Gestire i log per un cluster HDInsight
Un cluster HDInsight produce vari file di log. Apache Hadoop e i servizi correlati, come Apache Spark, generano ad esempio log di esecuzione dei processi dettagliati. La gestione dei file di log è una delle attività che consentono di mantenere integro un cluster HDInsight. Possono anche esistere requisiti normativi per l'archiviazione dei log. A causa del numero e delle dimensioni dei file di log, ottimizzando la memorizzazione e l'archiviazione dei log è possibile semplificare la gestione dei costi dei servizi.
La gestione dei log cluster di HDInsight include la conservazione delle informazioni su tutti gli aspetti dell'ambiente cluster, che comprendono tutti i log dei servizi di Azure associati, la configurazione cluster, le informazioni sull'esecuzione dei processi, eventuali stati di errore e altri dati necessari.
I passaggi tipici della gestione dei log di HDInsight sono:
- Passaggio 1: Determinare i criteri di conservazione dei log
- Passaggio 2: Gestire i log di configurazione delle versioni dei servizi cluster
- Passaggio 3: Gestire i file di log di esecuzione dei processi cluster
- Passaggio 4: Prevedere le dimensioni e i costi di archiviazione dei volumi di log
- Passaggio 5: Determinare i criteri e i processi di archiviazione dei log
Passaggio 1: Determinare i criteri di conservazione dei log
Il primo passaggio per creare una strategia di gestione dei registri cluster di HDInsight prevede la raccolta di informazioni sugli scenari aziendali e sui requisiti di archiviazione della cronologia di esecuzione dei processi.
Dettagli del cluster
I dettagli dei cluster seguenti sono utili per raccogliere informazioni nell'ambito della strategia di gestione dei log. Raccogliere queste informazioni da tutti i cluster HDInsight creati in un determinato account Azure.
- Nome cluster
- Area del cluster e zona di disponibilità di Azure
- Stato del cluster, inclusi i dettagli dell'ultima modifica dello stato
- Tipo e numero di istanze di HDInsight specificate per i nodi master, principali e attività
È possibile ottenere la maggior parte di queste informazioni generali usando il portale di Azure. In alternativa, è possibile usare l'interfaccia della riga di comando di Azure per ottenere informazioni sui cluster HDInsight:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Per visualizzare queste informazioni, è anche possibile usare PowerShell. Per altre informazioni, vedere Gestire cluster Apache Hadoop in HDInsight usando Azure PowerShell.
Informazioni sui carichi di lavoro in esecuzione nei cluster
È importante conoscere i tipi di carichi di lavoro in esecuzione nei cluster HDInsight per progettare strategie di registrazione appropriate per ogni tipo.
- I carichi di lavoro sono sperimentali (ad esempio, sviluppo o test) o di qualità idonea ad ambienti di produzione?
- Con quale frequenza vengono in genere eseguiti i carichi di lavoro di qualità idonea ad ambienti di produzione?
- I carichi di lavoro sono a elevato utilizzo di risorse e/o a esecuzione prolungata?
- I carichi di lavoro usano un set complesso di servizi Hadoop per cui vengono generati più tipi di log?
- Ai carichi di lavoro sono associati requisiti normativi di derivazione dell'esecuzione?
Modelli e procedure di conservazione dei log di esempio
Prendere in considerazione la possibilità di gestire la verifica della derivazione dei dati aggiungendo un identificatore a ogni voce di log o con altre tecniche. Ciò consente di risalire all'origine dei dati e dell'operazione e di seguire i dati attraverso ogni fase per conoscerne la coerenza e la validità.
Considerare come sia possibile raccogliere i log dal cluster o da più di un cluster e collazionarli, ad esempio a scopo di controllo, monitoraggio, pianificazione e creazione di avvisi. È possibile usare una soluzione personalizzata per accedere e scaricare regolarmente i file di log e combinarli e analizzarli per fornire una visualizzazione del dashboard. È anche possibile aggiungere altre funzionalità per l'invio di avvisi per il rilevamento di errori o sicurezza. È possibile compilare queste utilità con PowerShell, gli SDK di HDInsight o il codice che accede al modello di distribuzione classica di Azure.
Stabilire se una soluzione o un servizio di monitoraggio possa essere vantaggioso. In Microsoft System Center è disponibile un Management Pack per HDInsight. Per raccogliere e centralizzare i log è anche possibile usare strumenti di terze parti, ad esempio Apache Chukwa e Ganglia. Molte aziende offrono servizi per monitorare le soluzioni Big Data basate su Hadoop, ad esempio,
Centerity, Compuware APM, Sematext SPM e Zettaset Orchestrator.
