Ricerca vettoriale di Databricks
Questo articolo offre una panoramica della soluzione di database vettoriale di Databricks, Ricerca vettoriale di Databricks, incluse le informazioni e il relativo funzionamento.
Che cos'è La ricerca vettoriale di Databricks?
Databricks Vector Search è un database vettoriale integrato nella piattaforma data intelligence di Databricks e integrato con i relativi strumenti di governance e produttività. Un database vettoriale è un database ottimizzato per archiviare e recuperare incorporamenti. Gli incorporamenti sono rappresentazioni matematiche del contenuto semantico dei dati, in genere dati di testo o immagine. Gli incorporamenti vengono generati da un modello linguistico di grandi dimensioni e sono un componente chiave di molte applicazioni GenAI che dipendono dalla ricerca di documenti o immagini simili tra loro. Esempi sono i sistemi RAG, i sistemi di raccomandazione e il riconoscimento di immagini e video.
Con Ricerca vettoriale si crea un indice di ricerca vettoriale da una tabella Delta. L'indice include dati incorporati con i metadati. È quindi possibile eseguire query sull'indice usando un'API REST per identificare i vettori più simili e restituire i documenti associati. È possibile strutturare l'indice da sincronizzare automaticamente quando viene aggiornata la tabella Delta sottostante.
Databricks Vector Search usa l'algoritmo HNSW (Hierarchical Navigable Small World) per le ricerche approssimative vicine più vicine e la metrica della distanza L2 per misurare la somiglianza del vettore di incorporamento. Se si vuole usare la somiglianza del coseno, è necessario normalizzare gli incorporamenti dei punti dati prima di inserirli in Ricerca vettoriale. Quando i punti dati vengono normalizzati, la classificazione prodotta dalla distanza L2 corrisponde alla classificazione prodotta dalla somiglianza del coseno.
Come funziona La ricerca vettoriale?
Per creare un database vettoriale in Databricks, è prima necessario decidere come fornire incorporamenti vettoriali. Databricks supporta tre opzioni:
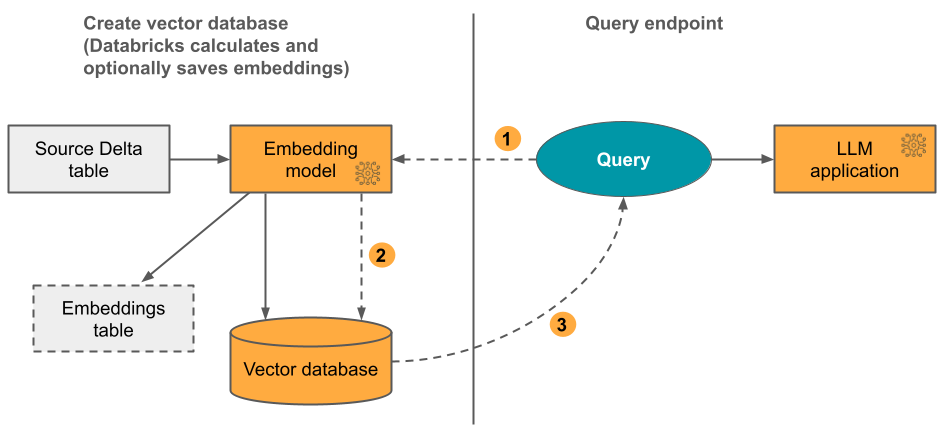
Opzione 1 Specificare una tabella Delta di origine contenente dati in formato testo. Databricks calcola gli incorporamenti, usando un modello specificato e, facoltativamente, salva gli incorporamenti in una tabella in Unity Catalog. Quando la tabella Delta viene aggiornata, l'indice rimane sincronizzato con la tabella Delta.
Il diagramma seguente illustra il processo:
- Calcolare gli incorporamenti delle query. La query può includere filtri di metadati.
- Eseguire ricerche di somiglianza per identificare i documenti più rilevanti.
- Restituire i documenti più rilevanti e aggiungerli alla query.
