Esercitazione: Implementare il modello di acquisizione data lake per aggiornare una tabella di Databricks Delta
Questa esercitazione descrive come gestire eventi in un account di archiviazione che include uno spazio dei nomi gerarchico.
Verrà compilata una piccola soluzione che permette a un utente di popolare una tabella di Databricks Delta caricando un file con valori delimitati da virgole (CSV) che descrive un ordine di vendita. Questa soluzione verrà compilata connettendo una sottoscrizione di Griglia di eventi, una funzione di Azure e un processo in Azure Databricks.
In questa esercitazione si apprenderà come:
- Creare una sottoscrizione di Griglia di eventi che chiama una funzione di Azure.
- Creare una funzione di Azure che riceve una notifica da un evento e quindi esegue il processo in Azure Databricks.
- Creare un processo di Azure Databricks che inserisce un ordine cliente in una tabella di Databricks Delta che si trova nell'account di archiviazione.
Questa soluzione verrà compilata in ordine inverso, a partire dall'area di lavoro di Azure Databricks.
Prerequisiti
Creare un account di archiviazione con uno spazio dei nomi gerarchico (Azure Data Lake Storage Gen2). Questa esercitazione usa un account di archiviazione denominato
contosoorders.Vedere Creare un account di archiviazione da usare con Azure Data Lake Storage Gen2.
Verificare che all'account utente sia assegnato il ruolo di collaboratore ai dati del BLOB di archiviazione.
Creare un'entità servizio, creare un segreto client e quindi concedere all'entità servizio l'accesso all'account di archiviazione.
Vedere Esercitazione: Connettersi a Azure Data Lake Storage Gen2 (passaggi da 1 a 3). Dopo aver completato questi passaggi, assicurarsi di incollare i valori ID tenant, ID app e segreto client in un file di testo. Saranno necessari a breve.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Creare un ordine di vendita
Prima di tutto, creare un file CSV che descrive un ordine di vendita e quindi caricarlo nell'account di archiviazione. Successivamente, i dati contenuti in questo file verranno usati per popolare la prima riga nella tabella di Databricks Delta.
Passare al nuovo account di archiviazione nel portale di Azure.