Passaggio 2: Gestire le versioni del servizio cluster e visualizzare i log
Un tipico cluster HDInsight usa diversi servizi e pacchetti software open source (ad esempio, Apache HBase, Apache Spark e così via). Per alcuni carichi di lavoro, ad esempio quelli di bioinformatica, potrebbe essere necessario conservare la cronologia dei log di configurazione dei servizi oltre ai log di esecuzione dei processi.
Visualizzare le impostazioni di configurazione cluster con l'interfaccia utente di Ambari
Apache Ambari semplifica la gestione, la configurazione e il monitoraggio di un cluster HDInsight grazie a un'interfaccia utente Web e a un'API REST. Ambari è incluso nei cluster HDInsight basati su Linux. Selezionare il riquadro Dashboard cluster nella pagina portale di Azure HDInsight per aprire la pagina di collegamento Dashboard cluster. Selezionare quindi il riquadro Dashboard cluster HDInsight per aprire l'interfaccia utente di Ambari. Vengono richieste le credenziali di accesso del cluster.
Per aprire un elenco di visualizzazioni di servizi, selezionare il riquadro Visualizzazioni di Ambari nella pagina del portale di Azure per HDInsight. Questo elenco varia a seconda delle librerie installate. È ad esempio possibile visualizzare YARN Queue Manager, Hive View e Tez View. Selezionare un collegamento al servizio per visualizzare le informazioni sulla configurazione e sul servizio. La pagina Stack and Version (Stack e versione) dell'interfaccia utente di Ambari contiene informazioni sulla configurazione dei servizi cluster e la cronologia delle versioni dei servizi. Per passare a questa sezione dell'interfaccia utente di Ambari, scegliere Stacks and Versions (Stack e versioni) dal menu Admin (Amministratore). Selezionare la scheda Versions (Versioni) per visualizzare le informazioni sulle versioni dei servizi.
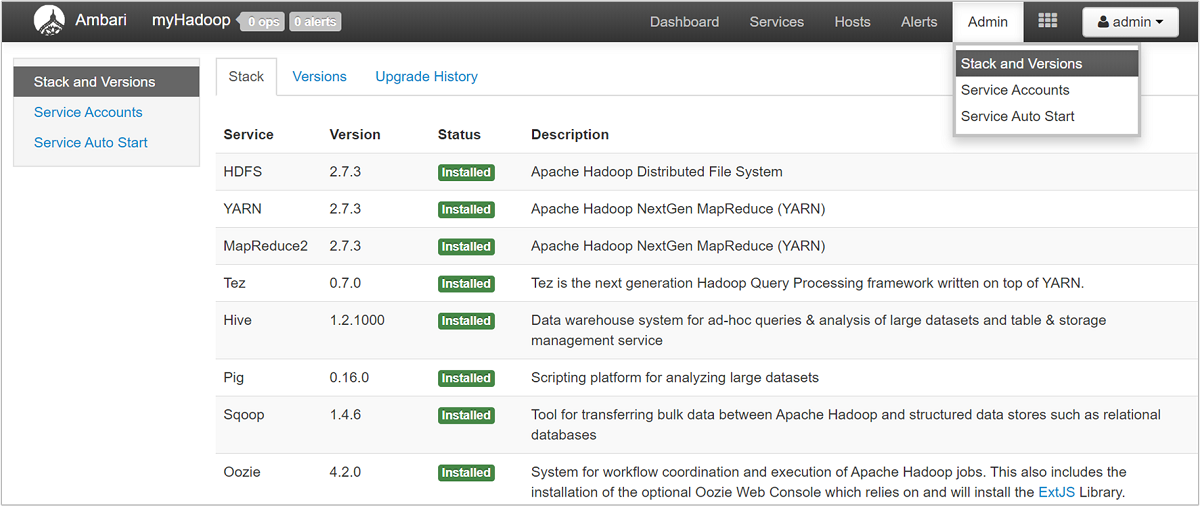
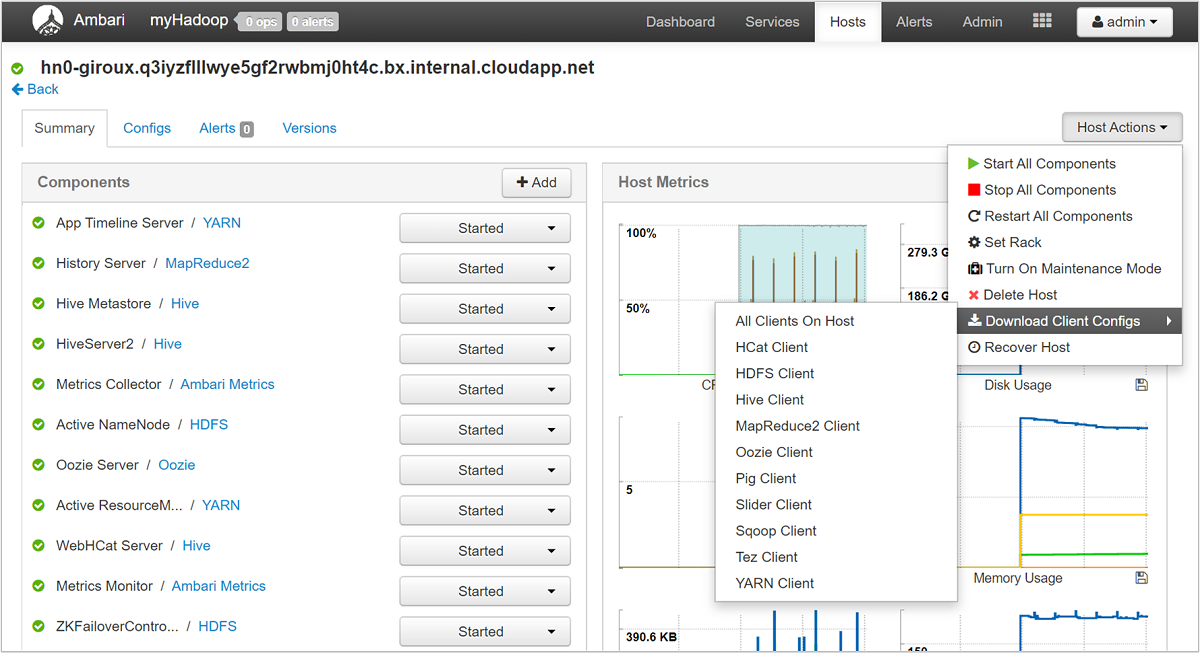
