lavoro deselezionare la casella di controllo Tutte le aree di lavoro hanno accesso.
Se il catalogo è già associato a una o più aree di lavoro, questa casella di controllo è già deselezionata.
Fare clic su Assegna alle aree di lavoro e immettere o trovare le aree di lavoro da assegnare.
(Facoltativo) Limitare l'accesso all'area di lavoro in sola lettura.
Nel menu Gestisci livello di accesso selezionare Modifica accesso in sola lettura.
È possibile invertire questa selezione in qualsiasi momento modificando il catalogo e selezionando Modifica l'accesso alla lettura e scrittura.
Per revocare l'accesso, passare alla scheda Aree di lavoro , selezionare l'area di lavoro e fare clic su Revoca.
Api
Esistono due API e due passaggi necessari per assegnare un catalogo a un'area di lavoro. Negli esempi seguenti sostituire <workspace-url> con il nome dell'istanza dell'area di lavoro. Per informazioni su come ottenere il nome dell'istanza dell'area di lavoro e l'ID dell'area di lavoro, vedere Ottenere gli identificatori per gli oggetti dell'area di lavoro. Per informazioni su come ottenere i token di accesso, vedere Autenticazione per l'automazione di Azure Databricks - Panoramica.
Usare l'API
catalogsper impostare il catalogoisolation modesuISOLATED:curl -L -X PATCH 'https://<workspace-url>/api/2.1/unity-catalog/catalogs/<my-catalog> \ -H 'Authorization: Bearer <my-token> \ -H 'Content-Type: application/json' \ --data-raw '{ "isolation_mode": "ISOLATED" }'L'impostazione predefinita
isolation modeèOPENtutte le aree di lavoro collegate al metastore.Usare l'API di aggiornamento
bindingsper assegnare le aree di lavoro al catalogo:curl -L -X PATCH 'https://<workspace-url>/api/2.1/unity-catalog/bindings/catalog/<my-catalog> \ -H 'Authorization: Bearer <my-token> \ -H 'Content-Type: application/json' \ --data-raw '{ "add": [{"workspace_id": <workspace-id>, "binding_type": <binding-type>}...], "remove": [{"workspace_id": <workspace-id>, "binding_type": "<binding-type>}...] }'Usare le
"add"proprietà e"remove"per aggiungere o rimuovere associazioni dell'area di lavoro.<binding-type>può essere“BINDING_TYPE_READ_WRITE”(impostazione predefinita) o“BINDING_TYPE_READ_ONLY”.
Per elencare tutte le assegnazioni dell'area di lavoro per un catalogo, usare l'API elenco bindings :
curl -L -X GET 'https://<workspace-url>/api/2.1/unity-catalog/bindings/catalog/<my-catalog> \
-H 'Authorization: Bearer <my-token> \
Annullare l'associazione di un catalogo da un'area di lavoro
Le istruzioni per revocare l'accesso all'area di lavoro a un catalogo tramite Esplora cataloghi o l'API bindings sono incluse in Associare un catalogo a una o più aree di lavoro.
Importante
Se l'area di lavoro è stata abilitata automaticamente per Unity Catalog e si dispone di un catalogo dell'area di lavoro, gli amministratori dell'area di lavoro possiedono tale catalogo e dispongono di tutte le autorizzazioni per tale catalogo solo nell'area di lavoro. Se il catalogo viene scollegato o associato ad altri cataloghi, è necessario concedere manualmente le autorizzazioni necessarie ai membri del gruppo di amministratori dell'area di lavoro come singoli utenti o usando gruppi a livello di account, perché il gruppo di amministratori dell'area di lavoro è un gruppo locale dell'area di lavoro. Per altre informazioni sui gruppi di account e sui gruppi locali dell'area di lavoro, vedere Differenza tra gruppi di account e gruppi locali dell'area di lavoro.
Aggiungere schemi al catalogo
Per informazioni su come aggiungere schemi (database) al catalogo. vedere Creare e gestire schemi (database).
Visualizzare i dettagli del catalogo
Per visualizzare informazioni su un catalogo, è possibile usare Esplora cataloghi o un comando SQL.
Esplora cataloghi
Accedere a un'area di lavoro collegata al metastore.
Fare clic su
Catalogo.Nel riquadro Catalogo trovare il catalogo e fare clic sul relativo nome.
Alcuni dettagli sono elencati nella parte superiore della pagina. Altri utenti possono essere visualizzati nelle schede Schemi, Dettagli, Autorizzazioni e Aree di lavoro .
Sql
Eseguire il comando SQL seguente in un notebook o in un editor SQL di Databricks. Gli elementi tra parentesi quadre sono facoltativi. Sostituire il segnaposto <catalog-name>.
Per informazioni dettagliate, vedere DESCRIBE CATALOG.
DESCRIBE CATALOG <catalog-name>;
Usare CATALOG EXTENDED per ottenere i dettagli completi.
Eliminare un catalogo
Per eliminare o eliminare un catalogo, è possibile usare Esplora cataloghi o un comando SQL. Per eliminare un catalogo, è necessario essere il proprietario.
Esplora cataloghi
È necessario eliminare tutti gli schemi nel catalogo tranne information_schema prima di poter eliminare un catalogo. Questo include lo schema creato automaticamente default .
- Accedere a un'area di lavoro collegata al metastore.
- Fare clic su Catalogo.