Selezionare Storage browser-BLOB containers-Add container (Contenitori BLOBdi archiviazione)>> e creare un nuovo contenitore denominato dati.
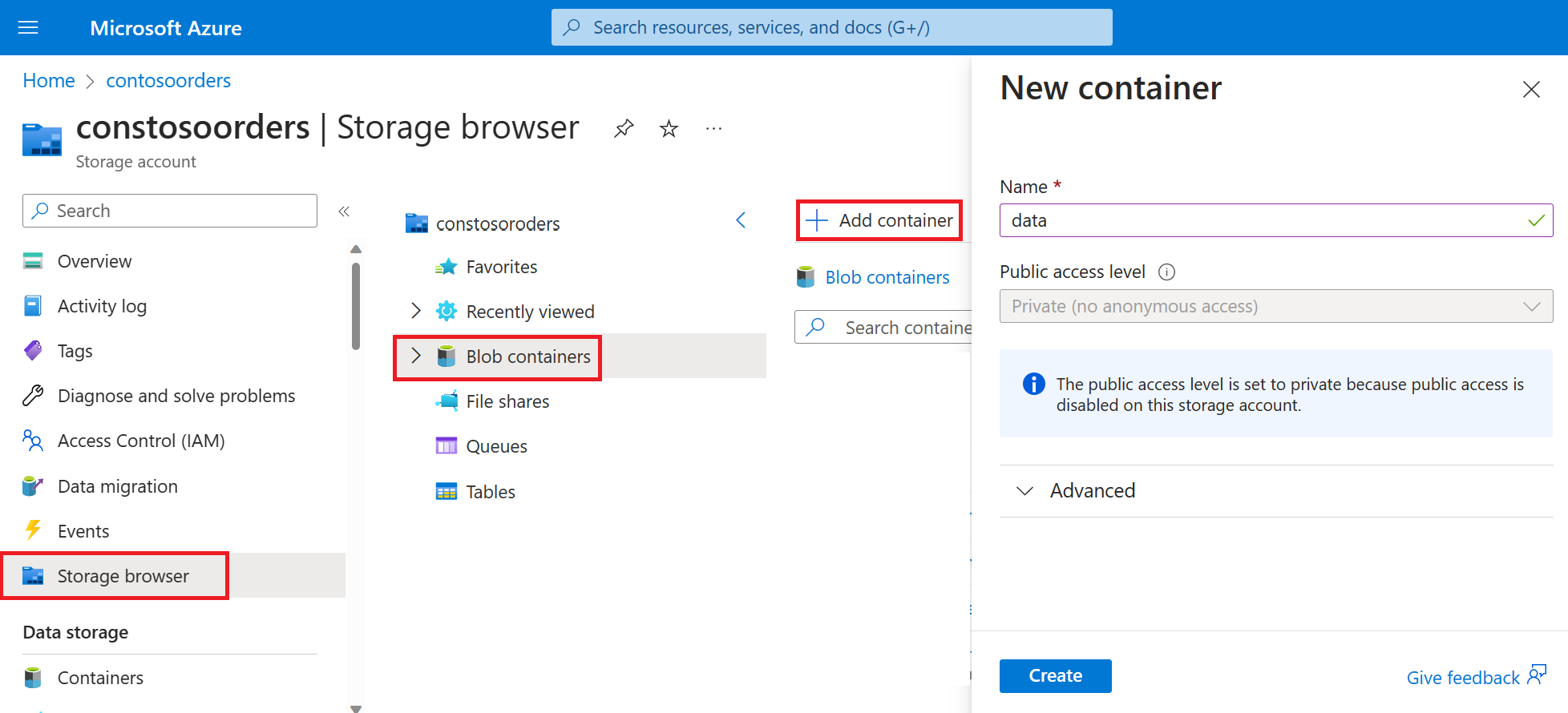
Nel contenitore dati creare una directory denominata input.
Incollare il testo seguente in un editor di testo.
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomSalvare il file nel computer locale con il nome data.csv.
Nel browser di archiviazione caricare questo file nella cartella di input .
Creare un processo in Azure Databricks
In questa sezione verranno eseguite le attività seguenti:
- Creare un'area di lavoro di Azure Databricks.
- Creare un notebook.
- Creare e popolare una tabella di Databricks Delta.
- Aggiungere codice per l'inserimento di righe nella tabella di Databricks Delta.
- Creare un processo.
Creare un'area di lavoro di Azure Databricks
In questa sezione viene creata un'area di lavoro di Azure Databricks usando il portale di Azure.
Creare un'area di lavoro di Azure Databricks. Nome dell'area di lavoro
contoso-orders. Vedere Creare un'area di lavoro di Azure Databricks.Creare un cluster. Assegnare al cluster
customer-order-clusteril nome . Vedere Creare un cluster.Creare un notebook. Assegnare un nome al notebook
configure-customer-tablee scegliere Python come linguaggio predefinito del notebook. Vedere Creare un notebook.
Creare e popolare una tabella di Databricks Delta
Nel notebook creato copiare e incollare il blocco di codice seguente nella prima cella, ma non eseguire ancora il codice.
Sostituire i valori segnaposto
appId,passwordetenantin questo blocco di codice con quelli raccolti durante il completamento dei prerequisiti di questa esercitazione.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Questo codice crea un widget denominato source_file. Più avanti si creerà una funzione di Azure che chiama questo codice e passa un percorso di file al widget. Questo codice autentica anche l'entità servizio con l'account di archiviazione e crea alcune variabili da usare in altre celle.
Nota
In un ambiente di produzione è consigliabile archiviare la chiave di autenticazione in Azure Databricks. Aggiungere quindi una chiave di ricerca al blocco di codice invece della chiave di autenticazione.