Usando l'interfaccia utente di Ambari, è possibile scaricare la configurazione per qualsiasi servizio (o per tutti) in esecuzione in un determinato host (o nodo) del cluster. Scegliere il collegamento dell'host a cui si è interessati dal menu Hosts (Host). Nella pagina di tale host selezionare il pulsante Host Actions (Azioni host) e quindi Download Client Configs (Scarica configurazioni client).
Visualizzare i log delle azioni script
Le azioni script di HDInsight eseguono script in un cluster, manualmente o se specificato. Ad esempio, le azioni script possono essere usate per installare altri software nel cluster o per modificare le impostazioni di configurazione dai valori predefiniti. I log delle azioni script forniscono informazioni sugli errori verificatisi durante la configurazione del cluster e anche sulle modifiche delle impostazioni di configurazione che possono avere effetto sulle prestazioni e sulla disponibilità del cluster. Per visualizzare lo stato di un'azione script, selezionare il pulsante ops (operazioni) nell'interfaccia utente di Ambari o accedere ai log di stato nell'account di archiviazione predefinito. I log di archiviazione sono disponibili in /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE.
Visualizzare i log di stato degli avvisi di Ambari
Apache Ambari scrive le modifiche dello stato degli avvisi in ambari-alerts.log. Il percorso completo è /var/log/ambari-server/ambari-alerts.log. Per abilitare il debug per il log, modificare una proprietà in /etc/ambari-server/conf/log4j.properties. Modifica e quindi immettere # Log alert state changes in da:
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Passaggio 3: Gestire i file di log di esecuzione dei processi cluster
Il passaggio successivo prevede la revisione dei file di log di esecuzione dei processi per i diversi servizi. I servizi possono includere Apache HBase, Apache Spark e molti altri. Un cluster Hadoop produce un numero elevato di log dettagliati, quindi determinare quali log sono utili (e quali non sono) possono richiedere molto tempo. Conoscere il sistema di registrazione è importante per la gestione mirata dei file di log. L'immagine seguente è un file di log di esempio.

