Che cos'è Azure HDInsight?
Azure HDInsight è un servizio di analisi open source, ad ampio spettro e gestito nel cloud, rivolto alle aziende. Con HDInsight è possibile usare framework open source, ad esempio Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop e altro ancora, nell'ambiente Azure.
Informazioni su Azure HDInsight e sullo stack di tecnologie Hadoop
Azure HDInsight è una piattaforma cluster gestita che semplifica l'esecuzione di framework Big Data come Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop e altri nell'ambiente Azure. È progettato per gestire grandi volumi di dati con velocità e efficienza elevate.
Perché usare Azure HDInsight?
| Funzionalità | Descrizione |
|---|---|
| Cloud nativo | Azure HDInsight consente di creare cluster ottimizzati per Spark, Interactive Query (LLAP), Kafka, HBase e Hadoop in Azure. HDInsight fornisce anche un contratto di servizio end-to-end per tutti i carichi di lavoro di produzione. |
| Costi contenuti e scalabilità | HDInsight consente di aumentare o ridurre i carichi di lavoro. È possibile ridurre i costi creando cluster su richiesta e pagando solo per ciò che si usa. È anche possibile compilare pipeline di dati per rendere operativi i processi. Le risorse di calcolo e di archiviazione disaccoppiate offrono prestazioni e flessibilità migliori. |
| Sicurezza e conformità | HDInsight consente di proteggere gli asset di dati aziendali con Azure Rete virtuale, crittografia e integrazione con Microsoft Entra ID. HDInsight soddisfa anche i più diffusi standard di conformità del settore e governativi. |
| Monitoraggio | Azure HDInsight si integra con i log di Monitoraggio di Azure per fornire una singola interfaccia che consente di monitorare tutti i cluster. |
| Disponibilità globale | HDInsight è disponibile in più aree rispetto a qualsiasi altra offerta di analisi di Big Data . Azure HDInsight è anche disponibile in Azure per enti pubblici, Cina e Germania per soddisfare le esigenze aziendali nelle principali aree sovrane. |
| Produttività | Azure HDInsight consente di usare strumenti di produttività avanzati per Hadoop e Spark con gli ambienti di sviluppo più diffusi. Questi ambienti di sviluppo includono il supporto di Visual Studio, VS Code, Eclipse e IntelliJ per Scala, Python, Java e .NET. |
| Estendibilità | È possibile estendere i cluster HDInsight con componenti installati (Hue, Presto e così via) usando azioni script, aggiungendo nodi perimetrali o integrando altre applicazioni certificate per Big Data . HDInsight consente un'integrazione senza problemi con le più diffuse soluzioni Big Data tramite una distribuzione con un clic. |
What is big data? (Che cosa sono i Big Data?)
I Big Data vengono raccolti in volumi sempre più elevati, a velocità crescenti e nella gamma di formati più ampia mai resa disponibile. Può trattarsi di dati cronologici (ovvero archiviati) o in tempo reale (ovvero trasmessi in streaming dall'origine). Per altre informazioni sui caso d'uso più comuni per i Big Data, vedere Scenari per l'uso di HDInsight.