Ad esempio, invece di usare la riga di codicespark.conf.set("fs.azure.account.oauth2.client.secret", "<password>"), si userà la riga di codice seguente:spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
Dopo aver completato questa esercitazione, vedere l'articolo Azure Data Lake Storage Gen2 nel sito Web di Azure Databricks per alcuni esempi di questo approccio.Premere MAIUSC + INVIO per eseguire il codice in questo blocco.
Copiare e incollare il blocco di codice seguente in una cella diversa e quindi premere MAIUSC+INVIO per eseguire il codice in questo blocco.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Questo codice crea la tabella di Databricks Delta nell'account di archiviazione e quindi carica alcuni dati iniziali dal file CSV caricato in precedenza.
Al termine dell'esecuzione di questo blocco di codice, rimuoverlo dal notebook.
Aggiungere codice per l'inserimento di righe nella tabella di Databricks Delta
Copiare e incollare il blocco di codice seguente in una cella diversa, ma non eseguire ancora la cella.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Questo codice inserisce dati in una visualizzazione tabella temporanea usando i dati di un file CSV. Il percorso del file CSV deriva dal widget di input creato in un passaggio precedente.
Copiare e incollare il blocco di codice seguente in una cella diversa. Questo codice unisce il contenuto della vista tabella temporanea con la tabella Databricks Delta.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Creare un processo
Creare un processo per l'esecuzione del notebook creato in precedenza. Più avanti si creerà una funzione di Azure che esegue questo processo quando viene generato un evento.
Selezionare Nuovoprocesso>.
Assegnare un nome al processo, scegliere il notebook creato e il cluster. Selezionare quindi Crea per creare il processo.
Creare una funzione di Azure
Creare una funzione di Azure che esegue il processo.
Nell'area di lavoro Azure Databricks fare clic sul nome utente di Azure Databricks nella barra superiore e quindi nell'elenco a discesa selezionare Impostazioni utente.
Nella scheda Token di accesso selezionare Genera nuovo token.
Copiare il token visualizzato e quindi fare clic su Fine.
Nell'angolo superiore dell'area di lavoro di Databricks scegliere l'icona Persone, quindi scegliere Impostazioni utente.

Selezionare il pulsante Genera nuovo token e quindi selezionare il pulsante Genera .
Assicurarsi di copiare il token in una posizione sicura. La funzione di Azure richiede questo token per l'autenticazione con Databricks, in modo da poter eseguire il processo.
Nel menu del portale di Azure o dalla pagina Home selezionare Crea una risorsa.
Nella pagina Nuovo, selezionare Calcolo>App per le funzioni.
Nella scheda Nozioni di base della pagina Crea app per le funzioni scegliere un gruppo di risorse e quindi modificare o verificare le impostazioni seguenti:
Impostazione Valore Nome dell'app per le funzioni contosoorder Stack di runtime .NET Pubblica Codice Sistema operativo Windows Tipo di piano Consumo (serverless) Selezionare Rivedi e crea e quindi Crea.
Al termine della distribuzione, selezionare Vai alla risorsa per aprire la pagina di panoramica dell'app per le funzioni.
Nel gruppo Impostazioni selezionare Configurazione.
Nella pagina Impostazioni applicazione scegliere il pulsante Nuova impostazione applicazione per aggiungere ogni impostazione.

Usare le impostazioni seguenti:
Nome impostazione valore DBX_INSTANCE Area dell'area di lavoro di Databricks. Ad esempio: westus2.azuredatabricks.netDBX_PAT Token di accesso personale generato in precedenza. DBX_JOB_ID Identificatore del processo in esecuzione. Selezionare Salva per eseguire il commit di queste impostazioni.
Nel gruppo Funzioni selezionare Funzioni e quindi crea.
Scegliere Trigger griglia di eventi.
Installare l'estensione Microsoft.Azure.WebJobs.Extensions.EventGrid, se viene chiesto di farlo. Se è necessario installarla, scegliere di nuovo Trigger griglia di eventi per creare la funzione.
Viene visualizzato il riquadro Nuova funzione.
