Scritture accelerate di Azure HDInsight per Apache HBase
Questo articolo fornisce informazioni generali sulla funzionalità Scritture accelerate per Apache HBase in Azure HDInsight e su come può essere usata in modo efficace per migliorare le prestazioni di scrittura. Le scritture accelerate usano dischi gestiti SSD Premium di Azure per migliorare le prestazioni del log di write ahead (WAL) di Apache HBase. Per altre informazioni su Apache HBase, vedere Informazioni su Apache HBase in HDInsight.
Panoramica dell'architettura HBase
In HBase una riga è costituita da una o più colonne e identificata da una chiave di riga. Più righe costituiscono una tabella. Le colonne contengono celle, che sono versioni con timestamp del valore in tale colonna. Le colonne vengono raggruppate in famiglie di colonne e tutte le colonne di una famiglia di colonne vengono archiviate insieme nei file di archiviazione denominati HFiles.
Le aree in HBase vengono usate per bilanciare il carico di elaborazione dati. HBase archivia innanzitutto le righe di una tabella in una singola area. Le righe vengono distribuite in più aree man mano che aumenta la quantità di dati nella tabella. I server di area possono gestire le richieste per più aree.
Write Ahead Log per Apache HBase
HBase scrive prima gli aggiornamenti dei dati in un tipo di log di commit denominato write ahead log (WAL). Dopo aver archiviato l'aggiornamento nel wal, viene scritto nel MemStore in memoria. Quando i dati in memoria raggiungono la capacità massima, viene scritto su disco come .HFile
Se un oggetto RegionServer si arresta in modo anomalo o non è più disponibile prima dello scaricamento del MemStore, è possibile usare il log write ahead per riprodurre gli aggiornamenti. Senza wal, se un elemento RegionServer si arresta in modo anomalo prima di scaricare gli aggiornamenti a un HFile, tutti gli aggiornamenti andranno persi.
Funzionalità Di scrittura accelerata in Azure HDInsight per Apache HBase
La funzionalità Scritture accelerate risolve il problema delle latenze di scrittura più elevate causate dall'uso dei log write-ahead presenti nell'archiviazione cloud. La funzionalità Scritture accelerate per i cluster Apache HBase di HDInsight collega dischi gestiti ssd Premium a ogni RegionServer (nodo di lavoro). I log write-ahead vengono quindi scritti nel file system Hadoop (HDFS) montato in questi dischi gestiti Premium anziché nell'archiviazione cloud. I dischi gestiti Premium usano dischi SSD (Solid-State Disks) e offrono prestazioni di I/O eccellenti con tolleranza di errore. A differenza dei dischi non gestiti, se un'unità di archiviazione diventa inattiva, non influirà su altre unità di archiviazione nello stesso set di disponibilità. Di conseguenza, i dischi gestiti offrono bassa latenza di scrittura e una migliore resilienza per le applicazioni. Per altre informazioni sui dischi gestiti di Azure, vedere Introduzione ai dischi gestiti di Azure.
Come abilitare le scritture accelerate per HBase in HDInsight
Per creare un nuovo cluster HBase con la funzionalità Scritture accelerate, seguire la procedura descritta in Configurare i cluster in HDInsight. Nella scheda Informazioni di base selezionare il tipo di cluster come HBase, specificare una versione del componente e quindi fare clic sulla casella di controllo accanto a Abilita scritture con accelerazione HBase. Continuare quindi con i passaggi rimanenti per la creazione del cluster.
