Eseguire il training con progetti MLflow in Azure Machine Learning (anteprima)
Questo articolo illustra come inviare processi di training con progetti MLflow che usano le aree di lavoro di Azure Machine Learning per il rilevamento. È possibile inviare processi e monitorarli solo con Azure Machine Learning o eseguire la migrazione delle esecuzioni nel cloud per l'esecuzione completa in ambiente di calcolo di Machine Learning.
Avviso
Il supporto per i file di MLproject (MLflow Projects) in Azure Machine Learning verrà ritirato completamente a settembre 2026. MLflow è ancora completamente supportato ed è comunque il modo consigliato per tenere traccia dei carichi di lavoro di Machine Learning in Azure Machine Learning.
Man mano che si continua a usare MLflow, è consigliabile passare da file di MLproject a Processi Azure Machine Learning, usando l'interfaccia della riga di comando di Azure o Azure Machine Learning SDK per Python (v2). Per altre informazioni sui processi di Azure Machine Learning, vedere Tenere traccia degli esperimenti e dei modelli di Machine Learning con MLflow.
Progetti MLflow consentono di organizzare e descrivere il codice per consentire ad altri data scientist (o strumenti automatizzati) di eseguirlo. I progetti MLflow con Azure Machine Learning consentono di tenere traccia e gestire le esecuzioni di training nell'area di lavoro.
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto non è consigliabile usarla per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Altre informazioni sull'integrazione di MLflow e Azure Machine Learning.
Prerequisiti
Installare il pacchetto SDK MLflow
mlflowe il plug-in di Azure Machine Learning per MLflowazureml-mlflow.pip install mlflow azureml-mlflowSuggerimento
È possibile usare il pacchetto
mlflow-skinny, che è un pacchetto di MLflow leggero senza risorse di archiviazione SQL, server, interfaccia utente o dipendenze di data science.mlflow-skinnyè consigliabile per gli utenti che necessitano principalmente delle funzionalità di rilevamento e registrazione di MLflow senza importare il gruppo completo di funzionalità, incluse le distribuzioni.Un'area di lavoro di Azure Machine Learning. È possibile crearne una seguendo l'esercitazione Creare risorse di Machine Learning.
Se si esegue il rilevamento remoto, ovvero si monitorano esperimenti in esecuzione all'esterno di Azure Machine Learning, configurare MLflow in modo che punti all'URI di rilevamento dell'area di lavoro di Azure Machine Learning. Per altre informazioni su come connettere MLflow all'area di lavoro, vedere Configurare MLflow per Azure Machine Learning.
L'uso di Azure Machine Learning come back-end per i progetti MLflow richiede il pacchetto
azureml-core:pip install azureml-core
Connettersi all'area di lavoro
Se si lavora all'esterno di Azure Machine Learning, è necessario configurare MLflow in modo che punti all'URI di rilevamento dell'area di lavoro di Azure Machine Learning. Le istruzioni sono disponibili in Configurare MLflow per Azure Machine Learning.
Tenere traccia dei progetti MLflow nelle aree di lavoro di Azure Machine Learning
Questo esempio illustra come inviare progetti MLflow e tracciarli Azure Machine Learning.
Aggiungere il pacchetto
azureml-mlflowcome dipendenza pip al file di configurazione dell'ambiente per tenere traccia delle metriche e degli artefatti chiave nell'area di lavoro.conda.yaml
name: mlflow-example channels: - defaults dependencies: - numpy>=1.14.3 - pandas>=1.0.0 - scikit-learn - pip: - mlflow - azureml-mlflowInviare l'esecuzione locale e assicurarsi di impostare il parametro
backend = "azureml", che aggiunge il supporto del rilevamento automatico, dell'acquisizione del modello, dei file di log, degli snapshot e degli errori stampati nell'area di lavoro. In questo esempio si presuppone che il progetto MLflow che si sta tentando di eseguire si trovi nella stessa cartella attualmente in uso,uri=".".mlflow run . --experiment-name --backend azureml --env-manager=local -P alpha=0.3Visualizzare le esecuzioni e le metriche nello studio di Azure Machine Learning.
