Creare una query full-text in Ricerca di intelligenza artificiale di Azure
Se si sta creando una query per la ricerca full-text, questo articolo illustra i passaggi per configurare la richiesta. Introduce anche una struttura di query e spiega in che modo gli attributi dei campi e gli analizzatori linguistici possono influire sui risultati delle query.
Prerequisiti
Indice di ricerca con campi stringa attribuiti come
searchable.Autorizzazioni di lettura per l'indice di ricerca. Per l'accesso in lettura, includere una chiave API di query nella richiesta o concedere al chiamante le autorizzazioni di lettura dati dell'indice di ricerca.
Esempio di richiesta di query full-text
In Ricerca di intelligenza artificiale di Azure una query è una richiesta di sola lettura per la raccolta di documenti di un singolo indice di ricerca, con parametri che informano l'esecuzione della query e modellano la risposta restituita.
Una query full-text viene specificata in un search parametro ed è costituita da termini, frasi racchiuse tra virgolette e operatori. Altri parametri aggiungono altre definizioni alla richiesta.
La chiamata API REST POST di ricerca seguente illustra una richiesta di query usando i parametri indicati in precedenza.
POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/search?api-version=2023-11-01
{
"search": "NY +view",
"queryType": "simple",
"searchMode": "all",
"searchFields": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"select": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"top": "10",
"count": "true"
}
Punti principali:
searchfornisce i criteri di corrispondenza, in genere termini interi o frasi, con o senza operatori. Qualsiasi campo attribuito come "ricercabile" nello schema dell'indice è un candidato per questo parametro.queryTypeimposta il parser:simple,full. Il parser di query semplice predefinito è ottimale per la ricerca full-text. Il parser di query Lucene completo è destinato a costrutti di query avanzati come espressioni regolari, ricerca di prossimità, ricerca fuzzy e ricerca con caratteri jolly. Questo parametro può anche essere impostato susemanticper la classificazione semantica per la modellazione semantica avanzata nella risposta della query.searchModespecifica se le corrispondenze sono basate su criteri "all" (predilige la precisione) o su "any" (richiamare) nell'espressione. Il valore predefinito è "any". Se si prevede un uso elevato degli operatori booleani, che è più probabile negli indici che contengono blocchi di testo di grandi dimensioni (un campo di contenuto o descrizioni lunghe), assicurarsi di testare le query con ilsearchMode=Any|Allparametro per valutare l'impatto di tale impostazione sulla ricerca booleana.searchFieldsvincola l'esecuzione di query a campi ricercabili specifici. Durante lo sviluppo, è utile usare lo stesso elenco di campi per la selezione e la ricerca. In caso contrario, una corrispondenza potrebbe essere basata su valori di campo che non è possibile visualizzare nei risultati, creando incertezza sul motivo per cui è stato restituito il documento.
Parametri usati per modellare la risposta:
selectspecifica i campi da restituire nella risposta. Solo i campi contrassegnati come "recuperabili" nell'indice possono essere usati in un'istruzione select.toprestituisce il numero specificato di documenti corrispondenti. In questo esempio vengono restituiti solo 10 riscontri. È possibile usare la parte superiore e ignorare (non visualizzata) per paginare i risultati.countindica quanti documenti nell'intero indice corrispondono complessivamente, che possono essere più di quelli restituiti.orderbyviene usato se si desidera ordinare i risultati in base a un valore, ad esempio una classificazione o una posizione. In caso contrario, l'impostazione predefinita consiste nell'usare il punteggio di pertinenza per classificare i risultati. Un campo deve essere attribuito come "ordinabile" per essere un candidato per questo parametro.
Scegliere un client
Per i primi test di sviluppo e modello di verifica, iniziare con portale di Azure o un client REST. Entrambi gli approcci sono interattivi, utili per i test mirati e consentono di valutare gli effetti di proprietà diverse senza dover scrivere codice.
Per chiamare la ricerca dall'interno di un'app, usare le librerie client Azure.Document.Search negli SDK di Azure per .NET, Java, JavaScript e Python.
Nel portale, quando si apre un indice, è possibile usare Esplora ricerche insieme alla definizione JSON dell'indice nelle schede affiancate per semplificare l'accesso agli attributi dei campi. Controllare la tabella Fields per vedere quali sono ricercabili, ordinabili, filtrabili e facetable durante il test delle query.
Accedere al portale di Azure e trovare il servizio di ricerca.
Aprire Indici e selezionare un indice.
Viene aperto un indice nella scheda Esplora ricerche in modo che sia possibile eseguire immediatamente una query. Passare alla visualizzazione JSON per specificare la sintassi delle query.
