Processi elastici per il database SQL di Azure
Si applica a:![]() database SQL di Azure
database SQL di Azure
In questo articolo esaminiamo le funzionalità e i dettagli dei processi elastici per database SQL di Azure.
- Per un'esercitazione sulla configurazione dei processi elastici, vedere l'esercitazione sui processi elastici.
- Ulteriori informazioni sui concetti di automazione nelle piattaforme di database di Azure.
Panoramica dei processi elastici
È possibile creare e pianificare processi elastici eseguibili periodicamente su uno o più database SQL di Azure per eseguire query T-SQL (Transact-SQL) e attività di manutenzione.
È possibile definire il database o i gruppi di database di destinazione in cui verrà eseguito il processo, nonché le pianificazioni per l'esecuzione. Tutti i riferimenti relativi a data e orari nei processi elastici sono nel fuso orario UTC.
Un processo gestisce l'attività di accesso al database di destinazione. È anche possibile definire, gestire e mantenere script Transact-SQL da eseguire su un gruppo di database.
Ogni processo registra lo stato di esecuzione e ripete automaticamente le operazioni se si verificano errori.
Quando usare i processi elastici
L'automazione dei processi elastici può essere usata in diversi scenari:
- Automatizzare le attività di gestione e quindi pianificare l'esecuzione in ogni giorno feriale, fuori orario lavorativo e così via.
- Distribuzione delle modifiche dello schema, gestione delle credenziali.
- Raccolta di dati sulle prestazioni o raccolta della telemetria dei tenant (clienti).
- Aggiornare i dati di riferimento, ad esempio informazioni comuni tra tutti i database.
- Caricare dati da archiviazione BLOB di Azure.
- Configurare i processi per l'esecuzione in una raccolta di database su base periodica, ad esempio durante le fasce orarie non di punta.
- Raccogliere i risultati di query da un set di database in una tabella centrale su base costante.
- Le query possono essere eseguite continuamente e configurate per l'esecuzione di attività aggiuntive di trigger.
- Raccogliere i dati per i report
- Aggregare i dati di una raccolta di database in una singola tabella di destinazione.
- Eseguire query di elaborazione dei dati più lunghe per una vasta serie di database, ad esempio la raccolta della telemetria del cliente. I risultati vengono raccolti in una tabella di destinazione singola per ulteriori analisi.
- Spostamento dei dati
- Per soluzioni sviluppate su misura, automazione aziendale o altre attività di gestione.
- Elaborazione ETL per estrarre/elaborare/inserire dati tra le tabelle di un database.
Prendere in considerazione i processi elastici se:
- Si ha un'attività che dev'essere eseguita regolarmente in base a una pianificazione, destinata a uno o più database.
- Si ha un'attività che dev'essere eseguita una volta sola, ma in più database.
- Si ha necessità di eseguire processi su qualsiasi combinazione di database: uno o più database individuali, tutti i database su un server, tutti i database in un pool elastico, con in più la possibilità di includere o escludere database specifici. I processi possono essere eseguiti in più server, in più pool e anche in database di sottoscrizioni differenti. I server e i pool vengono enumerati in modo dinamico in fase di esecuzione, quindi i processi vengono eseguiti su tutti i database esistenti nel gruppo di destinazione al momento dell'esecuzione.
- Si tratta di una differenza significativa rispetto a SQL Agent, che non può enumerare dinamicamente i database di destinazione, soprattutto negli scenari dei clienti SaaS in cui i database vengono aggiunti/eliminati in modo dinamico.
Componenti dei processi elastici
| Componente | Descrizione |
|---|---|
| Agente di processo elastico | Risorsa di Azure creata per eseguire e gestire i processi. |
| Database di processo | Un database di Database SQL di Azure usato dall'agente di processo per archiviare dati, definizioni e così via correlati ai processi. |
| Mansione | Un processo è un'unità di lavoro costituita da uno o più passaggi. I passaggi del processo specificano lo script T-SQL da eseguire, nonché altri dettagli necessari per eseguirlo. |
| Gruppo di destinazione | Il set di server, pool e database su cui eseguire un processo. |
Agente di processo elastico
Un agente di processo elastico è la risorsa di Azure per creare, eseguire e gestire i processi. L'agente di processo elastico è una risorsa di Azure che viene creata nel portale (sono anche supportati PowerShell e REST API).
La creazione di un agente di processo elastico richiede un database esistente in database SQL di Azure. L'agente configura il database SQL di Azure esistente come database di processo.
