DevOps per una pipeline di inserimento dati
Nella maggior parte degli scenari, una soluzione di inserimento dati è una composizione di script, chiamate al servizio e una pipeline che orchestra tutte le attività. Questo articolo illustra come applicare le procedure DevOps al ciclo di vita di sviluppo di una pipeline di inserimento dati comune che prepara i dati per il training del modello di Machine Learning. La pipeline viene compilata usando i servizi di Azure seguenti:
- Azure Data Factory: legge i dati non elaborati e orchestra la preparazione dei dati.
- Azure Databricks: esegue un notebook Python che trasforma i dati.
- Azure Pipelines: automatizza un processo di integrazione e sviluppo continuo.
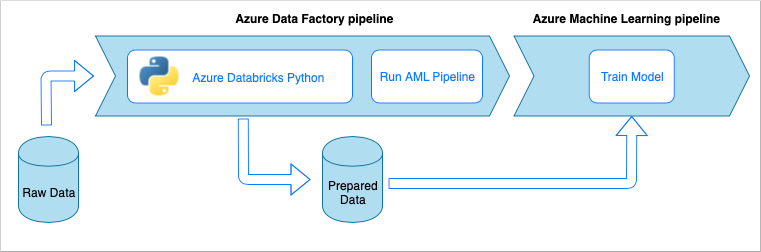
Flusso di lavoro della pipeline di inserimento dati
La pipeline di inserimento dati implementa il flusso di lavoro seguente:
- I dati non elaborati sono letti in una pipeline di Azure Data Factory (ADF).
- La pipeline di Azure Data Factory invia i dati a un cluster di Azure Databricks, che esegue un notebook Python per trasformare i dati.
- I dati vengono archiviati in un contenitore BLOB, dove possono essere usati da Azure Machine Learning per eseguire il training di un modello.
Panoramica dell'integrazione continua e recapito continuo
Come per molte soluzioni software, c'è un team, ad esempio, ingegneri dei dati, che lavora su di esso. Il team collabora e condivide le stesse risorse di Azure, ad esempio Azure Data Factory, Azure Databricks e gli account di Archiviazione di Azure. La raccolta di queste risorse è un ambiente di sviluppo. Gli ingegneri dei dati contribuiscono alla stessa codebase di origine.
Un sistema di integrazione continua e recapito continuo automatizza il processo di compilazione, test e distribuzione della soluzione. Il processo di integrazione continua (CI) esegue le attività seguenti:
- Assembla il codice
- Lo verifica rispetto ai test di qualità del codice
- Esegue gli unit test
- Produce artefatti come codice testato e modelli di Azure Resource Manager
Il processo di recapito continuo (CD) distribuisce gli artefatti negli ambienti downstream.
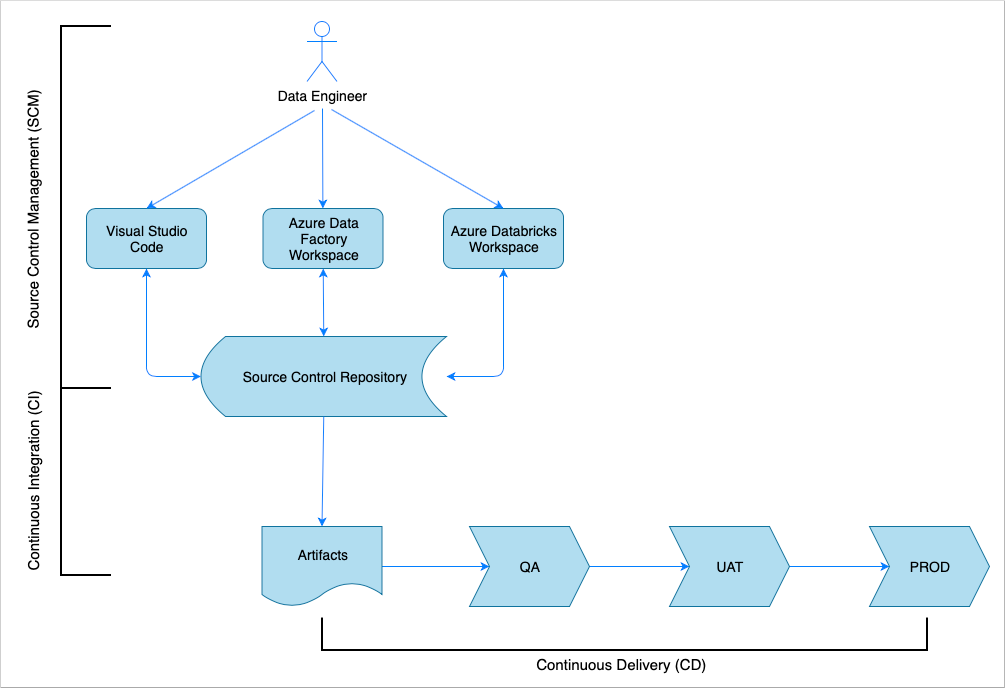
Questo articolo illustra come automatizzare i processi integrazione continua (CI) e recapito continuo (CD) con Azure Pipelines.