Ecco un'espressione di query di ricerca full-text che funziona per l'indice di esempio Hotels:
{ "search": "pool spa +airport", "queryType": "simple", "searchMode": "any", "searchFields": "Description, Tags", "select": "HotelName, Description, Tags", "top": 10, "count": true }Lo screenshot seguente illustra la query e la risposta:
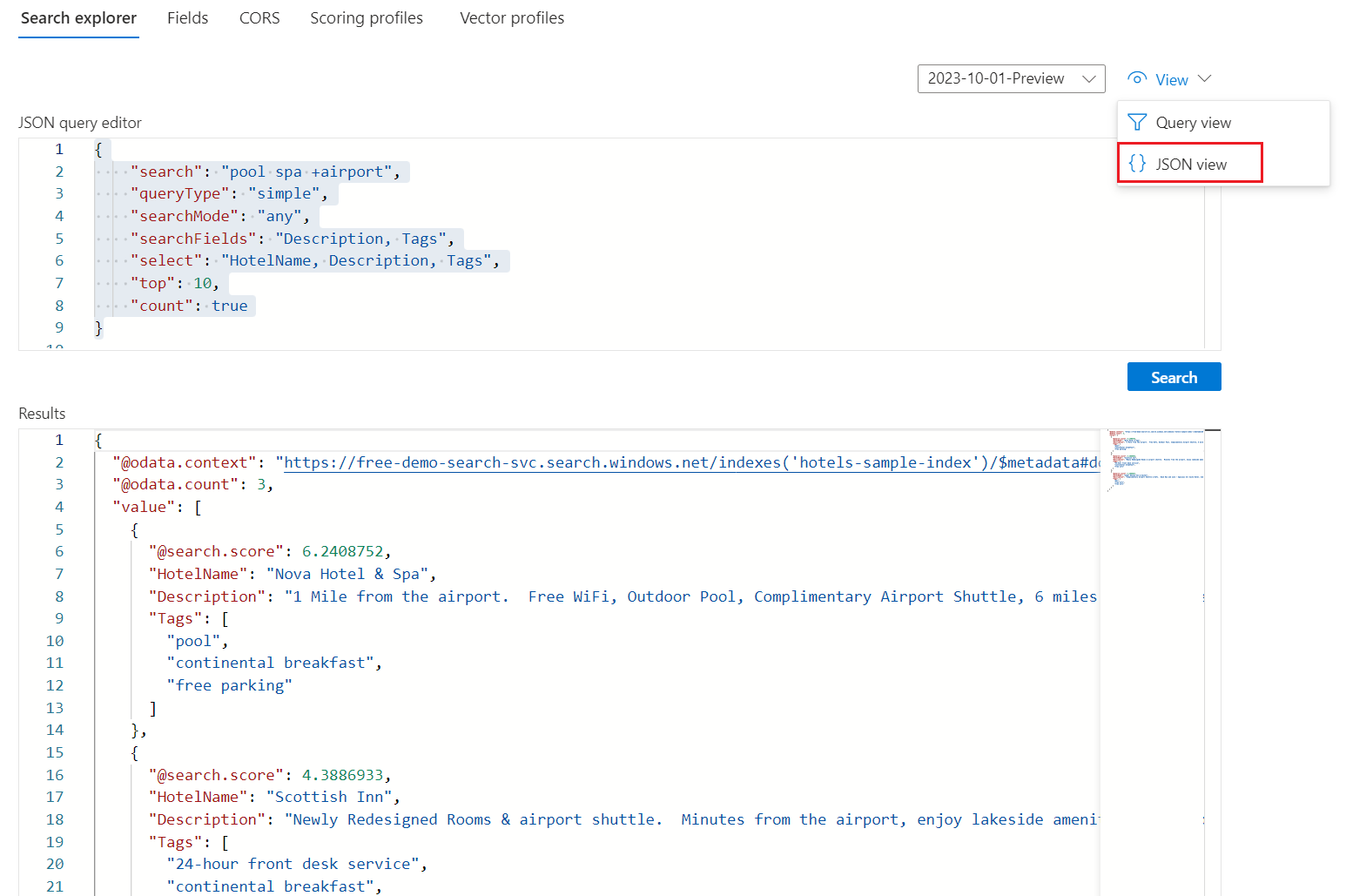
Scegliere un tipo di query: semplice | Completo
Se la query è una ricerca full-text, viene usato un parser di query per elaborare qualsiasi testo passato come termini di ricerca e frasi. Ricerca di intelligenza artificiale di Azure offre due parser di query.