È possibile avviare, disattivare o annullare un processo tramite il portale di Azure. Il portale di Azure permette anche di visualizzare le definizioni dei processi e la cronologia di esecuzione.
Costo dell'agente di processo elastico
Il database di processo viene fatturato alla stessa tariffa di qualsiasi database di Database SQL di Azure. Per il costo dell'agente di processi elastico, vedere Calcolatore dei prezzi di Azure.
Database dei processi elastici
Il database di processo viene usato per definire i processi e tracciare lo stato e la cronologia delle esecuzioni dei processi. I processi sono eseguiti nei database di destinazione. Il database di processo viene anche usato per archiviare metadati dell'agente, log, risultati e definizioni dei processi e contiene anche molte stored procedure utili e altri oggetti del database per creare, eseguire e gestire i processi con T-SQL.
Si consiglia di utilizzare un database esistente del database SQL di Azure (S1 o superiore).
Il database del processo dev'essere un database SQL di Azure pulito, vuoto, con obiettivo S1 o superiore.
L'obiettivo di servizio consigliato per il database di processo è S1 o superiore, ma la scelta ottimale dipende dalle prestazioni richieste dai processi, ovvero il numero di passaggi del processo, il numero di obiettivi del processo e la frequenza delle esecuzioni.
Se le operazioni eseguite sul database dei processi sono più lente del previsto, monitorare le prestazioni del database e l'utilizzo delle risorse nel database dei processi durante i periodi di lentezza usando il portale di Azure o la DMV sys. dm_db_resource_stats. Se l'utilizzo di una risorsa, ad esempio CPU, I/O dati o scrittura log si avvicina al 100% ed è correlato a periodi di lentezza, valutare il ridimensionamento incrementale del database a obiettivi di servizio più elevati (nel modello DTU o nel modello vCore) finché le prestazioni del database del processo non sono sufficientemente migliorate.
Importante
Non modificare gli oggetti esistenti o creare nuovi oggetti nel database del processo, anche se è possibile leggere le tabelle per i report e le analisi.
Processi elastici e fasi del processo
Un processo è un'unità di lavoro che viene eseguita in una pianificazione o come processo occasionale. Un processo è costituito da uno o più passaggi.
Ogni passaggio del processo specifica uno script T-SQL da eseguire, uno o più gruppi di destinazione in cui eseguire lo script T-SQL e le credenziali richieste dall'agente di processo per connettersi al database di destinazione. Ogni passaggio del processo ha criteri di timeout e ripetizione personalizzabili e può eventualmente specificare parametri di output.
Destinazioni dei processi elastici
I processi elastici consentono di eseguire uno o più script T-SQL in parallelo, in un numero elevato di database, in una pianificazione o su richiesta. La destinazione può essere qualunque livello di database SQL di Azure.
È possibile eseguire processi su qualsiasi combinazione di database: uno o più database individuali, tutti i database su un server, tutti i database in un pool elastico, con in più la possibilità di includere o escludere database specifici. I processi possono essere eseguiti in più server, in più pool e anche in database di sottoscrizioni differenti. I server e i pool vengono enumerati in modo dinamico in fase di esecuzione, quindi i processi vengono eseguiti su tutti i database esistenti nel gruppo di destinazione al momento dell'esecuzione.
La figura seguente mostra un agente di processo che esegue processi tra diversi tipi di gruppi di destinazione:
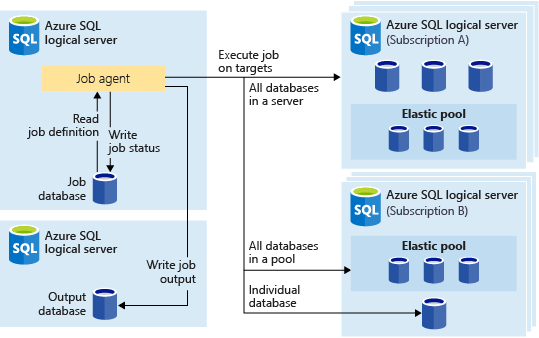
Gruppo di destinazione
Un gruppo di destinazione definisce il set di database sui quali verrà eseguito un passaggio di processo. Un gruppo di destinazione può contenere qualsiasi numero e una combinazione degli elementi seguenti:
- Server logico di SQL Server: se è specificato un server, tutti i database presenti al suo interno al momento dell'esecuzione del processo fanno parte del gruppo. È necessario fornire le credenziali del database
masterin modo che il gruppo possa essere enumerato e aggiornato prima dell'esecuzione del processo. Per ulteriori informazioni sui server logici, vedere Informazioni sul server nel database SQL di Azure e in Azure Synapse Analytics. - Pool elastico: se è specificato un pool elastico, tutti i database presenti nel pool elastico al momento dell'esecuzione del processo fanno parte del gruppo. Come per un server, è necessario fornire le credenziali del database
masterin modo che il gruppo possa essere aggiornato prima dell'esecuzione del processo. - Database singolo: specificare uno o più database singoli da includere nel gruppo.
