Eseguire il training del componente modello
Questo articolo descrive un componente nella finestra di progettazione di Azure Machine Learning.
Usare questo componente per eseguire il training di un modello di classificazione o regressione. Il training viene eseguito dopo aver definito un modello e impostato i relativi parametri e richiede i dati con tag. È anche possibile usare Train Model per ripetere il training di un modello esistente con nuovi dati.
Funzionamento del processo di training
In Azure Machine Learning la creazione e l'uso di un modello di Machine Learning è in genere un processo in tre passaggi.
Per configurare un modello, scegliere un particolare tipo di algoritmo e definirne i parametri o gli iperparametri. Scegliere uno dei tipi di modello seguenti:
- Modelli di classificazione , basati su reti neurali, alberi delle decisioni e foreste delle decisioni e altri algoritmi.
- Modelli di regressione , che possono includere regressione lineare standard o che usano altri algoritmi, tra cui reti neurali e regressione bayesiana.
Specificare un set di dati etichettato e che disponga di dati compatibili con l'algoritmo. Connettere sia i dati che il modello a Train Model.
Il training prodotto è un formato binario specifico, ovvero iLearner, che incapsula i modelli statistici appresi dai dati. Non è possibile modificare o leggere direttamente questo formato; Tuttavia, altri componenti possono usare questo modello sottoposto a training.
È anche possibile visualizzare le proprietà del modello. Per altre informazioni, vedere la sezione Risultati.
Al termine del training, usare il modello sottoposto a training con uno dei componenti di assegnazione dei punteggi per eseguire stime sui nuovi dati.
Come usare Train Model
Aggiungere il componente Train Model alla pipeline. È possibile trovare questo componente nella categoria Machine Learning . Espandere Train (Esegui training) e quindi trascinare il componente Train Model (Esegui training modello ) nella pipeline.
Nell'input sinistro collegare la modalità non sottoposto a training. Collegare il set di dati di training all'input di destra di Train Model.
Il set di dati di training deve contenere una colonna etichetta. Le righe senza etichette vengono ignorate.
Per Colonna Etichetta fare clic su Modifica colonna nel pannello destro del componente e scegliere una singola colonna contenente i risultati che il modello può usare per il training.
Per i problemi di classificazione, la colonna label deve contenere valori categorici o valori discreti . Alcuni esempi possono essere una classificazione sì/no, un codice o un nome di classificazione delle malattie o un gruppo di reddito. Se si seleziona una colonna non categorica, il componente restituirà un errore durante il training.
Per i problemi di regressione, la colonna etichetta deve contenere dati numerici che rappresentano la variabile di risposta. Idealmente i dati numerici rappresentano una scala continua.
Alcuni esempi possono essere un punteggio di rischio di credito, il tempo previsto per un errore per un disco rigido o il numero previsto di chiamate a un call center in un determinato giorno o ora. Se non si sceglie una colonna numerica, è possibile che venga visualizzato un errore.
- Se non si specifica la colonna di etichetta da usare, Azure Machine Learning tenterà di dedurre la colonna di etichetta appropriata usando i metadati del set di dati. Se seleziona la colonna errata, usare il selettore di colonna per correggerlo.
Suggerimento
In caso di problemi con il selettore di colonna, vedere l'articolo Selezionare colonne nel set di dati per suggerimenti. Vengono descritti alcuni scenari e suggerimenti comuni per l'uso delle opzioni WITH RULES e BY NAME .
Inviare la pipeline. Se si dispone di una grande quantità di dati, l'operazione può richiedere un po' di tempo.
Importante
Se si dispone di una colonna ID che è l'ID di ogni riga o di una colonna di testo, che contiene troppi valori univoci, train model può generare un errore simile a "Numero di valori univoci nella colonna: "{column_name}" è maggiore del consentito.