Accedere ai file di log di Hadoop
HDInsight archivia i file di log sia nel file system del cluster che in Archiviazione di Azure. È possibile esaminare i file di log nel cluster aprendo una connessione SSH al cluster e esplorando il file system oppure usando il portale di stato yarn hadoop nel server del nodo head remoto. È possibile esaminare i file di log in Archiviazione di Azure usando uno degli strumenti che possono accedere e scaricare dati da Archiviazione di Azure. Esempi sono AzCopy, CloudXplorer e Esplora server di Visual Studio. È anche possibile usare PowerShell e le librerie client di Archiviazione di Azure o gli SDK di Azure .NET per accedere ai dati nell'archivio BLOB di Azure.
Hadoop esegue i processi come tentativi di attività in diversi nodi del cluster. HDInsight può avviare tentativi di attività speculative, terminando tutti gli altri tentativi di attività che non vengono completati per primi. Viene così generata una significativa attività che viene immediatamente registrata nei file di log del controller, di stderr e di syslog. Vengono inoltre eseguiti simultaneamente più tentativi di attività, ma un file di log può visualizzare i risultati solo in modo lineare.
Log di HDInsight scritti nell'archivio BLOB di Azure
I cluster HDInsight sono configurati per scrivere i log delle attività in un account di archiviazione BLOB di Azure per qualsiasi processo inviato usando i cmdlet di Azure PowerShell o le API per l'invio di processi tramite .NET. Se si inviano i processi tramite SSH al cluster, le informazioni di registrazione di esecuzione vengono archiviate nelle tabelle di Azure, come illustrato nella sezione precedente.
Oltre ai file di log principali generati da HDInsight, anche i servizi installati, ad esempio YARN, generano file di log di esecuzione dei processi. Il numero e il tipo di file di log dipendono dai servizi installati. Servizi comuni sono Apache HBase, Apache Spark e così via. Esaminare i file di log di esecuzione dei processi di ogni servizio per comprendere i file di registrazione completa nel cluster. Ogni servizio ha metodi di registrazione univoci e percorsi univoci per l'archiviazione dei file di log. Come esempio, nella sezione seguente vengono illustrati i dettagli per accedere ai file di log dei servizi più comuni (da YARN).
Log di HDInsight generati da YARN
YARN aggrega i log di tutti i contenitori in un nodo di lavoro e archivia tali log come file di log aggregati per ogni nodo di lavoro. Quando un'applicazione termina, tale log viene archiviato nel file system predefinito. L'applicazione può usare centinaia o migliaia di contenitori, ma i log di tutti i contenitori eseguiti su un singolo nodo di lavoro vengono sempre aggregati in un unico file. Esiste un solo log per nodo di lavoro usato dall'applicazione. La funzione di aggregazione dei log è abilitata per impostazione predefinita nei cluster HDInsight versione 3.0 o successiva. I log aggregati sono disponibili nella risorsa di archiviazione predefinita per il cluster.
/app-logs/<user>/logs/<applicationId>
I log aggregati non sono direttamente leggibili, perché vengono scritti in un TFile formato binario indicizzato dal contenitore. Usare i log YARN ResourceManager o gli strumenti dell'interfaccia della riga di comando per visualizzare questi log come testo normale per applicazioni o contenitori di interesse.
Strumenti dell’interfaccia di riga di comando YARN
Per utilizzare gli strumenti dell'interfaccia della riga di comando YARN, è innanzitutto necessario connettersi al cluster HDInsight tramite SSH. Specificare le informazioni <applicationId>, <user-who-started-the-application>, <containerId> e <worker-node-address> quando si eseguono questi comandi. È possibile visualizzare i log come testo normale con uno dei comandi seguenti:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
Interfaccia utente di YARN Resource Manager
L'interfaccia utente di YARN Resource Manager viene eseguita nel nodo head del cluster ed è accessibile tramite l'interfaccia utente Web di Ambari. Per visualizzare i log di YARN, procedere come segue:
- In un Web browser accedere a
https://CLUSTERNAME.azurehdinsight.net. Sostituire CLUSTERNAME con il nome del cluster HDInsight. - Nell'elenco dei servizi a sinistra selezionare YARN.
- Nell'elenco a discesa Collegamenti rapidi selezionare uno dei nodi head del cluster e quindi selezionare Log di Resource Manager. Viene visualizzato un elenco di collegamenti ai log YARN.
Passaggio 4: Prevedere le dimensioni e i costi di archiviazione dei volumi di log
Dopo avere completato i passaggi precedenti, si è a conoscenza dei tipi e dei volumi di file di log generati dai cluster HDInsight.