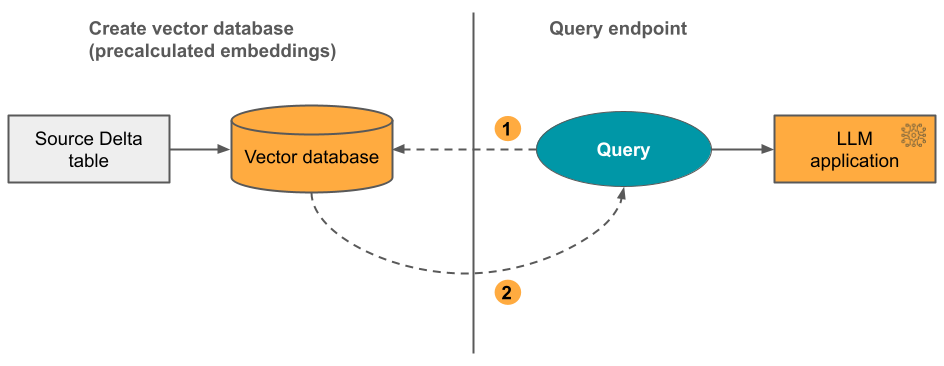
Opzione 2 Specificare una tabella Delta di origine contenente incorporamenti precalcosi. Quando la tabella Delta viene aggiornata, l'indice rimane sincronizzato con la tabella Delta.
Il diagramma seguente illustra il processo:
- La query è costituita da incorporamenti e può includere filtri di metadati.
- Eseguire ricerche di somiglianza per identificare i documenti più rilevanti. Restituire i documenti più rilevanti e aggiungerli alla query.
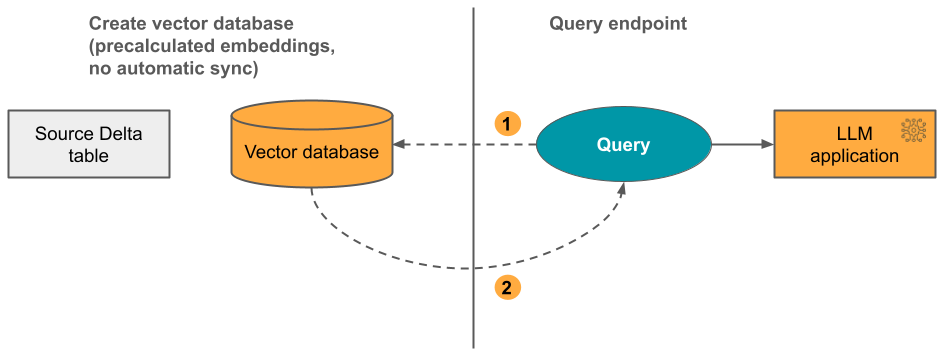
Opzione 3 Specificare una tabella Delta di origine contenente incorporamenti precalcosi. Non è presente alcuna sincronizzazione automatica quando la tabella Delta viene aggiornata. È necessario aggiornare manualmente l'indice usando l'API REST quando viene modificata la tabella di incorporamento.
Il diagramma seguente illustra il processo, che corrisponde all'opzione 2, ad eccezione del fatto che l'indice vettoriale non viene aggiornato automaticamente quando la tabella Delta viene modificata:
Calcolo della ricerca di somiglianza
Il calcolo della ricerca di somiglianza usa la formula seguente:
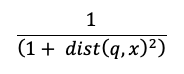
dove dist è la distanza euclidea tra la query q e la voce xdi indice :
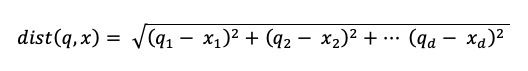
Come configurare La ricerca vettoriale
Per usare La ricerca vettoriale di Databricks, è necessario creare quanto segue:
- Endpoint di ricerca vettoriale. Questo endpoint serve l'indice di ricerca vettoriale. È possibile eseguire query e aggiornare l'endpoint usando l'API REST o l'SDK. Gli endpoint vengono ridimensionati automaticamente per supportare le dimensioni dell'indice o il numero di richieste simultanee. Per istruzioni, vedere Creare un endpoint di ricerca vettoriale.
- Indice di ricerca vettoriale. L'indice di ricerca vettoriale viene creato da una tabella Delta ed è ottimizzato per fornire ricerche vicine approssimative in tempo reale. L'obiettivo della ricerca è identificare i documenti simili alla query. Gli indici di ricerca vettoriali vengono visualizzati in e sono regolati da Unity Catalog. Per istruzioni, vedere Creare un indice di ricerca vettoriale.
Inoltre, se si sceglie di usare Databricks per calcolare gli incorporamenti, è necessario creare anche un endpoint di gestione del modello per il modello di incorporamento. Per istruzioni, vedere Creare un modello di base che gestisce gli endpoint.