Ciò è dovuto al fatto che la colonna raggiunge la soglia di valori univoci e può causare memoria insufficiente. È possibile usare Modifica metadati per contrassegnare la colonna come caratteristica Cancella e non verrà usata nel training o Estrarre funzionalità N-Gram dal componente Testo per pre-elaborare la colonna di testo. Per altri dettagli sull'errore, vedere Designer codice di errore.
Interpretabilità del modello
L'interpretazione del modello offre la possibilità di comprendere il modello di Machine Learning e di presentare la base sottostante per il processo decisionale in modo comprensibile agli esseri umani.
Attualmente il componente Train Model supporta l'uso del pacchetto di interpretabilità per spiegare i modelli di Machine Learning. Sono supportati gli algoritmi predefiniti seguenti:
- Linear Regression
- Regressione rete neurale
- Regressione albero decistion con boosting
- Regressione foresta delle decisioni
- Regressione di Poisson
- Regressione logistica a due classi
- Two-Class Support Vector Machine
- Two-Class albero decistionato con boosting
- Foresta delle decisioni a due classi
- Foresta delle decisioni multiclasse
- Regressione logistica multiclasse
- Rete neurale multiclasse
Per generare spiegazioni del modello, è possibile selezionare True nell'elenco a discesa Spiegazione modello nel componente Train Model .To generate model explanations, you can select True in the drop-down list of Model Explanation in Train Model component. Per impostazione predefinita, è impostata su False nel componente Train Model .By default it is set to False in the Train Model component. Si noti che la generazione di una spiegazione richiede costi di calcolo aggiuntivi.
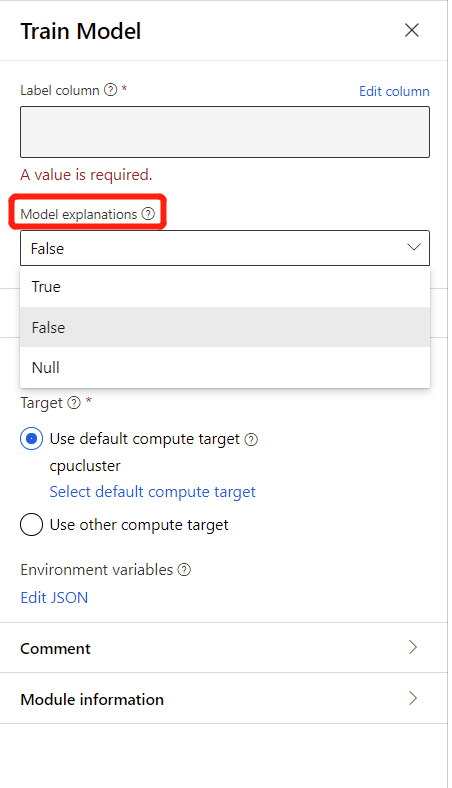
Al termine dell'esecuzione della pipeline, è possibile visitare la scheda Spiegazioni nel riquadro destro del componente Train Model ed esplorare le prestazioni del modello, il set di dati e l'importanza delle funzionalità.
