Rilevamento anomalie in Analisi di flusso di Azure
Analisi di flusso di Azure, disponibile sia nel cloud che in Azure IoT Edge, offre funzionalità di rilevamento anomalie integrate basate su Machine Learning, che possono essere usate per monitorare le due anomalie più frequenti: temporanee e persistenti. Le funzioni AnomalyDetection_SpikeAndDip e AnomalyDetection_ChangePoint consentono di eseguire il rilevamento anomalie direttamente nel processo di Analisi di flusso.
I modelli di Machine Learning presuppongono una serie temporale con campionamento uniforme. Se la serie temporale non è uniforme, è possibile inserire un passaggio di aggregazione con una finestra a cascata prima di chiamare il rilevamento anomalie.
Le operazioni di Machine Learning non supportano attualmente tendenze di stagionalità o correlazioni multi-variate.
Rilevamento anomalie mediante apprendimento automatico in Analisi di flusso di Azure
Il video seguente illustra come rilevare un'anomalia in tempo reale usando le funzioni di Machine Learning in Analisi di flusso di Azure.
Comportamento del modello
Generalmente l'accuratezza del modello migliora se la finestra temporale scorrevole contiene più dati. I dati nella finestra temporale scorrevole specificata vengono trattati come parte del normale intervallo di valori per quell'intervallo di tempo. Il modello considera solo la cronologia eventi sulla finestra temporale scorrevole per verificare se l'evento corrente è anomalo. Quando si sposta la finestra scorrevole, i valori precedenti vengono rimossi dal training del modello.
Le funzioni operano stabilendo una certa normalità in base a ciò che hanno visto finora. Gli outlier vengono identificati mediante un confronto con il valore normale stabilito, entro il livello di attendibilità. Le dimensioni della finestra devono essere basate sul numero minimo di eventi necessari per eseguire il training del modello per il comportamento normale in modo che, quando si verifica un'anomalia, sia in grado di riconoscerla.
Il tempo di risposta del modello aumenta con le dimensioni della cronologia perché deve essere confrontato con un numero maggiore di eventi precedenti. È consigliabile includere solo il numero necessario di eventi per ottenere prestazioni migliori.
La presenza di interruzioni nella serie temporale può dipendere dal fatto che il modello non riceve eventi in determinati periodi di tempo. Questa situazione viene gestita da Analisi di flusso usando la logica di imputazione. Le dimensioni della cronologia, nonché la durata, per la stessa finestra temporale scorrevole vengono usate per calcolare la frequenza media con cui si prevede che arrivino gli eventi.
Un generatore di anomalie disponibile qui può essere usato per inserire un hub Iot con dati con modelli di anomalie diversi. È possibile configurare un processo di Analisi di flusso di Azure con queste funzioni di rilevamento anomalie per leggere da questo hub IoT e rilevare le anomalie.
Picchi e flessioni
Le anomalie temporanee in un flusso di eventi di una serie temporale sono note come picchi e flessioni. Questi picchi e flessioni possono essere monitorati usando l'operatore basato su Machine Learning AnomalyDetection_SpikeAndDip.
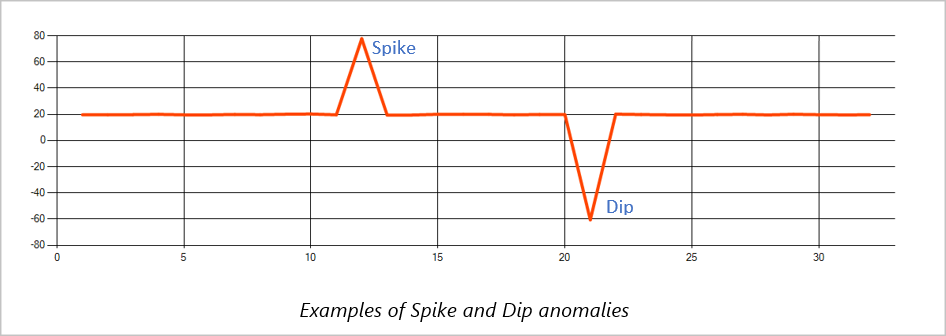
Se nella stessa finestra temporale scorrevole un secondo picco è inferiore al primo, il punteggio calcolato del picco inferiore non è probabilmente abbastanza significativo rispetto al punteggio del primo picco all'interno del livello di attendibilità specificato. È possibile provare a ridurre il livello di attendibilità del modello per rilevare tali anomalie. Se però si inizia a ricevere troppi avvisi, è possibile usare un intervallo di attendibilità più elevato.