Suggerimento
Al momento dell'esecuzione del processo, l'enumerazione dinamica rivaluta il set dei database nei gruppi di destinazione che includono server o pool. L'enumerazione dinamica assicura che i processi vengano eseguiti in tutti i database esistenti nel server o nel pool al momento dell'esecuzione. Rivalutare l'elenco dei database in fase di esecuzione è particolarmente utile per gli scenari in cui l'appartenenza al pool o al server cambia frequentemente.
I pool e i database singoli possono essere specificati come inclusi o esclusi dal gruppo. Ciò consente di creare un gruppo di destinazione con qualsiasi combinazione di database. È ad esempio possibile aggiungere un server a un gruppo di destinazione, ma escludere database specifici di un pool elastico o escludere un intero pool.
Un gruppo di destinazione può includere database in più sottoscrizioni e in più aree. Le esecuzioni tra più aree hanno una latenza maggiore rispetto alle esecuzioni nella stessa area.
Gli esempi seguenti illustrano come diverse definizioni del gruppo destinazione vengono enumerate in modo dinamico al momento dell'esecuzione del processo per determinare i database che verranno eseguiti:

- L'esempio 1 mostra un gruppo di destinazione costituito da un elenco di singoli database. Quando un passaggio del processo viene eseguito usando questo gruppo di destinazione, l'azione del passaggio verrà eseguita in ognuno di tali database.
- L'esempio 2 mostra un gruppo di destinazione contenente un server. Quando un passaggio del processo viene eseguito usando questo gruppo di destinazione, il server viene enumerato in modo dinamico per determinare l'elenco dei database attualmente presenti nel server. L'azione del passaggio del processo verrà eseguita in ognuno di tali database.
- L'esempio 3 mostra un gruppo di destinazione simile a quello dell'esempio 2, ma con l'esclusione specifica di un singolo database. L'azione del passaggio del processo non verrà eseguita nel database escluso.
- L'esempio 4 mostra un gruppo di destinazione contenente un pool elastico come destinazione. Analogamente all'esempio 2, il pool verrà enumerato in modo dinamico in fase di esecuzione del processo per determinare l'elenco dei database nel pool.

- L'esempio 5 e l'esempio 6 mostrano scenari avanzati in cui server, pool elastici e database possono essere combinati usando regole di inclusione e di esclusione.
Nota
Lo stesso database del processo può essere la destinazione di un processo. In questo scenario, il database del processo è considerato come qualsiasi altro database di destinazione. È necessario aver creato l'utente del processo a cui concedere autorizzazioni sufficienti nel database del processo e in esso devono anche esistere le credenziali con ambito database per l'utente del processo, come per qualsiasi altro database di destinazione.
Autenticazione
Scegliere un metodo per tutte le destinazioni di un agente di processo elastico. Ad esempio, per un singolo agente di processo elastico, non è possibile configurare un server di destinazione per l'uso delle credenziali con ambito database e un altro per l'uso dell'autenticazione con Microsoft Entra ID.
L'agente di processo elastico può connettersi ai server/database specificati dal gruppo di destinazione tramite due opzioni di autenticazione:
- Usare l'autenticazione di Microsoft Entra (in precedenza Azure Active Directory) con un'identità gestita assegnata dall'utente (UMI).
- Usare le credenziali nell’ambito del database.
Autenticazione tramite l'identità gestita assegnata dall'utente (UMI)
L'autenticazione di Microsoft Entra (in precedenza Azure Active Directory) tramite l'identità gestita assegnata dall'utente (UMI) è l'opzione consigliata per connettere i processi elastici al database SQL di Azure. Con il supporto di Microsoft Entra ID, l'agente di processo sarà in grado di connettersi ai database di destinazione (database, server, pool elastici) e ai database di output usando l'UMI.