Per eseguire query sull'endpoint di gestione del modello, usare l'API REST o Python SDK. La query può definire filtri in base a qualsiasi colonna della tabella Delta. Per informazioni dettagliate, vedere Usare filtri per query, informazioni di riferimento sull'API o informazioni di riferimento su Python SDK.
Requisiti
- Area di lavoro abilitata per Unity Catalog.
- Calcolo serverless abilitato.
- Per la tabella di origine deve essere abilitato il feed di dati delle modifiche.
- CREATE TABLE privilegi per gli schemi del catalogo per creare indici.
- Token di accesso personali abilitati.
Protezione dei dati e autenticazione
Databricks implementa i controlli di sicurezza seguenti per proteggere i dati:
- Ogni richiesta cliente a Ricerca vettoriale è isolata, autenticata e autorizzata logicamente.
- La ricerca vettoriale di Databricks crittografa tutti i dati inattivi (AES-256) e in transito (TLS 1.2+).
Ricerca vettoriale di Databricks supporta due modalità di autenticazione:
- Token di accesso personale: è possibile usare un token di accesso personale per eseguire l'autenticazione con Ricerca vettoriale. Vedere Token di autenticazione dell'accesso personale. Se si usa l'SDK in un ambiente notebook, viene generato automaticamente un token PAT per l'autenticazione.
- Token dell'entità servizio: un amministratore può generare un token dell'entità servizio e passarlo all'SDK o all'API. Vedere Usare le entità servizio. Per i casi d'uso di produzione, Databricks consiglia di usare un token dell'entità servizio.
Monitorare l'utilizzo e i costi di Ricerca vettoriale
La tabella del sistema di utilizzo fatturabile consente di monitorare l'utilizzo e i costi associati agli indici e agli endpoint di ricerca vettoriali. Di seguito è fornito un esempio di query:
SELECT *
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
AND usage_metadata.endpoint_name IS NOT NULL
Per informazioni dettagliate sul contenuto della tabella relativa all'utilizzo della fatturazione, vedere Informazioni di riferimento sulla tabella del sistema di utilizzo fatturabile. Le query aggiuntive sono disponibili nel notebook di esempio seguente.
Notebook query sulle tabelle di sistema di Ricerca vettoriale
Limiti relativi alle dimensioni delle risorse e dei dati
La tabella seguente riepiloga i limiti delle dimensioni delle risorse e dei dati per gli endpoint e gli indici di ricerca vettoriali:
| Conto risorse | Granularità | Limite |
|---|---|---|
| Endpoint di ricerca vettoriali | Per area di lavoro | 100 |
| Incorporamenti | Per endpoint | 100.000.000 |
| Dimensione di incorporamento | Per indice | 4096 |
| Indici | Per endpoint | 20 |
| Colonne | Per indice | 20 |
| Colonne | Tipi supportati: byte, short, integer, long, float, double, boolean, string, timestamp, date | |
| Campi dei metadati | Per indice | 20 |
| Nome dell'indice | Per indice | 128 caratteri |
I limiti seguenti si applicano alla creazione e all'aggiornamento degli indici di ricerca vettoriale:
| Conto risorse | Granularità | Limite |
|---|---|---|
| Dimensioni delle righe per l'indice di sincronizzazione delta | Per indice | 100 KB |
| Incorporamento delle dimensioni delle colonne di origine per l'indice di Sincronizzazione delta | Per indice | 32764 byte |
| Limite delle dimensioni delle richieste di upsert bulk per l'indice Direct Vector | Per indice | 10 MB |
| Limite delle dimensioni delle richieste di eliminazione bulk per l'indice Direct Vector | Per indice | 10 MB |
I limiti seguenti si applicano all'API di query per la ricerca vettoriale.
| Conto risorse | Granularità | Limite |
|---|---|---|
| Lunghezza del testo della query | Per query | 32764 |
| Numero massimo di risultati restituiti | Per query | 10,000 |
Limiti
- PrivateLink è attualmente limitato al set selezionato di clienti. Se si è interessati a usare la funzionalità con PrivateLink, contattare il rappresentante dell'account Databricks.
- Le aree di lavoro regolamentate non sono supportate, pertanto questa funzionalità non è conforme a HIPAA.
- Le autorizzazioni a livello di riga e colonna non sono supportate. È tuttavia possibile implementare elenchi di controllo di accesso a livello di applicazione personalizzati usando l'API di filtro.
Risorse aggiuntive
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per