Analizzare ora il volume dei dati dei log nelle posizioni di archiviazione chiave per un periodo di tempo. È ad esempio possibile analizzare il volume e la crescita per periodi di 30, 60 e 90 giorni. Registrare queste informazioni in un foglio di calcolo o usare altri strumenti, ad esempio Visual Studio, Azure Storage Explorer o Power Query per Excel. ```
Ora si hanno informazioni sufficienti per creare una strategia di gestione per i log chiave. Usare il foglio di calcolo (o lo strumento scelto) per valutare sia la crescita delle dimensioni dei log che i costi dei servizi di Azure per l'archiviazione dei log in futuro. Prendere in considerazione anche eventuali requisiti di conservazione dei log per il set di log che si sta esaminando. È ora possibile eseguire nuovamente il rollforecast dei costi di archiviazione dei log futuri, dopo aver determinato quali file di log possono essere eliminati (se presenti) e quali log devono essere conservati e archiviati in Archiviazione di Azure meno costosi.
Passaggio 5: Determinare i criteri e i processi di archiviazione dei log
Dopo avere determinato quali file di log possono essere eliminati, è possibile modificare i parametri di registrazione in molti servizi Hadoop per eliminare automaticamente i file di log dopo un periodo di tempo specificato.
Per determinati file di log, è possibile usare un approccio di archiviazione di prezzo inferiore. Per i log attività di Azure Resource Manager, è possibile esplorare questo approccio con il portale di Azure. Configurare l'archiviazione dei log di Resource Manager selezionando il collegamento Log attività nella portale di Azure per l'istanza di HDInsight. Nella parte superiore della pagina di ricerca Log attività scegliere la voce di menu Esporta per aprire il riquadro Esporta log attività. Specificare la sottoscrizione, l'area, se eseguire l'esportazione in un account di archiviazione e per quanti giorni conservare i log. In questo stesso riquadro è anche possibile indicare se eseguire l'esportazione in un hub eventi.
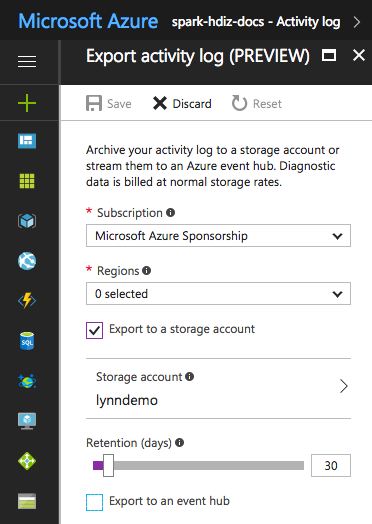
In alternativa, è possibile generare uno script per archiviare i log con PowerShell.
Accesso alle metriche di Archiviazione di Azure
Archiviazione di Azure possono essere configurati per registrare le operazioni di archiviazione e l'accesso. È possibile usare questi log dettagliati per il monitoraggio e la pianificazione della capacità e per il controllo delle richieste di archiviazione. Le informazioni registrate includono i dettagli sulla latenza, che consentono di monitorare e ottimizzare le prestazioni delle soluzioni. È possibile usare .NET SDK per Hadoop per esaminare i file di log generati per il Archiviazione di Azure che contiene i dati per un cluster HDInsight.
Controllare le dimensioni e il numero di indici di backup per i file di log obsoleti
Per controllare le dimensioni e il numero di file di log conservati, impostare le proprietà seguenti di RollingFileAppender:
maxFileSizeè la dimensione critica del file, che viene eseguito il rollback del file. Il valore predefinito è 10 MB.maxBackupIndexspecifica il numero di file di backup da creare. Il valore predefinito è 1.
Altre tecniche di gestione dei log
Per evitare l'esaurimento dello spazio su disco, è possibile usare alcuni strumenti del sistema operativo, ad esempio logrotate , per gestire i file di log. È possibile configurare logrotate per l'esecuzione giornaliera, in cui vengono compressi i file di log e vengono rimossi quelli obsoleti. L'approccio dipende dai requisiti, ad esempio per quanto tempo conservare i file di log nei nodi locali.
È anche possibile verificare se la registrazione DEBUG è abilitata per uno o più servizi, aumentando notevolmente le dimensioni del log di output.
Per raccogliere i log da tutti i nodi in una posizione centrale, è possibile creare un flusso di dati, ad esempio inserendo tutte le voci di log in Solr.