API del modello di Databricks Foundation
Questo articolo offre una panoramica delle API del modello di base in Azure Databricks. Include i requisiti per l'uso, i modelli supportati e le limitazioni.
Che cosa sono le API modello di Databricks Foundation?
Databricks Model Serving supporta ora le API del modello di base che consentono di accedere ai modelli aperti all'avanguardia ed eseguire query su modelli aperti all'avanguardia da un endpoint di servizio. Con le API del modello Di base, è possibile creare applicazioni in modo rapido e semplice che sfruttano un modello di intelligenza artificiale generativa di alta qualità senza gestire la distribuzione del proprio modello.
Le API del modello di base sono disponibili in due modalità di determinazione dei prezzi:
- Pagamento in base al token: questo è il modo più semplice per iniziare ad accedere ai modelli di base in Databricks ed è consigliato per iniziare il percorso con le API del modello di base. Questa modalità non è progettata per applicazioni a velocità effettiva elevata o carichi di lavoro di produzione con prestazioni elevate.
- Velocità effettiva con provisioning: questa modalità è consigliata per tutti i carichi di lavoro di produzione, in particolare per quelli che richiedono velocità effettiva elevata, garanzie di prestazioni, modelli ottimizzati o requisiti di sicurezza aggiuntivi. Gli endpoint di velocità effettiva con provisioning sono disponibili con certificazioni di conformità come HIPAA.
Per indicazioni su come usare queste due modalità e i modelli supportati, vedere Usare le API del modello foundation.
Usando le API del modello di base è possibile:
- Eseguire una query su un LLM generalizzato per verificare la validità di un progetto prima di investire più risorse.
- Eseguire query su un LLM generalizzato per creare un modello di verifica rapido per un'applicazione basata su LLM prima di investire nel training e distribuire un modello personalizzato.
- Usare un modello di base, insieme a un database vettoriale, per creare un chatbot usando la generazione aumentata di recupero (RAG).
- Sostituire i modelli proprietari con alternative aperte per ottimizzare i costi e le prestazioni.
- Confrontare in modo efficiente i moduli APM per vedere qual è il candidato migliore per il caso d'uso o scambiare un modello di produzione con un modello di produzione con prestazioni migliori.
- Creare un'applicazione LLM per lo sviluppo o la produzione oltre a una soluzione LLM scalabile e supportata dal contratto di servizio che può supportare i picchi di traffico di produzione.
Requisiti
- Token API di Databricks per autenticare le richieste di endpoint.
- Calcolo serverless (per i modelli di velocità effettiva con provisioning).
- Un'area di lavoro in un'area supportata:
- Aree con pagamento in base al token.
- Aree elaborate con provisioning.
Nota
Per i carichi di lavoro con provisioning della velocità effettiva che usano il modello di base DBRX, vedere Limiti delle API del modello di base per la disponibilità dell'area.
Usare le API del modello Foundation
Sono disponibili più opzioni per l'uso delle API Foundation Model.
Le API sono compatibili con OpenAI, quindi è anche possibile usare il client OpenAI per l'esecuzione di query. È anche possibile usare l'interfaccia utente, le API Python per i modelli di base, MLflow Deployments SDK o l'API REST per l'esecuzione di query sui modelli supportati. Databricks consiglia di usare MLflow Deployments SDK o l'API REST per interazioni estese e l'interfaccia utente per provare la funzionalità.
Per esempi di assegnazione dei punteggi, vedere Eseguire query sui modelli di base.