Gestione del controllo del codice sorgente
La gestione del controllo del codice sorgente è necessaria per tenere traccia delle modifiche e consentire la collaborazione tra i membri del team. Ad esempio, il codice verrà archiviato in un repository Azure DevOps, GitHub o GitLab. Il flusso di lavoro di collaborazione si basa su un modello di diramazione.
Codice sorgente del notebook Python
Gli ingegneri dei dati lavorano con il codice sorgente del notebook Python o in locale in un ambiente di sviluppo integrato (IDE), ad esempio, Visual Studio Code, o direttamente nell'area di lavoro di Databricks. Una volta completate le modifiche al codice, vengono unite al repository seguendo un criterio di diramazione.
Suggerimento
È consigliabile archiviare il codice nei file .py anziché in formato Jupyter Notebook .ipynb. Migliora la leggibilità del codice e abilita controlli automatici della qualità del codice nel processo di integrazione continua.
Codice sorgente di Azure Data Factory
Il codice sorgente delle pipeline di Azure Data Factory è una raccolta di file JSON generati da un'area di lavoro di Azure Data Factory. In genere, gli ingegneri dei dati lavorano con una finestra di progettazione visiva nell'area di lavoro di Azure Data Factory anziché direttamente con i file di codice sorgente.
Per configurare l'area di lavoro per l'uso di un repository di controllo del codice sorgente, vedere Scrivere codice con l’integrazione Git Azure Repos.
Integrazione continua (CI)
L'obiettivo finale del processo di integrazione continua è raccogliere il lavoro congiunto del team dal codice sorgente e prepararlo per la distribuzione negli ambienti downstream. Come per la gestione del codice sorgente, questo processo è diverso per i notebook Python e le pipeline di Azure Data Factory.
Integrazione continua (CI) di notebook Python
Il processo di integrazione continua per i notebook Python ottiene il codice dal ramo di collaborazione, ad esempio, master o develop, ed esegue le attività seguenti:
- Linting del codice
- Unit test
- Salvataggio del codice come artefatto
Il frammento di codice seguente illustra l'implementazione di questi passaggi in una pipeline YAML di Azure DevOps:
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
La pipeline usa flake8 per eseguire il linting del codice Python. Esegue gli unit test definiti nel codice sorgente e pubblica i risultati di linting e test in modo che siano disponibili nella schermata di esecuzione di Azure Pipelines.
Se l'esecuzione di linting e unit test ha esito positivo, la pipeline copia il codice sorgente nel repository degli artefatti da usare nei passaggi di distribuzione successivi.
Integrazione continua di Azure Data Factory
Il processo di integrazione continua per una pipeline di Azure Data Factory è un collo di bottiglia per una pipeline di inserimento dati. Non esiste alcuna integrazione continua. Un artefatto distribuibile per Azure Data Factory è una raccolta di modelli di Azure Resource Manager. L'unico modo per produrre questi modelli consiste nel fare clic sul pulsante Pubblica nell'area di lavoro di Azure Data Factory.
- Gli ingegneri dei dati uniscono il codice sorgente dai relativi rami di funzionalità nel ramo di collaborazione, ad esempio master o develop.
- Un utente con le autorizzazioni concesse fa clic sul pulsante Pubblica per generare modelli di Azure Resource Manager dal codice sorgente nel ramo di collaborazione.