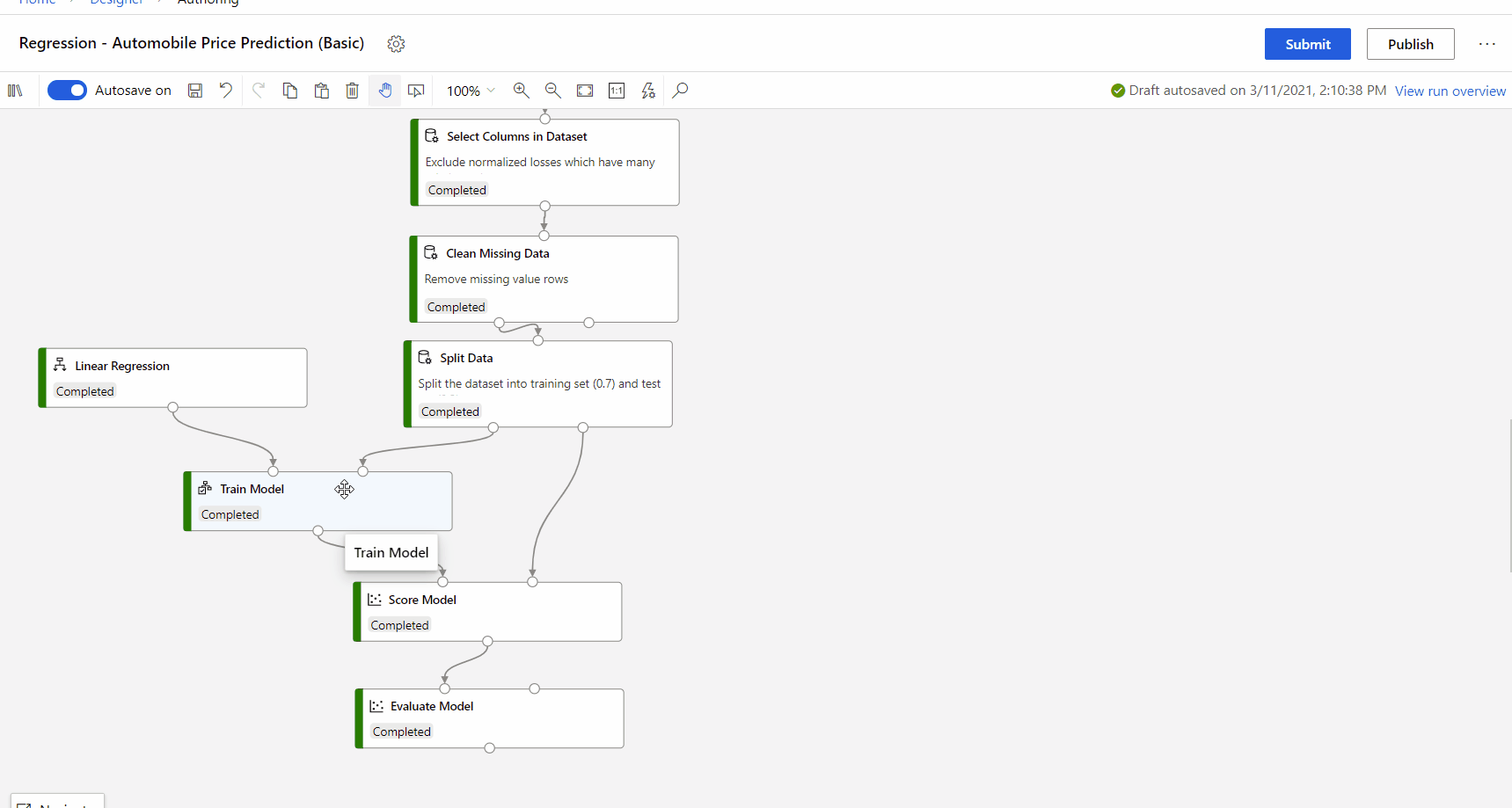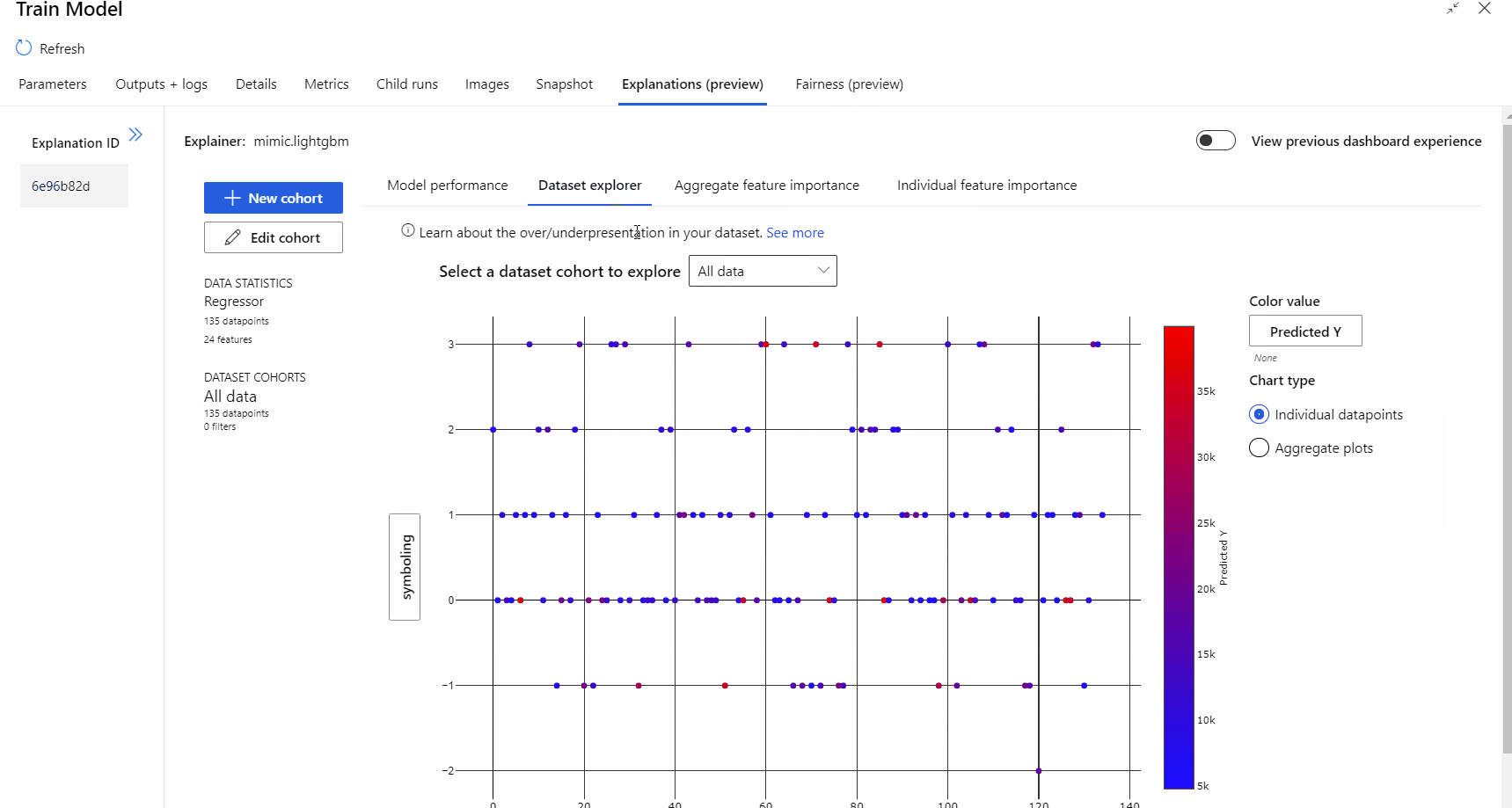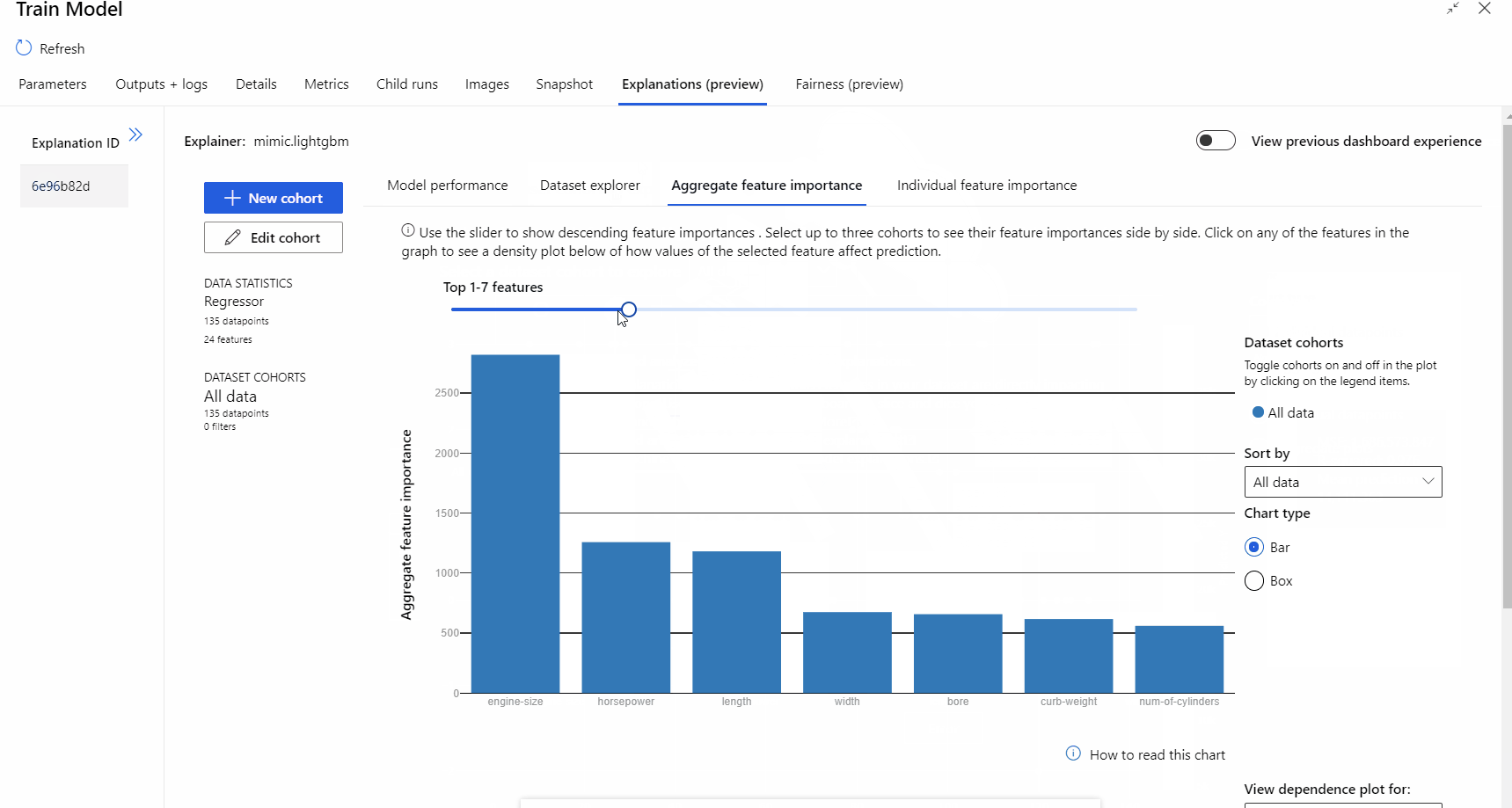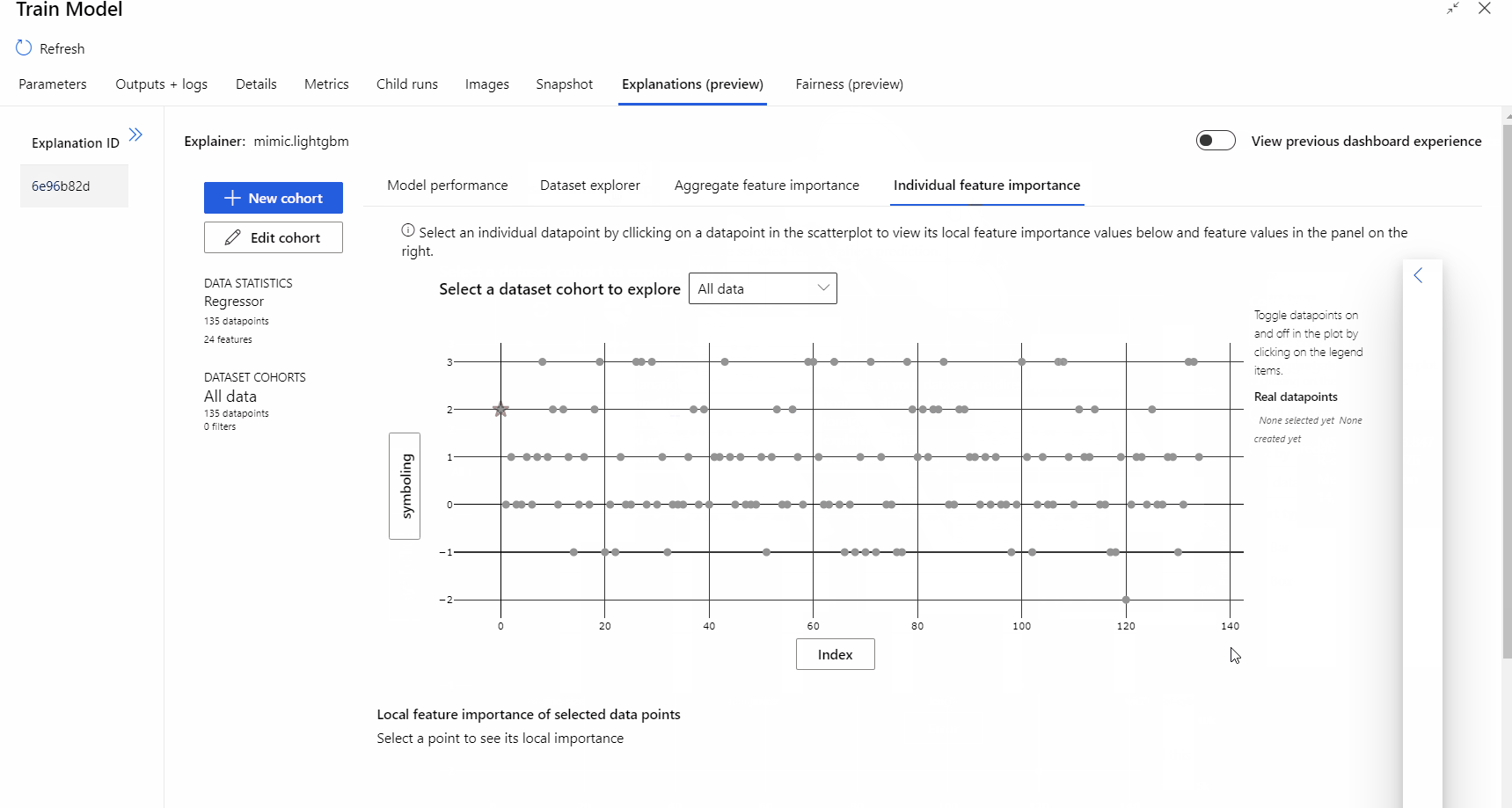
Per altre informazioni sull'uso delle spiegazioni dei modelli in Azure Machine Learning, vedere l'articolo sulle procedure sull'interpretazione dei modelli di Machine Learning.
Risultati
Dopo il training del modello:
Per usare il modello in altre pipeline, selezionare il componente e selezionare l'icona Registra set di dati nella scheda Output nel pannello a destra. È possibile accedere ai modelli salvati nella tavolozza dei componenti in Set di dati.
Per usare il modello per stimare nuovi valori, connetterlo al componente Score Model insieme ai nuovi dati di input.
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.