Configurare un ambiente di sviluppo con Azure Databricks e AutoML in Azure Machine Learning
Informazioni su come configurare un ambiente di sviluppo in Azure Machine Learning che usa Azure Databricks e ML automatizzato.
Azure Databricks è ideale per l'esecuzione di flussi di lavoro di Machine Learning su larga scala nella piattaforma scalabile di Apache Spark nel cloud di Azure. Offre un ambiente di collaborazione basato su Notebook con un cluster di calcolo basato su CPU o GPU.
Per informazioni su altri ambienti di sviluppo Machine Learning, vedere Configurare l'ambiente di sviluppo Python.
Prerequisito
Area di lavoro di Azure Machine Learning. Per crearne una, seguire la procedura descritta nell'articolo Creare risorse dell'area di lavoro.
Azure Databricks con Azure Machine Learning e AutoML
Azure Databricks si integra con Azure Machine Learning e le relative funzionalità di AutoML.
È possibile usare Azure Databricks:
- Per eseguire il training di un modello con Spark MLlib e distribuire il modello in Istanze di Azure Container e/o nel servizio Azure Container.
- Con le funzionalità di Machine Learning automatizzato usando un SDK di Azure Machine Learning.
- Come destinazione di calcolo da una pipeline di Azure Machine Learning.
Configurare un cluster di Databricks
Creare un cluster di Databricks. Alcune impostazioni vengono applicate solo dopo l'installazione dell'SDK per processi di Machine Learning automatizzato in Databricks.
La creazione del cluster richiede alcuni minuti.
Usare queste impostazioni:
| Impostazione | Si applica a | Valore |
|---|---|---|
| Nome del cluster | sempre | nomecluster |
| Databricks Runtime Version | sempre | 9.1 LTS |
| Versione di Python | sempre | 3 |
| Tipo di ruolo di lavoro (determina il numero massimo di iterazioni simultanee) |
Machine Learning automatizzato only |
È preferibile una macchina virtuale ottimizzata per la memoria |
| Lavoratori | sempre | almeno 2 |
| Enable Autoscaling (Abilita la scalabilità automatica) | Machine Learning automatizzato only |
Deselezionare |
Attendere che il cluster sia in esecuzione prima di proseguire.
Aggiungere Azure Machine Learning SDK a Databricks
Una volta avviata l'esecuzione del cluster, creare una libreria per collegare il pacchetto appropriato di Azure Machine Learning SDK al proprio cluster.
Per usare ML automatizzato, passare alla sezione Aggiungere Azure Machine Learning SDK con AutoML a Databricks.
Fare clic con il pulsante destro del mouse sulla cartella dell'area di lavoro corrente in cui archiviare la libreria. Selezionare Crea>Libreria.
Suggerimento
Se si ha una versione precedente dell'SDK, deselezionarla dalle librerie installate del cluster e spostarla nel Cestino. Installare la nuova versione dell'SDK e riavviare il cluster. Se dopo il riavvio si verifica un problema, scollegare e ricollegare il cluster.
Scegliere l'opzione seguente (non sono supportate altre installazioni dell'SDK)
Elementi aggiuntivi del pacchetto SDK Origine PyPi Name (Nome PyPi) Per Databricks Caricare Python Egg o PyPI azureml-sdk[databricks] Avviso
Non è possibile installare elementi aggiuntivi dell'SDK. Scegliere solo l'opzione [
databricks].- Non selezionare Collega automaticamente a tutti i cluster.
- Selezionare Collega accanto al nome del cluster.
Monitorare l'eventuale presenza di errori finché lo stato non diventa Collegato. L'operazione potrebbe richiedere alcuni minuti. Se questo passaggio non riesce:
Eseguire le operazioni seguenti per provare a riavviare il cluster:
- Nel riquadro a sinistra selezionare Cluster.
- Nella tabella selezionare il nome del cluster.
- Nella scheda Librerie selezionare Riavvia.