In via facoltativa, è anche possibile abilitare l'autenticazione di Microsoft Entra ID nel server logico contenente il database di processi elastici per l'accesso o l'esecuzione di query sul database tramite le connessioni Microsoft Entra ID. Tuttavia, l'agente di processo stesso usa un'autenticazione interna basata su certificati per connettersi al proprio database del processo.
È possibile creare una UMI o usarne una esistente e assegnare la stessa UMI a più agenti di processo. Per ogni agente di processo è supportata una sola UMI. Quando una UMI viene assegnata a un agente di processo, esso userà questa identità solo per connettersi ed eseguire processi t-SQL nei database di destinazione. L'autenticazione SQL non verrà usata per il server o i database di destinazione di tale agente di processo.
Il nome dell'UMI deve iniziare con una lettera o un numero e deve avere una lunghezza compresa tra 3 e 128 caratteri. Può contenere i caratteri - e _.
Per ulteriori informazioni sull'UMI nel database SQL di Azure, vedere Identità gestite per Azure SQL, inclusi i passaggi necessari e i vantaggi dell'uso di una UMI come identità del server logico del database SQL di Azure. Per ulteriori informazioni, vedere Usare Microsoft Entra (in precedenza Azure Active Directory) per l'autenticazione alle piattaforme Azure SQL.
Importante
Quando si usa l'autenticazione di Microsoft Entra ID, creare l'utente jobuser da tale Microsoft Entra ID in ogni database di destinazione. Concedere all'utente le autorizzazioni necessarie per eseguire i processi in ciascun database di destinazione.
L'uso di un'identità gestita assegnata dal sistema (SMI) non è supportato.
Autenticazione mediante credenziali con ambito database
Sebbene l'autenticazione di Microsoft Entra (in precedenza Azure Active Directory) sia l'opzione consigliata, i processi possono essere configurati per usare le credenziali con ambito database per connettersi ai database specificati dal gruppo di destinazione al momento dell'esecuzione. Prima di ottobre 2023, le credenziali con ambito database erano la sola opzione di autenticazione.
Se un gruppo di destinazione contiene server o pool, queste credenziali con ambito database vengono usate per connettersi al database master ed enumerare i database disponibili.
- Le credenziali con ambito database devono essere create nel database di processo.
- Per completare correttamente il processo, tutti i database di destinazione devono avere un account di accesso con autorizzazioni sufficienti (
jobusernel diagramma seguente). - Le credenziali create nei database di destinazione (
LOGINePASSWORDpermasteruserejobuser, nel diagramma seguente) devono corrispondere aIDENTITYeSECRETnelle credenziali create nel database del processo. - Le credenziali possono essere riutilizzate in tutti i processi e le password delle credenziali vengono crittografate e protette dagli utenti che hanno accesso in sola lettura agli oggetti del processo.
La seguente immagine è progettata per aiutare a comprendere la configurazione delle corrette credenziali del processo e il modo in cui l'agente di processo elastico si connette usando le credenziali del database come autenticazione per gli account di accesso/utenti nei server o nei database di destinazione.
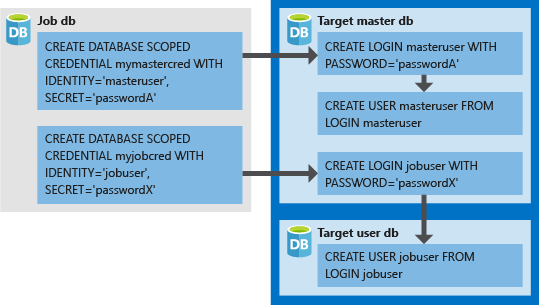
Nota
Quando si usano credenziali con ambito database, ricordarsi di creare l'utente jobuser per ogni database di destinazione.
Endpoint privati dei processi elastici
L'agente di processo elastico supporta endpoint privati dei processi elastici. La creazione di un endpoint privato dei processi elastici consente di stabilire un collegamento privato tra il processo elastico e il server di destinazione. La funzionalità degli endpoint privati dei processi elastici è diversa dal collegamento privato di Azure.

La funzionalità degli endpoint privati dei processi elastici supporta le connessioni private ai server di destinazione/output, in modo che l'agente di processo possa comunque raggiungerli anche quando è attivata l'opzione "Nega accesso pubblico". L'uso di endpoint privati è anche una possibile soluzione se si vuole disattivare l'opzione "Consenti alle risorse e ai servizi di Azure di accedere a questo server".