Nel riquadro Nuova funzione assegnare un nome alla funzione UpsertOrder e quindi selezionare il pulsante Crea .
Sostituire il contenuto del file di codice con questo codice e quindi selezionare il pulsante Salva :
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Questo codice analizza le informazioni sull'evento di archiviazione generato e quindi crea un messaggio di richiesta con l'URL del file che ha generato l'evento. Come parte del messaggio, la funzione passa un valore al widget source_file creato in precedenza. Il codice della funzione invia il messaggio al processo di Databricks e usa il token ottenuto in precedenza come autenticazione.
Creare una sottoscrizione di Griglia di eventi
In questa sezione si creerà una sottoscrizione di Griglia di eventi che chiama la funzione di Azure quando vengono caricati file nell'account di archiviazione.
Selezionare Integrazione e quindi nella pagina Integrazione selezionare Trigger griglia di eventi.
Nel riquadro Modifica trigger assegnare un nome all'evento e quindi selezionare Crea sottoscrizione evento
eventGridEvent.Nota
Il nome
eventGridEventcorrisponde al parametro denominato passato alla funzione di Azure.Nella scheda Nozioni di base della pagina Crea sottoscrizione evento modificare o verificare le impostazioni seguenti:
Impostazione Valore Nome contoso-order-event-subscription Tipo di argomento Account di archiviazione Risorsa di origine contosoorders Nome dell'argomento di sistema <create any name>Filtro per tipi di evento BLOB creato e BLOB eliminato Selezionare il pulsante Crea.
Testare la sottoscrizione di Griglia di eventi
Creare un file denominato
customer-order.csv, incollare le informazioni seguenti nel file e salvarlo nel computer locale.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneIn Storage Explorer caricare questo file nella cartella input dell'account di archiviazione.
Il caricamento di un file genera l'evento Microsoft.Storage.BlobCreated. Griglia di eventi invia una notifica a tutti i sottoscrittori dell'evento. In questo caso, la funzione di Azure è l'unico sottoscrittore. La funzione di Azure analizza i parametri dell'evento per determinare l'evento che si è verificato. Passa quindi l'URL del file al processo di Databricks. Il processo di Databricks legge il file e aggiunge una riga alla tabella di Databricks Delta che si trova nell'account di archiviazione.
Per verificare se il processo ha esito positivo, visualizzare le esecuzioni per il processo. Verrà visualizzato uno stato di completamento. Per altre informazioni su come visualizzare le esecuzioni per un processo, vedere Visualizzare le esecuzioni per un processo
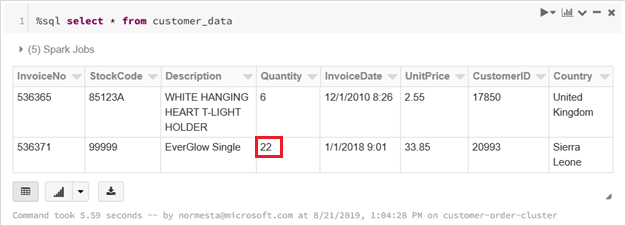
In una nuova cella della cartella di lavoro eseguire questa query per visualizzare la tabella di Databricks Delta aggiornata.
%sql select * from customer_dataLa tabella restituita mostra il record più recente.

Per aggiornare questo record, creare un file denominato
customer-order-update.csv, incollare le informazioni seguenti nel file e salvarlo nel computer locale.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneQuesto file CSV è quasi identico a quello precedente, ad eccezione del fatto che la quantità dell'ordine è stata modificata da
228a22.In Storage Explorer caricare questo file nella cartella input dell'account di archiviazione.
Eseguire di nuovo la query
selectper visualizzare la tabella Delta aggiornata.%sql select * from customer_dataLa tabella restituita mostra il record aggiornato.
Pulire le risorse
Quando non sono più necessari, eliminare il gruppo di risorse e tutte le risorse correlate. A questo scopo, selezionare il gruppo di risorse per l'account di archiviazione e quindi fare clic su Elimina.