Oggetti dati nella data lakehouse di Databricks
Databricks lakehouse organizza i dati archiviati con Delta Lake nell'archiviazione di oggetti cloud con relazioni familiari, ad esempio database, tabelle e viste. Questo modello combina molti dei vantaggi di un data warehouse aziendale con la scalabilità e la flessibilità di un data lake. Altre informazioni sul funzionamento di questo modello e sulla relazione tra dati oggetto e metadati, in modo da poter applicare le procedure consigliate durante la progettazione e l'implementazione di Databricks lakehouse per l'organizzazione.
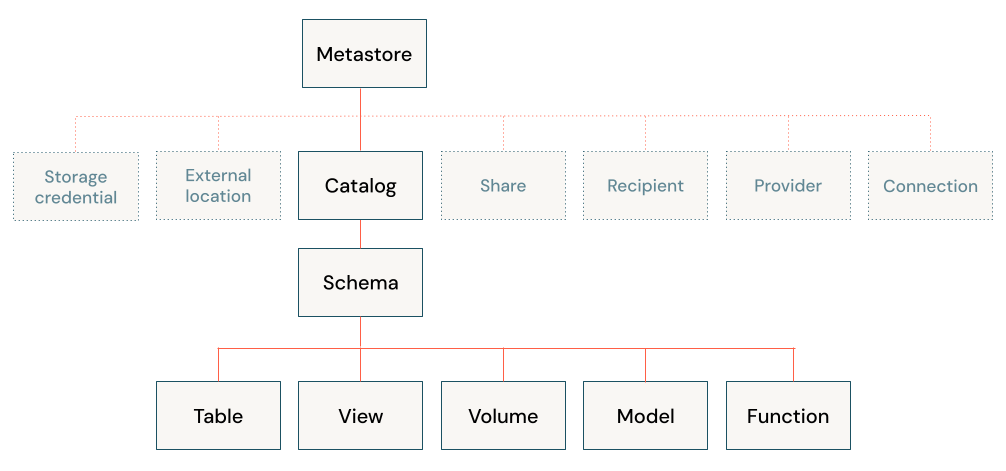
Quali oggetti dati si trovano in Databricks lakehouse?
L'architettura di Databricks lakehouse combina i dati archiviati con il protocollo Delta Lake nell'archiviazione di oggetti cloud con i metadati registrati in un metastore. In Databricks lakehouse sono presenti cinque oggetti principali:
- Catalogo: raggruppamento di database.
- Database o schema: raggruppamento di oggetti in un catalogo. I database contengono tabelle, viste e funzioni.
- Tabella: raccolta di righe e colonne archiviate come file di dati nell'archivio oggetti.
- Vista: una query salvata in genere su una o più tabelle o origini dati.
- Funzione: logica salvata che restituisce un valore scalare o un set di righe.
Per informazioni sulla protezione degli oggetti con Il catalogo unity, vedere Modello di oggetti a protezione diretta.
Che cos'è un metastore?
Il metastore contiene tutti i metadati che definiscono gli oggetti dati nella lakehouse. Azure Databricks offre le opzioni del metastore seguenti:
Metastore del catalogo Unity: Il catalogo unity offre funzionalità centralizzate di controllo di accesso, controllo, derivazione e individuazione dei dati. I metastore di Unity Catalog vengono creati a livello di account Azure Databricks e un singolo metastore può essere usato in più aree di lavoro.
Ogni metastore del catalogo Unity è configurato con una posizione di archiviazione radice in un contenitore azure Data Lake Archiviazione Gen2 nell'account Azure. Questo percorso di archiviazione viene usato per impostazione predefinita per l'archiviazione dei dati per le tabelle gestite.
In Unity Catalog i dati sono protetti per impostazione predefinita. Inizialmente, gli utenti non hanno accesso ai dati in un metastore. L'accesso può essere concesso da un amministratore del metastore o dal proprietario di un oggetto. Gli oggetti a protezione diretta nel Catalogo Unity sono gerarchici e i privilegi vengono ereditati verso il basso. Unity Catalog offre un'unica posizione per amministrare i criteri di accesso ai dati. Gli utenti possono accedere ai dati in Unity Catalog da qualsiasi area di lavoro a cui è collegato il metastore. Per altre informazioni, vedere Gestire i privilegi in Unity Catalog.
Metastore Hive predefinito (legacy): ogni area di lavoro di Azure Databricks include un metastore Hive predefinito come servizio gestito. Un'istanza del metastore viene distribuita in ogni cluster e accede in modo sicuro ai metadati da un repository centrale per ogni area di lavoro del cliente.
Il metastore Hive offre un modello di governance dei dati meno centralizzato rispetto a Unity Catalog. Per impostazione predefinita, un cluster consente a tutti gli utenti di accedere a tutti i dati gestiti dal metastore Hive predefinito dell'area di lavoro, a meno che non sia abilitato il controllo di accesso alle tabelle per tale cluster. Per altre informazioni, vedere Controllo di accesso alle tabelle metastore Hive (legacy).For more information, see Hive metastore table access control (legacy).