Gli endpoint privati dei processi elastici supportano tutte le opzioni di autenticazione dell'agente di processo elastico.
La funzionalità degli endpoint privati dei processi elastici consente di scegliere un endpoint privato gestito dal servizio per stabilire una connessione sicura tra l'agente di processo e i relativi server di destinazione/output. Un endpoint privato gestito dal servizio è un indirizzo IP privato all'interno di una rete virtuale e di una subnet specifiche. Quando si sceglie di usare endpoint privati su uno dei server di destinazione/output dell'agente di processo, Microsoft crea un endpoint privato gestito dal servizio. Questo endpoint privato viene quindi usato esclusivamente dall'agente di processo per la connessione e l'esecuzione di processi o per la scrittura dell'output del processo nei database di destinazione/output.
Gli endpoint privati dei processi elastici possono essere creati e autorizzati tramite il portale di Azure. I server di destinazione connessi tramite il collegamento privato possono trovarsi ovunque in Azure, anche in aree geografiche e sottoscrizioni diverse. Per abilitare questa comunicazione, è necessario creare un endpoint privato per ogni server di destinazione desiderato e per il server di output del processo.
Per un'esercitazione su come configurare un nuovo endpoint privato per i processi elastici gestito dal servizio, vedere Configurare l'endpoint privato dei processi elastici di Azure SQL.
Requisiti degli endpoint privati dei processi elastici
- Per usare un endpoint privato dei processi elastici, sia l'agente di processo che i server o i database di destinazione devono essere ospitati in Azure (nella stessa area o in aree diverse) e nello stesso tipo di cloud (ad esempio, entrambi in un cloud pubblico oppure entrambi in un cloud per enti pubblici).
- Il provider di risorse
Microsoft.Networkdev'essere registrato per le sottoscrizioni di host sia dell'agente di processo sia dei server di destinazione/output. - Gli endpoint privati dei processi elastici vengono creati per ciascun server di destinazione/output. Devono essere approvati prima che l'agente di processo elastico possa usarli. Questa operazione può essere eseguita tramite il riquadro Rete del server logico o del client preferito. L'agente di processo elastico sarà quindi in grado di raggiungere tutti i database in quel server usando una connessione privata.
- La connessione dall'agente di processo elastico al database dei processi non userà l'endpoint privato. L'agente di processo stesso usa un'autenticazione interna basata su certificati per connettersi al proprio database del processo. Un'avvertenza: se si aggiunge il database dei processi come membro del gruppo di destinazione, esso si comporta come una destinazione normale che dev'essere configurata con l'endpoint privato, se necessario.
Autorizzazioni per il database dei processi elastici
Durante la creazione di un agente di processo vengono creati uno schema, delle tabelle e un ruolo denominato jobs_reader nel database dei processi. Il ruolo viene creato con la seguente autorizzazione ed è progettato per fornire agli amministratori un controllo di accesso più preciso per il monitoraggio dei processi. Gli amministratori possono fornire agli utenti la possibilità di monitorare l'esecuzione dei processi aggiungendoli al ruolo jobs_reader nel database dei processi.
| Nome ruolo | Autorizzazioni per lo schema "jobs" | Autorizzazioni per lo schema 'jobs_internal' |
|---|---|---|
| jobs_reader | SELECT | None |
Attenzione
Non aggiornare le viste interne del catalogo nel database dei processi, ad esempio jobs.target_group_members. La modifica manuale delle viste del catalogo può danneggiare il database dei processi e provocare un errore. Queste viste sono destinate solo all'esecuzione di query di sola lettura. È possibile usare le stored procedure nel database dei processi per aggiungere/eliminare gruppi/membri di destinazione, ad esempio jobs.sp_add_target_group_member.
Importante
Considerare le implicazioni di sicurezza prima di concedere un accesso elevato al database dei processi. Un utente malintenzionato con le autorizzazioni di creazione o modifica dei processi potrebbe creare o modificare un processo che usa una credenziale archiviata per connettersi a un database con il controllo dell'utente malintenzionato, consentendo a questo utente di determinare la password della credenziale o di eseguire comandi dannosi.
Monitorare i processi elastici
A partire da ottobre 2023, l'agente di processi elastici si integra con gli avvisi di Azure per le notifiche sullo stato dei processi, semplificando la soluzione per il monitoraggio dello stato e della cronologia dell'esecuzione dei processi.