- Nel riquadro Catalogo, a sinistra, fare clic sul catalogo da eliminare.
- Nel riquadro dei dettagli fare clic sul menu a tre punti a sinistra del pulsante Crea database e selezionare Elimina.
- Nella finestra di dialogo Elimina catalogo fare clic su Elimina.
Sql
Eseguire il comando SQL seguente in un notebook o in un editor SQL di Databricks. Gli elementi tra parentesi quadre sono facoltativi. Sostituire il segnaposto <catalog-name>.
Per le descrizioni dei parametri, vedere DROP CATALOG.
Se si usa DROP CATALOG senza l'opzione CASCADE , è necessario eliminare tutti gli schemi nel catalogo tranne information_schema prima di poter eliminare il catalogo. Questo include lo schema creato automaticamente default .
DROP CATALOG [ IF EXISTS ] <catalog-name> [ RESTRICT | CASCADE ]
Ad esempio, per eliminare un catalogo denominato vaccine e i relativi schemi:
DROP CATALOG vaccine CASCADE
Gestire il catalogo predefinito
Per ogni area di lavoro abilitata per Il catalogo Unity è configurato un catalogo predefinito. Il catalogo predefinito consente di eseguire operazioni sui dati senza specificare un catalogo. Se si omette il nome del catalogo di primo livello quando si eseguono operazioni sui dati, viene utilizzato il catalogo predefinito.
Un amministratore dell'area di lavoro può visualizzare o cambiare il catalogo predefinito usando l'interfaccia utente Amministrazione Impostazioni. È anche possibile impostare il catalogo predefinito per un cluster usando una configurazione spark.
I comandi che non specificano il catalogo (ad esempio GRANT CREATE TABLE ON SCHEMA myschema TO mygroup) vengono valutati per il catalogo nell'ordine seguente:
- Il catalogo è impostato per la sessione usando un'istruzione
USE CATALOGo un'impostazione JDBC? - La configurazione
spark.databricks.sql.initial.catalog.namespacedi Spark è impostata nel cluster? - Esiste un catalogo predefinito dell'area di lavoro per il cluster?
Configurazione del catalogo predefinita quando Il catalogo unity è abilitato
Il catalogo predefinito configurato inizialmente per l'area di lavoro dipende dal modo in cui l'area di lavoro è stata abilitata per il catalogo Unity:
- Per alcune aree di lavoro abilitate automaticamente per Unity Catalog, il catalogo dell'area di lavoro è stato impostato come catalogo predefinito. Vedere Abilitazione automatica del catalogo Unity.
- Per tutte le altre aree di lavoro, il
hive_metastorecatalogo è stato impostato come catalogo predefinito.
Se si esegue la transizione dal metastore Hive al catalogo Unity all'interno di un'area di lavoro esistente, in genere è opportuno usare hive_metastore come catalogo predefinito per evitare di influire sul codice esistente che fa riferimento al metastore hive.
Modificare il catalogo predefinito
Un amministratore dell'area di lavoro può modificare il catalogo predefinito per l'area di lavoro. Chiunque disponga dell'autorizzazione per creare o modificare un cluster può impostare un catalogo predefinito diverso per il cluster.
Avviso
La modifica del catalogo predefinito può interrompere le operazioni sui dati esistenti che dipendono da essa.
Per configurare un catalogo predefinito diverso per un'area di lavoro:
- Accedere all'area di lavoro come amministratore dell'area di lavoro.
- Fare clic sul nome utente nella barra superiore dell'area di lavoro e selezionare Impostazioni dall'elenco a discesa.
- Fare clic sulla scheda Avanzate.
- Nella riga Catalogo predefinito per l'area di lavoro immettere il nome del catalogo e fare clic su Salva.
Riavviare sql warehouse e cluster per rendere effettiva la modifica. Tutti i nuovi e riavviati sql warehouse e cluster useranno questo catalogo come impostazione predefinita dell'area di lavoro.
È anche possibile eseguire l'override del catalogo predefinito per un cluster specifico impostando la configurazione spark seguente nel cluster. Questo approccio non è disponibile per i warehouse SQL:
spark.databricks.sql.initial.catalog.name
Per istruzioni, vedere Configurazione di Spark.
Visualizzare il catalogo predefinito corrente
Per ottenere il catalogo predefinito corrente per l'area di lavoro, è possibile usare un'istruzione SQL in un notebook o in una query dell'editor SQL. Un amministratore dell'area di lavoro può ottenere il catalogo predefinito usando l'interfaccia utente di Amministrazione Impostazioni.
Impostazioni dell'amministratore
- Accedere all'area di lavoro come amministratore dell'area di lavoro.
- Fare clic sul nome utente nella barra superiore dell'area di lavoro e selezionare Impostazioni dall'elenco a discesa.
- Fare clic sulla scheda Avanzate.
- Nel catalogo predefinito per la riga dell'area di lavoro visualizzare il nome del catalogo.
Sql
Eseguire il comando seguente in un notebook o in una query dell'editor SQL in esecuzione in un cluster conforme al catalogo di SQL Warehouse o Unity. Il catalogo predefinito dell'area di lavoro viene restituito finché non è stata impostata alcuna USE CATALOG istruzione o impostazione JDBC nella sessione e, purché non sia impostata alcuna spark.databricks.sql.initial.catalog.namespace configurazione per il cluster.
SELECT current_catalog();
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per