I controlli di accesso alle tabelle non vengono archiviati a livello di account e pertanto devono essere configurati separatamente per ogni area di lavoro. Per sfruttare i vantaggi del modello di governance dei dati centralizzato e semplificato fornito da Unity Catalog, Databricks consiglia di aggiornare le tabelle gestite dal metastore Hive dell'area di lavoro al metastore di Unity Catalog.
Metastore Hive esterno (legacy): è anche possibile usare il proprio metastore in Azure Databricks. I cluster Di Azure Databricks possono connettersi ai metastore Apache Hive esterni esistenti. È possibile usare il controllo di accesso alle tabelle per gestire le autorizzazioni in un metastore esterno. I controlli di accesso alle tabelle non vengono archiviati nel metastore esterno e pertanto devono essere configurati separatamente per ogni area di lavoro. Databricks consiglia invece di usare Unity Catalog per la semplicità e il modello di governance incentrato sugli account.
Indipendentemente dal metastore usato, Azure Databricks archivia tutti i dati della tabella nell'archiviazione oggetti nell'account cloud.
Che cos'è un catalogo?
Un catalogo è l'astrazione più alta (o granularità grossolana) nel modello relazionale Databricks lakehouse. Ogni database verrà associato a un catalogo. I cataloghi esistono come oggetti all'interno di un metastore.
Prima dell'introduzione di Unity Catalog, Azure Databricks usava uno spazio dei nomi a due livelli. I cataloghi sono il terzo livello nel modello di suddivisione dei nomi del catalogo Unity:
catalog_name.database_name.table_name
Il metastore Hive predefinito supporta solo un singolo catalogo, hive_metastore.
Che cos'è un database?
Un database è una raccolta di oggetti dati, ad esempio tabelle o viste (dette anche "relazioni") e funzioni. In Azure Databricks i termini "schema" e "database" vengono usati in modo intercambiabile (mentre in molti sistemi relazionali un database è una raccolta di schemi).
I database verranno sempre associati a una posizione nell'archiviazione di oggetti cloud. Facoltativamente, è possibile specificare un oggetto LOCATION durante la registrazione di un database, tenendo presente che:
- L'oggetto
LOCATIONassociato a un database viene sempre considerato una posizione gestita. - La creazione di un database non crea file nel percorso di destinazione.
- L'oggetto
LOCATIONdi un database determinerà il percorso predefinito per i dati di tutte le tabelle registrate nel database. - L'eliminazione di un database comporterà l'eliminazione ricorsiva di tutti i dati e i file archiviati in un percorso gestito.
Questa interazione tra percorsi gestiti da database e file di dati è molto importante. Per evitare l'eliminazione accidentale dei dati:
- Non condividere percorsi di database tra più definizioni di database.
- Non registrare un database in un percorso che contiene già dati.
- Per gestire il ciclo di vita dei dati indipendentemente dal database, salvare i dati in un percorso non annidato in nessun percorso del database.
Che cos'è una tabella?
Una tabella di Azure Databricks è una raccolta di dati strutturati. Una tabella Delta archivia i dati come directory di file nell'archivio oggetti cloud e registra i metadati della tabella nel metastore all'interno di un catalogo e di uno schema. Poiché Delta Lake è il formato predefinito per le tabelle create in Azure Databricks, per impostazione predefinita tutte le tabelle create in Databricks sono tabelle Delta. Poiché le tabelle Delta archiviano i dati nell'archiviazione di oggetti cloud e forniscono riferimenti ai dati tramite un metastore, gli utenti di un'organizzazione possono accedere ai dati usando le API preferite; in Databricks sono inclusi SQL, Python, PySpark, Scala e R.
Si noti che è possibile creare tabelle in Databricks che non sono tabelle Delta. Queste tabelle non sono supportate da Delta Lake e non forniscono le transazioni ACID e le prestazioni ottimizzate delle tabelle Delta. Le tabelle che rientrano in questa categoria includono tabelle registrate su dati in sistemi esterni e tabelle registrate in altri formati di file nel data lake. Vedere Connessione alle origini dati.
Esistono due tipi di tabelle nelle tabelle Databricks, gestite e non gestite (o esterne).
Nota
La distinzione tra tabelle live Delta e tabelle live in streaming non viene applicata dal punto di vista della tabella.
Che cos'è una tabella gestita?
Azure Databricks gestisce sia i metadati che i dati per una tabella gestita; quando si elimina una tabella, si eliminano anche i dati sottostanti. Gli analisti dei dati e altri utenti che lavorano principalmente in SQL possono preferire questo comportamento. Le tabelle gestite sono l'impostazione predefinita durante la creazione di una tabella. I dati per una tabella gestita risiedono nel LOCATION del database in cui sono registrati. Questa relazione gestita tra il percorso dei dati e il database significa che per spostare una tabella gestita in un nuovo database, è necessario riscrivere tutti i dati nella nuova posizione.