Eseguire il training di progetti MLflow nei processi di Azure Machine Learning
Questo esempio illustra come inviare progetti MLflow come processo in esecuzione nell'ambiente di calcolo di Azure Machine Learning.
Creare l'oggetto di configurazione back-end, in questo caso verrà indicato
COMPUTE. Questo parametro fa riferimento al nome del cluster di elaborazione remoto che si vuole usare per l'esecuzione del progetto. SeCOMPUTEè presente, il progetto verrà inviato automaticamente come processo di Azure Machine Learning al calcolo indicato.backend_config.json
{ "COMPUTE": "cpu-cluster" }Aggiungere il pacchetto
azureml-mlflowcome dipendenza pip al file di configurazione dell'ambiente per tenere traccia delle metriche e degli artefatti chiave nell'area di lavoro.conda.yaml
name: mlflow-example channels: - defaults dependencies: - numpy>=1.14.3 - pandas>=1.0.0 - scikit-learn - pip: - mlflow - azureml-mlflowInviare l'esecuzione locale e assicurarsi di impostare il parametro
backend = "azureml", che aggiunge il supporto del rilevamento automatico, dell'acquisizione del modello, dei file di log, degli snapshot e degli errori stampati nell'area di lavoro. In questo esempio si presuppone che il progetto MLflow che si sta tentando di eseguire si trovi nella stessa cartella attualmente in uso,uri=".".mlflow run . --backend azureml --backend-config backend_config.json -P alpha=0.3Nota
Poiché i processi di Azure Machine Learning vengono sempre eseguiti nel contesto degli ambienti, il parametro
env_managerviene ignorato.Visualizzare le esecuzioni e le metriche nello studio di Azure Machine Learning.
Pulire le risorse
Se non si prevede di usare le metriche e gli artefatti registrati nell'area di lavoro, non è attualmente possibile eliminarli singolarmente. Eliminare invece il gruppo di risorse che contiene l'account di archiviazione e l'area di lavoro, in modo che non vengano addebitati costi:
Nel portale di Azure fare clic su Gruppi di risorse all'estrema sinistra.
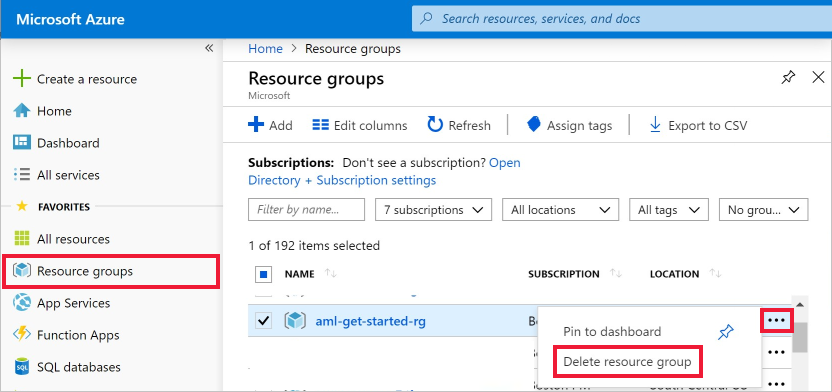
Nell'elenco selezionare il gruppo di risorse creato.
Selezionare Elimina gruppo di risorse.
Immettere il nome del gruppo di risorse. Quindi seleziona Elimina.
Notebook di esempio
Questo articolo illustra e analizza in dettaglio i notebook MLflow con Azure Machine Learning.
- Eseguire il training di un progetto MLflow in un calcolo locale
- Eseguire il training di un progetto MLflow in un calcolo remoto.
Nota
Un repository di esempi dell'uso di MLflow gestito dalla community è disponibile all'indirizzo https://github.com/Azure/azureml-examples.