Il parser semplice comprende la sintassi di query semplice. Questo parser è stato selezionato come valore predefinito per la velocità e l'efficacia nelle query di testo in formato libero. La sintassi supporta operatori di ricerca comuni (AND, OR, NOT) per le ricerche di termini e frasi e il prefisso (
*) (come in "sea*" per Seattle e Sea). È consigliabile provare prima il parser semplice e quindi passare a un parser completo se i requisiti dell'applicazione richiedono query più potenti.La sintassi di query Lucene completa, abilitata quando si aggiunge
queryType=fullalla richiesta, si basa sul parser Apache Lucene.
La sintassi completa e la sintassi semplice si sovrappongono nella misura in cui entrambi supportano le stesse operazioni di prefisso e booleano, ma la sintassi completa fornisce più operatori. Sono disponibili più operatori per le espressioni booleane e altri operatori per query avanzate, ad esempio ricerca fuzzy, ricerca con caratteri jolly, ricerca di prossimità ed espressioni regolari.
Scegliere i metodi di query
La ricerca è fondamentalmente un esercizio guidato dall'utente, in cui termini o frasi vengono raccolti da una casella di ricerca o da eventi click in una pagina. La tabella seguente riepiloga i meccanismi in base ai quali è possibile raccogliere l'input dell'utente, insieme all'esperienza di ricerca prevista.
| Input | Esperienza |
|---|---|
| Metodo di ricerca | Un utente digita i termini o le frasi in una casella di ricerca, con o senza operatori, e fa clic su Cerca per inviare la richiesta. La ricerca può essere usata con filtri sulla stessa richiesta, ma non con completamento automatico o suggerimenti. |
| Autocomplete, metodo | Un utente digita alcuni caratteri e le query vengono avviate dopo la digitazione di ogni nuovo carattere. La risposta è una stringa completata dall'indice. Se la stringa specificata è valida, l'utente fa clic su Cerca per inviare tale query al servizio. |
| Metodo Suggestions | Come per il completamento automatico, vengono generati alcuni caratteri e query incrementali. La risposta è un elenco a discesa di documenti corrispondenti, in genere rappresentati da alcuni campi univoci o descrittivi. Se una delle selezioni è valida, l'utente fa clic su uno e viene restituito il documento corrispondente. |
| Esplorazione in base a facet | Una pagina mostra collegamenti di spostamento selezionabili o percorsi di navigazione che restringeno l'ambito della ricerca. Una struttura di spostamento in base a facet è composta in modo dinamico in base a una query iniziale. Ad esempio, search=* per popolare un albero di spostamento in base a facet composto da ogni categoria possibile. Una struttura di spostamento in base a facet viene creata da una risposta di query, ma è anche un meccanismo per esprimere la query successiva. n riferimento all'API REST, facets è documentato come parametro di query di un'operazione Di ricerca documenti, ma può essere usato senza il search parametro . |
| Metodo Filter | I filtri vengono usati con facet per restringere i risultati. È anche possibile implementare un filtro dietro la pagina, ad esempio per inizializzare la pagina con campi specifici della lingua. In Informazioni di riferimento $filter sull'API REST è documentato come parametro di query di un'operazione Di ricerca documenti, ma può essere usato senza il search parametro . |
Effetto degli attributi di campo sulle query
Se si ha familiarità con i tipi di query e la composizione, è possibile ricordare che i parametri di una richiesta di query dipendono dagli attributi di campo in un indice. Ad esempio, solo i campi contrassegnati come searchable e retrievable possono essere usati nelle query e nei risultati della ricerca. Quando si impostano i searchparametri , filtere orderby nella richiesta, è necessario controllare gli attributi per evitare risultati imprevisti.
Nello screenshot del portale seguente dell'indice di esempio degli hotel, solo gli ultimi due campi "LastRenovationDate" e "Rating" sono sortable, un requisito per l'uso in una "$orderby" clausola solo.

Per le definizioni di attributi di campo, vedere Creare un indice (API REST).
Effetto dei token sulle query
Durante l'indicizzazione, il motore di ricerca usa un analizzatore di testo sulle stringhe per massimizzare il potenziale di ricerca di una corrispondenza in fase di query. Come minimo, le stringhe sono minuscole, ma a seconda dell'analizzatore, possono anche subire la lemmatizzazione e arrestare la rimozione delle parole. Le stringhe più grandi o le parole composte vengono in genere suddivise da spazi vuoti, trattini o trattini e indicizzate come token separati.
Il punto da portare via è che ciò che si ritiene che l'indice contenga e che cosa sia effettivamente in esso, può essere diverso. Se le query non restituiscono risultati previsti, è possibile esaminare i token creati dall'analizzatore tramite l'API REST Analizza testo. Per altre informazioni sulla tokenizzazione e sull'impatto sulle query, vedere Ricerca e modelli di termini parziali con caratteri speciali.
Passaggi successivi
Ora che si ha una migliore comprensione del funzionamento delle richieste di query, provare le guide introduttive seguenti per un'esperienza pratica.