Esistono diversi modi per creare tabelle gestite, tra cui:
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name (field_name1 INT, field_name2 STRING)
df.write.saveAsTable("table_name")
Che cos'è una tabella non gestita?
Azure Databricks gestisce solo i metadati per le tabelle non gestite (esterne); quando si rilascia una tabella, non si influiscono sui dati sottostanti. Le tabelle non gestite specificano sempre un LOCATION oggetto durante la creazione della tabella. È possibile registrare una directory esistente di file di dati come tabella o specificare un percorso quando una tabella viene definita per la prima volta. Poiché i dati e i metadati vengono gestiti in modo indipendente, è possibile rinominare una tabella o registrarla in un nuovo database senza dover spostare dati. I data engineer preferiscono spesso tabelle non gestite e la flessibilità offerta per i dati di produzione.
Esistono diversi modi per creare tabelle non gestite, tra cui:
CREATE TABLE table_name
USING DELTA
LOCATION '/path/to/existing/data'
CREATE TABLE table_name
(field_name1 INT, field_name2 STRING)
LOCATION '/path/to/empty/directory'
df.write.option("path", "/path/to/empty/directory").saveAsTable("table_name")
Che cos'è una visualizzazione?
Una vista archivia il testo per una query in genere su una o più origini dati o tabelle nel metastore. In Databricks una vista equivale a un dataframe Spark persistente come oggetto in un database. A differenza dei dataframe, è possibile eseguire query sulle viste da qualsiasi parte del prodotto Databricks, presupponendo di disporre delle autorizzazioni necessarie. La creazione di una vista non elabora o scrive dati; solo il testo della query viene registrato nel metastore nel database associato.
Che cos'è una visualizzazione temporanea?
Una vista temporanea ha un ambito limitato e la persistenza e non è registrata in uno schema o in un catalogo. La durata di una visualizzazione temporanea varia in base all'ambiente in uso:
- Nei notebook e nei processi, le visualizzazioni temporanee hanno come ambito il notebook o il livello di script. Non è possibile fare riferimento all'esterno del notebook in cui sono dichiarati e non esiste più quando il notebook si scollega dal cluster.
- In Databricks SQL le viste temporanee hanno come ambito il livello di query. Più istruzioni all'interno della stessa query possono usare la visualizzazione temporanea, ma non può essere fatto riferimento in altre query, anche all'interno dello stesso dashboard.
- Le visualizzazioni temporanee globali hanno come ambito il livello del cluster e possono essere condivise tra notebook o processi che condividono risorse di calcolo. Databricks consiglia di usare viste con ACL di tabella appropriati anziché viste temporanee globali.
Che cos'è una funzione?
Le funzioni consentono di associare la logica definita dall'utente a un database. Le funzioni possono restituire valori scalari o set di righe. Le funzioni vengono usate per aggregare i dati. Azure Databricks consente di salvare le funzioni in vari linguaggi a seconda del contesto di esecuzione, con SQL supportato su larga scala. È possibile usare le funzioni per fornire l'accesso gestito alla logica personalizzata in un'ampia gamma di contesti nel prodotto Databricks.
Come funzionano gli oggetti relazionali in tabelle live Delta?
Le tabelle live delta usano la sintassi dichiarativa per definire e gestire la distribuzione DDL, DML e dell'infrastruttura. Le tabelle live delta usano il concetto di "schema virtuale" durante la pianificazione e l'esecuzione della logica. Le tabelle Live Delta possono interagire con altri database nell'ambiente Databricks e le tabelle Live Delta possono pubblicare e rendere persistenti le tabelle per l'esecuzione di query altrove specificando un database di destinazione nelle impostazioni di configurazione della pipeline.
Tutte le tabelle create nelle tabelle Live Delta sono tabelle Delta. Quando si usa il catalogo Unity con tabelle live Delta, tutte le tabelle sono tabelle gestite da Catalogo Unity. Se Il catalogo unity non è attivo, le tabelle possono essere dichiarate come tabelle gestite o non gestite.
Anche se le viste possono essere dichiarate in tabelle live Delta, queste viste devono essere considerate come viste temporanee con ambito della pipeline. Le tabelle temporanee nelle tabelle live Delta sono un concetto univoco: queste tabelle salvano i dati nell'archiviazione, ma non pubblicano i dati nel database di destinazione.
Alcune operazioni, ad esempio APPLY CHANGES INTO, registreranno sia una tabella che una vista nel database. Il nome della tabella inizierà con un carattere di sottolineatura (_) e la vista avrà il nome della tabella dichiarato come destinazione dell'operazione APPLY CHANGES INTO . La vista esegue una query sulla tabella nascosta corrispondente per materializzare i risultati.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per