Tipi di cluster in HDInsight
HDInsight include tipi di cluster specifici e funzionalità di personalizzazione dei cluster, ad esempio la possibilità di aggiungere componenti, utilità e linguaggi. HDInsight offre i seguenti tipi di cluster:
| Tipo di cluster | Descrizione | Operazioni preliminari |
|---|---|---|
| Apache Hadoop | un framework che usa HDFS, la gestione risorse YARN e un semplice modello di programmazione MapReduce per elaborare e analizzare i dati batch in parallelo. | Creare un cluster Apache Hadoop |
| Apache Spark | è un framework open source di elaborazione parallela che supporta l'elaborazione in memoria per migliorare le prestazioni di applicazioni analitiche di Big Data. Vedere Informazioni su Apache Spark in HDInsight. | Creare un cluster Apache Spark |
| Apache HBase | un database NoSQL basato su Hadoop che fornisce accesso casuale e coerenza assoluta per quantità elevate di dati non strutturati e semistrutturati. Può gestire potenzialmente milioni di righe e colonne. Vedere Informazioni su HBase in HDInsight | Creare un cluster Apache HBase |
| Apache Interactive Query | Caching in memoria per query Hive interattive e più rapide. Vedere Usare Interactive Query in HDInsight. | Creare un cluster Interactive Query |
| Apache Kafka | Una piattaforma open source viene usata per la compilazione di pipeline e applicazioni di dati di streaming. Kafka fornisce inoltre funzionalità di code di messaggi che consentono di pubblicare e sottoscrivere i flussi di dati. Vedere Introduction to Apache Kafka on HDInsight (Introduzione ad Apache Kafka in HDInsight). | Creare un cluster Apache Kafka |
Scenari per l'uso di HDInsight
Azure HDInsight può essere usato per diversi scenari nell'elaborazione di Big Data . Possono essere dati cronologici (dati già raccolti e archiviati) o dati in tempo reale (dati trasmessi direttamente dall'origine). Gli scenari per l'elaborazione di tali dati possono essere riepilogati nelle categorie seguenti:
Elaborazione batch (ETL)
L'estrazione, trasformazione e caricamento (ETL) è un processo in cui dati strutturati o non strutturati vengono estratti da origini dati eterogenei. I dati vengono quindi trasformati in un formato strutturato e caricati in un archivio dati. È possibile usare i dati trasformati per data science o data warehousing.
Data warehousing
È possibile usare HDInsight per eseguire query interattive nell'ordine di grandezza di petabyte su dati strutturati o non strutturati in qualsiasi formato. È anche possibile compilare modelli che le connettono a strumenti di business intelligence.
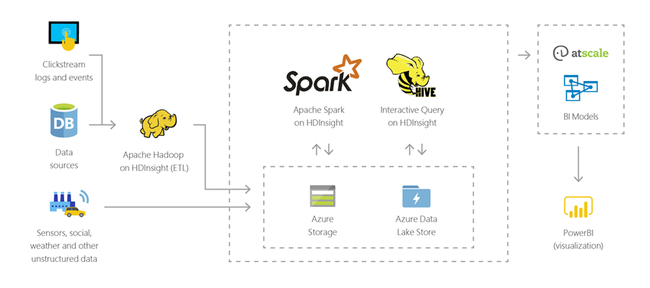
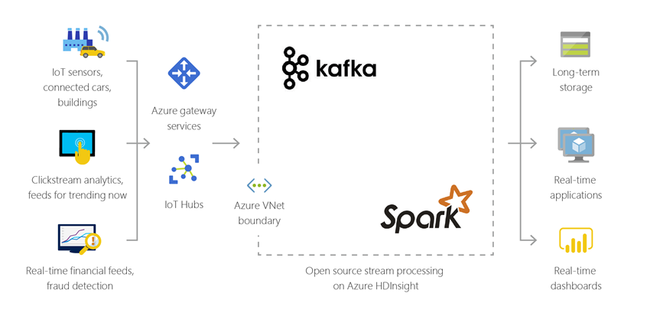
internet delle cose (IoT)
È possibile usare HDInsight per elaborare i dati di streaming ricevuti in tempo reale da diversi tipi di dispositivi. Per altre informazioni, leggere questo post di blog di Azure che annuncia l'anteprima pubblica di Apache Kafka su HDInsight con Azure Managed Disks.