Il portale di Azure include anche nuove funzionalità aggiuntive per supportare i processi elastici e il monitoraggio dei processi. Nella pagina Informazioni generali dell'agente di processo elastico vengono visualizzate le esecuzioni più recenti del processo, come illustrato nello screenshot seguente.

È possibile creare regole di avviso del Monitoraggio di Azure con il portale di Azure, l'interfaccia della riga di comando di Azure, PowerShell e l'API REST. La metrica Processi elastici non riusciti è un buon punto di partenza per monitorare e ricevere avvisi sull'esecuzione dei processi elastici. Inoltre, è possibile scegliere di ricevere un avviso tramite un'azione configurabile, ad esempio SMS o posta elettronica, dalla funzionalità avvisi di Azure. Per ulteriori informazioni, vedere Creare avvisi per il database SQL di Azure nel portale di Azure.
Per un esempio, vedere Creare, configurare e gestire processi elastici.
Output del processo
Il risultato dei passaggi di un processo in ciascun database di destinazione vengono registrati nei dettagli e l'output dello script può essere acquisito in una tabella specifica. È possibile specificare un database per salvare i dati restituiti da un processo.
Cronologia dei processi
Visualizzare la cronologia di esecuzione dei processi elastici nel database dei processi eseguendo una query sulla tabella jobs.job_executions. Un processo di pulizia del sistema elimina la cronologia dei processi eseguiti oltre 45 giorni prima. Per rimuovere manualmente la cronologia entro i 45 giorni precedenti, eseguire la stored procedure sp_purge_jobhistory nel database dei processi.
Stato processo
È possibile monitorare le esecuzioni dei processi elastici nel database dei processi eseguendo una query sulla tabella jobs.job_executions.
Procedure consigliate
Quando si utilizzano processi di database elastici, considerare le seguenti procedure consigliate.
Procedure consigliate per la sicurezza
- Limitare l'utilizzo delle API a utenti attendibili.
- Le credenziali devono avere i privilegi minimi necessari per eseguire il passaggio del processo. Per ulteriori informazioni, vedere Autorizzazioni e permessi.
- Quando si usa un server e/o un membro del gruppo di destinazione del pool, è consigliabile creare una credenziale separata con diritti per il database
masterper visualizzare/elencare i database, usata per espandere gli elenchi dei database dei server e/o dei pool prima dell'esecuzione del processo.
Prestazioni dei processi elastici
I processi elastici usano risorse di calcolo minime, in attesa del completamento dei processi di lunga durata.
A seconda delle dimensioni del gruppo di database di destinazione e del tempo di esecuzione desiderato per un processo (numero di processi simultanei), l'agente richiede prestazioni e risorse di calcolo differenti per il database dei processi (maggiore è il numero di destinazioni e di processi, maggiore sarà la quantità di risorse di calcolo necessarie).
Livelli di capacità simultanei
A partire da ottobre 2023, l'agente di processi elastici dispone di più livelli di prestazioni per consentire un aumento della capacità.
Gli incrementi di capacità indicano il numero totale di database di destinazione simultanei a cui l'agente di processo può connettersi e avviare un processo. Per più connessioni di destinazione simultanee per l'esecuzione del processo, aggiornare il livello dell'agente di processo rispetto al livello predefinito JA100, che ha un limite di 100 connessioni di destinazione simultanee.
La maggior parte degli ambienti richiede meno di 100 processi simultanei in ogni momento, quindi JA100 è l'impostazione predefinita.
| Livello dell'agente di processo elastico | Numero massimo di processi simultanei |
|---|---|
| JA100 | 100 |
| JA200 | 200 |
| JA400 | 400 |
| JA800 | 800 |
Il superamento del livello di capacità di concorrenza dell'agente di processo con le destinazioni dei processi creerà ritardi di accodamento per alcuni database/server di destinazione. Ad esempio, se si avvia un processo con 110 destinazioni nel livello JA100, 10 processi resteranno in attesa di avviarsi solo al completamento degli altri processi.
Il livello o l'obiettivo di servizio di un agente di processo elastico può essere modificato tramite il portale di Azure, PowerShell, o l'API REST degli agenti di processo. Per un esempio, vedere Ridimensionare l'agente di processo.