La query di esempio seguente presuppone una frequenza di input uniforme di un evento al secondo in una finestra temporale scorrevole di 2 minuti con una cronologia di 120 eventi. L'istruzione SELECT finale estrae e restituisce il punteggio e lo stato dell'anomalia con un livello di attendibilità del 95%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Punto di modifica
Le anomalie persistenti in un flusso di eventi di una serie temporale sono modifiche nella distribuzione dei valori del flusso di eventi, come cambi di livello e tendenze. In Analisi di flusso queste anomalie vengono rilevate mediante l'operatore basato su Machine Learning AnomalyDetection_ChangePoint.
Le modifiche persistenti durano molto più a lungo dei picchi e delle immersioni e potrebbero indicare eventi irreversibili. Le modifiche persistenti non sono in genere visibili all'occhio nudo, ma possono essere rilevate con l'operatore AnomalyDetection_ChangePoint .
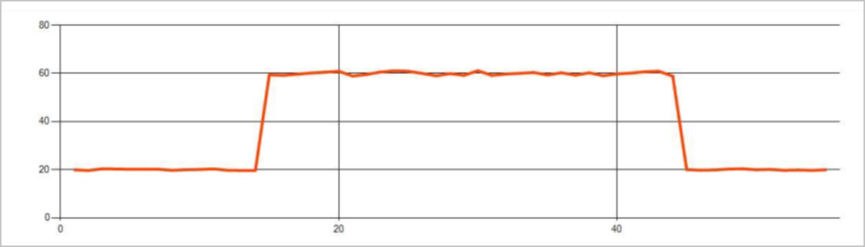
L'immagine seguente è un esempio di cambio di livello:
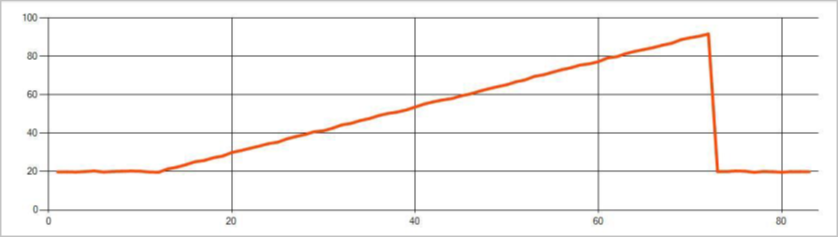
L'immagine seguente è un esempio di cambio di tendenza:
La query di esempio seguente presuppone una frequenza di input uniforme di un evento al secondo in una finestra temporale scorrevole di 20 minuti con dimensioni della cronologia di 1.200 eventi. L'istruzione SELECT finale estrae e restituisce il punteggio e lo stato dell'anomalia con un livello di attendibilità dell'80%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Caratteristiche delle prestazioni
Le prestazioni di questi modelli dipendono dalle dimensioni della cronologia, dalla durata della finestra, dal caricamento degli eventi e dall'uso del partizionamento a livello di funzione. In questa sezione vengono descritte queste configurazioni e vengono forniti esempi per il supporto dei tassi di inserimento di 1 K, 5 K e 10.000 eventi al secondo.
- Dimensioni cronologia: questi modelli vengono eseguiti in modo lineare con le dimensioni della cronologia. Più lunga è la dimensione della cronologia, più i modelli impiegano per assegnare un punteggio a un nuovo evento. Il motivo è che i modelli confrontano il nuovo evento con ognuno degli eventi precedenti nel buffer della cronologia.