API modello di base con pagamento in base al token
Importante
Questa funzionalità è disponibile in anteprima pubblica.
I modelli con pagamento in base al token sono accessibili nell'area di lavoro di Azure Databricks e sono consigliati per iniziare. Per accedervi nell'area di lavoro, passare alla scheda Serve nella barra laterale sinistra. Le API del modello di base si trovano nella parte superiore della visualizzazione elenco Endpoint.
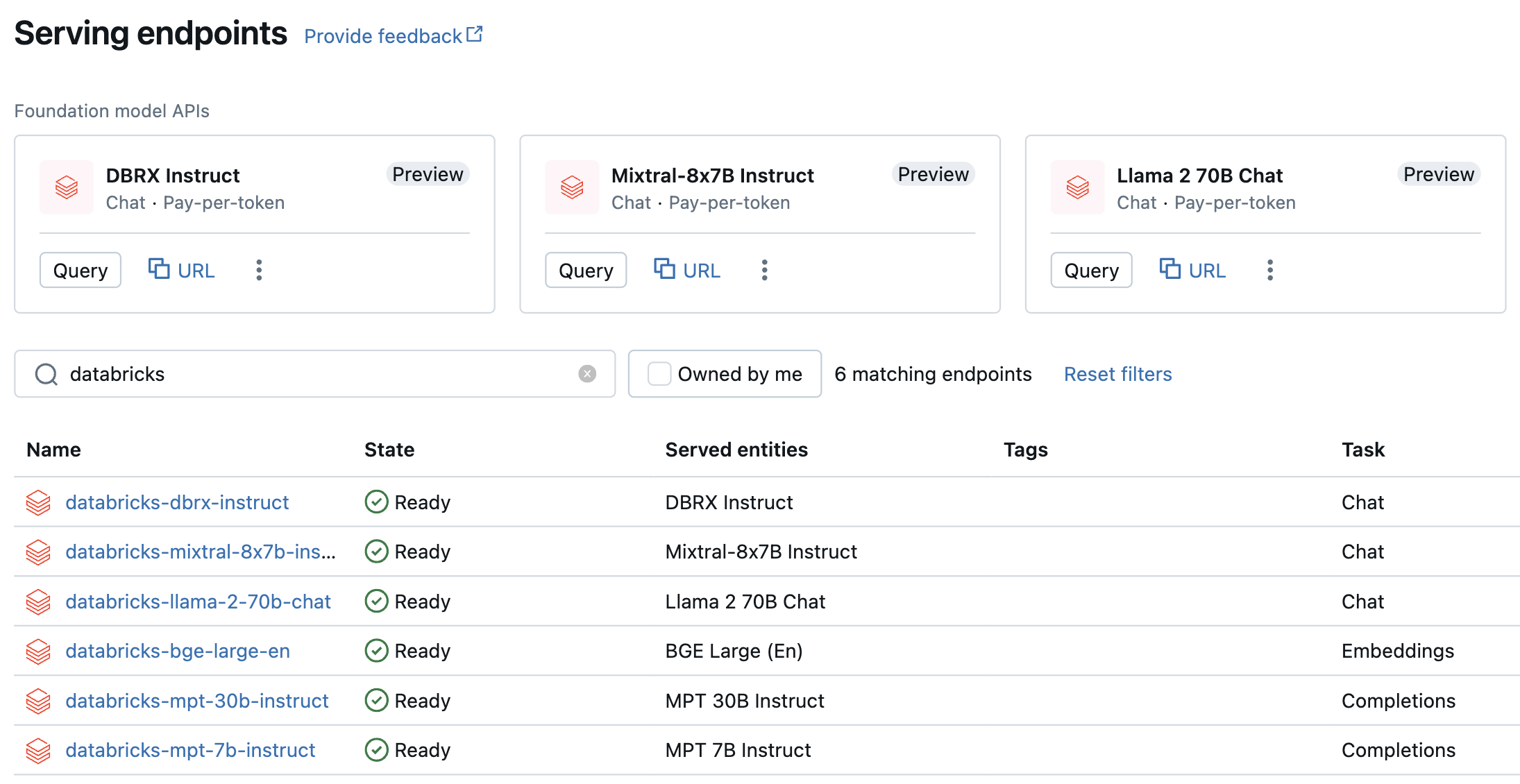
La tabella seguente riepiloga i modelli supportati per il pagamento per token. Per altre informazioni sul modello, vedere Modelli supportati per il pagamento per token .
Se si vuole testare e chattare con questi modelli, è possibile farlo usando ai Playground. Vedere Chat with supported LLMs using AI Playground (Chat with SUPPORTED LLMs using AI Playground).
| Modello | Tipo di attività | Endpoint |
|---|---|---|
| DBRX Instruct | Chat | databricks-dbrx-instruct |
| Meta-Llama-3-70B-Instruct | Chat | databricks-meta-llama-3-70b-instruct |
| Meta-Llama-2-70B-Chat | Chat | databricks-llama-2-70b-chat |
| Istruzioni mixtral-8x7B | Chat | databricks-mixtral-8x7b-instruct |
| Istruzioni MPT 7B | Completion | databricks-mpt-7b-instruct |
| Istruzioni MPT 30B | Completion | databricks-mpt-30b-instruct |
| BGE Large (inglese) | Incorporamento | databricks-bge-large-en |
- Per indicazioni su come eseguire query sulle API del modello di base, vedere Modelli di base delle query.
- Per i parametri e la sintassi necessari, vedere Informazioni di riferimento sulle API REST del modello di Base.
API del modello Di base per la velocità effettiva con provisioning
La velocità effettiva con provisioning è disponibile a livello generale e Databricks consiglia la velocità effettiva con provisioning per i carichi di lavoro di produzione. La velocità effettiva con provisioning offre endpoint con inferenza ottimizzata per i carichi di lavoro del modello di base che richiedono garanzie di prestazioni. Vedere Provisioned throughput Foundation Model APIs (API del modello di base per la velocità effettiva con provisioning) per una guida dettagliata su come distribuire le API del modello foundation in modalità di cui è stato effettuato il provisioning in tutta la modalità.
Il supporto della velocità effettiva con provisioning include:
- Modelli di base di tutte le dimensioni, ad esempio DBRX Base. È possibile accedere ai modelli di base usando Databricks Marketplace oppure è possibile scaricarli da Hugging Face o da un'altra origine esterna e registrarli nel catalogo unity. Quest'ultimo approccio funziona con qualsiasi variante ottimizzata dei modelli supportati, indipendentemente dal metodo di ottimizzazione impiegato.
- Varianti ottimizzate dei modelli di base, ad esempio LlamaGuard-7B. Sono inclusi i modelli ottimizzati per i dati proprietari.
- Pesi e tokenizzatori completamente personalizzati, ad esempio quelli sottoposti a training da zero o continui pre-training o altre varianti usando l'architettura del modello di base (ad esempio CodeLlama, Yi-34B-Chat o SOLAR-10.7B).
La tabella seguente riepiloga le architetture del modello supportate per la velocità effettiva con provisioning.
| Architettura del modello | Tipi di attività | Note |
|---|---|---|
| DBRX | Chat o completamento | Vedere Limiti delle API del modello di base per la disponibilità dell'area. |
| Meta Llama 3 | Chat o completamento | |
| Meta Llama 2 | Chat o completamento | |
| Mistral | Chat o completamento | |
| Mixtral | Chat o completamento | |
| MPT | Chat o completamento | |
| BGE v1.5 (inglese) | Incorporamento |
Limiti
Vedere Model Serving limits and regions (Limiti e aree di gestione dei modelli).