- L'area di lavoro convalida le pipeline, la si consideri come linting e unit test, genera modelli di Azure Resource Manager, la si consideri come compilazione, e salva i modelli generati in un ramo tecnico adf_publish nello stesso repository di codice, la si consideri come la pubblicazione degli artefatti. Questo ramo viene creato automaticamente dall'area di lavoro di Azure Data Factory.
Per altre informazioni su questo processo, vedere Integrazione continua e recapito continuo in Azure Data Factory.
È importante assicurarsi che i modelli di Azure Resource Manager generati siano indipendenti dall'ambiente. Ciò significa che tutti i valori che possono variare tra gli ambienti sono parametrizzati. Azure Data Factory è abbastanza intelligente da esporre la maggior parte di valori come i parametri. Ad esempio, nel modello seguente le proprietà di connessione a un'area di lavoro di Azure Machine Learning vengono esposte come parametri:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
Tuttavia, è possibile esporre le proprietà personalizzate non gestite dall'area di lavoro di Azure Data Factory per impostazione predefinita. Nello scenario di questo articolo una pipeline di Azure Data Factory richiama un notebook Python che elabora i dati. Il notebook accetta un parametro con il nome di un file di dati di input.
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
Questo nome è diverso per gli ambienti Dev, QA, UAT e PROD. In una pipeline complessa con più attività possono essere presenti diverse proprietà personalizzate. È consigliabile raccogliere tutti questi valori in un'unica posizione e definirli come variabili della pipeline:
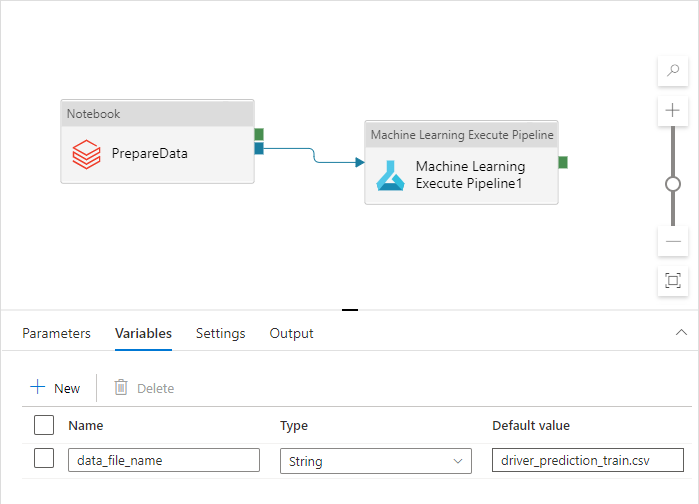
Le attività della pipeline possono fare riferimento alle variabili della pipeline durante l'uso effettivo:
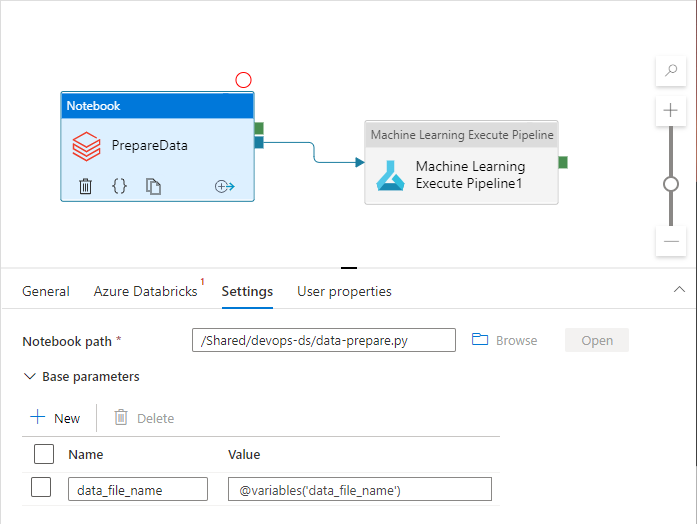
L'area di lavoro di Azure Data Factory non espone le variabili della pipeline come parametri dei modelli di Azure Resource Manager per impostazione predefinita. L'area di lavoro usa il modello di parametrizzazione predefinito stabilendo quali proprietà della pipeline devono essere esposte come parametri del modello di Azure Resource Manager. Per aggiungere variabili della pipeline all'elenco, aggiornare la sezione "Microsoft.DataFactory/factories/pipelines" del Modello di parametrizzazione predefinito con il frammento di codice seguente e inserire il file JSON risultato nella radice della cartella di origine:
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
In questo modo, l'area di lavoro di Azure Data Factory verrà forzata ad aggiungere le variabili all'elenco dei parametri quando si fa clic sul pulsante Pubblica:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
I valori nel file JSON sono predefiniti, configurati nella definizione della pipeline. È previsto che vengano sottoposti a override con i valori dell'ambiente di destinazione quando viene distribuito il modello di Azure Resource Manager.