Limitare l'impatto dei processi sui pool elastici
Per garantire che le risorse non siano sovraccariche quando si eseguono processi su un database SQL di Azure in un pool elastico, è possibile configurare i processi in modo da limitare il numero di database in cui un processo può essere eseguito contemporaneamente.
Impostare il numero di database simultanei in cui viene eseguito un processo impostando il parametro sp_add_jobstep della stored procedure @max_parallelism in T-SQL.
Script idempotenti
Gli script T-SQL di un processo elastico devono essere idempotenti. Idempotente significa che se lo script ha esito positivo e viene eseguito nuovamente, si ottiene lo stesso risultato. Uno script potrebbe non andare a buon fine a causa di problemi di rete temporanei. In tal caso, il processo ritenterà automaticamente l'esecuzione dello script per un numero di volte predefinito prima di desistere. Uno script idempotente ha lo stesso risultato anche se è stato eseguito correttamente due (o più) volte.
Una semplice strategia consiste nel verificare l'esistenza di un oggetto prima di crearlo. Di seguito viene riportato un esempio ipotetico:
IF NOT EXISTS (SELECT * FROM sys.objects WHERE [name] = N'some_object')
print 'Object does not exist'
-- Create the object
ELSE
print 'Object exists'
-- If it exists, drop the object before recreating it.
Analogamente, uno script deve poter essere eseguito correttamente verificando in modo logico e risolvendo qualsiasi condizione trovata.
Limiti
Queste sono le limitazioni attuali del servizio di processi elastici. Stiamo lavorando attivamente al fine di rimuovere il maggior numero possibile di queste limitazioni.
| Problema | Descrizione |
|---|---|
| L'agente di processi elastici dev'essere ricreato e avviato nella nuova area dopo un failover/passaggio a una nuova area di Azure. | Il servizio di processi elastici archivia tutti gli agenti di processo e i metadati dei processi nel database dei processi. Qualsiasi failover o spostamento delle risorse di Azure in una nuova area di Azure sposta anche il database dei processi, l'agente di processo e i metadati dei processi nella nuova area di Azure. Tuttavia, l'agente di processi elastici è una risorsa di solo calcolo e deve essere esplicitamente ricreato e avviato nella nuova area prima che i processi inizino a essere eseguiti di nuovo nella nuova area. Dopo l'avvio, l'agente di processi elastici riprenderà l'esecuzione dei processi nella nuova area in base alla pianificazione dei processi definita in precedenza. |
| Eccesso di log di controllo dal database dei processi | L'agente di processi elastici opera eseguendo costantemente il polling del database dei processi per verificare l'arrivo di nuovi processi e altre operazioni CRUD. Se il controllo è abilitato nel server che ospita un database dei processi, è possibile che quest'ultimo generi un numero elevato di log di controllo. Questa operazione può essere mitigata filtrando questi log di controllo usando il comando Set-AzSqlServerAudit con un'espressione di predicato.Ad esempio: Set-AzSqlServerAudit -ResourceGroupName "ResourceGroup01" -ServerName "Server01" -BlobStorageTargetState Enabled -StorageAccountResourceId "/subscriptions/7fe3301d-31d3-4668-af5e-211a890ba6e3/resourceGroups/resourcegroup01/providers/Microsoft.Storage/storageAccounts/mystorage" -PredicateExpression "database_principal_name <> '##MS_JobAccount##'"Questo comando filtrerà solo i log di controllo dell'agente di processo verso il database dei processi, non i log di controllo dell'agente di processo verso i database di destinazione. |
| Uso di un database Hyperscale come database dei processi | L'uso di un database Hyperscale come database dei processi non è supportato. Tuttavia, i processi elastici possono avere come destinazione i database Hyperscale allo stesso modo di qualsiasi altro database SQL di Azure. |
| Database serverless e sospensione automatica con i processi elastici. | Il database serverless abilitato per la sospensione automatica non è supportato come database dei processi. I database serverless di destinazione dei processi elastici supportano la sospensione automatica e verranno ripresi dalle connessioni dei processi. |
| Esportare un database dei processi in un file BACPAC | L'esportazione di un database dei processi in un file BACPAC non è supportata. Se è necessario esportare il server SQL contenente un database dei processi, prima di esportare il server è necessario eliminare il database dei processi. |
Contenuto correlato
- Creare, configurare e gestire processi elastici
- Automatizzare le attività di gestione con Azure SQL
- Creare e gestire processi elastici usando PowerShell
- Creare e gestire processi elastici usando T-SQL
Passaggio successivo
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per