Scegliere i parametri per ottimizzare gli algoritmi in Machine Learning Studio (versione classica)
SI APPLICA A:Si applica Machine Learning Studio (versione classica)
Machine Learning Studio (versione classica)  Azure Machine Learning
Azure Machine Learning
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere leinformazioni sullo spostamento di progetti di Machine Learning da ML Studio (versione classica) ad Azure Machine Learning.
- Scoprire di più su Azure Machine Learning
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
Questo argomento descrive come scegliere il set di iperparametri corretto per un algoritmo in Machine Learning Studio (versione classica). Per la maggior parte degli algoritmi di Machine Learning è necessario impostare i parametri. Quando si esegue il training di un modello, è necessario specificare valori per questi parametri. L'efficacia del modello di cui è stato eseguito il training dipende dai parametri scelti per il modello. Il processo per trovare il set ottimale di parametri è noto come selezione del modello.
Ci sono vari modi per selezionare un modello. In Machine Learning la convalida incrociata è uno dei metodi più usati per la selezione dei modelli ed è il meccanismo di selezione del modello predefinito in Machine Learning Studio (versione classica). Poiché Machine Learning Studio (versione classica) supporta sia R che Python, è sempre possibile implementare i propri meccanismi di selezione dei modelli usando R o Python.
Il processo per trovare il migliore set di parametri è costituito da quattro passaggi:
- Definire lo spazio del parametro: prima decidere i valori esatti dei parametri che si vogliono prendere in considerazione per l'algoritmo.
- Definire le impostazioni di convalida incrociata: decidere come scegliere le riduzioni di convalida incrociata per il set di dati.
- Definire la metrica: decidere quale metrica usare per determinare il migliore set di parametri, ad esempio, l'accuratezza, l'errore quadratico medio, la precisione, il richiamo, o il punteggio f.
- Eseguire il training, valutare e confrontare: per ogni combinazione univoca dei valori dei parametri, la convalida incrociata viene eseguita e basata sulla metrica di errore definita dall'utente. Dopo valutazione e confronto, è possibile scegliere il modello con le prestazioni migliori.
L'immagine seguente illustra come è possibile ottenere questo risultato in Machine Learning Studio (versione classica).
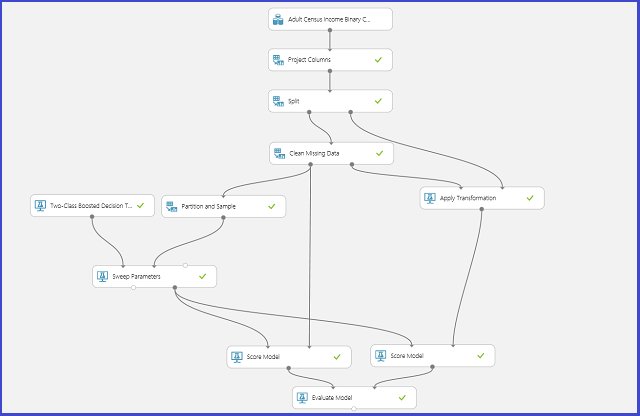
Definire lo spazio dei parametri
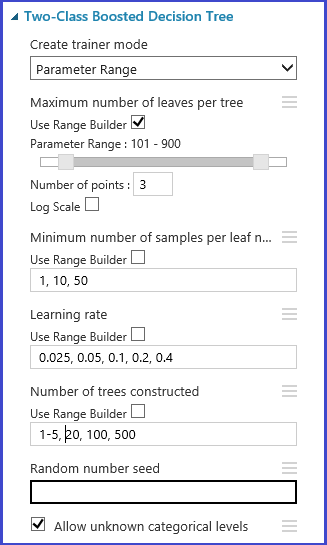
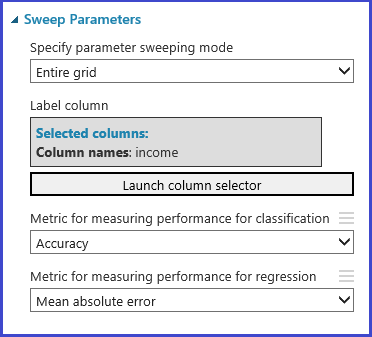
Il set di parametri può essere definito nella fase di inizializzazione del modello. Il pannello dei parametri di tutti gli algoritmi di Machine Learning presenta due modalità di training: parametro singolo e intervallo di parametri. Scegliere la modalità intervallo di parametri. Nella modalità intervallo di parametri è possibile immettere più valori per ogni parametro. Nella casella di testo è possibile immettere valori delimitati da virgole.