Recapito continuo (CD)
Il processo di recapito continuo accetta gli artefatti e li distribuisce nel primo ambiente di destinazione. Verifica che la soluzione funzioni eseguendo test. In caso di esito positivo, continua con l'ambiente successivo.
Il recapito continuo (CD) di Azure Pipelines è costituito da più fasi rappresentate dagli ambienti. Ogni fase contiene distribuzioni e processi che eseguono i passaggi seguenti:
- Distribuire un notebook Python nell'area di lavoro di Azure Databricks
- Distribuire una pipeline di Azure Data Factory
- Eseguire la pipeline
- Controllare il risultato dell'inserimento dati
Le fasi della pipeline possono essere configurate con approvazioni e gate che forniscono un controllo aggiuntivo sul modo in cui il processo di distribuzione si evolve attraverso la catena di ambienti.
Distribuire un notebook Python
Il frammento di codice seguente definisce una distribuzione di Azure Pipeline che copia un notebook Python in un cluster di Databricks:
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
Gli artefatti prodotti dall'integrazione continua vengono copiati automaticamente nell'agente di distribuzione e sono disponibili nella cartella $(Pipeline.Workspace). In questo caso, l'attività di distribuzione fa riferimento all’artefatto di-notebooks contenente il notebook Python. Questa distribuzione usa l'estensione Azure DevOps di Databricks per copiare i file del notebook nell'area di lavoro di Databricks.
La fase Deploy_to_QA contiene un riferimento al gruppo di variabili devops-ds-qa-vg definito nel progetto Azure DevOps. I passaggi di questa fase fanno riferimento alle variabili di questo gruppo di variabili, ad esempio $(DATABRICKS_URL) e $(DATABRICKS_TOKEN). L'idea è che la fase successiva, ad esempio Deploy_to_UAT, funzionerà con gli stessi nomi di variabile definiti nel proprio gruppo di variabili con ambito UAT.
Distribuire una pipeline di Azure Data Factory
Un artefatto distribuibile per Azure Data Factory è un modello di Azure Resource Manager. Verrà distribuito con l'attività distribuzione del gruppo di risorse di Azure come illustrato nel frammento di codice seguente:
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
Il valore del parametro data filename deriva dalla variabile $(DATA_FILE_NAME) definita in un gruppo di variabili in fase di QA. Analogamente, è possibile eseguire l'override di tutti i parametri definiti in ARMTemplateForFactory.json. In caso contrario, vengono usati i valori predefiniti.
Eseguire la pipeline e controllare il risultato dell'inserimento dati
Il passaggio successivo consiste nel verificare che la soluzione distribuita funzioni. La definizione di processo seguente esegue una pipeline di Azure Data Factory con uno script di PowerShell ed esegue un notebook Python in un cluster di Azure Databricks. Il notebook controlla se i dati sono stati inseriti correttamente e convalida il file di dati dei risultati con il nome $(bin_FILE_NAME).
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
L'attività finale nel processo controlla il risultato dell'esecuzione del notebook. Se restituisce un errore, imposta lo stato dell'esecuzione della pipeline su non riuscito.
Riepilogo
L’integrazione continua e recapito continuo (CI/CD) di Azure Pipeline completa è costituita dalle fasi seguenti:
- CI
- Eseguire la distribuzione nel QA
- Eseguire la distribuzione in Databricks e distribuire in Azure Data Factory
- Test di integrazione
Contiene una serie di fasi di distribuzione pari al numero di ambienti di destinazione disponibili. Ogni fase di distribuzione contiene due distribuzioni eseguite in parallelo e un processo eseguito dopo le distribuzioni per testare la soluzione nell'ambiente.
Un'implementazione di esempio della pipeline viene assemblata nel frammento di codice YAML seguente:
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'