Migliorare le prestazioni dei carichi di lavoro apache Spark con Cache I/O di Azure HDInsight
Nota
- La cache di I/O è supportata fino a Spark 2.3 e non sarà supportata in Spark 2.4 (HDInsight 4.0) e Spark 3.1.2 (HDInsight 5.0)
IO Cache è un servizio di memorizzazione dei dati nella cache per Azure HDInsight che consente di migliorare le prestazioni dei processi di Apache Spark. IO Cache funziona anche con i carichi di lavoro Apache TEZ e Apache Hive, che possono essere eseguiti nei cluster Apache Spark. IO Cache usa un componente open-source per la memorizzazione nella cache denominato RubiX. RubiX è una cache del disco locale da usare con i motori di analisi dei Big Data che accedono ai dati da sistemi di archiviazione cloud. RubiX è unico tra i sistemi di memorizzazione nella cache perché usa unità SSD (Solid State Drive) anziché riservare memoria operativa per la memorizzazione nella cache. Il servizio IO Cache avvia e gestisce i server di metadati RubiX in ogni nodo del ruolo di lavoro del cluster. Configura anche tutti i servizi del cluster per l'uso trasparente della cache RubiX.
Quasi tutte le unità SSD offrono più di 1 GB al secondo di larghezza di banda. Questa larghezza di banda, integrata dalla cache dei file in-memory del sistema operativo, è sufficiente per caricare i motori di elaborazione di calcolo dei Big Data, ad esempio Apache Spark. La memoria operativa viene lasciata disponibile per consentire ad Apache Spark di elaborare le attività altamente dipendenti dalla memoria, ad esempio le riproduzioni con sequenza casuale. Grazie all'uso esclusivo della memoria operativa, Apache Spark raggiunge un livello ottimale di utilizzo delle risorse.
Nota
IO Cache usa attualmente RubiX come componente per la memorizzazione nella cache, ma potrebbero verificarsi delle variazioni nelle future versioni del servizio. Usare le interfacce di IO Cache e non accettare dipendenze direttamente nell'implementazione RubiX. La cache di I/O è supportata solo con Archiviazione BLOB di Azure.
Vantaggi di Azure HDInsight IO Cache
L'uso di IO Cache assicura un aumento delle prestazioni dei processi che leggono dati da Archiviazione BLOB di Azure.
Per assistere ad aumenti delle prestazioni con l'uso di IO Cache, non occorre apportare modifiche ai processi Spark. Quando IO Cache è disabilitato, il codice Spark seguente leggerà i dati in remoto da Archiviazione BLOB di Azure: spark.read.load('wasbs:///myfolder/data.parquet').count(). Quando IO Cache è attivato, la stessa riga di codice determina l'esecuzione di un'operazione di lettura memorizzata nella cache tramite IO Cache. Alle letture successive, i dati vengono letti in locale dall'unità SSD. I nodi del ruolo di lavoro nel cluster HDInsight sono dotati di unità SSD dedicate e collegate in locale. HDInsight IO Cache usa queste unità SSD locali per la memorizzazione nella cache, in modo da offrire un livello di latenza minimo e larghezza di banda massima.
Introduzione
Nell'anteprima Azure HDInsight IO Cache è disattivato per impostazione predefinita. IO Cache è disponibile nei cluster Spark di Azure HDInsight 3.6 e versioni successive che eseguono Apache Spark 2.3. Per attivare I/O Cache in HDInsight 4.0, seguire questa procedura:
In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.netdoveCLUSTERNAMEè il nome del cluster.Selezionare il servizio IO Cache a sinistra.
Selezionare Azioni (azioni del servizio in HDI 3.6) e attiva.
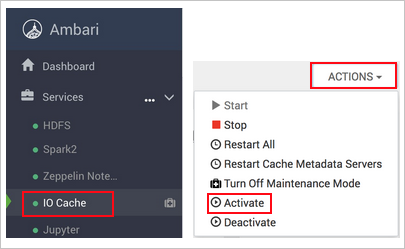
Confermare il riavvio di tutti i servizi interessati nel cluster.
Nota
Anche se dall'indicatore di stato risulta attivato, IO Cache non è effettivamente abilitato fino a quando non vengono riavviati gli altri servizi interessati.
Risoluzione dei problemi
È possibile che vengano visualizzati errori di spazio su disco durante l'esecuzione di processi Spark dopo l'abilitazione di IO Cache. Questi errori si verificano perché Spark usa anche il disco locale per archiviare i dati durante le operazioni di riproduzione casuale. Dopo che IO Cache è stato abilitato e lo spazio di archiviazione di Spark viene ridotto, Spark può esaurire lo spazio disponibile sulle unità SSD. La quantità di spazio usata da IO Cache assume come valore predefinito la metà dello spazio totale disponibile sulle unità SSD. L'utilizzo di spazio su disco per IO Cache può essere configurato in Ambari. Se si verificano errori di spazio su disco, ridurre la quantità di spazio sulle unità SSD per IO Cache e riavviare il servizio. Per modificare lo spazio impostato per IO Cache, seguire questa procedura:
In Apache Ambari selezionare il servizio HDFS a sinistra.
Selezionare le schede Configs (Configurazioni) e Advanced (Avanzate).
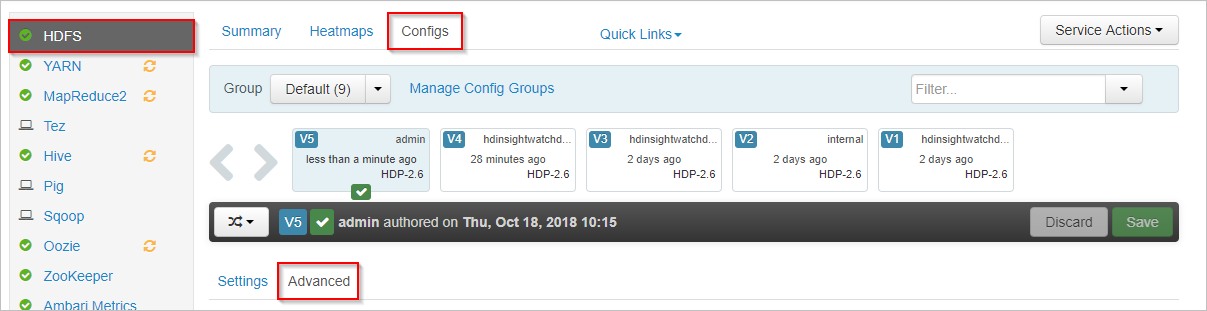
Scorrere verso il basso ed espandere l'area Custom core-site (Impostazioni core-site personalizzate).
Individuare la proprietà hadoop.cache.data.fullness.percentage.
Modificare il valore nella casella.

Selezionare Save (Salva) in alto a destra.
Selezionare Restart (Riavvia)>Restart All Affected (Riavvia tutti gli elementi interessati).

Selezionare Confirm Restart All (Conferma riavvio di tutti gli elementi).
Se non funziona, disabilitare I/O Cache.
Passaggi successivi
Altre informazioni su IO Cache, inclusi i benchmark delle prestazioni illustrati in questo post di blog: Apache Spark jobs gain up to 9x speed up with HDInsight IO Cache (Processi di Apache Spark fino a 9 volte più veloci con HDInsight IO Cache)