- Durata finestra: la durata della finestra deve riflettere il tempo necessario per ricevere tutti gli eventi specificati dalle dimensioni della cronologia. Senza questo numero di eventi nella finestra, Analisi di flusso di Azure imputa valori mancanti. Di conseguenza, il consumo della CPU è una funzione delle dimensioni della cronologia.
- Carico eventi: maggiore è il carico degli eventi, maggiore è il lavoro eseguito dai modelli, che influisce sull'utilizzo della CPU. Il processo può essere ridimensionato rendendolo imbarazzantemente parallelo, presupponendo che sia opportuno usare più partizioni di input per la logica di business.
- Il partizionamento a livello di funzione del partizionamento - a livello di funzione viene eseguito usando
PARTITION BYall'interno della chiamata di funzione di rilevamento anomalie. Questo tipo di partizionamento comporta un sovraccarico, perché lo stato deve essere mantenuto per più modelli contemporaneamente. Il partizionamento a livello di funzione viene usato in scenari come il partizionamento a livello di dispositivo.
Relationship
Le dimensioni della cronologia, la durata della finestra e il carico totale degli eventi sono correlati nel modo seguente:
windowDuration (in ms) = 1000 * historySize/ (eventi di input totali al secondo/ Conteggio partizioni di input)
Quando si partiziona la funzione in base a deviceId, aggiungere "PARTITION BY deviceId" alla chiamata di funzione di rilevamento anomalie.
Osservazioni
La tabella seguente include le osservazioni sulla velocità effettiva per un singolo nodo (sei unità di ricerca) per il caso non partizionato:
| Dimensioni cronologia (eventi) | Durata finestra (ms) | Totale eventi di input al secondo |
|---|---|---|
| 60 | 55 | 2.200 |
| 600 | 728 | 1,650 |
| 6.000 | 10,910 | 1.100 |
La tabella seguente include le osservazioni sulla velocità effettiva per un singolo nodo (sei unità di ricerca) per il caso partizionato:
| Dimensioni cronologia (eventi) | Durata finestra (ms) | Totale eventi di input al secondo | Conteggio dispositivi |
|---|---|---|---|
| 60 | 1,091 | 1.100 | 10 |
| 600 | 10,910 | 1.100 | 10 |
| 6.000 | 218,182 | <550 | 10 |
| 60 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6.000 | 2,181,819 | <550 | 100 |
Il codice di esempio per eseguire le configurazioni non partizionate precedenti si trova nel repository Streaming At Scale di Esempi di Azure. Il codice crea un processo di analisi di flusso senza partizionamento a livello di funzione, che usa Hub eventi come input e output. Il carico di input viene generato usando i client di test. Ogni evento di input è un documento JSON di 1 KB. Gli eventi simulano un dispositivo IoT che invia dati JSON (per un massimo di 1 K dispositivi). Le dimensioni della cronologia, la durata della finestra e il carico totale degli eventi sono variati in due partizioni di input.
Nota
Per una stima più accurata, personalizzare gli esempi per adattarli allo scenario.
Identificazione dei colli di bottiglia
Per identificare i colli di bottiglia nella pipeline, usare il riquadro Metriche nel processo di Analisi di flusso di Azure. Vedere Eventi di input/output per la velocità effettiva e "Ritardo limite" o Eventi con backlog per verificare se il processo è in grado di mantenere la frequenza di input. Per le metriche di Hub eventi, cercare Richieste limitate e regolare le unità di soglia di conseguenza. Per le metriche di Azure Cosmos DB, vedere Max consumed UR/s per ogni intervallo di chiavi di partizione in Velocità effettiva per assicurarsi che gli intervalli di chiavi di partizione vengano usati in modo uniforme. Per il database SQL di Azure, monitorare I/O LOG e CPU.
Video demo
Passaggi successivi
- Introduzione ad Analisi dei flussi di Azure
- Introduzione all'uso di Analisi dei flussi di Azure
- Ridimensionare i processi di Analisi dei flussi di Azure
- Informazioni di riferimento sul linguaggio di query di Analisi di flusso di Azure
- Informazioni di riferimento sulle API REST di gestione di Analisi di flusso di Azure