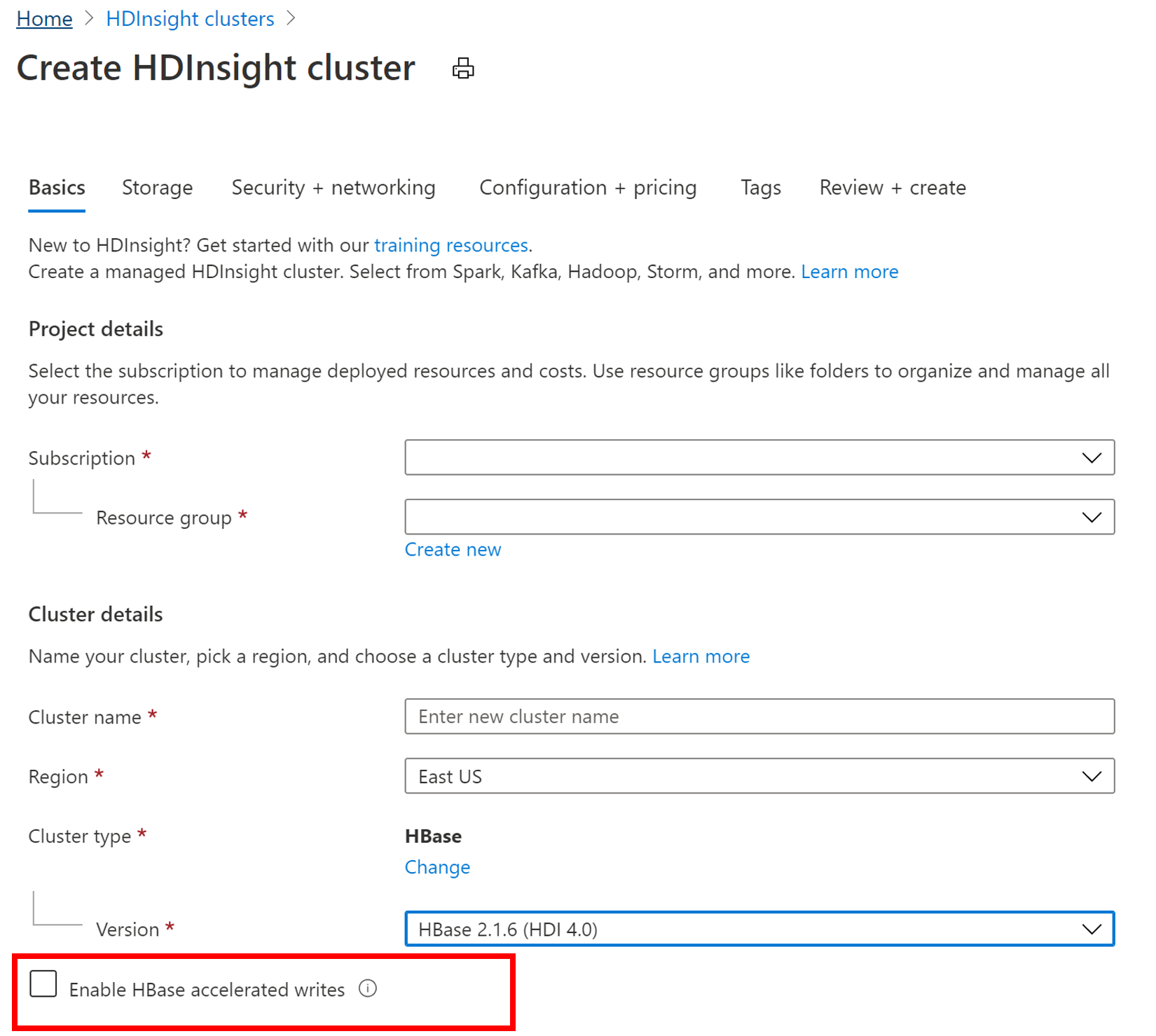
Verificare che la funzionalità Scritture accelerate sia stata abilitata
È possibile usare il portale di Azure per verificare se la funzionalità Scritture accelerate è abilitata in un cluster HBA edizione Standard.
- Cercare il cluster HBA edizione Standard nel portale di Azure.
- Selezionare il pannello Dimensioni cluster.
- Verranno visualizzati i dischi Premium per nodo di lavoro.
Ridimensionamento di cluster HBA edizione Standard
Per mantenere la durabilità dei dati, creare un cluster con almeno tre nodi di lavoro. Dopo la creazione, non è possibile ridurre il cluster a meno di tre nodi di lavoro.
Scaricare o disabilitare le tabelle HBase prima di eliminare il cluster, in modo da non perdere i dati del log write-ahead.
flush 'mytable'
disable 'mytable'
Seguire i passaggi simili quando si esegue il ridimensionamento del cluster: scaricare le tabelle e disabilitare le tabelle per arrestare i dati in ingresso. Non è possibile ridurre il cluster a meno di tre nodi.
Seguendo questa procedura si garantisce una riduzione corretta del numero di istanze ed evitare la possibilità di un nodo name in modalità provvisoria a causa di file con replica non replicata o temporanea.
Se il nodo dei nomi passa alla modalità provvisoria dopo una riduzione delle prestazioni, usare i comandi hdfs per replicare nuovamente i blocchi sotto replicati e ottenere hdfs dalla modalità provvisoria. Questa replica di nuovo consentirà di riavviare correttamente HBase.
Passaggi successivi
- Documentazione ufficiale di Apache HBase sulla funzionalità Write Ahead Log
- Per aggiornare il cluster Apache HBase di HDInsight per l'uso di scritture accelerate, vedere Eseguire la migrazione di un cluster Apache HBase a una nuova versione.