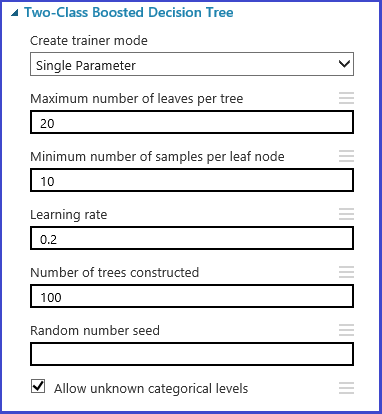
In alternativa è possibile definire il punto massimo e minimo della griglia e il numero totale dei punti da generare con Use Range Builder. Per impostazione predefinita, i valori dei parametri vengono generati su una scala lineare. Ma se è selezionata l'opzione Scala logaritmica, i valori vengono generati in scala logaritmica (ovvero, il rapporto dei punti adiacenti è costante invece di rappresentare la loro differenza). Per i parametri Integer, è possibile definire un intervallo tramite un segno meno. Ad esempio, "1-10" indica che tutti gli interi tra 1 e 10 (entrambi inclusi) formano il set di parametri. È supportata anche una modalità mista. Ad esempio, il set di parametri "1-10, 20, 50" include interi 1-10, 20 e 50.
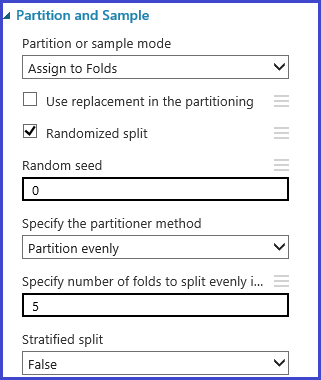
Definire le riduzioni di convalida incrociata
Il modulo Partition and Sample (Partizionamento e campionamento) può essere usato per assegnare riduzioni ai dati in modo casuale. Nella configurazione di esempio seguente del modulo, vengono definite cinque riduzioni e viene assegnato in modo casuale un numero di riduzione alle istanze dell'esempio.
Definire la metrica
Il modulo Tune Model Hyperparameters fornisce supporto per scegliere in modo empirico il miglior set di parametri per un algoritmo e un set di dati specifici. Oltre ad altre informazioni sul training del modello, il riquadro Properties (Proprietà) di questo modulo include la metrica per determinare il miglior set di parametri. E ha due elenchi a discesa rispettivamente per gli algoritmi di classificazione e di regressione. Se l'algoritmo in esame è un algoritmo di classificazione, la metrica di regressione viene ignorata e viceversa. In questo esempio specifico la metrica è Accuracy (Accuratezza).
Eseguire il training, valutare e confrontare
Lo stesso modulo Tune Model Hyperparameters esegue il training di tutti i modelli corrispondenti al set di parametri, valuta diverse metriche e crea il miglior modello in base alla metrica scelta. Tale modulo dispone di due input obbligatori:
- Allievo non formato
- Set di dati
Il modulo contiene anche un set di dati di input facoltativo. Connettere il set di dati con le informazioni di riduzione all'input del set di dati obbligatorio. Se al set di dati non vengono assegnate informazioni di riduzione, per impostazione predefinita viene eseguita automaticamente una convalida incrociata a 10 riduzioni. Se non viene eseguita l'assegnazione di riduzione e viene specificato un set di dati di convalida nella porta del set di dati facoltativo, viene scelta la modalità di test del training e viene usato il primo set di dati per eseguire il training del modello per ogni combinazione di parametri.
Il modello viene quindi valutato sul set di dati di convalida. La porta di output sinistra del modulo visualizza metriche diverse come funzioni dei valori del parametro. La porta di output destra offre il modello di cui è stato eseguito il training che corrisponde al modello con le migliori prestazioni in base alla metrica scelta (in questo caso Accuracy).
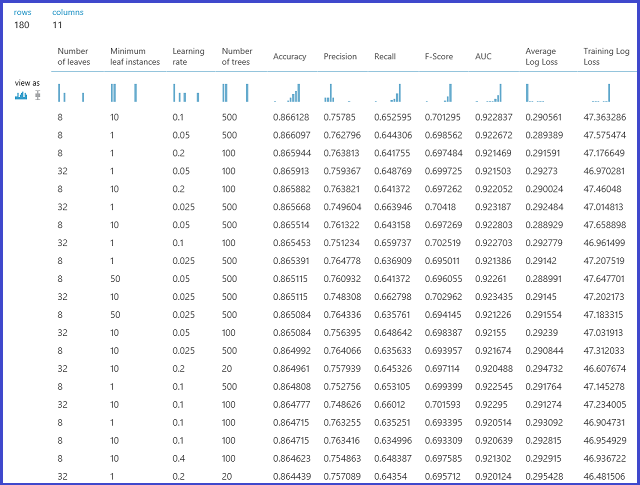
È possibile vedere esattamente i parametri scelti visualizzando la porta di output destra. Questo modello può essere utilizzato per la valutazione in un set di test o in un servizio web operativo dopo il salvataggio come modello per il training.