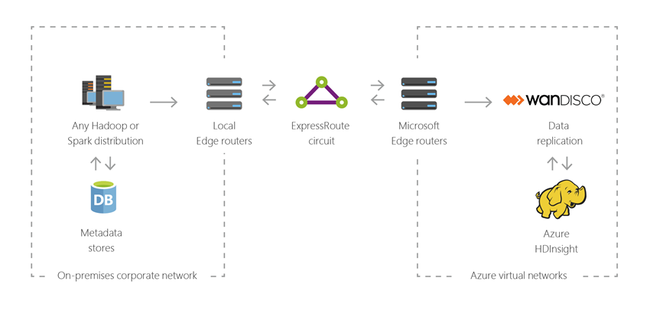
Ibrido
È possibile usare HDInsight per estendere l'infrastruttura Big Data locale esistente ad Azure per applicare le funzionalità di analisi avanzate del cloud.
Componenti open source in HDInsight
Azure HDInsight consente di creare cluster con framework open source come Spark, Hive, LLAP, Kafka, Hadoop e HBase. Per impostazione predefinita, questi cluster includono vari componenti open source, ad esempio Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie e Apache ZooKeeper.
Linguaggi di programmazione in HDInsight
I cluster di HDInsight, tra cui Spark, HBase, Kafka, Hadoop e altri, supportano molti linguaggi di programmazione. Alcuni linguaggi di programmazione non sono installati per impostazione predefinita. Per le librerie, i moduli o i pacchetti non installati per impostazione predefinita, usare un'azione script per installarli.
| Linguaggio di programmazione | Informazioni |
|---|---|
| Supporto per i linguaggi di programmazione predefiniti | Per impostazione predefinita, i cluster HDInsight supportano:
|
| Linguaggi per macchine virtuali Java | Molti linguaggi diversi da Java possono essere eseguiti in una macchina virtuale Java. Tuttavia, se si eseguono alcuni di questi linguaggi, potrebbe essere necessario installare più componenti nel cluster. I linguaggi basati su JVM seguenti sono supportati nei cluster HDInsight:
|
| Linguaggi specifici di Hadoop | I cluster HDInsight supportano i linguaggi seguenti specifici dello stack di tecnologie Hadoop:
|
Strumenti di sviluppo per HDInsight
È possibile usare gli strumenti di sviluppo di HDInsight, inclusi IntelliJ, Eclipse, Visual Studio Code e Visual Studio, per creare e inviare processi e query sui dati di HDInsight con una semplice integrazione con Azure.
- Toolkit di Azure per IntelliJ 10
- Toolkit di Azure per Eclipse 6
- Strumenti di Azure HDInsight per VS Code 13
- Strumenti Azure Data Lake per Visual Studio 9
Business intelligence in HDInsight
Gli strumenti di business intelligence (BI) noti consentono di recuperare, analizzare e creare report di dati integrati con HDInsight usando il componente aggiuntivo Power Query o Microsoft Hive ODBC Driver:
Apache Spark BI usando gli strumenti di visualizzazione di dati con Azure HDInsight
Visualizzare i dati Apache Hive con Microsoft Power BI in Azure HDInsight
Visualize Interactive Query Hive data with Power BI in Azure HDInsight (Visualizzare i dati Hive di Interactive Query con Power BI in Azure HDInsight)
Connettere Excel a Apache Hadoop mediante Power Query (richiede Windows)
Connettere Excel ad Apache Hadoop con Microsoft Hive ODBC Driver (richiede Windows)
Residenza dei dati nell'area geografica
Spark, Hadoop e LLAP non archivia i dati dei clienti, quindi questi servizi soddisfano automaticamente i requisiti di residenza dei dati nell'area specificati nel Centro protezione.
Kafka e HBase non archiviano i dati dei clienti. Questi dati vengono archiviati automaticamente da Kafka e HBase in una singola area, quindi questo servizio soddisfa i requisiti di residenza dei dati nell'area geografica specificati nel Centro protezione.
Gli strumenti di business intelligence (BI) noti consentono di recuperare, analizzare e creare report di dati integrati con HDInsight usando il componente aggiuntivo Power Query o Microsoft Hive ODBC Driver.