Un installazione riuscita è simile all'immagine seguente:
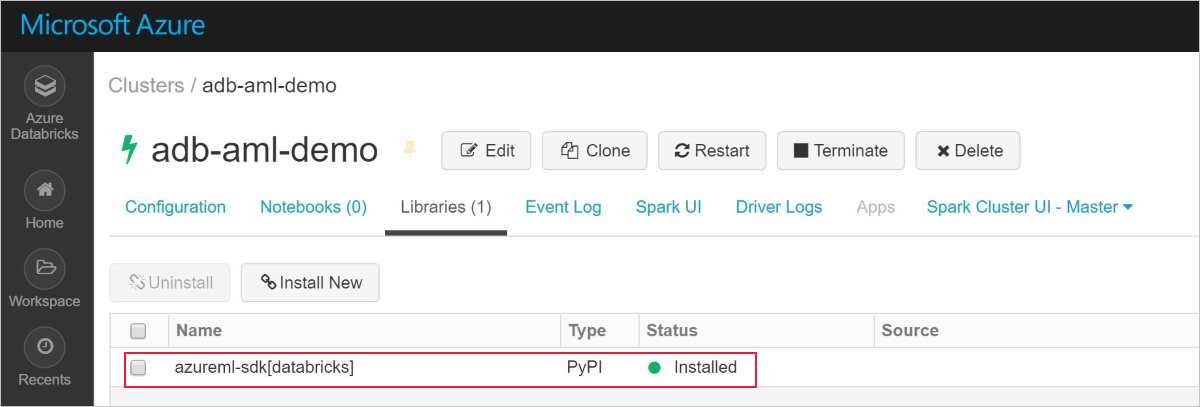
Aggiungere Azure Machine Learning SDK con AutoML a Databricks
Se il cluster è stato creato con Databricks Runtime 7.3 LTS (non ML), eseguire il comando seguente nella prima cella del notebook per installare Azure Machine Learning SDK.
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
Impostazioni di configurazione di AutoML
Nella configurazione di AutoML aggiungere i parametri seguenti quando si usa Azure Databricks:
max_concurrent_iterationssi basa sul numero di nodi di lavoro nel cluster.spark_context=scsi basa sul contesto Spark predefinito.
Notebook di ML compatibili con Azure Databricks
Per provarlo:
Anche se sono disponibili molti notebook di esempio, solo questi notebook di esempio sono compatibili con Azure Databricks.
Importare questi esempi direttamente dall'area di lavoro. Vedere di seguito:
Informazioni su come creare una pipeline con Databricks come ambiente di calcolo di training.
Risoluzione dei problemi
Databricks annulla un'esecuzione di Machine Learning automatizzato: quando si usano le funzionalità di Machine Learning automatizzato in Azure Databricks e si vuole annullare un'esecuzione per avviare una nuova esecuzione dell'esperimento, riavviare il cluster di Azure Databricks.
Più di 10 iterazioni di Databricks per Machine Learning automatizzato: se nelle impostazioni di Machine Learning automatizzato sono presenti più di 10 iterazioni, impostare
show_outputsuFalsequando si invia l'esecuzione.Widget Databricks per Azure Machine Learning SDK e Machine Learning automatizzato: il widget di Azure Machine Learning SDK non è supportato in un notebook di Databricks perché i notebook non possono analizzare widget HTML. È possibile visualizzare il widget nel portale usando questo codice Python nella cella del notebook di Azure Databricks:
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))Errore durante l'installazione dei pacchetti
L'installazione di Azure Machine Learning SDK in Azure Databricks non riesce quando sono installati altri pacchetti. Alcuni pacchetti, come
psutil, possono causare conflitti. Per evitare errori di installazione, installare i pacchetti bloccando la versione della libreria. Questo problema è correlato a Databricks e non ad Azure Machine Learning SDK. Potrebbe verificarsi anche con altre librerie. Esempio:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0In alternativa, è possibile usare gli script di inizializzazione se si continuano a riscontrare problemi di installazione con le librerie Python. Questo approccio non è supportato ufficialmente. Per altre informazioni, vedere Script init con ambito cluster.
Errore di importazione: non è possibile importare il nome
Timedeltadapandas._libs.tslibs: se viene visualizzato questo errore quando si usa Machine Learning automatizzato, eseguire le due righe seguenti nel notebook:%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4Errore di importazione: non esiste alcun modulo denominato 'pandas.core.indexes': se viene visualizzato questo errore quando si usa Machine Learning automatizzato:
Eseguire questo comando per installare due pacchetti nel cluster di Azure Databricks:
scikit-learn==0.19.1 pandas==0.22.0Scollegare e ricollegare il cluster al notebook.
Se questa procedura non risolve il problema, provare a riavviare il cluster.
FailToSendFeather: se viene visualizzato un errore
FailToSendFeatherdurante la lettura dei dati nel cluster di Azure Databricks, vedere le soluzioni seguenti:- Eseguire l'aggiornamento del pacchetto
azureml-sdk[automl]alla versione più recente. - Aggiungere
azureml-dataprepversione 1.1.8 o successiva. - Aggiungere
pyarrowversione 0.11 o successiva.
- Eseguire l'aggiornamento del pacchetto
Passaggi successivi
- Eseguire il training e distribuire un modello in Azure Machine Learning con il set di dati MNIST.
- Vedere la documentazione di riferimento del Software Development Kit di Azure Machine Learning per Python.